Command Palette
Search for a command to run...
Self-Forcing Real-Time Video Generation
An error occurred in the Server Components render. The specific message is omitted in production builds to avoid leaking sensitive details. A digest property is included on this error instance which may provide additional details about the nature of the error.
Failed to load notebook details1. Tutorial Introduction

Self Forcing, proposed by Xun Huang's team on June 9, 2025, is a novel training paradigm for autoregressive video diffusion models. It addresses the long-standing problem of exposure bias, where models trained on real context must generate sequences based on their own imperfect outputs during inference. Unlike previous methods that denoise future frames based on real context frames, Self Forcing performs an autoregressive rollout with key-value (KV) caching during training, setting the generation conditions for each frame to the previously generated output. This strategy is supervised by a video-level global loss function that directly evaluates the quality of the entire generated sequence, rather than relying solely on a traditional frame-by-frame objective function. To ensure training efficiency, a few-step diffusion model and stochastic gradient truncation strategy are employed, effectively balancing computational cost and performance. A rolling key-value caching mechanism is further introduced to achieve efficient autoregressive video extrapolation. Extensive experiments demonstrate that their method can achieve real-time streaming video generation with sub-second latency on a single GPU, while achieving or even surpassing the generation quality of significantly slower and non-causal diffusion models. Related paper results are as follows: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion .
This tutorial uses resources for a single RTX 4090 card.
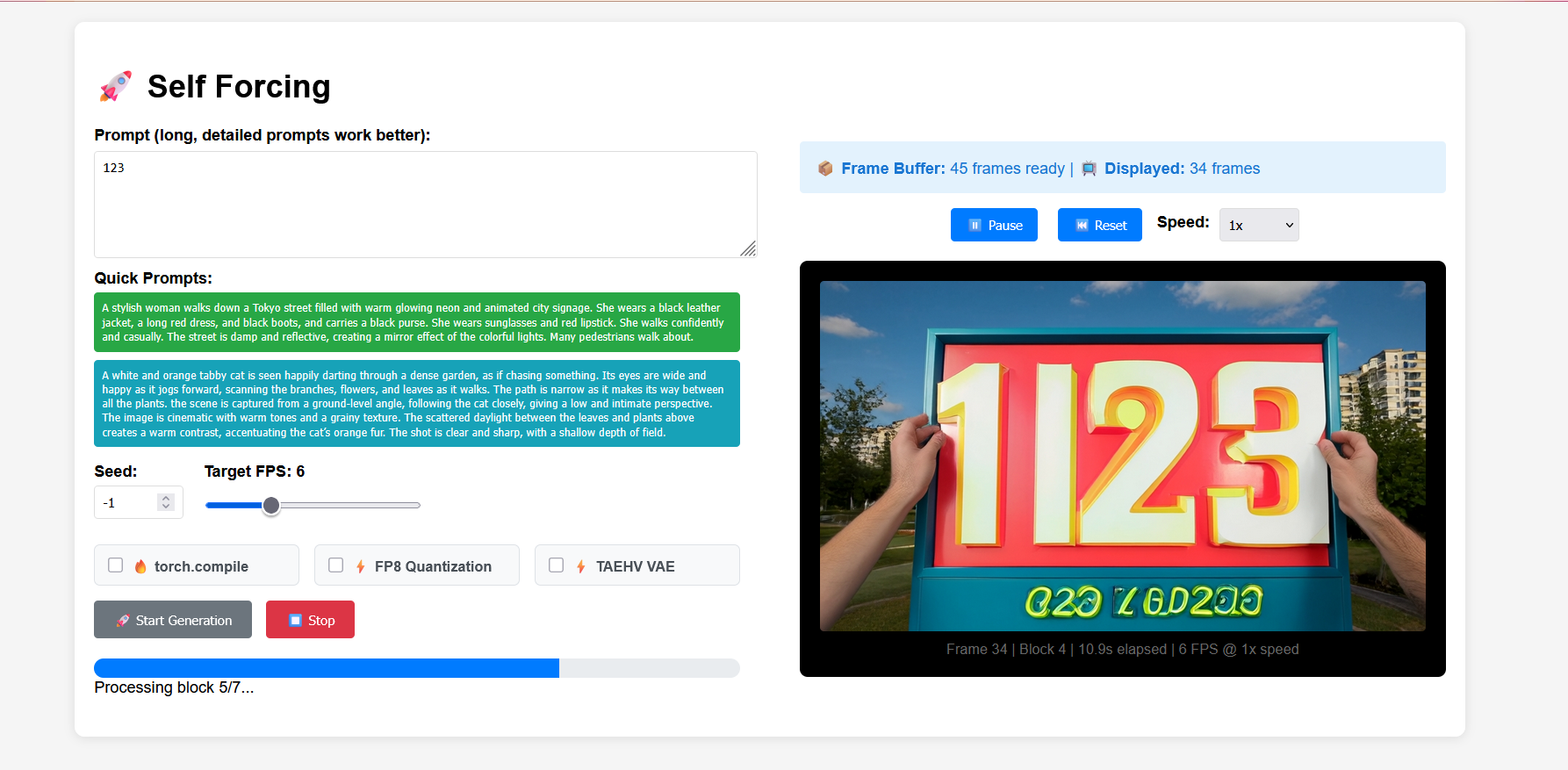
2. Project Examples
3. Operation steps
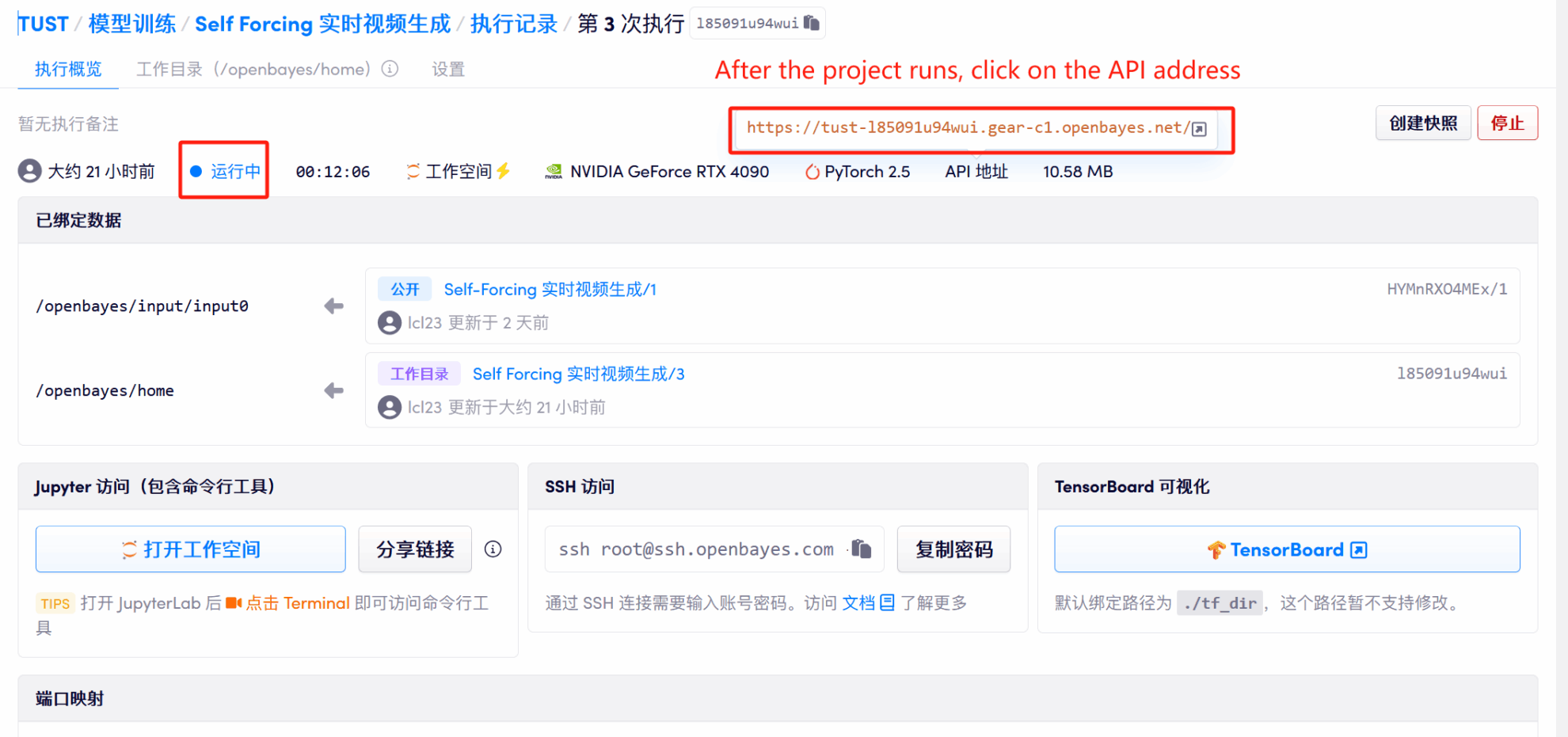
1. After starting the container, click the API address to enter the Web interface
2. Usage steps
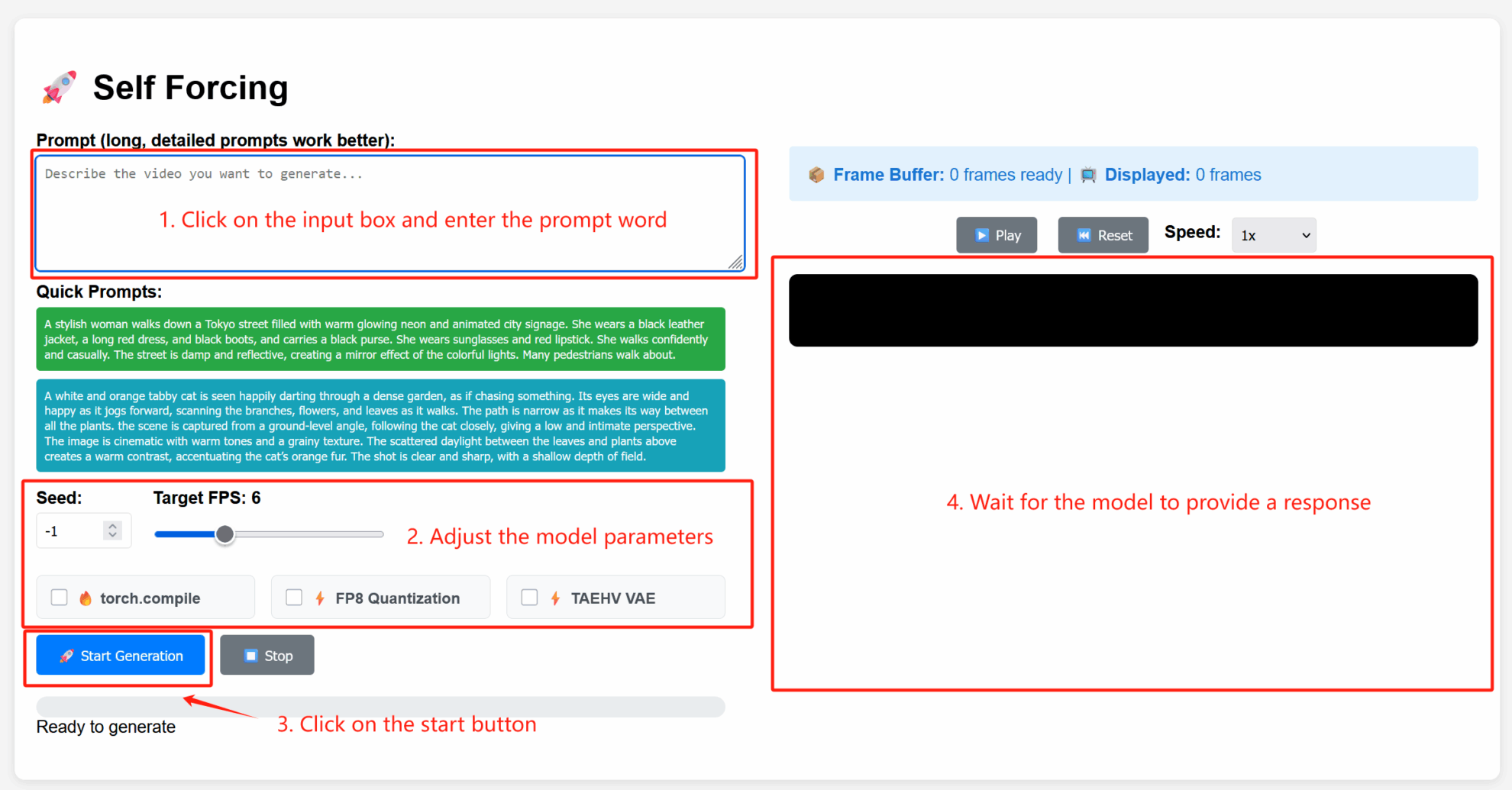
Parameter Description
- Advanced Settings:
- Seed: Random seed value that controls the randomness of the generation process. A fixed seed can reproduce the same results; -1 indicates a random seed.
- Target FPS: Target frame rate. The default value here is 6, which means the generated video is 6 frames per second.
- torch.compile: Enable PyTorch compilation optimization to accelerate model inference (environment support required).
- FP8 Quantization: Enables 8-bit floating-point quantization, reducing computational precision to increase generation speed (may slightly affect quality).
- TAEHV VAE: Specifies the type of variational autoencoder (VAE) model used, which may affect the generated details or style.
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@article{huang2025selfforcing,
title={Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion},
author={Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli},
journal={arXiv preprint arXiv:2506.08009},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.