Command Palette
Search for a command to run...
vLLM+Open WebUI Deployment MiniCPM4-8B
An error occurred in the Server Components render. The specific message is omitted in production builds to avoid leaking sensitive details. A digest property is included on this error instance which may provide additional details about the nature of the error.
Failed to load notebook details1. Tutorial Introduction

MiniCPM 4.0, launched by OpenBMB on June 6, 2025, is a high-performance edge-side Large Language Model (LLM). Through sparse architecture, quantization compression, and an efficient inference framework, it achieves high-performance inference with low computational cost, making it particularly suitable for long text processing, privacy-sensitive scenarios, and edge computing device deployment. MiniCPM4-8B demonstrates significantly faster processing speed compared to Qwen3-8B when handling long sequences. Related research papers are available. MiniCPM4: Ultra-Efficient LLMs on End Devices .
This tutorial uses resources for a single RTX 4090 card.
2. Project Examples
3. Operation steps
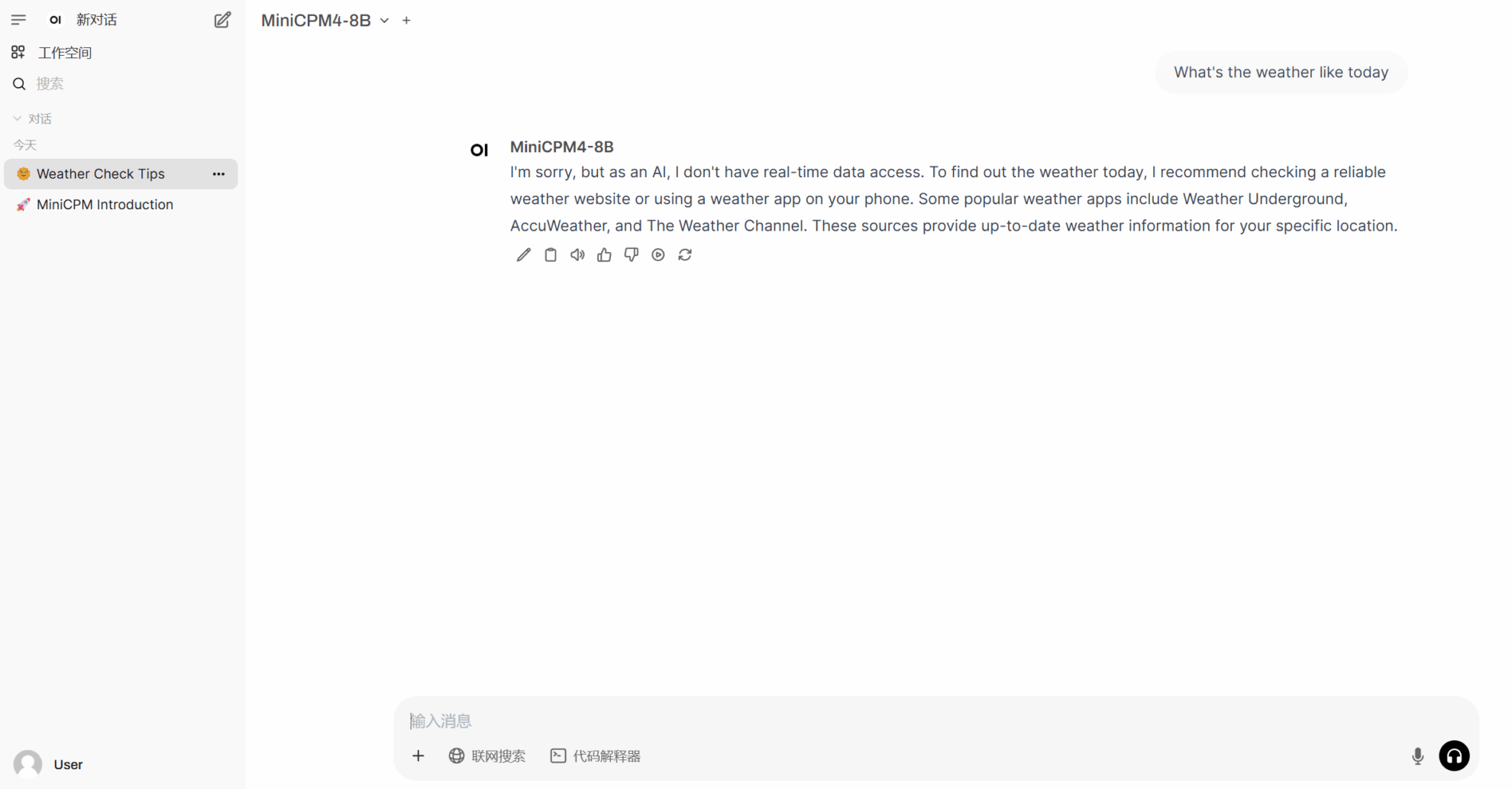
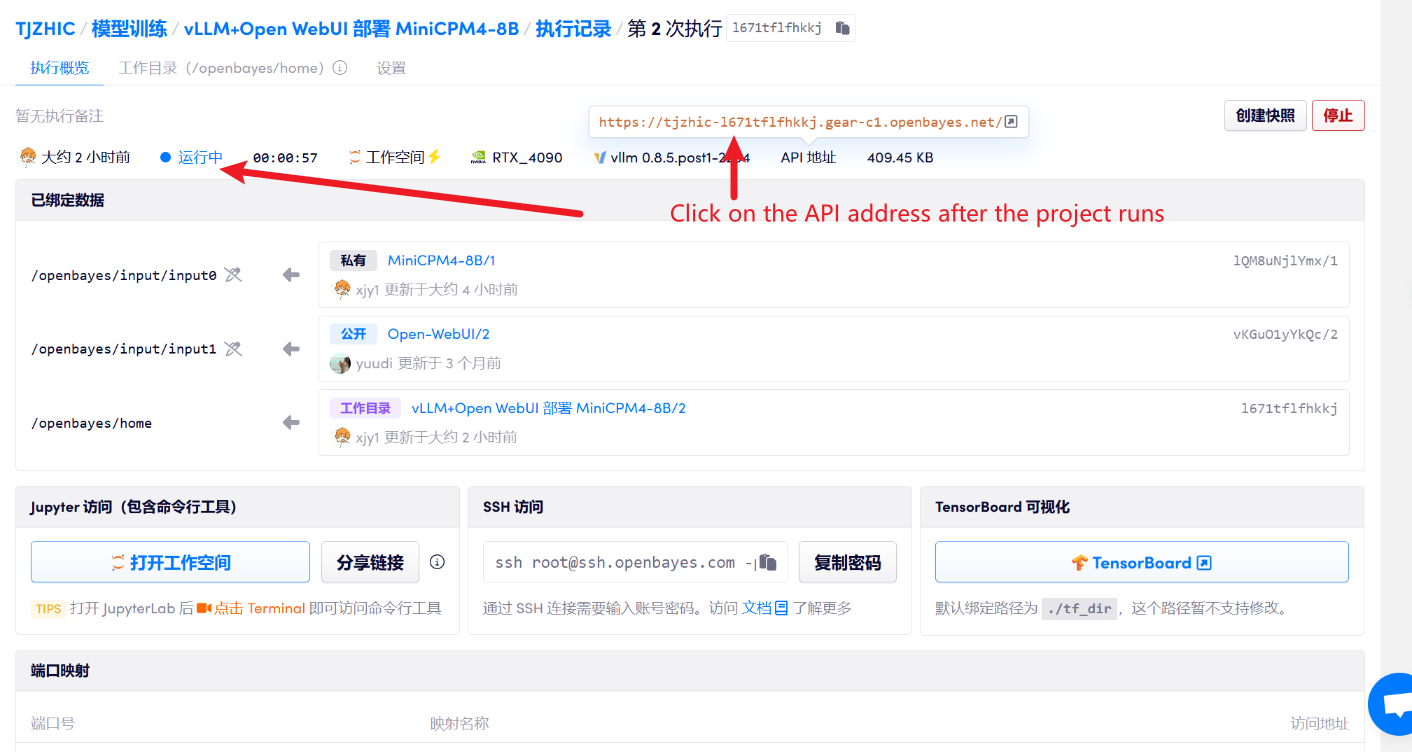
1. After starting the container, click the API address to enter the Web interface
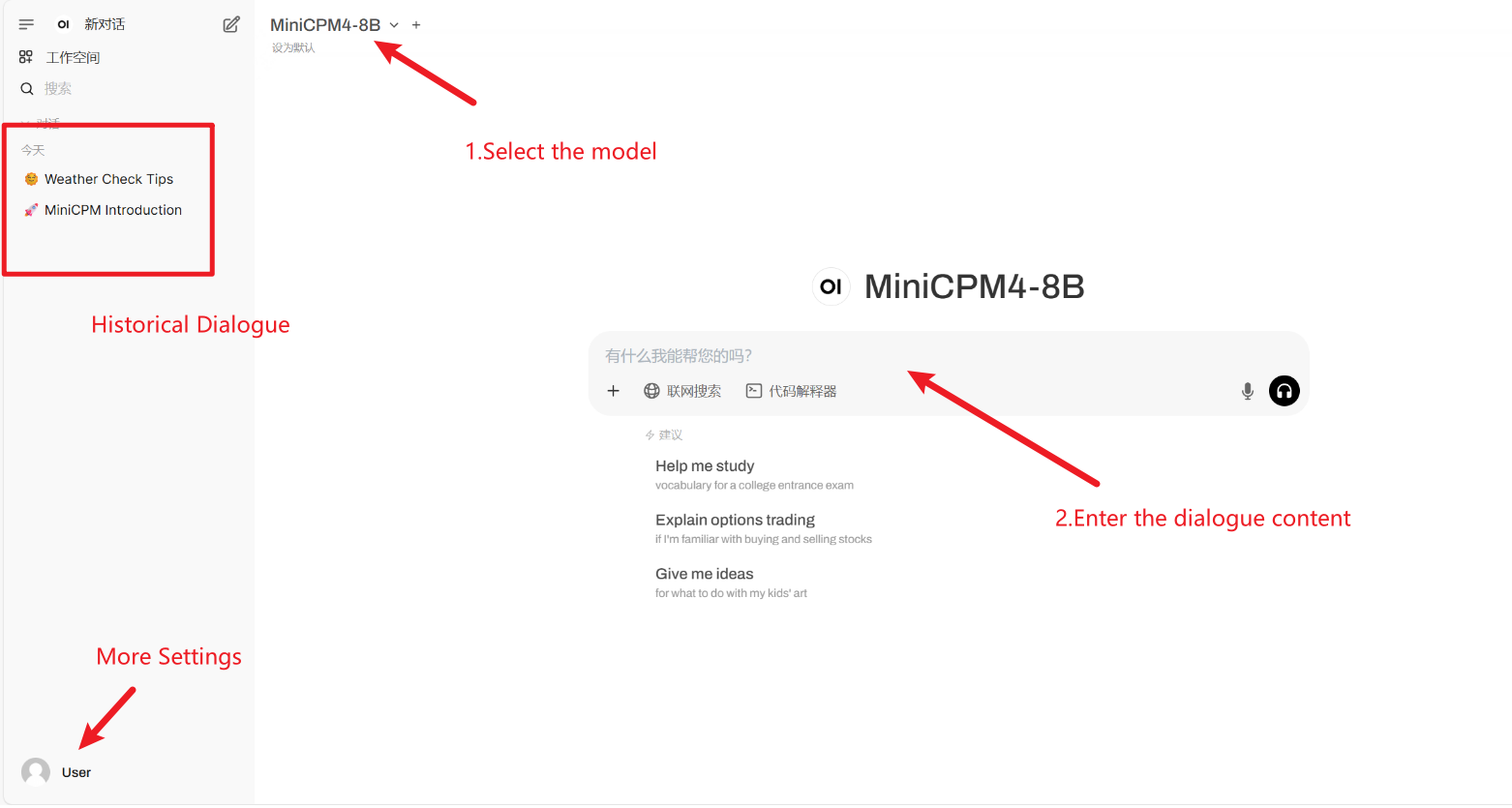
2. After entering the webpage, you can start a conversation with the model
If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 2-3 minutes and refresh the page.
How to use
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
Thanks to Github user xxxjjjyyy1 Deployment of this tutorial. The reference information of this project is as follows:
@article{minicpm4,
title={MiniCPM4: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
@inproceedings{huminicpm,
title={MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies},
author={Hu, Shengding and Tu, Yuge and Han, Xu and Cui, Ganqu and He, Chaoqun and Zhao, Weilin and Long, Xiang and Zheng, Zhi and Fang, Yewei and Huang, Yuxiang and others},
booktitle={First Conference on Language Modeling},
year={2024}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.