Command Palette
Search for a command to run...
PhysBrain 1.0 技术报告
PhysBrain 1.0 技术报告
摘要
视觉-语言-动作模型取得了快速进展,但仅依靠机器人轨迹所提供的覆盖范围有限,难以支撑对广泛物理理解的深入学习。PhysBrain 1.0 探索了一条互补路径:在机器人适应之前,将大规模人类第一人称视角视频转化为结构化的物理常识监督信号。我们的数据引擎提取场景元素、空间动态、动作执行以及深度感知关系,并将其转化为问答监督信号,用于训练 PhysBrain 视觉语言模型(VLMs)。由此获得的物理先验知识,通过一种保留能力且对语言敏感的适应设计,进一步迁移至视觉-语言-动作(VLA)策略。在包括 ERQA、PhysBench、SimplerEnv-WidowX、LIBERO 和 RoboCasa 在内的多模态问答基准和具身控制基准上,PhysBrain 1.0 取得了最先进(SOTA)的结果,并在 SimplerEnv 上展现出尤为出色的域外泛化性能。这些结果表明,从人类交互视频中扩展物理常识,可以为从多模态理解到机器人动作的转化提供一条有效途径。
一句话总结
PhysBrain 1.0 通过将大规模人类第一人称视角视频转换为结构化的物理常识监督信号,解决了仅依赖轨迹学习的覆盖范围有限问题。该系统通过数据引擎提取场景元素、空间动态、动作执行及深度感知关系,构建问答监督信号,随后借助具备能力保持与语言敏感特性的适配框架,将这些先验知识迁移至视觉-语言-动作策略中。最终,该模型在 ERQA、PhysBench、SimplerEnv-WidowX、LIBERO 和 RoboCasa 等多模态问答与具身控制基准测试中取得领先成果,并在 SimplerEnv 上展现出显著出色的域外泛化性能。
核心贡献
- PhysBrain 1.0 引入了一种基于模式的数据标注流水线,将大规模人类第一人称视角视频转换为结构化的场景元信息与物理常识问答监督信号。该流水线显式提取空间动态、物体状态及深度感知关系,以生成可扩展的物理常识先验。
- 集成的适配架构将这些基于物理的先验知识迁移至视觉-语言-动作策略,同时保持通用的多模态理解能力与语言敏感性。通过将机器人轨迹的作用限定于定向适配,该设计有效防止了策略微调过程中的灾难性遗忘。
- 系统性评估表明,该模型在 ERQA、PhysBench、SimplerEnv-WidowX、LIBERO 和 RoboCasa 等多模态问答与具身控制基准测试中均取得领先性能。模型在 SimplerEnv 上展现出强大的域外泛化能力,验证了源自人类经验的物理先验能够有效弥合多模态理解与机器人动作之间的鸿沟。
引言
视觉-语言-动作模型正在快速推动机器人控制技术的发展,但扩展此类系统通常依赖于收集昂贵且特定于平台的机器人轨迹,其物理覆盖范围十分有限。以往仅模仿这些轨迹的方法往往难以捕捉底层物理规律,且在适配过程中频繁遭遇通用多模态能力的灾难性遗忘。研究团队利用大规模人类第一人称视角视频作为可扩展的替代方案,引入数据引擎提取结构化的场景元素、空间动态与深度感知关系,以生成具备物理基础的问答监督信号。通过在物理常识先验上训练基础视觉语言模型,并应用具备能力保持特性的适配流水线,研究团队成功将稳健的推理能力迁移至下游机器人控制任务中,同时将模型对有限轨迹数据的依赖降至最低。
数据集

数据集构成与来源
- 研究团队采用分阶段方式构建训练语料,而非依赖单一静态数据集
- 主要视频来源包括 Ego4D、BuildAI 和 EgoDex 等第一人称交互数据集,随后整合了 EPIC 和 SEA-Small 等经过重新标注的物理推理数据源
- 类似 FineVision 的通用多模态数据被混合引入作为辅助保留材料,以维持广泛的基础视觉语言处理能力
子集细节与过滤机制
- 第一阶段视频片段使用基于 VGGT 提取的画面质量与相机运动得分进行预过滤,在标注前剔除不稳定或信息量低的片段
- 第二阶段子集将重心从简单的动作识别转向结构化物理推理,将视频片段按物体、材质属性、空间关系、深度线索及状态变化进行分类组织
- 第三阶段将这些结构化记录转换为自由格式的 VQA 监督信号,涵盖空间智能、时间理解、具身规划与通用多模态推理
- 具体数据集规模与训练混合比例未明确说明,但研究团队将各子集视为课程学习流程,确保每个阶段发挥独立的物理基础构建作用
元数据构建与处理流程
- 每个视频片段通过均匀采样的帧进行表示,并解析为包含三个核心字段的受限 JSON 模式:场景元素、空间动态与动作执行
- 场景元素用于捕捉静态物体、周围环境以及材质线索、几何结构与状态等显式物理属性
- 空间动态追踪初始布局及时间维度的变化,例如靠近、接触过程、分离或重新定向
- 动作执行提供简洁的任务概要以及详细指令序列,重点强调运动轨迹、速度分布与接触物理特性
- 包含 GPT-5、Gemini 3.1 Pro 及多个 Qwen-VL 变体的多模型标注池对所有记录进行交叉验证,以降低单模型偏差,并使基础模型接触多样化的物理导向描述
深度增强与质量控制
- 物体定位与 Depth Anything v3 提供的逐像素深度估计相结合,将物体中心映射至深度图,以生成相对空间与度量空间问题
- 质量控制检查在流水线的每个接口处运行,用于拦截无效 JSON、缺失帧、无法读取的深度文件或失败的物体定位结果
- 格式错误的记录会获得明确的状态标记与哨兵值,而非静默进入训练流程
- 下游问答生成模块会自动跳过被标记样本中依赖深度的问题,同时保留这些样本的其他有效场景信息
方法
PhysBrain 1.0 框架围绕两阶段训练流程构建,首先在通用多模态模型中建立稳健的物理理解能力,随后再将其适配至具身控制任务。整体流水线以人类第一人称视角视频为起点,经过处理以提取结构化的场景元信息。该过程包括识别主要物体与环境等场景元素、分析初始布局与变化等空间动态、细化动作执行步骤,以及估算深度感知关系。 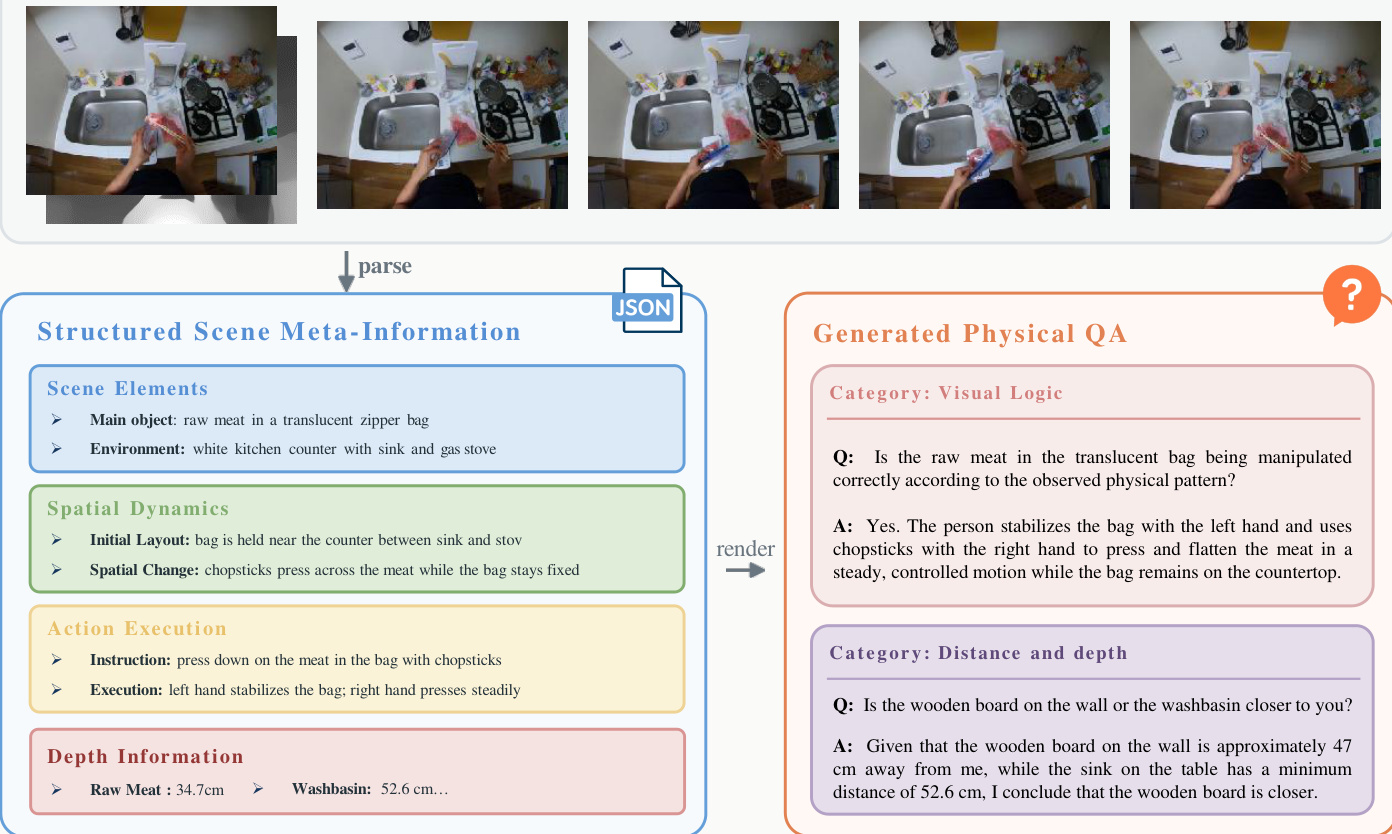 如图所示,此类结构化数据被转换为涵盖视觉逻辑、距离与深度、具身推理等类别的物理常识问答对,用于训练具备物理知识的基础视觉语言模型(VLM)。此阶段的目标在于强化模型的第一人称物理推理能力,涵盖物体状态、空间布局、度量深度、时间动态与多步任务结构,且无需依赖机器人演示数据来获取物理先验。
如图所示,此类结构化数据被转换为涵盖视觉逻辑、距离与深度、具身推理等类别的物理常识问答对,用于训练具备物理知识的基础视觉语言模型(VLM)。此阶段的目标在于强化模型的第一人称物理推理能力,涵盖物体状态、空间布局、度量深度、时间动态与多步任务结构,且无需依赖机器人演示数据来获取物理先验。
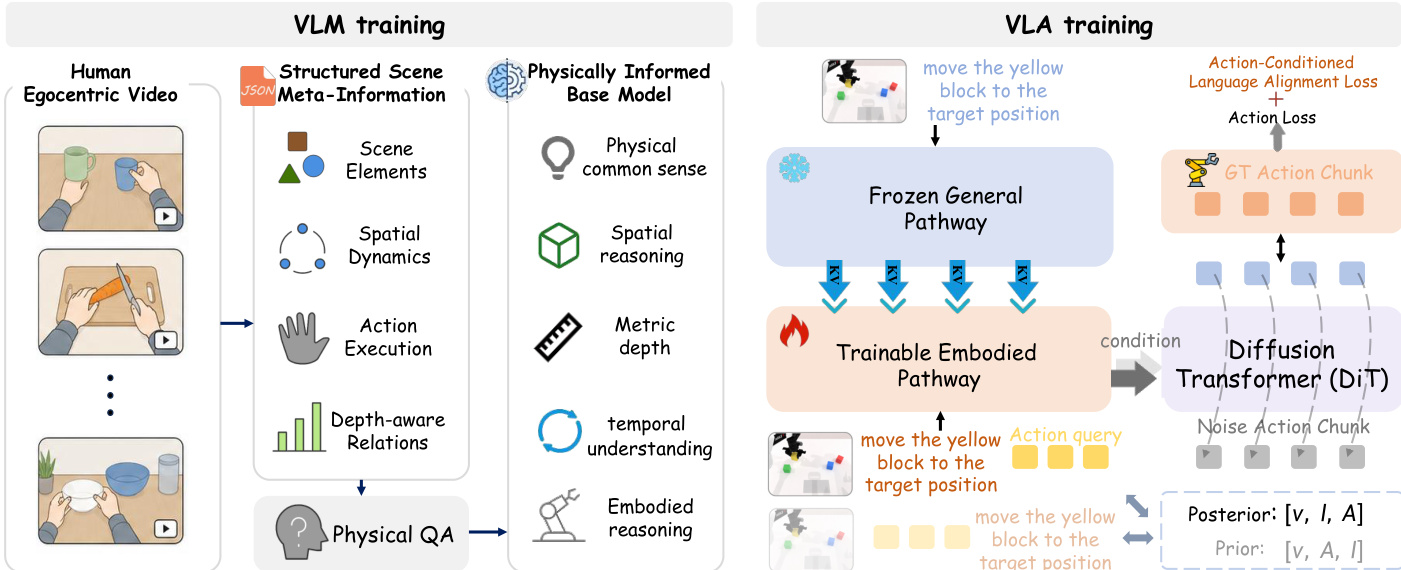 参见框架示意图。基础模型随后通过双路径架构适配为视觉-语言-动作(VLA)策略,该架构旨在保留通用多模态能力的同时学习连续的机器人控制。该架构由冻结的通用路径与可训练的具身路径组成。通用路径基于具备物理知识的基础模型初始化,保持冻结状态,负责处理视觉观测与语言指令,作为稳定的语义参考。具身路径同样基于该模型家族初始化,在机器人演示数据上进行优化以进行动作预测。两条路径通过非对称的逐层融合机制进行通信:具身路径的查询源自其自身的隐藏状态,但其键值上下文则将其自身状态与来自通用路径的停止梯度特征相结合。该设计使控制路径能够依赖保留的语义信息,同时防止通用表示在适配过程中被覆盖。
参见框架示意图。基础模型随后通过双路径架构适配为视觉-语言-动作(VLA)策略,该架构旨在保留通用多模态能力的同时学习连续的机器人控制。该架构由冻结的通用路径与可训练的具身路径组成。通用路径基于具备物理知识的基础模型初始化,保持冻结状态,负责处理视觉观测与语言指令,作为稳定的语义参考。具身路径同样基于该模型家族初始化,在机器人演示数据上进行优化以进行动作预测。两条路径通过非对称的逐层融合机制进行通信:具身路径的查询源自其自身的隐藏状态,但其键值上下文则将其自身状态与来自通用路径的停止梯度特征相结合。该设计使控制路径能够依赖保留的语义信息,同时防止通用表示在适配过程中被覆盖。
为确保数据高效的机器人适配过程中的指令敏感性,PhysBrain 1.0 采用了语言感知动作目标函数。该目标函数使用配对分支对比纯视觉动作上下文与语言条件动作上下文。前置分支将输入排列为 [v, A, l],使动作查询 tokens 仅关注视觉信息而不关注语言;后置分支将输入排列为 [v, l, A],允许动作查询 tokens 同时关注视觉与语言信息。这些查询 tokens 的隐藏状态为动作预测提供条件,而基于对数似然比风格的目标函数则促使动作表示保留与指令相关的信息。该目标函数与扩散 Transformer 动作解码器的动作损失共同进行优化。
动作解码器通过预测流匹配目标的速度场来生成连续的机器人动作。给定真实动作轨迹与高斯噪声,解码器预测速度场以最小化预测动作变化与实际变化之间的差异。预测轨迹在末端执行器坐标系动作空间中进行表示,这与基础模型训练阶段获得的度量深度理解保持一致。在推理阶段,后置分支基于语言感知动作查询状态对动作解码器进行条件约束,以生成连续控制指令。最后阶段使用特定基准的机器人轨迹将 PhysBrain 1.0 适配至具体机器人基准测试中,借助先前的物理理解能力,通过减少机器人演示需求实现数据高效适配。
实验
评估范围涵盖基于物理与通用推理基准的视觉语言模型测试、面向多样化机器人形态的视觉-语言-动作仿真试验,以及针对既定基线的现实世界操作对比。这些实验验证了在人类第一人称数据上进行物理导向预训练能够同时增强多模态理解与具身控制能力。结果一致表明,该模型在异构机器人平台上展现出卓越的域外泛化能力、稳健的灵巧操作性能以及改进的任务执行效率。最终,研究结果证实,在机器人适配前整合结构化物理先验,能够为下游视觉-语言-动作策略奠定更具能力与可迁移性的基础。
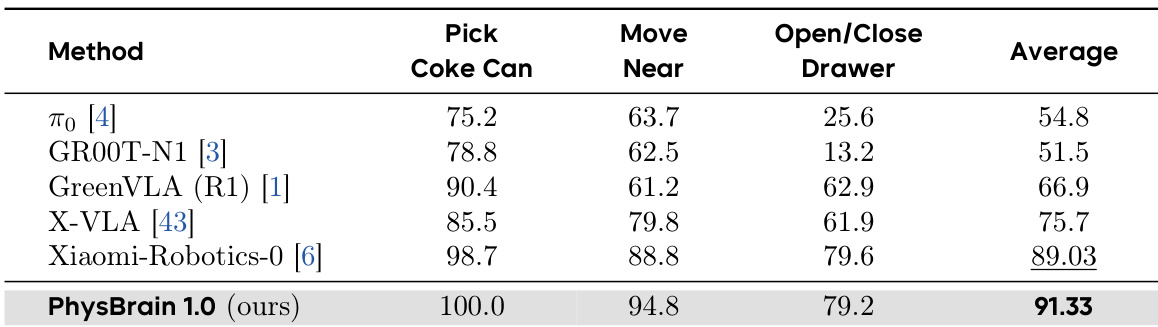
研究团队在仿真环境中使用 SimplerEnv-GoogleRobot 基准对 PhysBrain 1.0 模型进行评估,并将其性能与多种现有方法进行对比。结果表明,PhysBrain 1.0 在评估任务中取得了最高的平均成功率,在大多数单项任务中超越所有其他方法,并在单物体操作与长周期任务中均展现出强劲性能。相较于其他所有方法,PhysBrain 1.0 在 SimplerEnv-GoogleRobot 基准上获得最高平均成功率。该模型在 Pick Coke Can 任务中取得最佳表现,并在 Move Near 与 Open/Close Drawer 任务中结果优异。PhysBrain 1.0 在所有单项任务中均超越排名第二的方法,表明其相较于现有方案具有持续且稳定的提升。
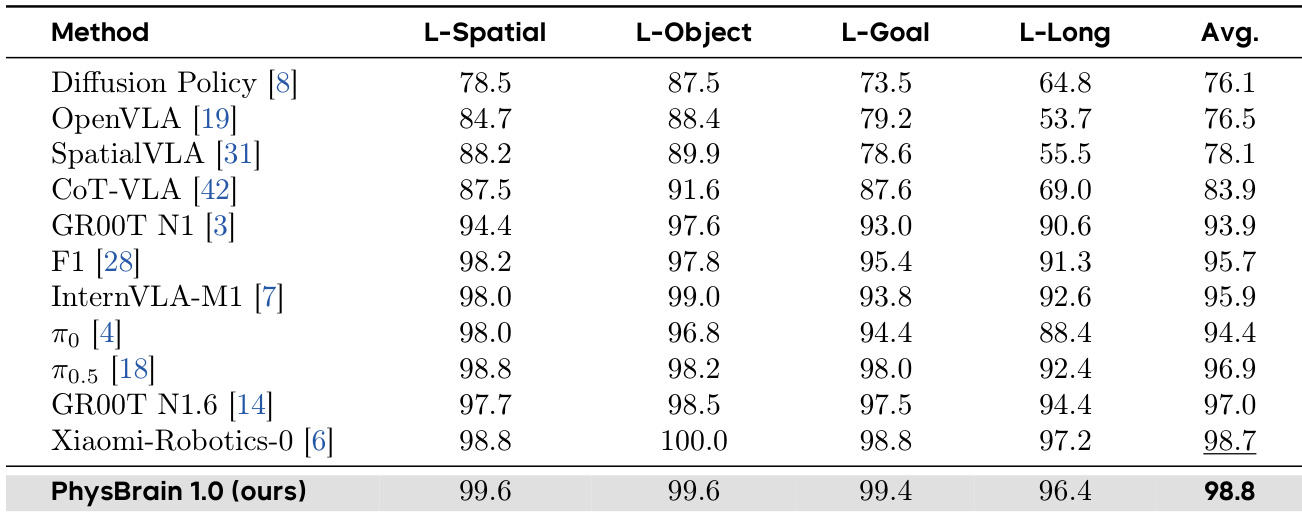
研究团队在 LIBERO 基准上评估了 PhysBrain 1.0 的性能,并将其与多款前沿 VLA 模型在四个任务套件中进行对比。结果表明,PhysBrain 1.0 取得了最高的平均成功率,超越所有列出的基线模型,并在所有单项任务类别中均展现出强劲性能。在 LIBERO 基准上,PhysBrain 1.0 的平均成功率位居榜首,领先于其他所有方法。该模型在包括 L-Spatial 与 L-Goal 在内的全部四个任务套件中均保持高水平表现。PhysBrain 1.0 在单物体操作与长周期任务中均显示出相较于先前方法的持续改进。
研究团队在多模态推理与具身控制任务上评估了 PhysBrain 系列模型,结果显示其在多个基准测试中均优于基线模型。结果表明,基于物理导向的视觉理解能力能够同时提升通用多模态性能与下游机器人适配效果,在不同机器人形态与任务类型中均带来稳定增益。PhysBrain 系列模型在多数视觉问答基准中取得最佳性能,展现出增强的物理推理与多模态理解能力。模型在不同机器人形态与操作任务中均表现出强大的域外泛化能力与持续改进趋势。PhysBrain 1.0 在所有评估的 VLA 基准上均超越强劲基线,涵盖配备灵巧手与复杂操作任务的场景。
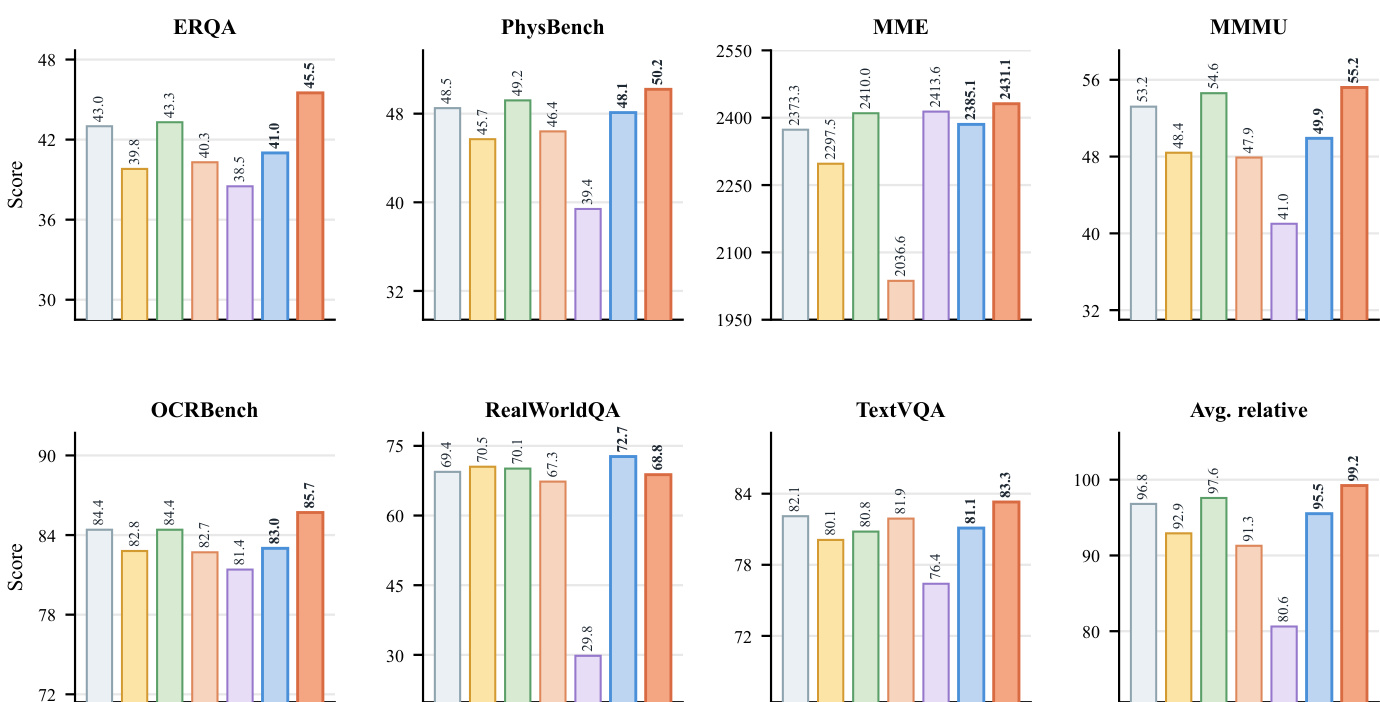
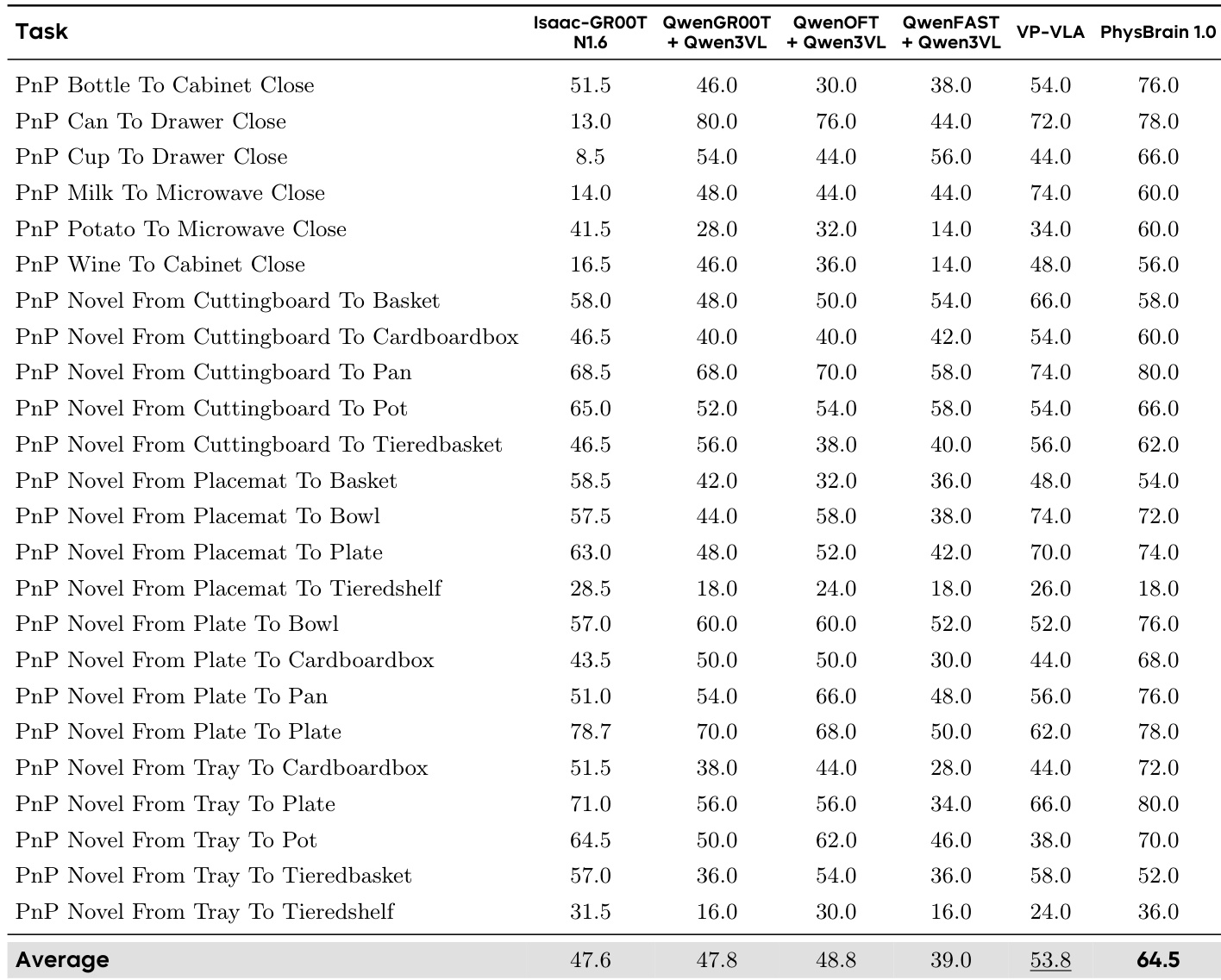
研究团队在多个仿真基准的具身控制任务中评估了 PhysBrain 1.0 的性能,验证了其在适配不同机器人形态与操作场景方面的有效性。结果表明,PhysBrain 1.0 在所有评估基准上均取得最高平均成功率,印证了其物理先验具备强大的泛化与迁移能力。该模型在所有基准任务中均获得最高平均成功率,超越所有其他方法。PhysBrain 1.0 在单物体操作与长周期操作任务中均对基线模型保持持续领先。模型在多样化机器人形态与任务分布中均取得优异表现,进一步表明其物理先验具备稳健的迁移特性。
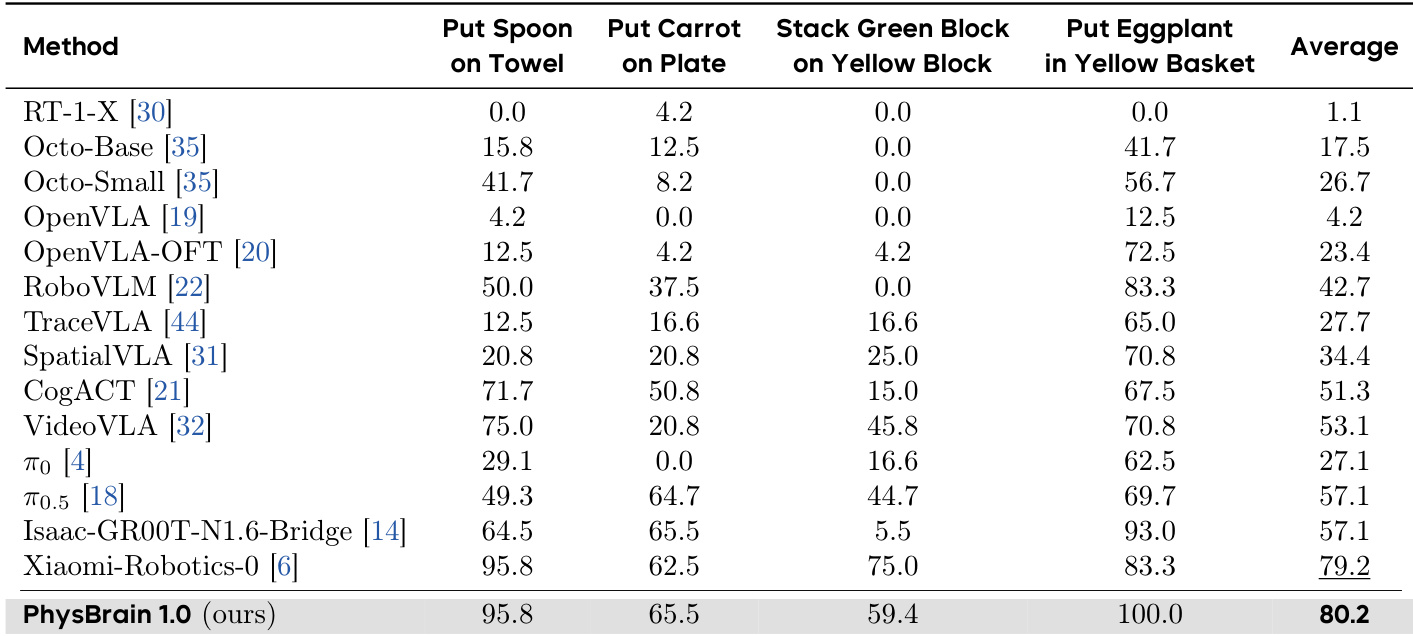
研究团队在 SimplerEnv-WidowX 仿真基准上评估了 PhysBrain 1.0 的性能,并将其与多款前沿 VLA 模型在多项操作任务中进行对比。结果表明,PhysBrain 1.0 取得了最高平均成功率,在大多数单项任务中超越所有其他方法,并在不同任务类型间展现出强大的泛化能力。在 SimplerEnv-WidowX 基准上,PhysBrain 1.0 的平均成功率位居首位,领先于所有对比方法。该模型在多个单项任务中取得顶尖表现,包括在 Put Eggplant in Yellow Basket 任务中达成 100% 成功率。PhysBrain 1.0 在多项关键任务中显著优于先前方法,表明其操作策略的泛化能力与鲁棒性得到进一步提升。
PhysBrain 1.0 模型在多种仿真环境与多模态推理基准上接受了全面评估,验证了其在单物体操作、长周期控制与跨形态泛化方面的有效性。在所有测试场景中,该模型持续超越前沿的视觉-语言-动作基线,在复杂操作设置中展现出卓越的物理推理能力与稳健的策略执行效率。这些结果共同表明,嵌入物理导向的视觉先验能够显著提升下游机器人适配效果,使模型能够在多样化的硬件配置与任务分布中实现可靠迁移。