HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

Memp:探索Agent程序记忆

Perch 2.0:对生物声学的鹬鸟启示




























Memp:探索Agent程序记忆
Perch 2.0:对生物声学的鹬鸟启示
我们在评估文档检索增强生成的正确道路上吗?
Hi3DEval:基于分层有效性的三维生成评估
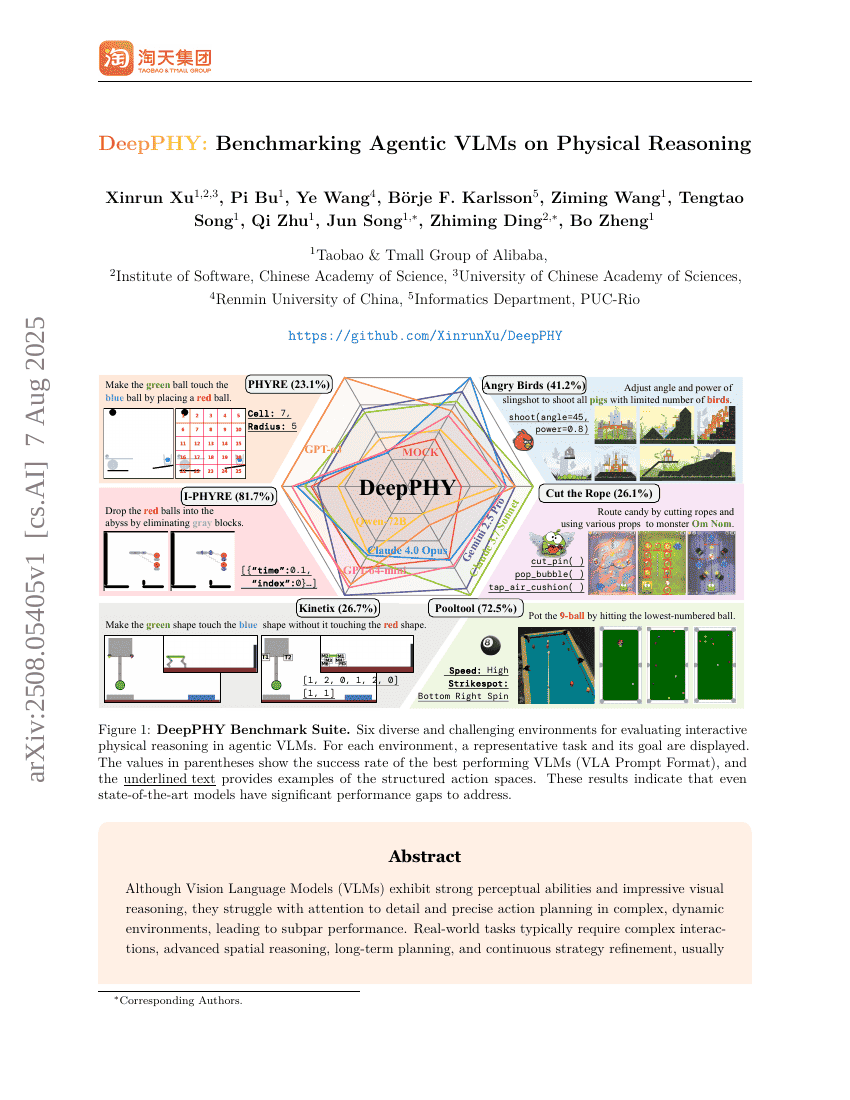
DeepPHY:面向物理推理的智能体视觉语言模型基准测试
Genie Envisioner:面向机器人操作的统一世界基础平台
R-Zero:从零数据自演化推理的LLM
监督微调的泛化:基于奖励修正的强化学习视角
利用LLM赋能的智能体模拟类人学习动态
GRAIL:用于检索增强推理的大型知识图谱交互学习
CoTox:基于思维链的分子毒性推理与预测
高效代理:在降低成本的同时构建有效代理
LLM 的思维链推理是一场幻觉吗?基于数据分布的视角
VeriGUI:可验证的长链GUI数据集
Qwen2.5-VL 技术报告
生成对抗网络已死;万岁,生成对抗网络!一种现代的生成对抗网络基线
MegaPairs:面向通用多模态检索的大规模数据合成
Lyra:一种高效且以语音为中心的全认知框架
通过模型、数据和测试时扩展,拓展开源多模态模型的性能边界
NVILA:高效前沿视觉语言模型
VisionZip:在视觉语言模型中,更长并不一定更好
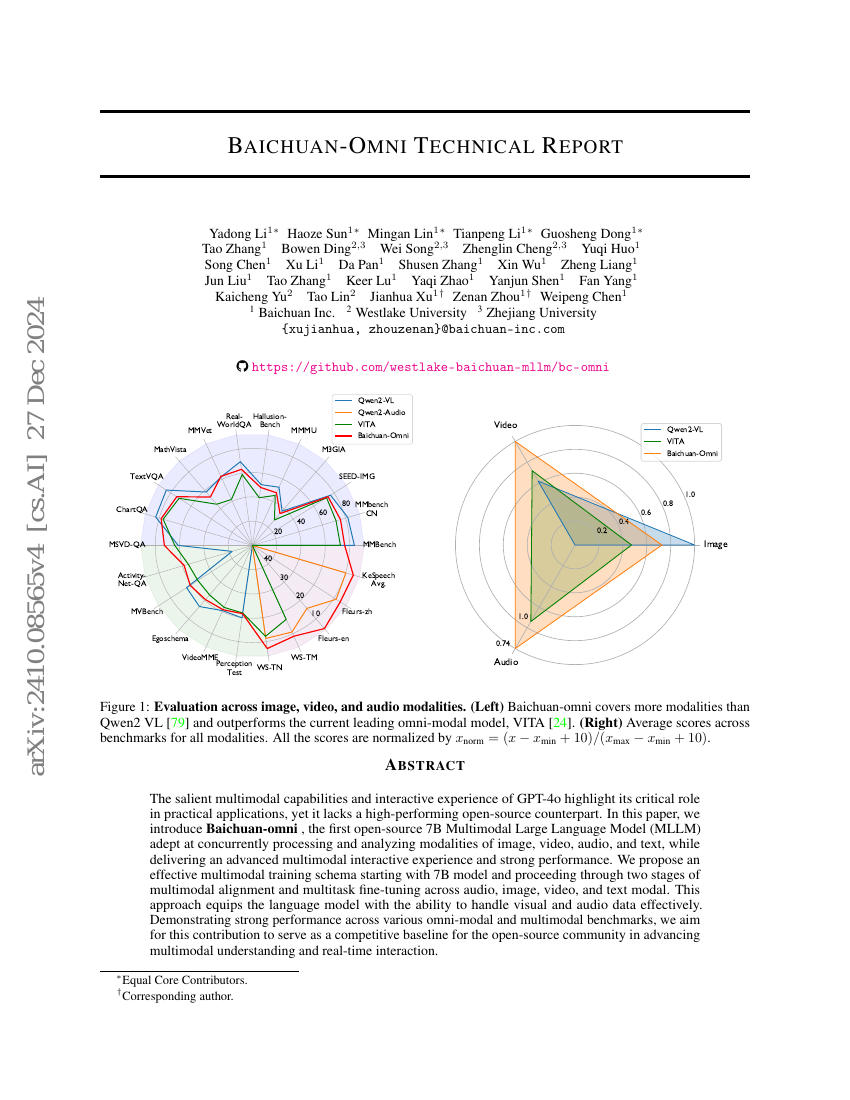
百川Omni技术报告
MM1.5:多模态LLM微调的方法、分析与洞见
Emu3:下一token预测就是你所需的一切
CogVLM2:用于图像与视频理解的视觉语言模型
Qwen2 技术报告
一张图像对于重建和生成而言价值32个token
自回归模型胜过扩散模型:Llama 实现可扩展的图像生成
Meteor:基于Mamba的大型语言与视觉模型推理路径遍历
FIFO-Diffusion:无需训练从文本生成无限视频
我们距离GPT-4V还有多远?通过开源套件缩小与商业多模态模型的差距
通过想象、搜索与批判实现LLM的自我改进
我们在评估文档检索增强生成的正确道路上吗?
Hi3DEval:基于分层有效性的三维生成评估
DeepPHY:面向物理推理的智能体视觉语言模型基准测试
Genie Envisioner:面向机器人操作的统一世界基础平台
R-Zero:从零数据自演化推理的LLM
监督微调的泛化:基于奖励修正的强化学习视角
利用LLM赋能的智能体模拟类人学习动态
GRAIL:用于检索增强推理的大型知识图谱交互学习
CoTox:基于思维链的分子毒性推理与预测
高效代理:在降低成本的同时构建有效代理
LLM 的思维链推理是一场幻觉吗?基于数据分布的视角
VeriGUI:可验证的长链GUI数据集
Qwen2.5-VL 技术报告
生成对抗网络已死;万岁,生成对抗网络!一种现代的生成对抗网络基线
MegaPairs:面向通用多模态检索的大规模数据合成
Lyra:一种高效且以语音为中心的全认知框架
通过模型、数据和测试时扩展,拓展开源多模态模型的性能边界
NVILA:高效前沿视觉语言模型
VisionZip:在视觉语言模型中,更长并不一定更好
百川Omni技术报告
MM1.5:多模态LLM微调的方法、分析与洞见
Emu3:下一token预测就是你所需的一切
CogVLM2:用于图像与视频理解的视觉语言模型
Qwen2 技术报告
一张图像对于重建和生成而言价值32个token
自回归模型胜过扩散模型:Llama 实现可扩展的图像生成
Meteor:基于Mamba的大型语言与视觉模型推理路径遍历
FIFO-Diffusion:无需训练从文本生成无限视频
我们距离GPT-4V还有多远?通过开源套件缩小与商业多模态模型的差距
通过想象、搜索与批判实现LLM的自我改进