Command Palette
Search for a command to run...
学习预见:揭示在线策略蒸馏的解锁效率
学习预见:揭示在线策略蒸馏的解锁效率
摘要
基于策略蒸馏(On-policy distillation, OPD)已成为大语言模型一种高效的训练后范式。然而,现有研究大多将这一优势归因于更密集且更稳定的监督信号,而对 OPD 效率背后的参数级机制仍缺乏深入理解。在本工作中,我们认为 OPD 的效率源于一种“前瞻性”(foresight):它在训练早期就建立了一条朝向最终模型的稳定更新轨迹。这种前瞻性体现在两个方面。首先,在模块分配层面(Module-Allocation Level),OPD 识别出边际效用较低的区域,并将更新集中在对推理更为关键的模块上。其次,在更新方向层面(Update-Direction Level),OPD 表现出更强的低秩集中特性,其主导子空间在训练早期便与最终更新子空间高度对齐。基于这些发现,我们提出了 EffOPD,这是一种即插即用的加速方法,通过自适应地选择外推步长并沿当前更新方向移动来加速 OPD。EffOPD 无需额外的可训练模块或复杂的超参数调优,在保持相当最终性能的同时,实现了平均 3 倍的训练加速。总体而言,我们的研究结果为理解 OPD 的效率提供了参数动态视角,并为设计更高效的大语言模型训练后方法提供了实用见解。
一句话总结
基于对策略蒸馏的效率源于模块分配的早期预判与更新方向对齐的发现,作者提出了 EffOPD。这是一种即插即用的加速方法,通过自适应选择外推步长以跟随当前的更新轨迹,从而在无需额外可训练模块或复杂超参数调优的情况下,保持相当的最终性能,为大型语言模型实现平均 3 倍的训练加速。
核心贡献
- 分析表明,对策略蒸馏通过建立早期预判来提升效率,该预判将参数更新沿稳定轨迹引导至最终模型。该机制将梯度更新集中在推理关键模块上,并在训练早期使主导的低秩子空间与最终更新子空间对齐。
- 提出 EffOPD 作为一种即插即用的加速方法,通过自适应选择外推步长沿当前更新方向推进。该方法无需额外可训练模块或复杂超参数调优。
- 实证评估表明,与基线对策略蒸馏相比,EffOPD 实现了平均 3 倍的训练加速,同时保持相当的最终性能。这些结果验证了外推策略在高效大型语言模型后训练中的有效性。
引言
对策略蒸馏已成为大型语言模型的关键后训练范式,在提供与强化学习相当推理能力的同时显著降低了计算开销。现有文献主要利用更密集的监督等宏观优化特性来解释这一效率,而底层参数级动态与收敛机制仍未得到充分探索。作者揭示了一种预判机制:蒸馏过程在训练早期通过抑制低效用模块并锁定最终优化子空间,使更新轨迹趋于稳定。基于此洞察,作者提出了 EffOPD。这是一种即插即用的加速框架,沿这些早期预测方向进行外推,从而在无需引入额外可训练模块或复杂超参数调优的情况下实现三倍训练加速。
数据集

- 数据集构成与来源:作者未引入或发布新数据集。相反,研究依赖论文中完整引用的现有公开数据集、模型与基线。
- 各子集关键细节:未构建任何新子集。本研究严格遵循所有引用外部资产的原始许可、版本与服务条款。
- 数据使用与训练配置:作者遵循所引用数据集与基线的既定研究用途。本文未指定自定义训练划分、混合比例或微调协议,因为研究重点仍在于现有外部资源。
- 处理与元数据策略:未应用自定义裁剪、元数据构建或数据过滤规则。研究明确排除众包与人类受试者,因此无需同意程序、机构审查委员会批准或专门的数据策展流程。
方法
作者利用对策略蒸馏(OPD)作为大型语言模型的后训练范式,该范式继承了对策略训练特性,同时利用教师模型的密集监督信号以实现高效优化。OPD 的核心目标是最小化学生模型与固定教师模型在学生自身生成轨迹上的反向 Kullback-Leibler(KL)散度。其公式表示为 JOPD(θ)=Ex∼D,y∼πθ(⋅∣x)[DKL(πθ(y∣x)∥π∗(y∣x))],其中学生策略 πθ 生成自身响应 y。通过将优化重点聚焦于即时 token 级优化来近似对应的梯度,该方法在每个 token 位置提供密集的学习信号,从而相比存在奖励稀疏问题的可验证奖励强化学习(RLVR)实现了显著更高的训练效率。
该框架揭示了两个解释 OPD 效率的关键特性:功能冗余规避与早期低秩锁定。在模块分配层面观察到的功能冗余规避表明,OPD 将更新集中在高效用模块上。这一结论通过滑动窗口干预分析得以验证,该方法将局部参数更新注入 Transformer 架构的特定层与模块。分析显示,OPD 的参数更新高度集中在关键层(如顶层注意力层与 MLP 层),而嵌入层与底层等非关键模块的更新则受到抑制。 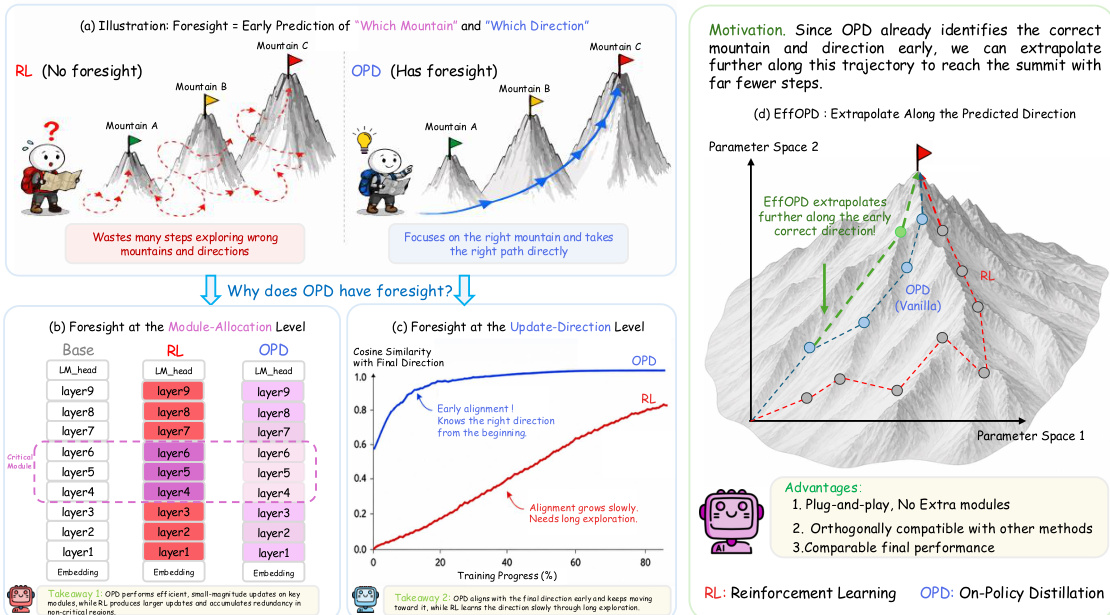
在更新方向层面,OPD 表现出早期低秩锁定特性,即其参数更新方向在训练初期即趋于稳定。该特性通过分析更新矩阵 ΔW 的几何属性得以研究。作者采用四项指标:谱范数、谱范数与 Frobenius 范数之比、有效秩以及 Top-1% 子空间范数比,来刻画更新的低秩结构。分析表明,OPD 的更新高度集中于单一主导方向,导致有效秩较低且 Top-1% 子空间范数比偏高,这与强化学习中更为分散的更新形成对比。OPD 目标函数的局部几何分析进一步解释了这一早期稳定现象,该分析将训练动态近似为凸二次最小化问题。结果表明,更新方向由教师-学生 logit 残差向参数空间的投影决定,该投影在实践中通常具有低秩特性,从而在训练初期便形成稳定且受限的优化轨迹。
受早期方向锁定的观察启发,作者提出了 EffOPD 这一即插即用的加速框架。EffOPD 利用该稳定性,在指数间隔的检查点(t=2n)执行外推搜索。在每个检查点,该方法估计局部更新方向 Δn=W2n−W2n−1,并沿此方向生成候选参数。研究使用轻量级验证集评估这些候选项,并采纳表现最优的一项,从而使进程加速的同时避免性能下降。该机制使 EffOPD 在保持标准 OPD 最终性能的前提下,实现最高 3 倍的训练加速。
实验
在多种模型规模与推理基准测试中,对比对策略蒸馏与强化学习的实验验证了蒸馏方法通过集中更新至高效用架构区域并抑制外围层变化,实现了更优的参数效率。谱分解与训练轨迹分析进一步表明,该方法在优化初期即稳定主导更新方向,形成紧凑的低秩结构,后续步骤仅对其进行放大而非重复探索。这种早期方向锁定使加速变体能够沿已验证路径安全外推,从而获得更快的收敛速度与更高的性能上限。最终,该方法的高效性源于其内在的优先处理任务相关更新几何结构的能力,并系统性地避免了标准强化学习固有的冗余探索特性。
作者对比了 OPD 与强化学习训练方法,表明 OPD 通过集中变化至高效用功能区域并避免低效用区域的冗余更新,实现了更高效的参数更新。结果表明,OPD 在训练初期形成稳定且与任务相关的更新方向,从而以更小的更新范数实现更快收敛与更高性能。该效率优势源于 OPD 能够早期锁定低秩子空间并维持方向稳定性,而强化学习则表现出更为分散且不稳定的更新轨迹。与强化学习相比,OPD 通过集中变化至高效用功能区域,以较小的参数更新实现了更高的推理性能。OPD 在训练初期形成稳定且与任务相关的更新方向,带来更快收敛与更高效率。OPD 的更新轨迹展现出更强的低秩集中度与方向稳定性,而强化学习则呈现更分散且不稳定的演化过程。
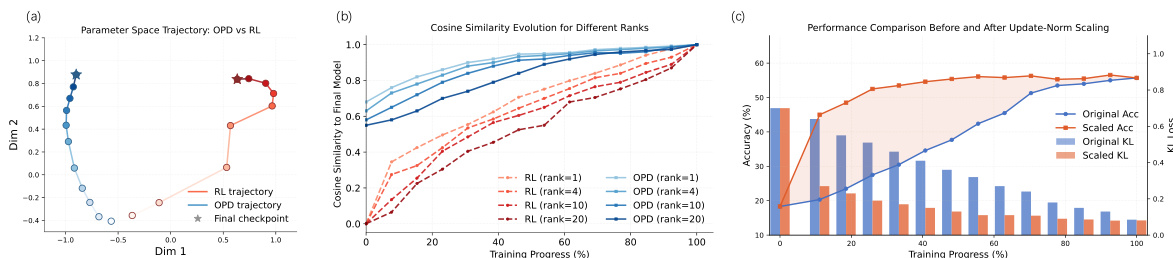
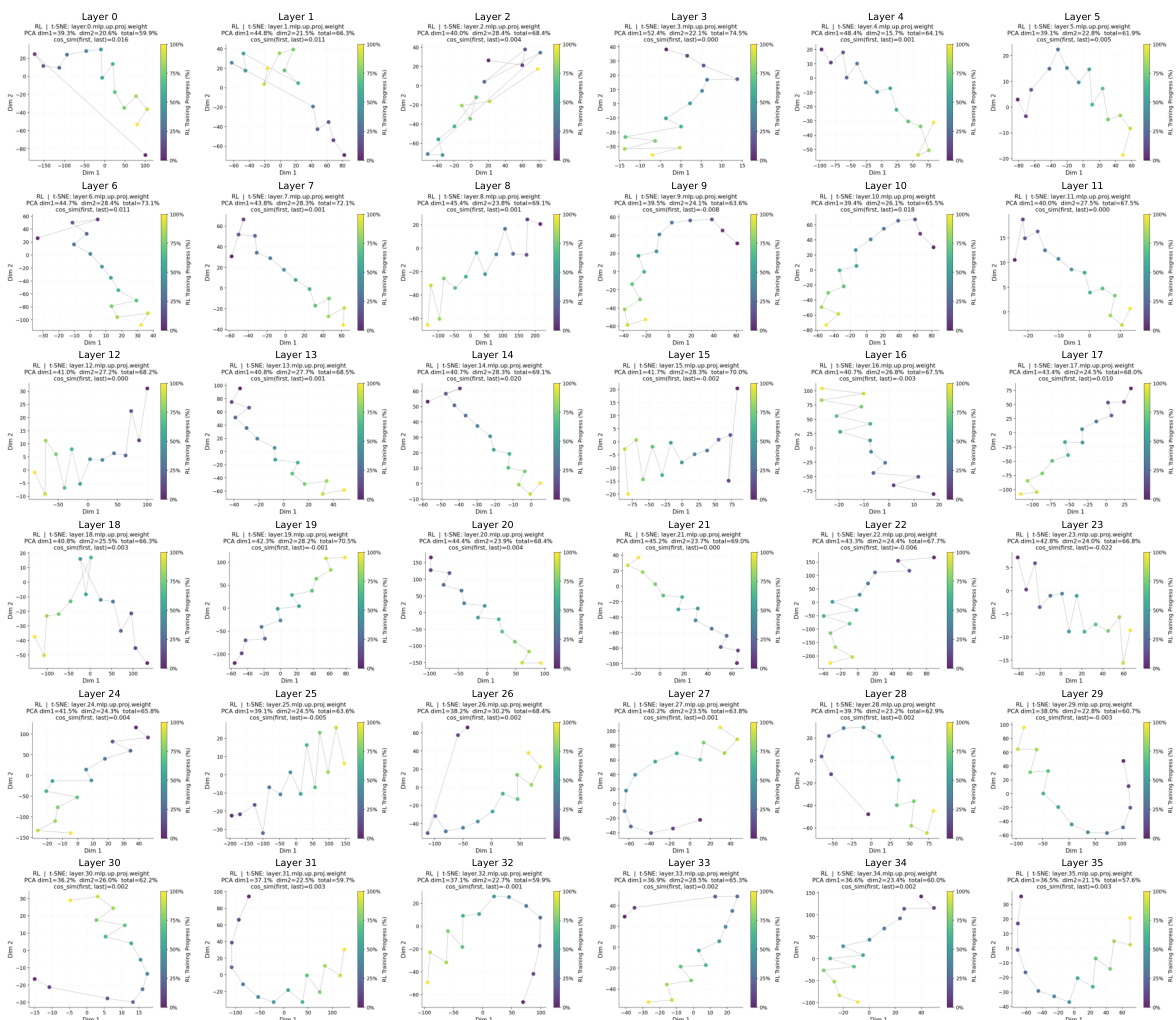
作者对比了 OPD 与强化学习在不同模型层上的参数更新模式,表明 OPD 以较小的参数更新实现了更高的推理性能。OPD 在训练初期表现出更集中且稳定的更新方向,将变化集中在功能贡献较高的中层模块,同时抑制低敏感性区域的更新。与强化学习相比,该方法实现了更高效紧凑的更新,后者引入了更大且针对性较弱(尤其是外围层)的变化。在所有模型层中,OPD 均能以较小的参数更新实现高于强化学习的推理性能。OPD 将更新集中于功能贡献较高的中层模块,而强化学习则在低敏感性外围层引入较大更新。OPD 在训练初期建立稳定且与任务相关的更新方向,从而带来更高效紧凑的参数变化。
作者对比了不同的强化学习方法及其对应的开源实现,重点关注模型性能与可用性。表格列出了多种基础模型、其关联的强化学习训练版本、所用算法以及模型是否开源。结果表明,部分模型为开源,部分则未开源,且小型模型以及 GRPO 和 PPO 等特定算法呈现出更高的开源趋势。表格展示了开源与非开源模型的混合情况,开源可用性因模型规模与算法而异。GRPO 与 PPO 在多种模型中得到应用,部分实现为开源,部分则否。与小型模型相比,Qwen3-14B 和 Qwen2.5-32B 等大型模型开源的可能性较低。
作者对比了用于优化语言模型的不同训练方法,重点关注效率与性能。结果表明,所提出的 EffOPD 方法与其他方法相比实现了更快的收敛速度与更高的性能,尤其在训练初期。分析强调,有效的参数更新集中在模型的特定功能区域,从而带来更高效的学习过程。EffOPD 收敛更快且在其他方法之上实现了更高精度,尤其是在训练初期。参数更新集中在模型的特定功能区域,促进了更高效的学习。与替代方案相比,该方法在保持高性能的同时减少了训练步骤与资源消耗。
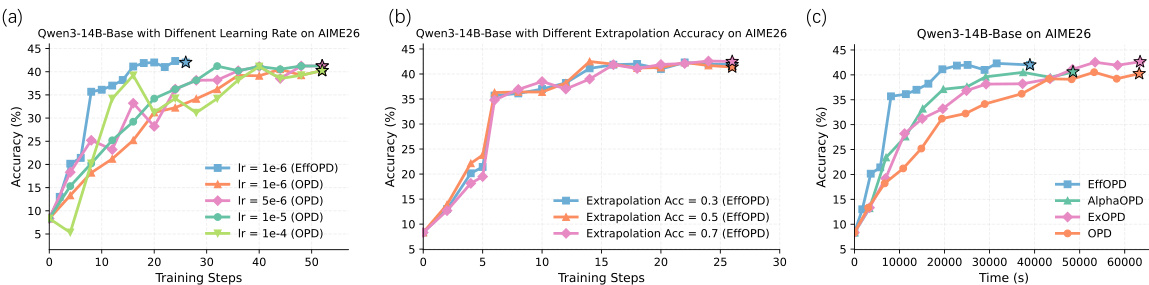
作者对比了训练大型模型时的不同参数更新方法,重点关注效率与性能。结果表明,与基线方法相比,所提方法以更小的参数更新实现了更快的收敛与更高的性能。该优势在不同模型规模与任务中保持一致,表明效率提升具有泛化性。该方法在多种模型与任务中的收敛速度显著快于基线方法。与基线相比,该方法以大幅减小的参数更新实现了更高性能。效率优势在不同模型规模与训练任务中保持一致,表明改进具有泛化潜力。
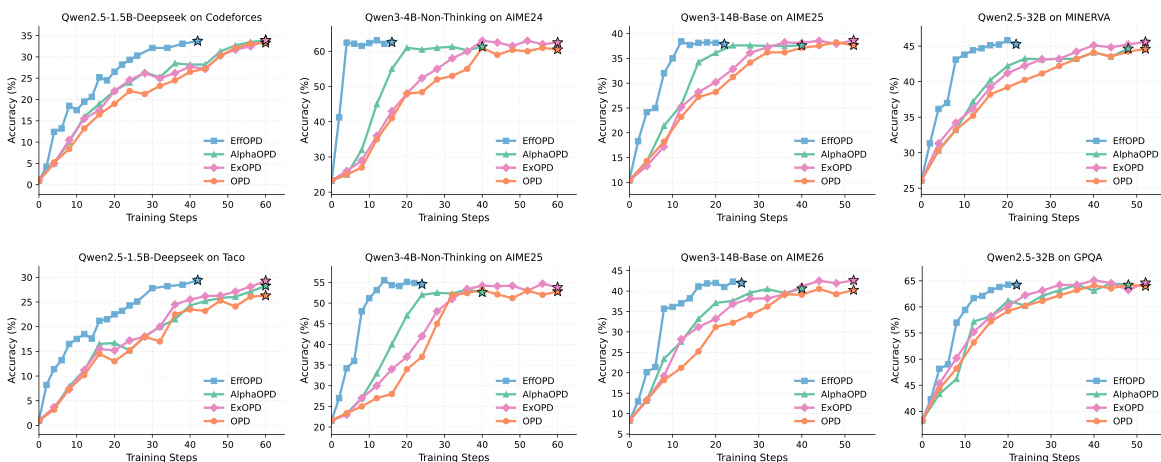
实验在多种模型规模与任务上评估了参数更新策略,将提出的 OPD 与 EffOPD 方法与标准强化学习基线及现有开源实现进行对比。这些评估验证了在高效用功能区域与中层模块集中更新能够生成在训练初期出现的稳定低秩轨迹。定性来看,所提方法始终实现更快收敛与更优推理性能,同时仅需大幅更小的参数修改,这与传统强化学习更为分散且不稳定的更新模式形成鲜明对比。此外,对现有实现的分析突出了不同模型规模与算法在开源可用性上的差异,进一步强调了所提方法的实际效率与广泛泛化能力。