Command Palette
Search for a command to run...
LightOnOCR-2-1B: High-precision end-to-end OCR Based on RLVR Training; Google Streetview National Street View Images: An open-source Panoramic Image Library Based on world-class Geomapping technology.

Currently, OCR technology relies on a complex, sequential pipeline: first, text regions are detected, then recognition is performed, and finally, post-processing is carried out.This model is cumbersome and fragile when dealing with documents with complex layouts and varied formats. Any error in any step can lead to poor overall results, and it is difficult to optimize end-to-end, resulting in high maintenance and adaptation costs.
In this context,LightOn has released the LightOnOCR-2-1B model as open source.This end-to-end vision-language model with only 1 billion parameters achieves new state-of-the-art (SOTA) performance on the authoritative benchmark OlmOCR-Bench, surpassing the previous best model with 9 billion parameters, while reducing size by 9 times and increasing inference speed by several times. LightOnOCR-2-1B uses a unified model to directly generate structured, ordered text and image bounding boxes from pixels. By integrating pre-trained components, high-quality distilled data, and strategies such as RLVR, it simplifies the process and significantly improves the efficiency of processing complex documents.
The "LightOnOCR-2-1B Lightweight High-Performance End-to-End OCR Model" is now available on the HyperAI website. Give it a try!
Online use:https://go.hyper.ai/8zlVw
A quick overview of hyper.ai's official website updates from February 2nd to February 6th:
* High-quality public datasets: 6
* A selection of high-quality tutorials: 9
* This week's recommended papers: 5
* Community article interpretation: 4 articles
* Popular encyclopedia entries: 5
Top conferences with February deadlines: 4
Visit the official website:hyper.ai
Selected public datasets
1. RubricHub Multi-Domain Generative Task Dataset
RubricHub is a large-scale, multi-domain generative task dataset jointly released by Li Auto and Zhejiang University. This dataset provides high-quality supervision based on scoring criteria for open-ended generative tasks. The dataset is constructed using an automated coarse-to-fine scoring criterion generation framework, integrating strategies such as principle-guided synthesis, multi-model aggregation, and difficulty evolution to produce comprehensive and highly discriminative evaluation criteria.
Direct use:https://go.hyper.ai/g3Htm
2. Nemotron-Personas-Brazil Brazilian Synthetic Character Dataset
Nemotron-Personas-Brazil is a synthetic character dataset for Brazil released by NVIDIA in collaboration with WideLabs. It aims to showcase the diversity and richness of Brazil's population to more comprehensively reflect the multidimensional potential population distribution, including regional diversity, ethnic background, education level, and occupational distribution.
Direct use:https://go.hyper.ai/7xKKH
3. CL-bench Context Learning Evaluation Benchmark
CL-bench is a benchmark dataset for evaluating the context learning capabilities of a large language model, jointly released by Tencent Hunyuan Team and Fudan University. It aims to test whether a model can learn new rules, concepts, or domain knowledge from a given context without relying on pre-trained knowledge and apply them to subsequent tasks.
Direct use:https://go.hyper.ai/w2MG3
4. RoVid-X Robot Video Generation Dataset
RoVid-X is a robot video generation dataset released by Peking University in collaboration with ByteDance Seed, aiming to address the physical challenges faced by video generation models when generating robot videos.
Direct use:https://go.hyper.ai/4P9hI
5. Google Streetview National Street View Image Dataset
Google Streetview is a dataset of street view images covering multiple countries. The image filenames include the creation date and map name, and the images for each country are placed in their respective folders.
Direct use:https://go.hyper.ai/tZRlI

6. DeepPlanning Long-Term Planning Capability Assessment Dataset
DeepPlanning is a dataset released by the Qwen team to evaluate the planning capabilities of intelligent agents, aiming to assess their reasoning and decision-making abilities in complex, long-term planning tasks.
Direct use:https://go.hyper.ai/yywsb
Selected Public Tutorials
1. Deploy Qwen-Image-Edit using vLLM-Omni
Qwen-Image-Edit is a multi-functional image editing model released by Alibaba's Tongyi Qianwen team. This model possesses both semantic and visual editing capabilities, enabling low-level visual appearance editing such as adding, removing, or modifying elements, as well as high-level visual semantic editing such as IP creation, object rotation, and style transfer. The model supports precise editing of both Chinese and English text, allowing direct modification of text content within images while preserving the original font, size, and style.
Run online:https://go.hyper.ai/DowYs
2. Deploy Qwen-Image-2512 using vLLM-Omni
Qwen-Image-2512 is the foundational text-to-image model in the Qwen-Image series. Compared to previous versions, Qwen-Image-2512 has undergone systematic optimization in several key dimensions, with a focus on improving the overall realism and usability of generated images. The naturalness of portrait generation is significantly enhanced, with facial structure, skin texture, and lighting relationships more closely resembling realistic photographic effects. In natural scenes, the model can generate more detailed terrain textures, vegetation details, and high-frequency information such as animal fur. Simultaneously, its text generation and typography capabilities have been improved, enabling more stable presentation of readable text and complex layouts.
Run online:https://go.hyper.ai/Xk93p
3. Step3-VL-10B: Multimodal Visual Understanding and Graphical Dialogue
STEP3-VL-10B is an open-source visual language model developed by the Stepping Star team, designed specifically for multimodal understanding and complex reasoning tasks. This model aims to redefine the balance between efficiency, reasoning ability, and visual understanding quality within a limited parameter scale of 10 billion (10B). It demonstrates superior performance in visual perception, complex reasoning, and human instruction alignment, consistently outperforming models of similar scale in multiple benchmark tests and comparable to models with 10-20 times larger parameter scales on some tasks.
Run online:https://go.hyper.ai/ZvOV0
4.vLLM+Open WebUI Deployment of GLM-4.7-Flash
GLM-4.7-Flash is a lightweight MoE inference model launched by Zhipu AI, designed to achieve a balance between high performance and high throughput. It natively supports thought chains, tool calls, and agent capabilities. It adopts a hybrid expert architecture and utilizes sparse activation mechanisms to significantly reduce the computational overhead of a single inference while maintaining the performance of large models.
Run online:https://go.hyper.ai/bIopo

5. LightOnOCR-2-1B Lightweight, High-Performance End-to-End OCR Model
LightOnOCR-2-1B is the latest generation of end-to-end visual language recognition (OCR) model released by LightOn AI. As the flagship version in the LightOnOCR series, it unifies document understanding and text generation into a compact architecture, boasts 1 billion parameters, and can run on consumer-grade GPUs (requiring approximately 6GB of VRAM). This model employs a visual language Transformer architecture and incorporates RLVR training technology, achieving extremely high recognition accuracy and inference speed. It is specifically designed for applications requiring the processing of complex documents, handwritten text, and LaTeX formulas.
Run online:https://go.hyper.ai/8zlVw
6.vLLM+Open WebUI Deployment of LFM2.5-1.2B-Thinking
LFM2.5-1.2B-Thinking is the latest edge-optimized hybrid architecture model released by Liquid AI. As a version in the LFM2.5 series specifically optimized for logical inference, it unifies long sequence processing and efficient inference capabilities in a compact architecture. The model has 1.2 billion parameters and can run smoothly on consumer-grade GPUs and even edge devices. It employs an innovative hybrid architecture, achieving extreme memory efficiency and throughput, and is designed for scenarios requiring real-time inference on-device devices without sacrificing intelligence.
Run online:https://go.hyper.ai/PACIr
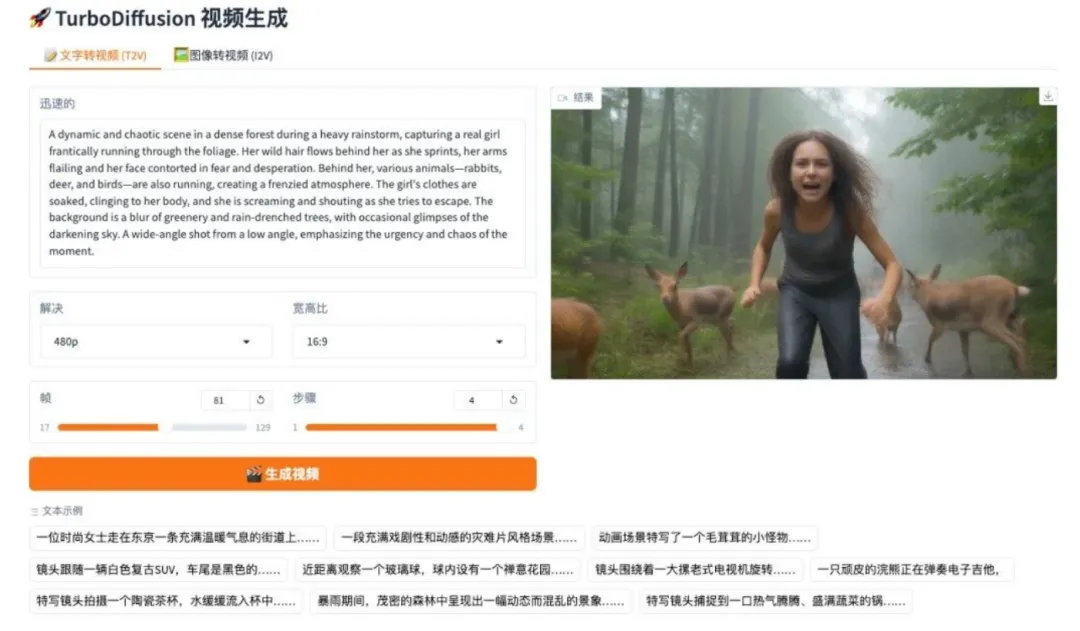
7. TurboDiffusion: Image and Text-Driven Video Generation System
TurboDiffusion is a high-efficiency video diffusion generation system developed by a team from Tsinghua University. Based on a 2.1 architecture, this project utilizes high-order distillation to address the pain points of slow inference speed and high computational resource consumption in large-scale video models, achieving high-quality video generation in minimal steps.
Run online:https://go.hyper.ai/YjCht
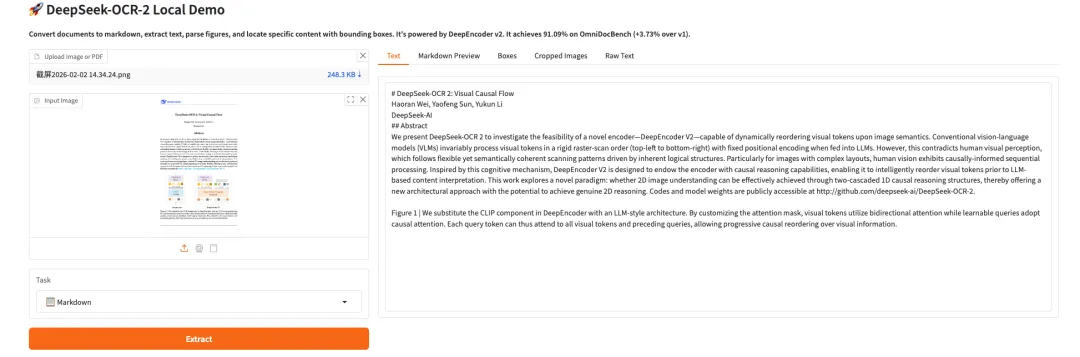
8. DeepSeek-OCR 2 Visual Causal Flow
DeepSeek-OCR 2 is the second-generation OCR model released by the DeepSeek team. By introducing the DeepEncoder V2 architecture, it achieves a paradigm shift from fixed scanning to semantic reasoning. The model employs causal stream querying and a dual-stream attention mechanism to dynamically reorder visual tokens, more accurately reconstructing the natural reading logic of complex documents. In the OmniDocBench v1.5 evaluation, the model achieved a comprehensive score of 91.09%, a significant improvement over its predecessor, while also greatly reducing the repetition rate of OCR results, providing a new path for building a full-modal encoder in the future.
Run online:https://go.hyper.ai/ITInm
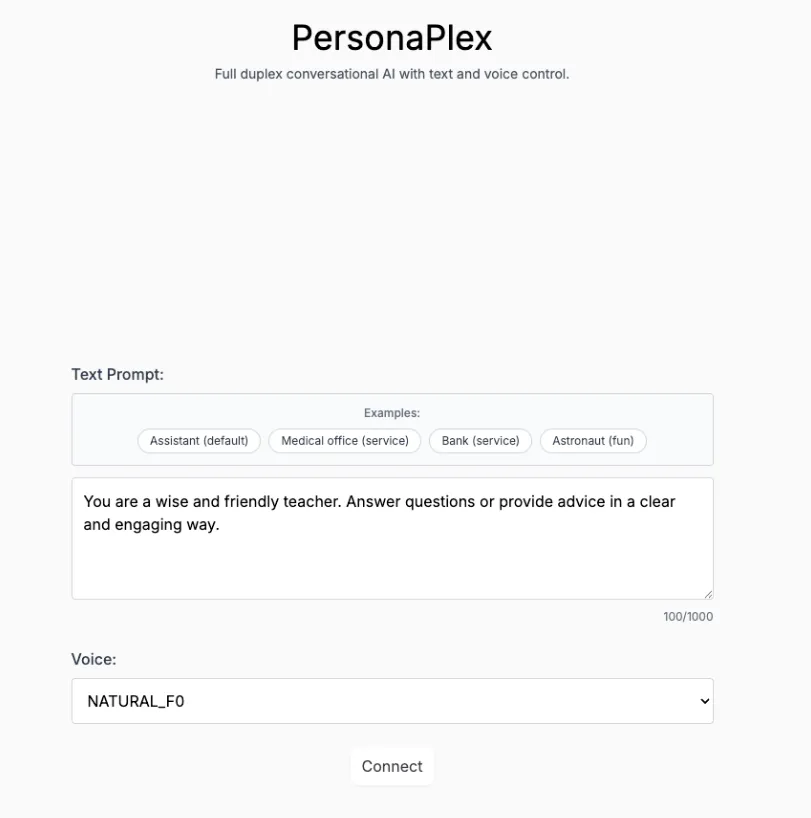
9. Personaplex-7B-v1: Real-time dialogue and character-customized voice interface
PersonaPlex-7B-v1 is a 7 billion parameter multimodal personalized dialogue model released by NVIDIA. It is designed for real-time voice/text interaction, long-term persona consistency simulation, and multimodal perception tasks, aiming to provide an immersive role-playing and multimodal interaction demonstration system with millisecond-level response speed.
Run online:https://go.hyper.ai/ndoj0
This week's paper recommendation
1. Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
This paper proposes MATTRL, a test-time reinforcement learning framework that enhances multi-agent reasoning by injecting structured textual experience into the reasoning process. It achieves consensus through multi-expert team collaboration and round-by-round credit allocation, and achieves robust performance improvements on medical, mathematical, and educational benchmarks without the need for retraining.
Paper link:https://go.hyper.ai/ENmkT
2. A^3-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
This paper proposes A³-Bench, a dual-scale memory-driven scientific reasoning benchmark. It evaluates the activation of anchors and attractors using the SAPM annotation framework and the AAUI metric, revealing how memory utilization can enhance reasoning consistency beyond standard coherence or answer accuracy.
Paper link:https://go.hyper.ai/Ao5t9
3. PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
This paper proposes PaCoRe, a parallel collaborative inference framework that achieves massive scaling of test-time computation (TTC) through message passing between multiple rounds of parallel inference trajectories. It outperforms GPT-5 (93.2%) with an accuracy of 94.5% on HMMT 2025. It efficiently integrates the inference process of millions of tokens within a fixed context constraint, while open-sourcing the model and data to promote the development of scalable inference systems.
Paper link:https://go.hyper.ai/fQrnt
4. Motion Attribution for Video Generation
This paper proposes Motive, a motion-centric gradient-based data attribution framework that separates temporal dynamics from static appearance through a motion-weighted loss mask. This enables scalable recognition of segments that influence fine-tuning, thereby improving motion smoothness and physical plausibility in text-to-video generation. It achieves a human preference win rate of 74.11 TP3T on VPench.
Paper link:https://go.hyper.ai/2pU21
5. VIBE: Visual Instruction Based Editor
This paper proposes VIBE, a compact instruction-based image editing workflow that uses a 2 billion parameter Qwen3-VL model for guidance and a 1.6 billion parameter Sana1.5 diffusion model for generation. It achieves high-quality editing that strictly maintains the consistency of the source image with extremely low computational cost. It runs efficiently on 24GB of GPU memory and generates a 2K image on an H100 in only about 4 seconds, achieving performance that meets or exceeds that of larger baseline models.
Paper link:https://go.hyper.ai/8YMEO
Community article interpretation
1. After traversing 100 million data points from the Hubble Space Telescope in 3 days, the European Space Agency proposed AnomalyMatch, discovering over a thousand anomalous celestial objects.
Currently, large-scale sky surveys with multi-band, wide field of view, and high depth are propelling astronomy into an unprecedented data-intensive era. One of its core scientific potentials lies in the systematic discovery and identification of rare celestial objects with special astrophysical value. However, their discovery has long relied heavily on researchers' accidental visual identification or manual screening by citizen science projects. These methods are not only highly subjective and inefficient, but also ill-suited to the massive scale of data to come. To address this deficiency, a research team at the European Space Astronomy Centre (ESAC), a branch of the European Space Agency (ESA), proposed and applied a new method called AnomalyMatch.
View the full report:https://go.hyper.ai/Jm3aq
2. Dataset Summary | 16 embodied intelligence datasets covering grasping, question answering, logical reasoning, trajectory reasoning, and other fields.
If the main battleground for artificial intelligence over the past decade has been "understanding the world" and "generating content," then the core issue of the next stage is shifting to a more challenging proposition: how can AI truly enter the physical world and act, learn, and evolve within it? In related research and discussions, the term "embodied intelligence" appears frequently. As the name suggests, embodied intelligence is not a traditional robot, but rather emphasizes the intelligence formed by the interaction between the agent and the environment within a closed loop of perception, decision-making, and action. This article will systematically organize and recommend all currently available high-quality datasets related to embodied intelligence, providing a reference for further learning and research.
View the full report:https://go.hyper.ai/lsCyF
3. Online Tutorial | DeepSeek-OCR 2 Formula/Table Parsing Improvements Achieve a Performance Leap of Nearly 4% with Low Visual Token Cost
In the development of Visual Language Models (VLMs), document OCR has always faced core challenges such as complex layout parsing and semantic logic alignment. How to enable models to "understand" visual logic like humans has become a key breakthrough in improving document comprehension capabilities. Recently, DeepSeek-AI's DeepSeek-OCR 2 provides a new answer. Its core is the adoption of the new DeepEncoder V2 architecture: the model abandons the traditional CLIP visual encoder and introduces an LLM-style visual encoding paradigm. Through the fusion of bidirectional attention and causal attention, it achieves semantic-driven rearrangement of visual tokens, constructing a new path of "two-stage 1D causal reasoning" for 2D image understanding.
View the full report:https://go.hyper.ai/nMH13
4. Covering 19 scenarios including astrophysics, earth science, rheology, and acoustics, Polymathic AI constructs 1.3B models to achieve accurate continuous medium simulation.
In the fields of scientific computing and engineering simulation, how to efficiently and accurately predict the evolution of complex physical systems has always been a core challenge for both academia and industry. Meanwhile, breakthroughs in deep learning in natural language processing and computer vision have prompted researchers to explore the potential applications of "foundational models" in physical simulations. However, physical systems often evolve across multiple time and spatial scales, while most learning models are typically trained only on short-term dynamics. Once used for long-term predictions, errors accumulate in complex systems, leading to model instability. Building on this, a research team from the Polymathic AI Collaboration proposed Walrus, a foundational model with 1.3 billion parameters, a Transformer-based architecture, and primarily designed for fluid-like continuum dynamics.
View the full report:https://go.hyper.ai/MJrny
Popular Encyclopedia Articles
1. Reverse sorting combined with RRF
2. Kolmogorov-Arnold Representation Theorem
3. Large-scale multi-task language understanding MMLU
4. BlackBox Optimizers
5. Class-conditional probability
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








