Command Palette
Search for a command to run...
One-click Deployment of VideoLLaMA3-7B
An error occurred in the Server Components render. The specific message is omitted in production builds to avoid leaking sensitive details. A digest property is included on this error instance which may provide additional details about the nature of the error.
Failed to load notebook details1. Tutorial Introduction


This tutorial uses a single RTX 4090 computing resource, deploys the model VideoLLaMA3-7B-Image, and provides two examples of video understanding and image understanding. In addition, it also provides four notebook script tutorials for "single image understanding", "multiple image understanding", "visual reference expression and positioning" and "video understanding".
VideoLLaMA3 is a multimodal foundational model open-sourced by the Alibaba DAMO Academy Natural Language Processing Team (DAMO-NLP-SG) in February 2025, focusing on image and video understanding tasks. Through a vision-centric architecture and high-quality data engineering, it significantly improves the accuracy and efficiency of video understanding. Its lightweight version (2B) caters to edge deployment needs, while the 7B model provides top-tier performance for research applications. The 7B model achieves state-of-the-art (SOTA) performance in three major tasks: general video understanding, temporal reasoning, and long video analysis. Related research papers are available. VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding .
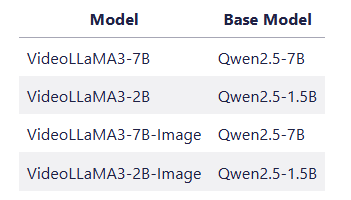
👉 The project provides 4 models of models:
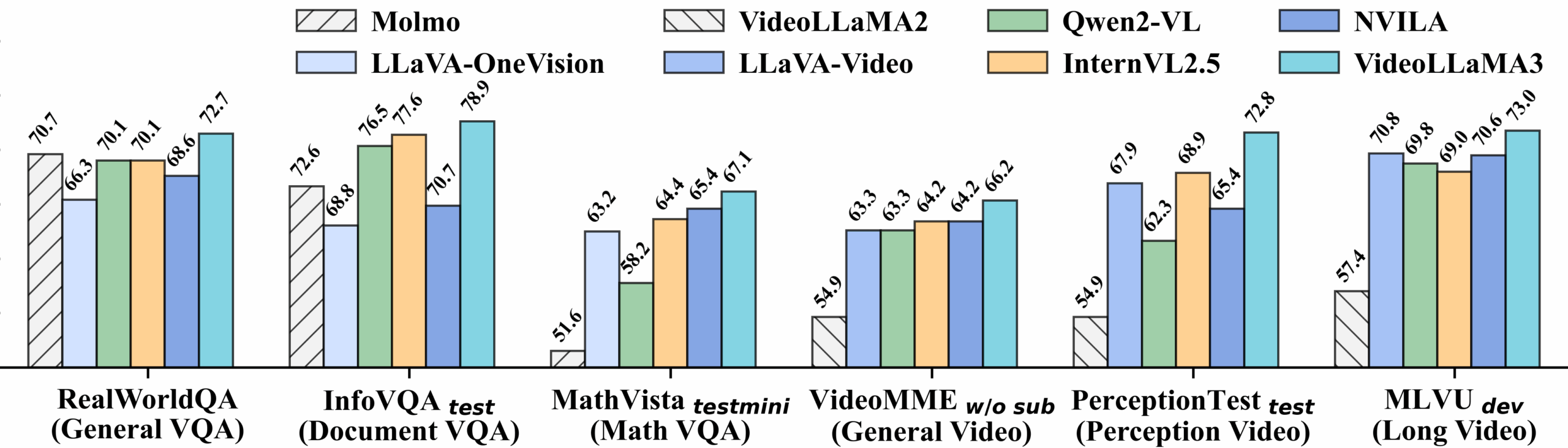
Video Benchmark Detailed Performance:
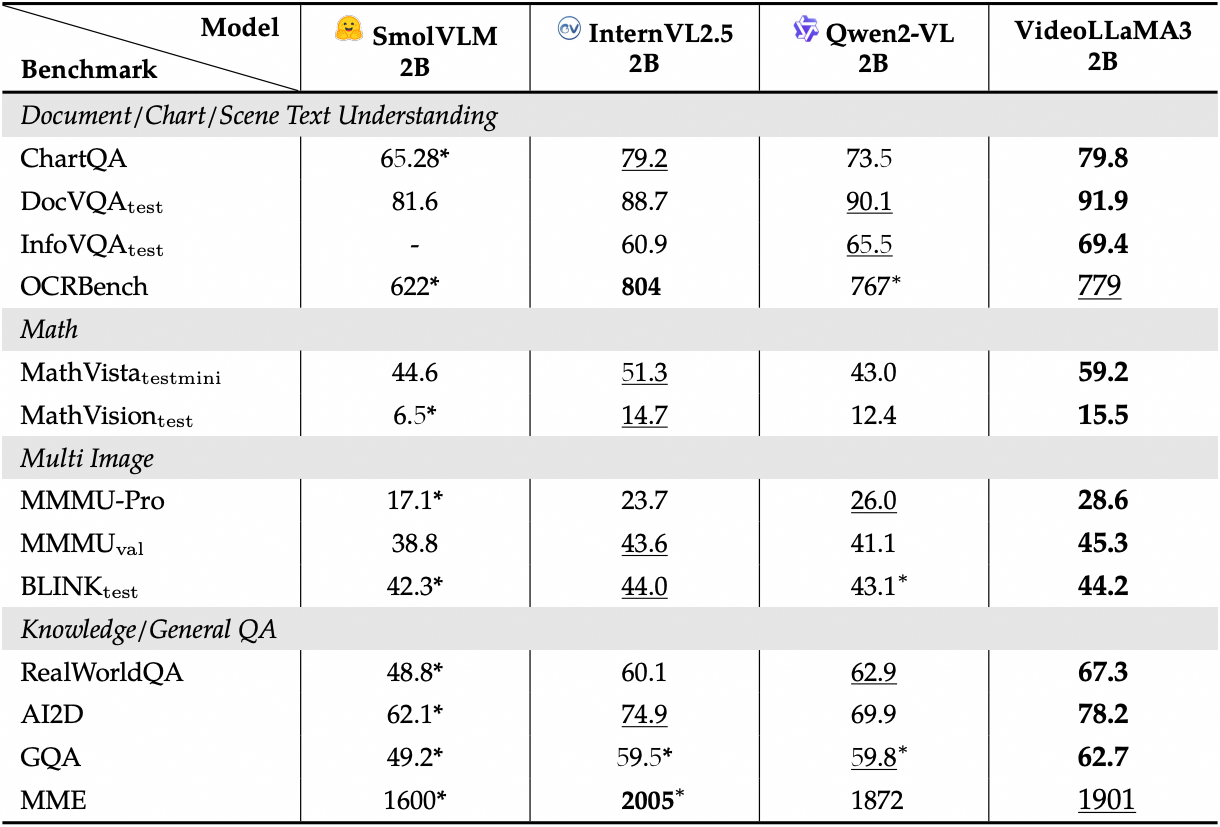
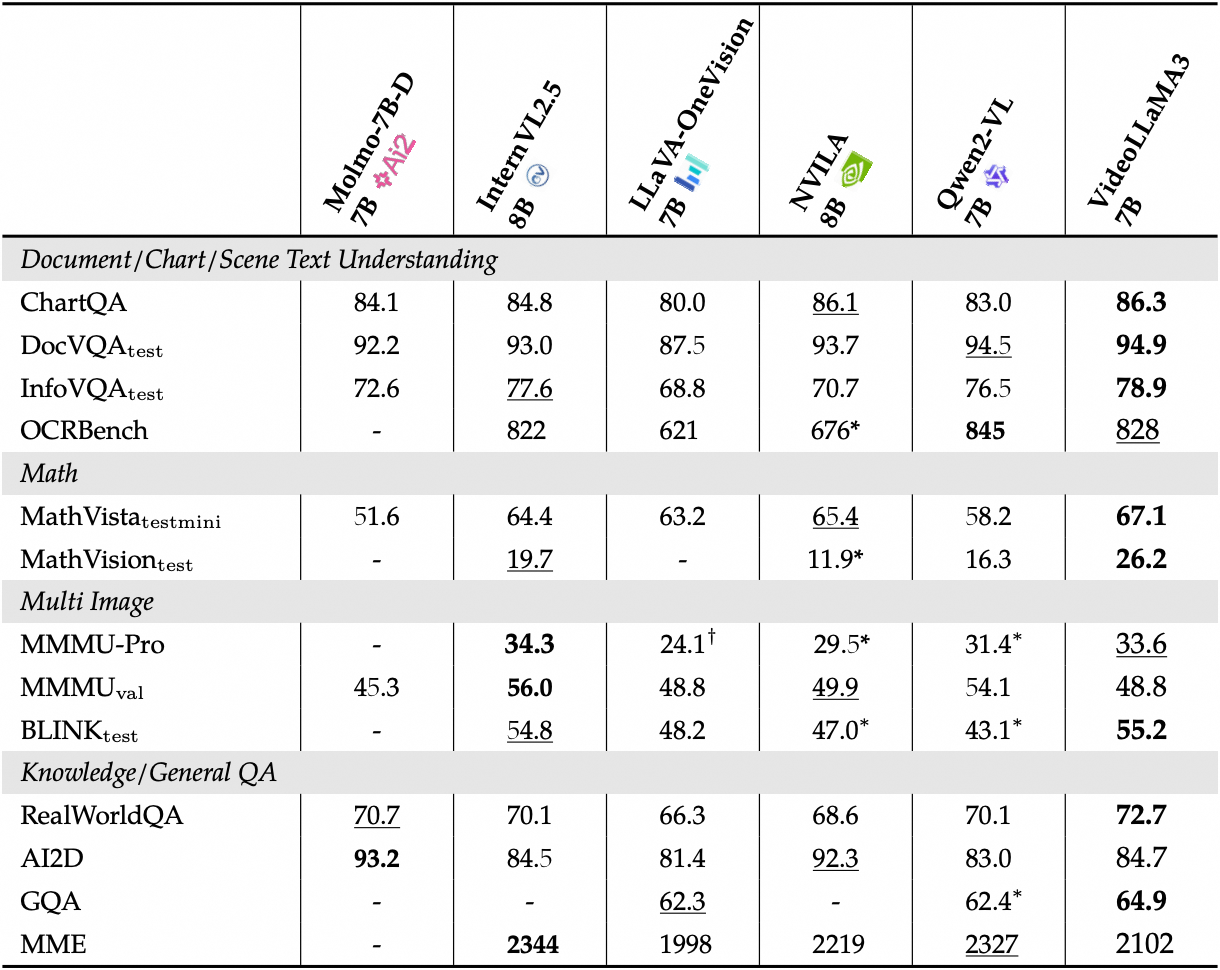
View detailed performance of the image benchmarks:
2. Operation steps
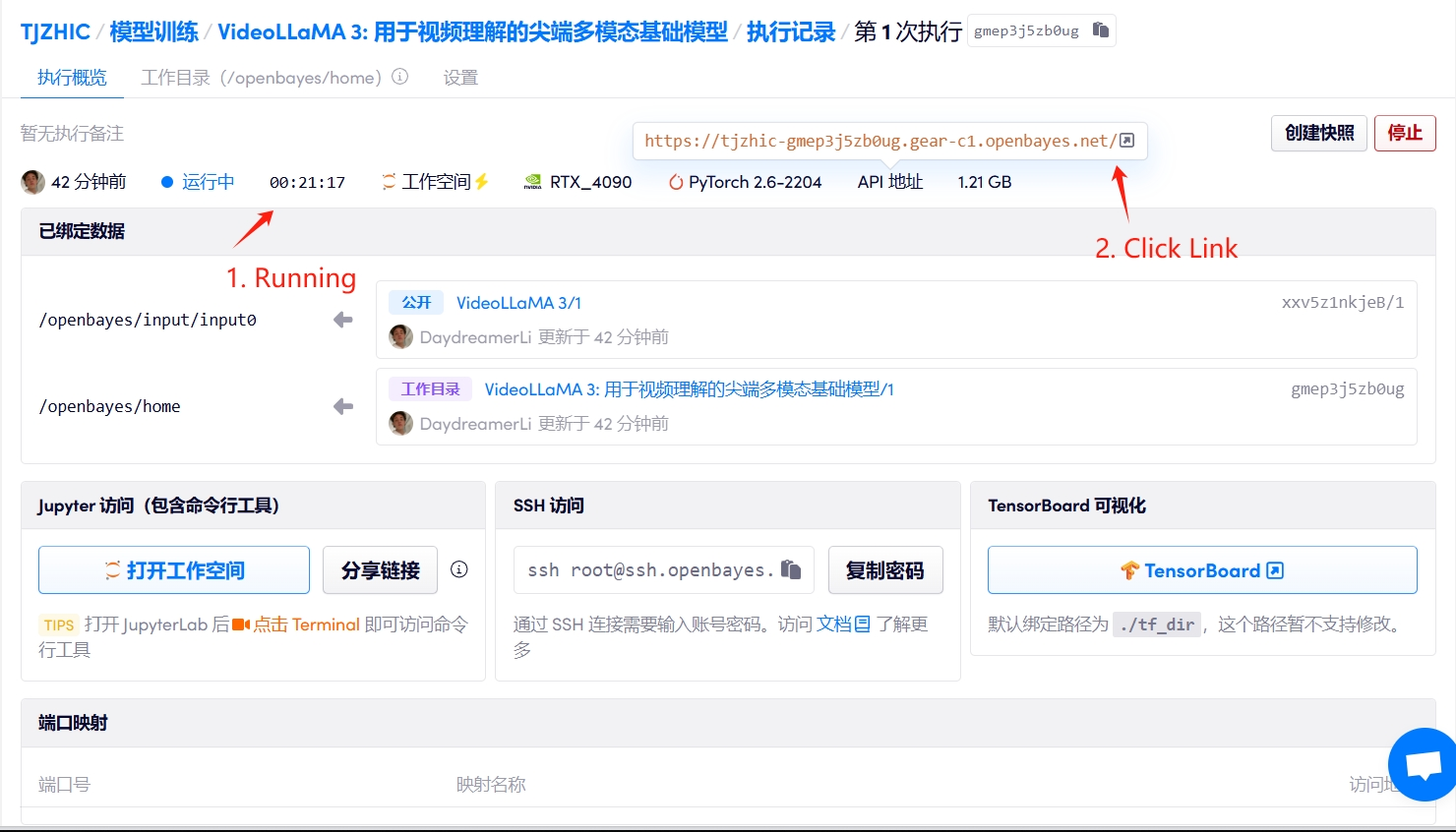
1. Start the container
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
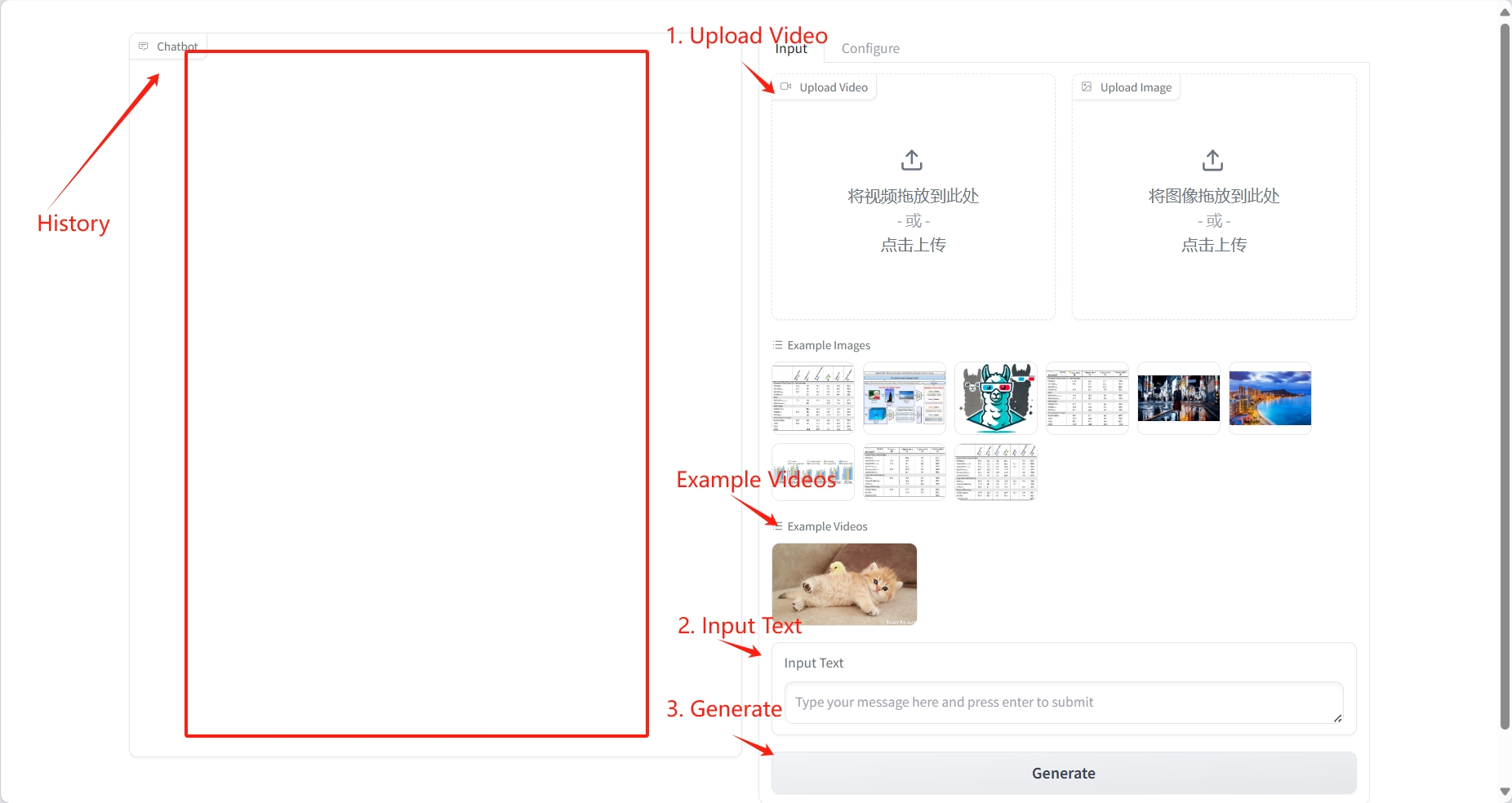
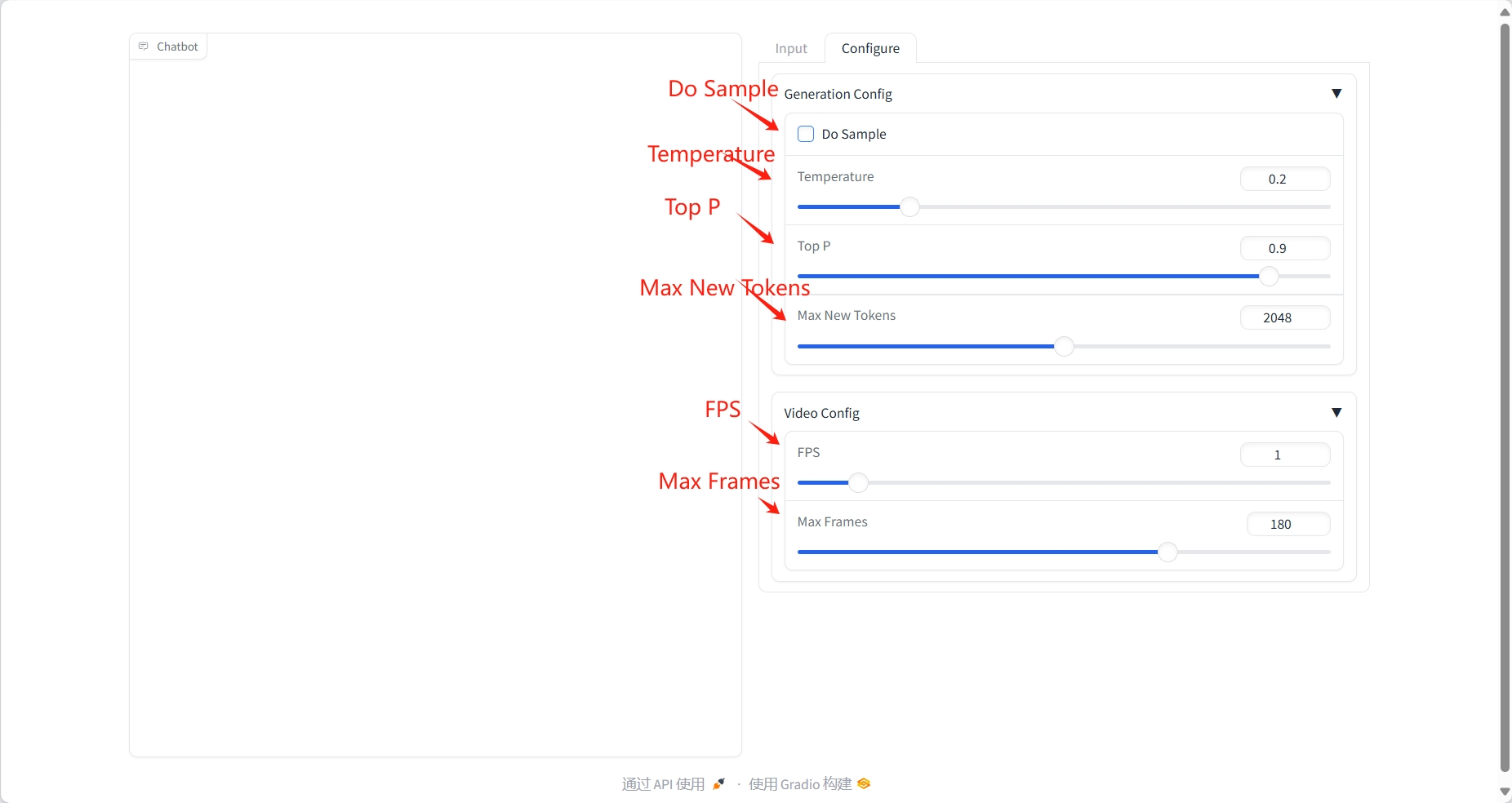
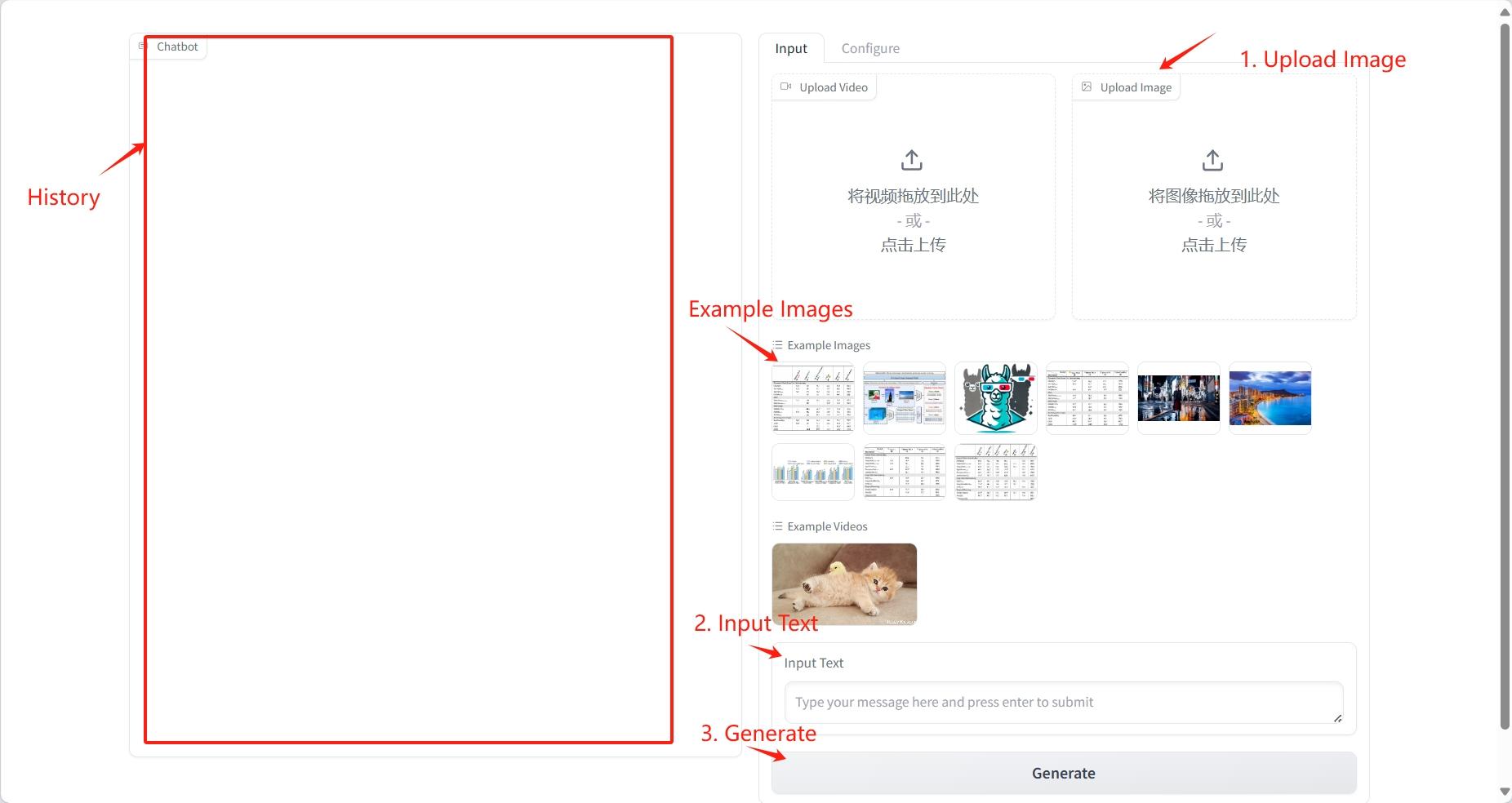
2. Usage steps
Video Understanding
result
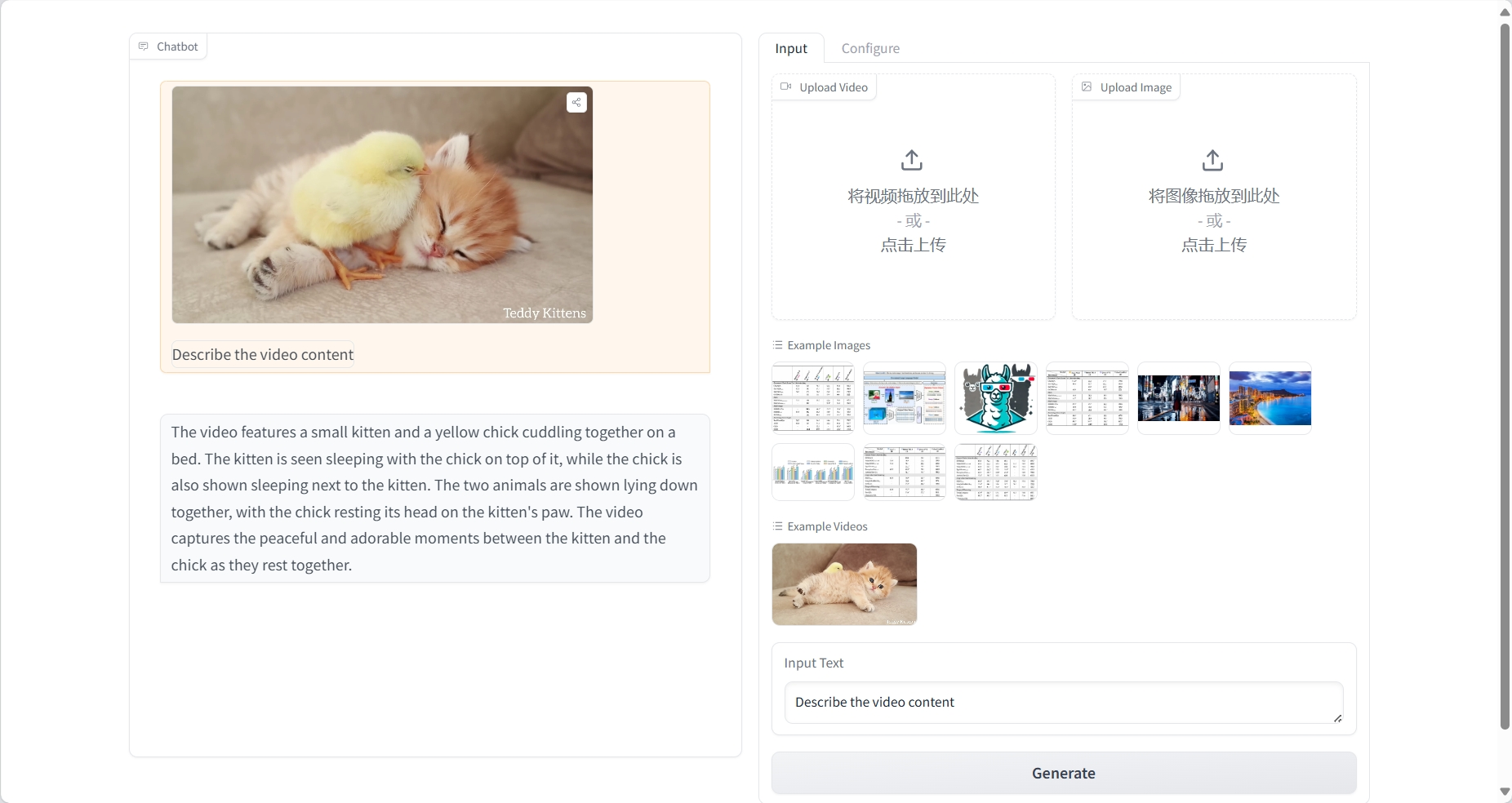
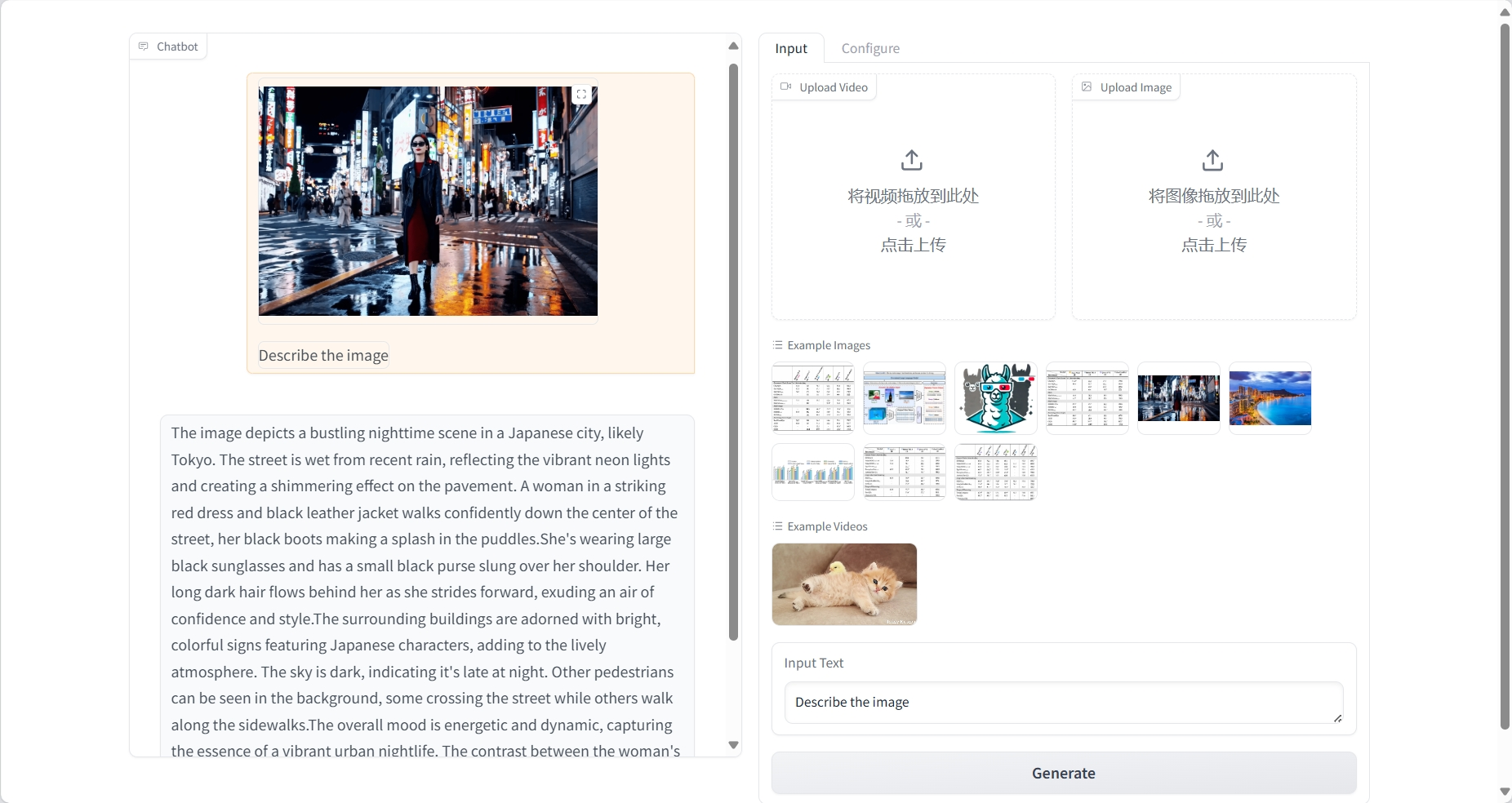
Image understanding
result
3. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.