Command Palette
Search for a command to run...
GMAI-MMBench Medical Multimodal Evaluation Benchmark Dataset
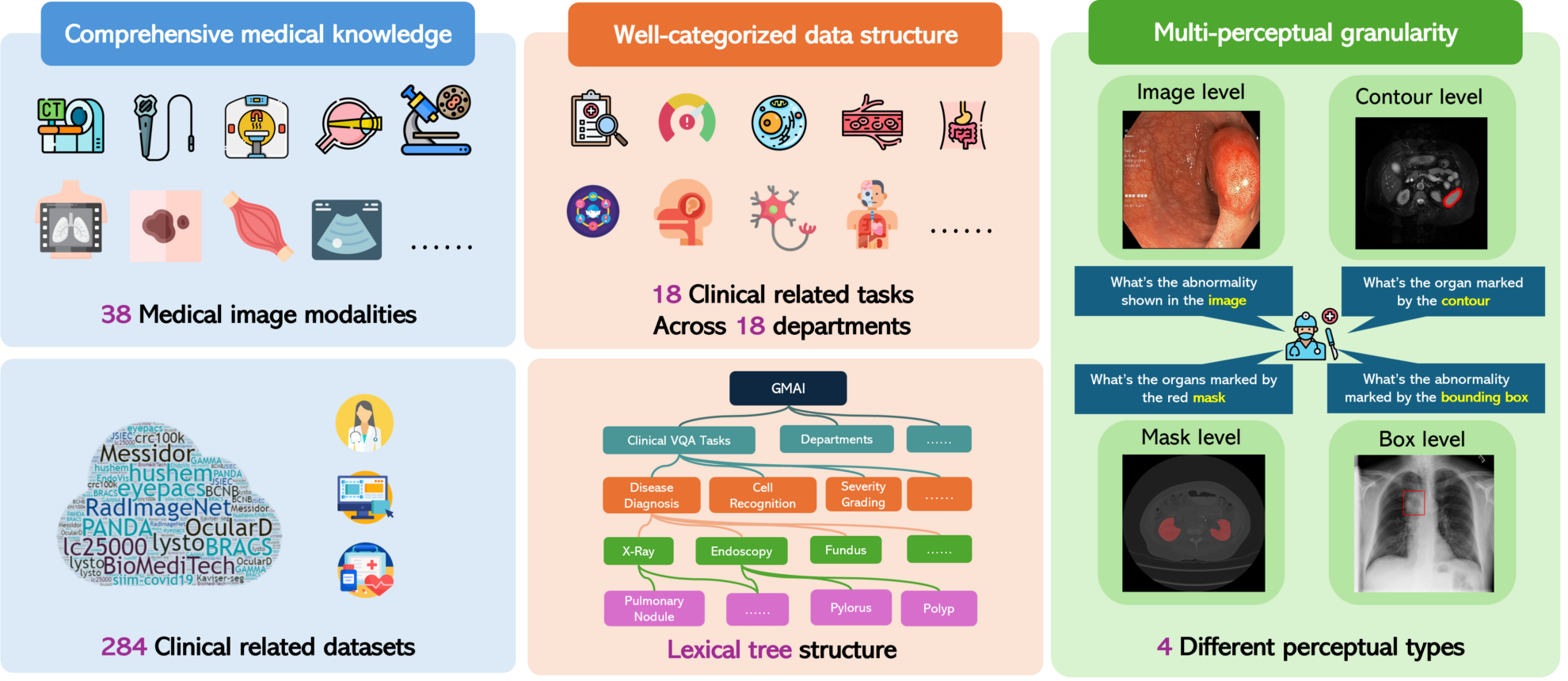
GMAI-MMBench is a multimodal evaluation benchmark designed to promote the development of general medical artificial intelligence. It was jointly launched in 2024 by nine institutions including Shanghai Artificial Intelligence Laboratory, University of Washington, Monash University, East China Normal University, University of Cambridge, Shanghai Jiao Tong University, The Chinese University of Hong Kong (Shenzhen), Shenzhen Institute of Big Data, and Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences.GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI". It helps researchers and developers gain in-depth understanding of the application effects of large visual language models (LVLMs) in the medical field and identify technical shortcomings by providing comprehensive and detailed evaluations. This benchmark covers a wide range of datasets, including 284 datasets from different sources, involving 38 medical image modalities and 18 clinically relevant tasks, covering 18 different medical departments, and evaluated at 4 different perceptual granularities, thereby considering the performance of LVLMs from multiple dimensions. A notable feature of GMAI-MMBench is its evaluation of multi-perceptual granularity, which not only focuses on the evaluation of the overall level of the image, but also goes deep into the regional level, providing a more detailed and comprehensive evaluation perspective. In addition, since the dataset mainly comes from hospitals and is annotated by professional doctors, the evaluation tasks of GMAI-MMBench are closer to real clinical scenarios and have a high degree of clinical relevance. This relevance makes the results of the benchmark test instructive for actual medical applications. GMAI-MMBench also allows users to customize evaluation tasks. By implementing a vocabulary tree structure, users can define evaluation tasks according to their needs, which provides flexibility for medical AI research and applications. The research team evaluated 50 LVLMs, including some advanced GPT-4o models, and found that even the most advanced models only achieved an accuracy of 52% in dealing with medical professional problems, indicating that the current LVLMs still have a lot of room for improvement in medical applications. The development of GMAI-MMBench provides a valuable resource for evaluating and improving the application of LVLMs in the medical field, while also revealing the challenges facing current technologies and pointing the way for future research.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.