This tutorial uses a single RTX 4090 computing resource, and the model only supports English speech recognition.
Parakeet-tdt-0.6b-v2 is a high-performance Automatic Speech Recognition (ASR) model with 600 million parameters, open-sourced by NVIDIA in May 2025. It is the latest version in the Parakeet series. Based on the FastConformer encoder architecture and TDT decoder, this model can efficiently transcribe English audio segments up to 24 minutes long in a single pass. It focuses on high-precision, low-latency English speech transcription tasks and is suitable for real-time English speech-to-text scenarios (such as customer service dialogues, meeting minutes, and voice assistants). Related research papers are available. Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition .
2. Operation steps
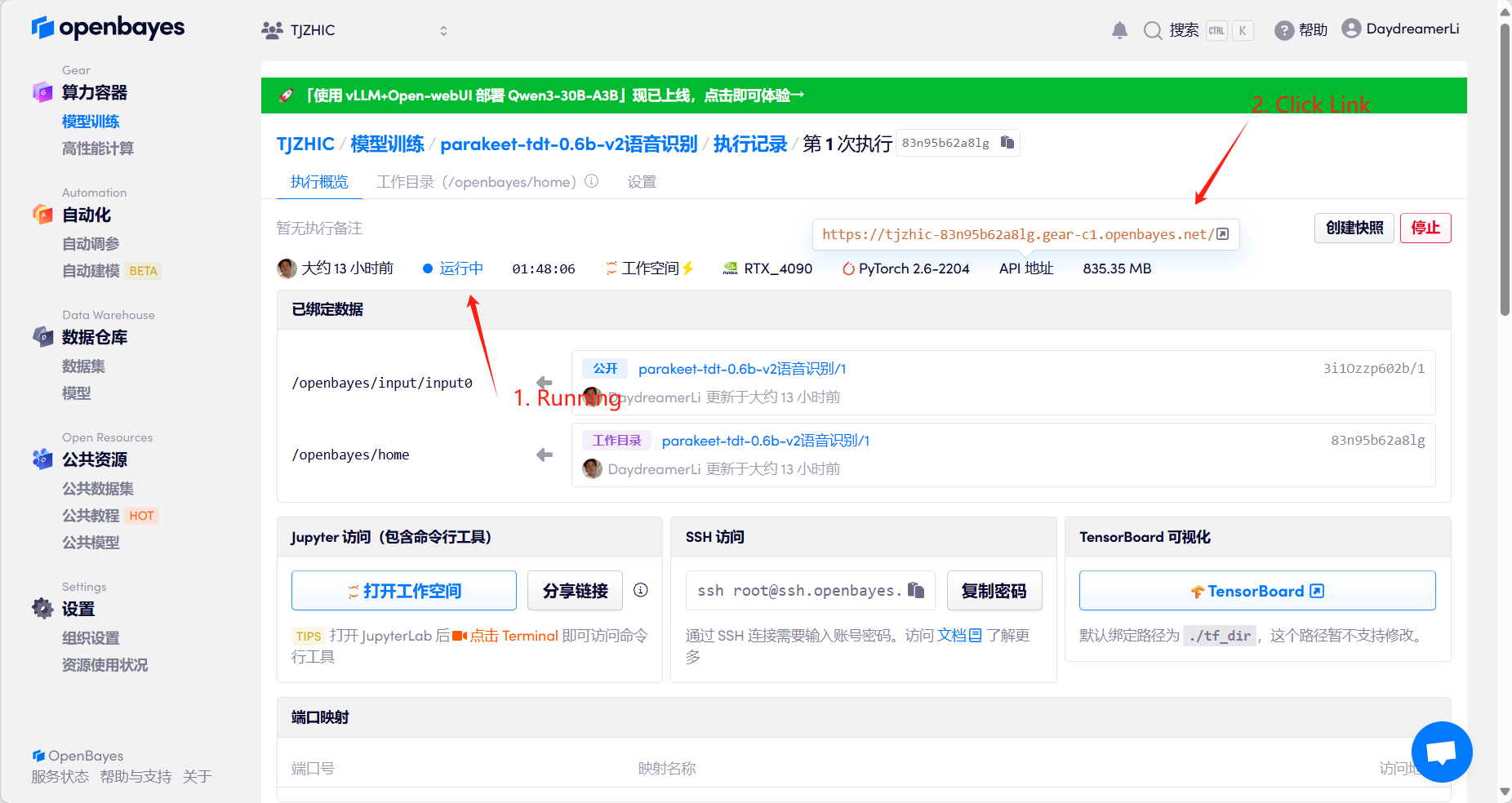
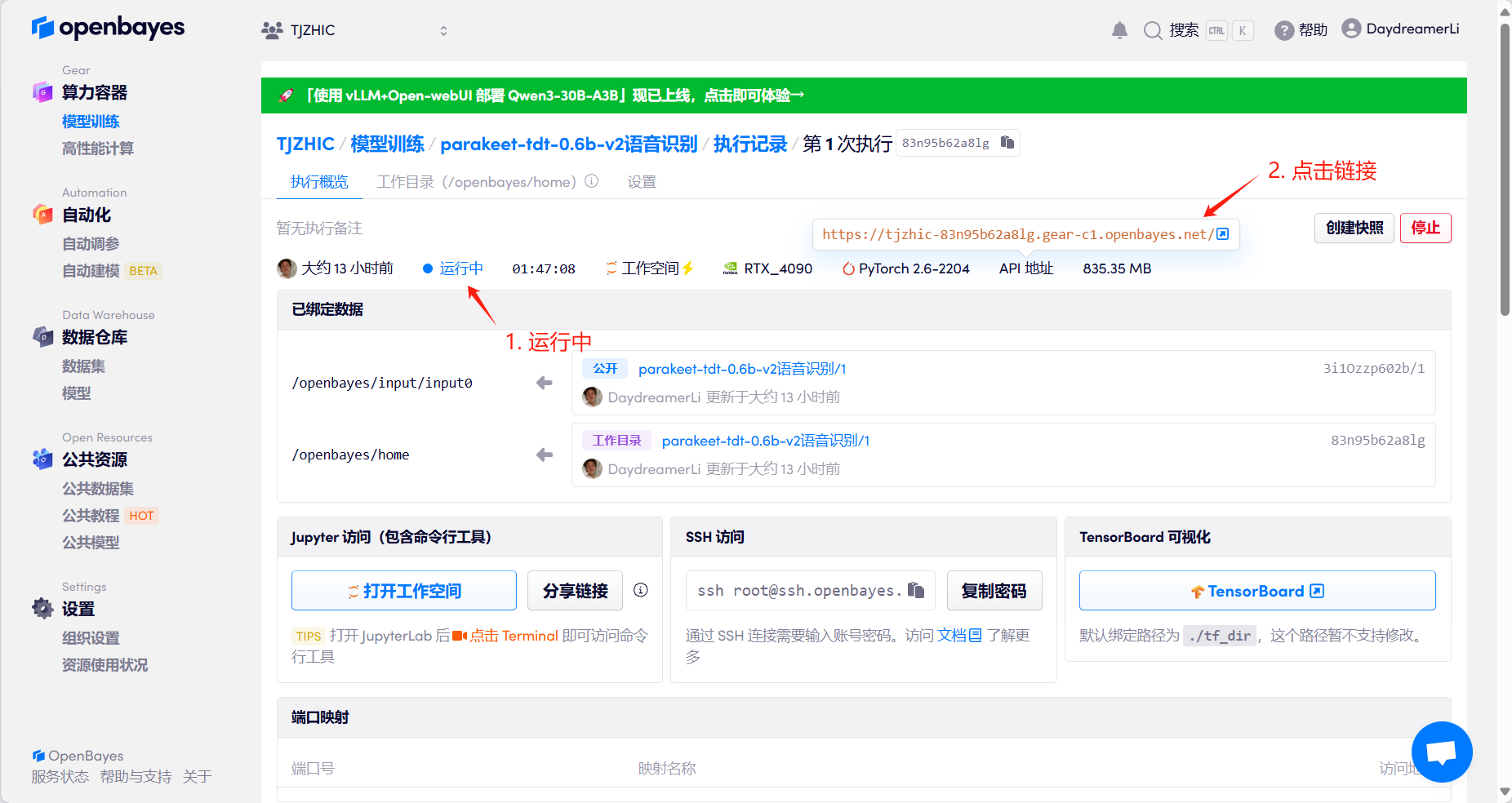
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
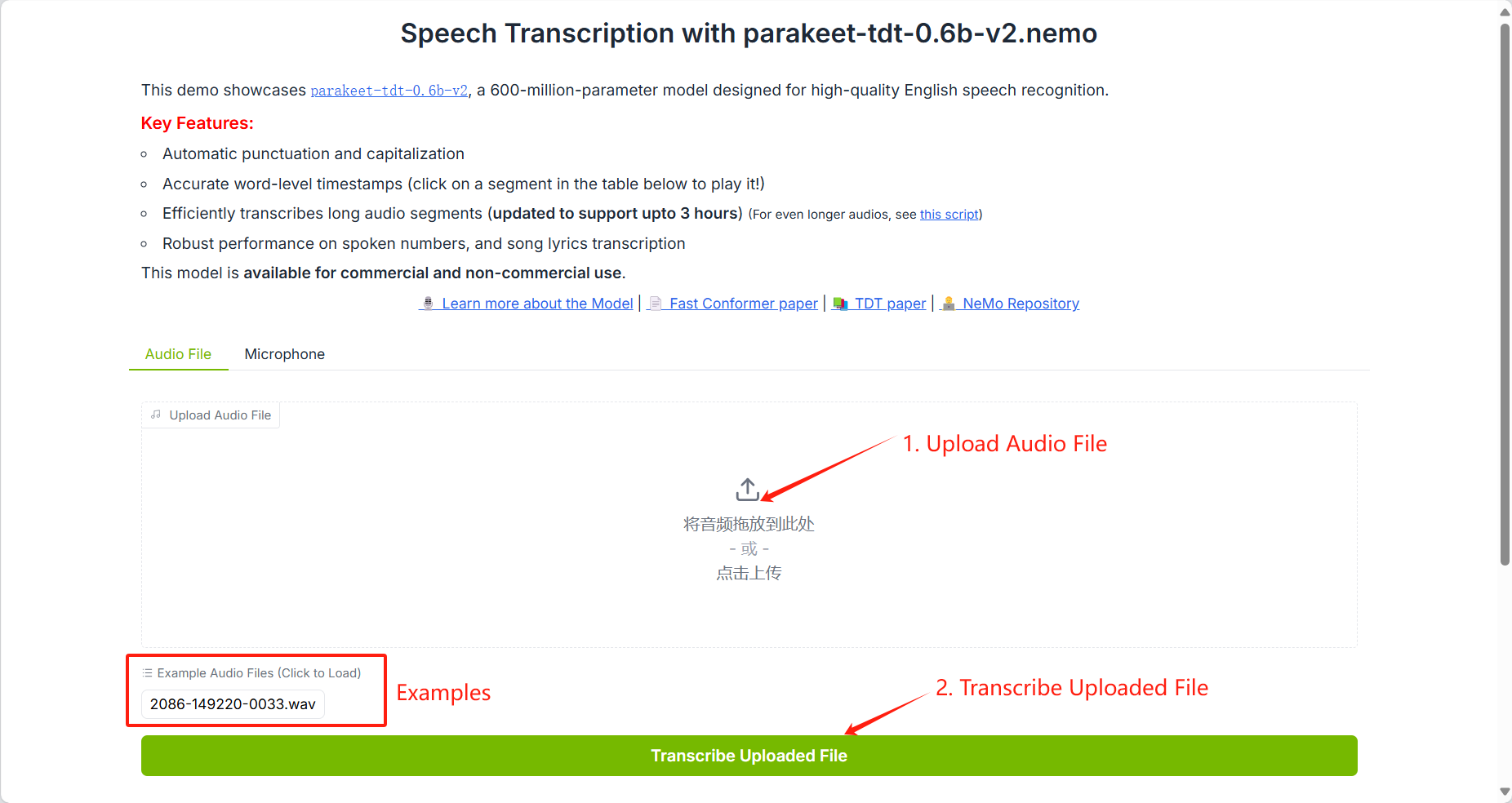
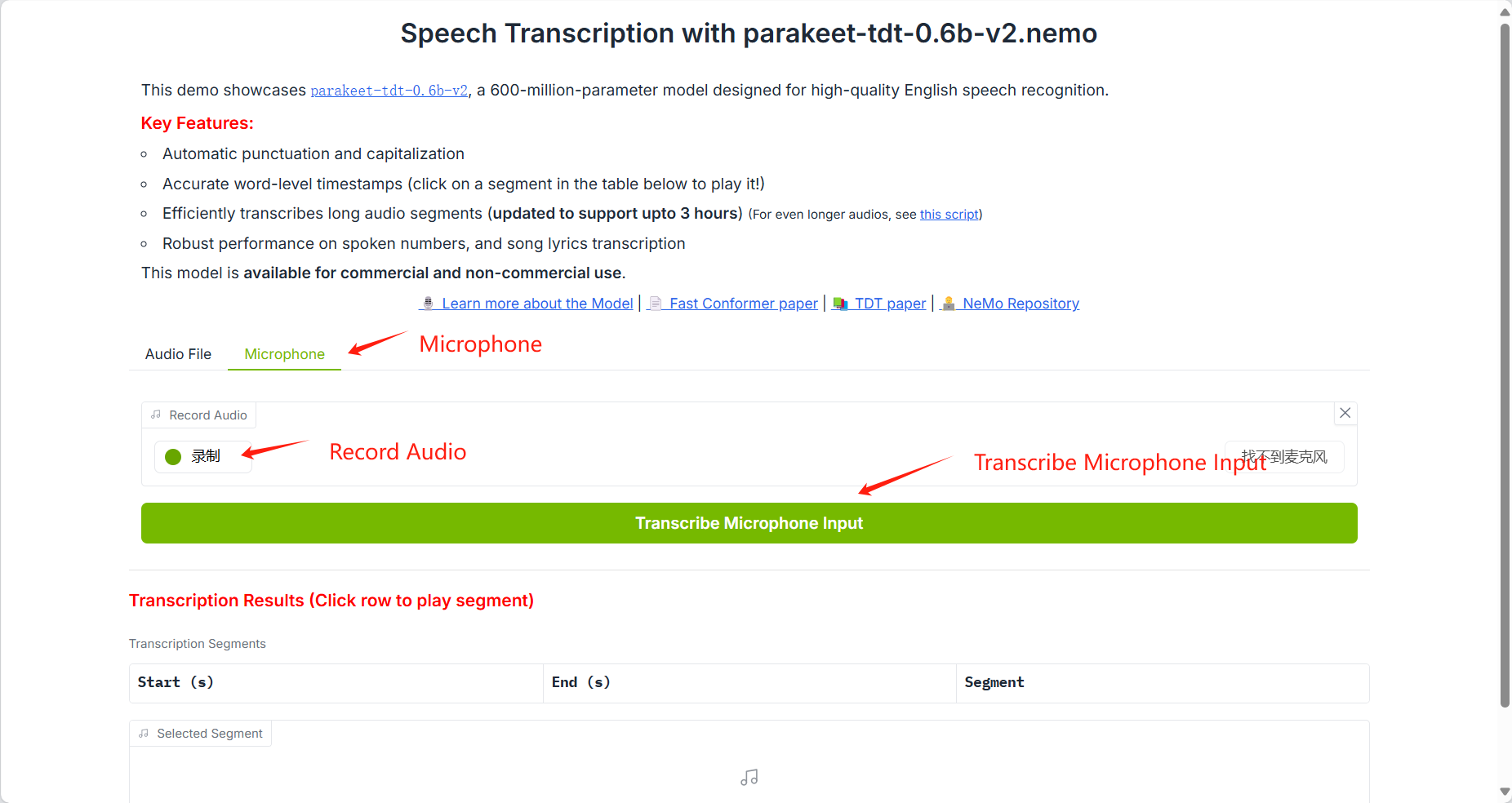
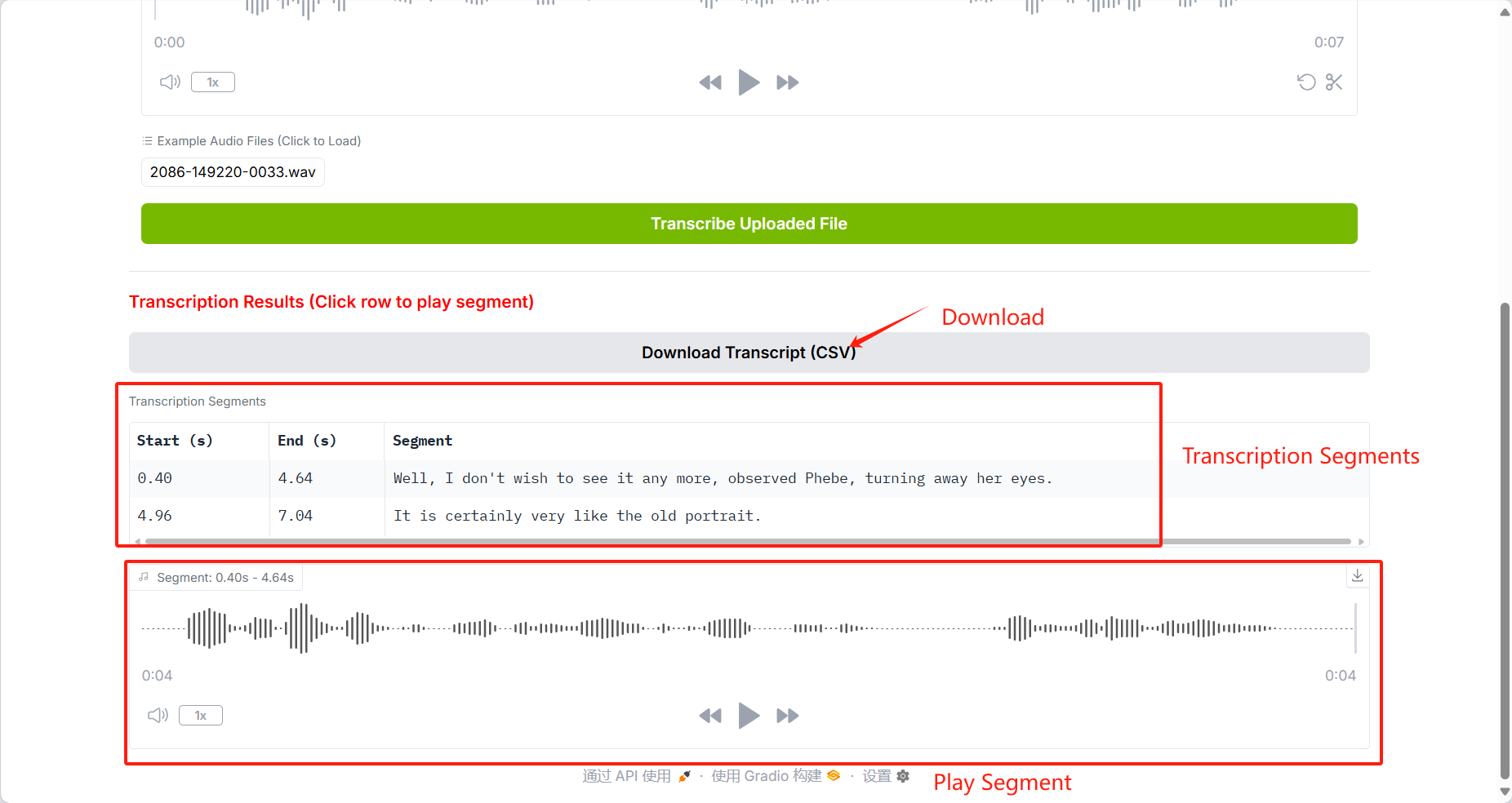
2. Use Demonstration
When using the Safari browser, audio may not play directly.
In addition to supporting uploading voice files, this tutorial also supports voice input.
Recognition results can be saved as CSV files
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Project Support
Thanks to Github user SuperYang Deployment of this tutorial.
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at support@hyper.ai for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
This tutorial uses a single RTX 4090 computing resource, and the model only supports English speech recognition.
Parakeet-tdt-0.6b-v2 is a high-performance Automatic Speech Recognition (ASR) model with 600 million parameters, open-sourced by NVIDIA in May 2025. It is the latest version in the Parakeet series. Based on the FastConformer encoder architecture and TDT decoder, this model can efficiently transcribe English audio segments up to 24 minutes long in a single pass. It focuses on high-precision, low-latency English speech transcription tasks and is suitable for real-time English speech-to-text scenarios (such as customer service dialogues, meeting minutes, and voice assistants). Related research papers are available. Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition .
2. Operation steps
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
2. Use Demonstration
When using the Safari browser, audio may not play directly.
In addition to supporting uploading voice files, this tutorial also supports voice input.
Recognition results can be saved as CSV files
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓
Project Support
Thanks to Github user SuperYang Deployment of this tutorial.
This notebook is contributed by community users and is intended for educational and informational purposes only. If any content involves copyright infringement, please contact us at support@hyper.ai for prompt review and removal.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.