Command Palette
Search for a command to run...
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Abstract
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities. Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
One-sentence Summary
The authors from DeepSeek-AI propose DeepSeek-R1, a reasoning model enhanced through multi-stage training and cold-start data prior to reinforcement learning, achieving performance on par with OpenAI-o1-1217; unlike its predecessor DeepSeek-R1-Zero, which lacks supervised fine-tuning and suffers from readability issues, DeepSeek-R1 improves coherence and reasoning accuracy, with open-sourced versions across six sizes for community use.
Key Contributions
-
This work pioneers a pure reinforcement learning (RL) approach to develop strong reasoning capabilities in large language models without any supervised fine-tuning (SFT), demonstrating that models like DeepSeek-R1-Zero can self-evolve advanced reasoning behaviors through large-scale RL, achieving pass@1 scores of 86.7% on AIIME 2024 via majority voting.
-
To improve readability and general performance, DeepSeek-R1 introduces a multi-stage training pipeline with cold-start data and iterative RL, incorporating rejection sampling and additional SFT, resulting in performance on par with OpenAI-o1-1217 across diverse reasoning benchmarks.
-
The reasoning capabilities of DeepSeek-R1 are successfully distilled into smaller dense models (1.5B to 70B) using Qwen and Llama as base models, with the distilled 14B model outperforming QwQ-32B-Preview and the 32B and 70B versions setting new records among open-source dense models.
Introduction
The authors leverage reinforcement learning (RL) to enhance reasoning capabilities in large language models (LLMs), addressing the growing need for models that can perform complex, step-by-step reasoning in tasks like math, coding, and scientific problem solving. Prior approaches relied heavily on supervised fine-tuning with large amounts of human-annotated Chain-of-Thought (CoT) data, which is costly and time-consuming, or used inference-time scaling techniques that lack generalization. The key contribution is the development of DeepSeek-R1-Zero, a pure RL method that enables a base model to self-evolve reasoning skills without any supervised data, achieving strong performance on benchmarks such as AIIME 2024. To improve coherence and generalization, the authors introduce DeepSeek-R1, which combines a small amount of cold-start CoT data with a multi-stage pipeline involving RL, rejection sampling, and supervised fine-tuning. This results in a model matching the performance of OpenAI’s o1-1217. Finally, they demonstrate that reasoning capabilities can be effectively distilled into smaller dense models, with their distilled 14B model outperforming state-of-the-art open-source models on reasoning benchmarks.
Method
The authors leverage a multi-stage training pipeline to develop DeepSeek-R1, building upon the foundational work of DeepSeek-R1-Zero, which is trained directly via reinforcement learning (RL) without supervised fine-tuning (SFT). This approach enables the model to naturally develop reasoning behaviors such as self-verification, reflection, and the generation of long chain-of-thought (CoT) responses. The framework for this training process is illustrated in the following diagram.
DeepSeek-R1-Zero is trained using Group Relative Policy Optimization (GRPO), a variant of policy optimization that eliminates the need for a separate critic model by estimating the baseline from group scores. For each input question q, GRPO samples a group of outputs {o1,o2,⋯,oG} from the current policy πθold and optimizes the policy model πθ by maximizing the objective:
IGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1∑i=1G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),where Ai is the advantage computed as the normalized difference between the reward ri and the group mean and standard deviation:
Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}).The KL divergence term DKL(πθ∣∣πref) is used to regularize the policy update, with πref being a reference policy, typically the previous policy. The hyperparameters ε and β control the clipping range and the strength of the KL penalty, respectively.
To train DeepSeek-R1-Zero, the authors employ a rule-based reward system composed of two components: accuracy rewards and format rewards. Accuracy rewards are derived from deterministic verification mechanisms, such as checking the correctness of mathematical answers or compiling code against test cases. Format rewards enforce the model to structure its output with the reasoning process enclosed between <tool_call> and </think> tags, and the final answer within <answer> tags. This ensures the model adheres to a consistent output format. The authors avoid using neural reward models, as they are prone to reward hacking and introduce additional complexity and resource requirements.
The training template for DeepSeek-R1-Zero is designed to guide the model to generate a reasoning process followed by a final answer, as shown in Table 1. This template is intentionally minimal, avoiding content-specific constraints to allow the model to develop reasoning behaviors naturally during RL.
For DeepSeek-R1, the authors introduce a cold start phase to mitigate the instability of early RL training. This involves collecting a small dataset of high-quality, readable long CoT responses, which are used to fine-tune the base model before RL. The cold-start data is curated through few-shot prompting, direct generation with reflection, and post-processing by human annotators. The resulting data is structured with a reasoning process and a summary, ensuring readability and coherence. This step addresses the poor readability and language mixing issues observed in DeepSeek-R1-Zero.
Following cold start, DeepSeek-R1 undergoes reasoning-oriented reinforcement learning. The same GRPO framework is applied, but with an additional language consistency reward that penalizes language mixing by measuring the proportion of target language words in the CoT. This reward is combined with the accuracy reward to form the final reward signal. The training focuses on reasoning-intensive tasks such as mathematics, coding, and logic, with the goal of enhancing reasoning capabilities while improving readability.
A second RL stage is then applied to align the model with human preferences, focusing on helpfulness and harmlessness. For reasoning tasks, rule-based rewards are used, while for general scenarios, reward models capture nuanced human preferences. The helpfulness reward evaluates the final summary for utility and relevance, while the harmlessness reward assesses the entire response, including the reasoning process, to detect and mitigate harmful content.
Finally, the authors perform distillation to transfer reasoning capabilities to smaller models. They fine-tune open-source models such as Qwen and Llama using 800k samples curated from DeepSeek-R1. This distillation process is conducted via supervised fine-tuning only, without an RL stage, to demonstrate the effectiveness of the technique. The resulting distilled models exhibit enhanced reasoning abilities, enabling broader access to reasoning-capable models.
Experiment
-
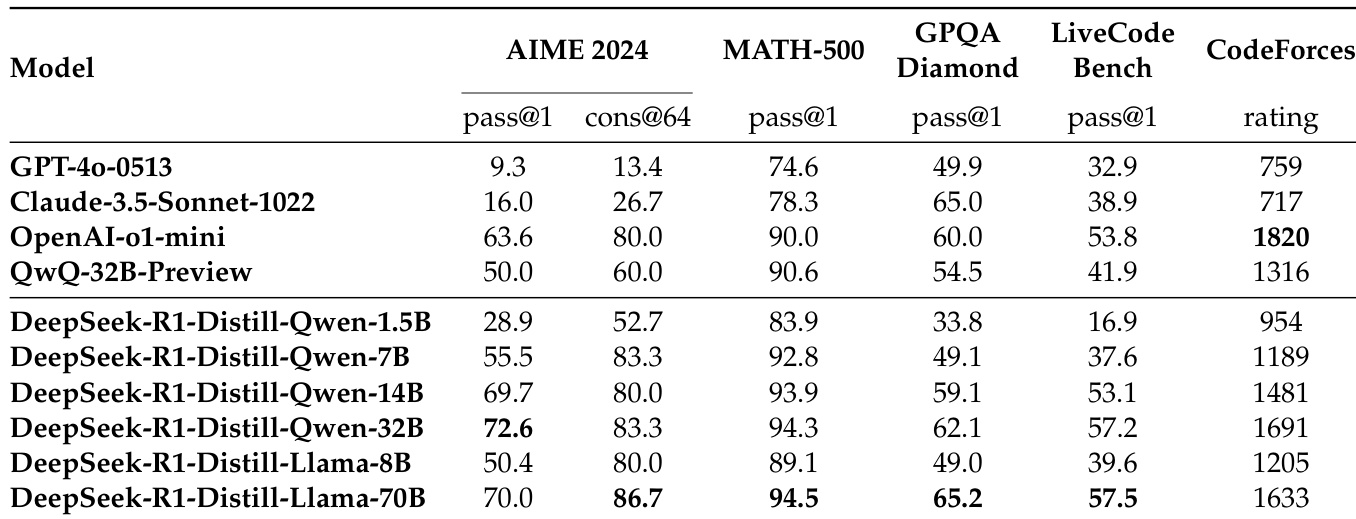
Distillation experiments show that reasoning patterns from larger models like DeepSeek-R1 can be effectively transferred to smaller models, resulting in superior performance compared to RL-trained small models. DeepSeek-R1-Distill-Qwen-7B achieves 55.5% on AIME 2024, surpassing QwQ-32B-Preview; DeepSeek-R1-Distill-Qwen-32B scores 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench, outperforming prior open-source models and approaching o1-mini levels. Open-sourced distilled models include 1.5B, 7B, 8B, 14B, 32B, and 70B variants based on Qwen2.5 and Llama3.
-
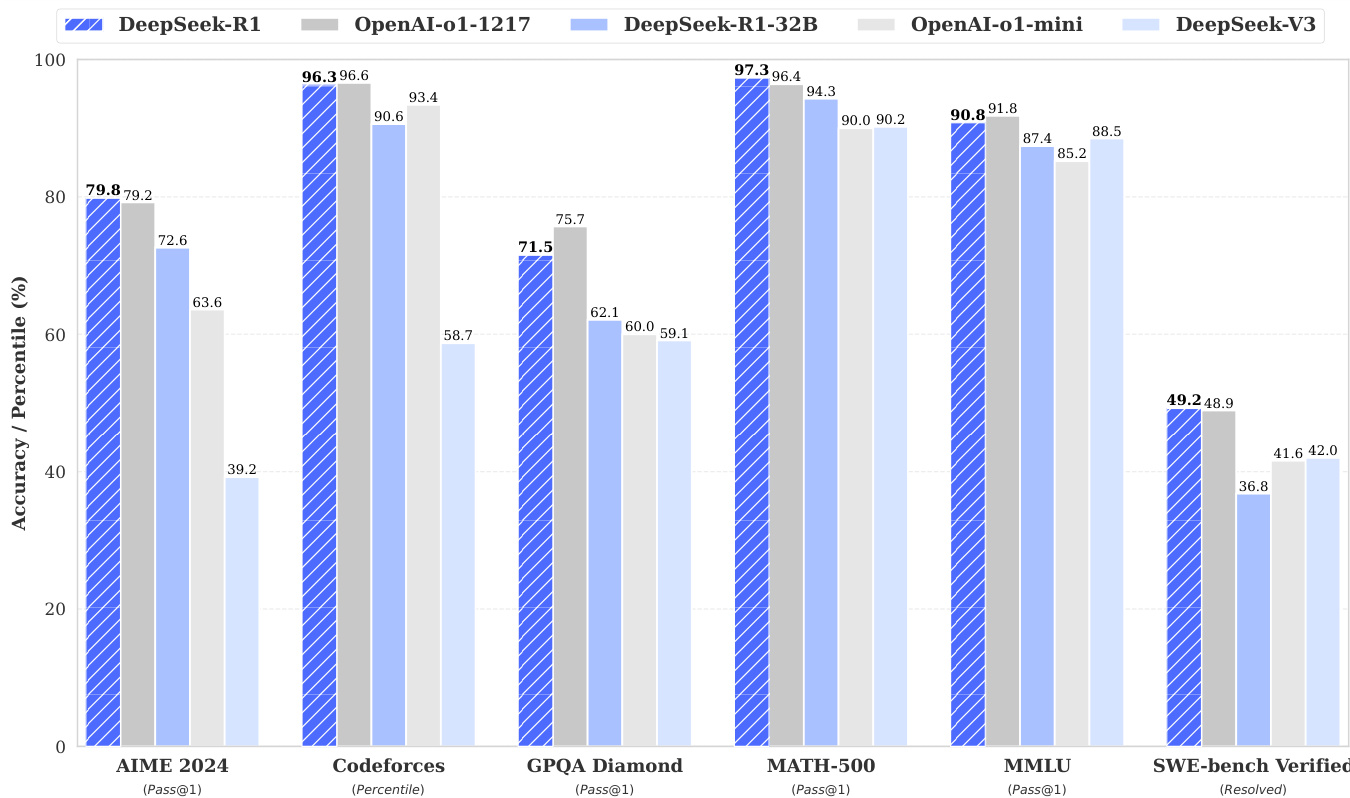
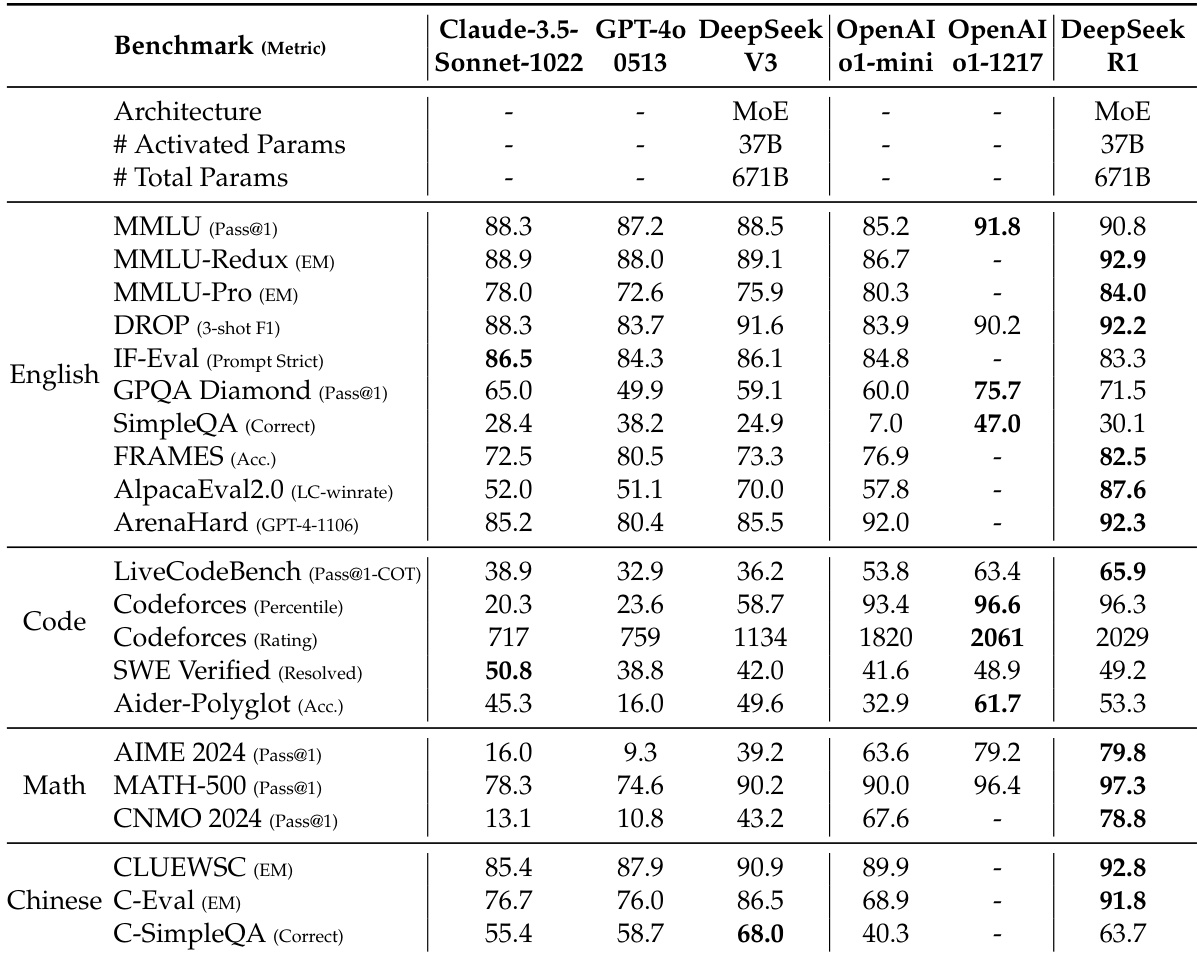
DeepSeek-R1 achieves 79.8% Pass@1 on AIME 2024, slightly surpassing OpenAI-o1-1217, and 97.3% on MATH-500, matching o1-1217. On coding tasks, it attains a 2,029 Elo rating on Codeforces, outperforming 96.3% of human participants. It also excels in knowledge benchmarks: 90.8% on MMLU, 84.0% on MMLU-Pro, and 71.5% on GPQA Diamond, significantly outperforming DeepSeek-V3. It achieves 87.6% length-controlled win-rate on AlpacaEval 2.0 and 92.3% on ArenaHard, demonstrating strong generalization across creative, factual, and long-context tasks.
-
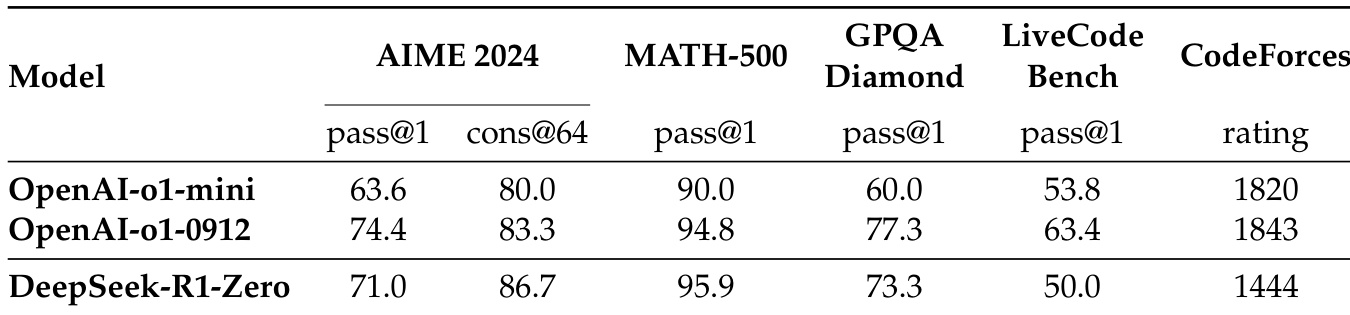
DeepSeek-R1-Zero, trained via RL without supervised fine-tuning, improves from 15.6% to 71.0% on AIME 2024, reaching performance comparable to OpenAI-o1-0912. With majority voting, it achieves 86.7%, exceeding o1-0912. The model autonomously develops advanced reasoning behaviors such as reflection and alternative approach exploration through increased test-time computation. An "aha moment" is observed where the model reevaluates its initial approach, demonstrating emergent intelligence through RL.
-
Supervised fine-tuning (SFT) enhances model capabilities by incorporating 600k reasoning samples via rejection sampling and generative reward models, and 200k non-reasoning samples from DeepSeek-V3’s pipeline. The final model is fine-tuned on 800k curated samples, improving instruction-following and general performance.
-
Distillation outperforms direct RL on smaller models: DeepSeek-R1-Distill-Qwen-32B significantly surpasses DeepSeek-R1-Zero-Qwen-32B (trained via 10K-step RL), demonstrating that distillation is more efficient and effective than large-scale RL alone for smaller models, though larger-scale RL remains essential for pushing intelligence boundaries.
Results show that DeepSeek-R1-Zero achieves a pass@1 score of 71.0 on AIME 2024 and a cons@64 score of 86.7, outperforming OpenAI-o1-mini and approaching the performance of OpenAI-o1-0912. On MATH-500, DeepSeek-R1-Zero scores 95.9 pass@1, surpassing both OpenAI models, and achieves 73.3 pass@1 on GPQA Diamond, while scoring 1444 on Codeforces, indicating strong reasoning and coding capabilities.
The authors use the table to compare the performance of DeepSeek-R1 and other models across multiple benchmarks. Results show that DeepSeek-R1 achieves top-tier performance, scoring 79.8% on AIME 2024 and 97.3% on MATH-500, outperforming models like OpenAI-o1-1217 and DeepSeek-V3. On MMLU, it scores 90.8%, and on Codeforces, it reaches a 90.8 percentile, demonstrating strong reasoning and coding capabilities.
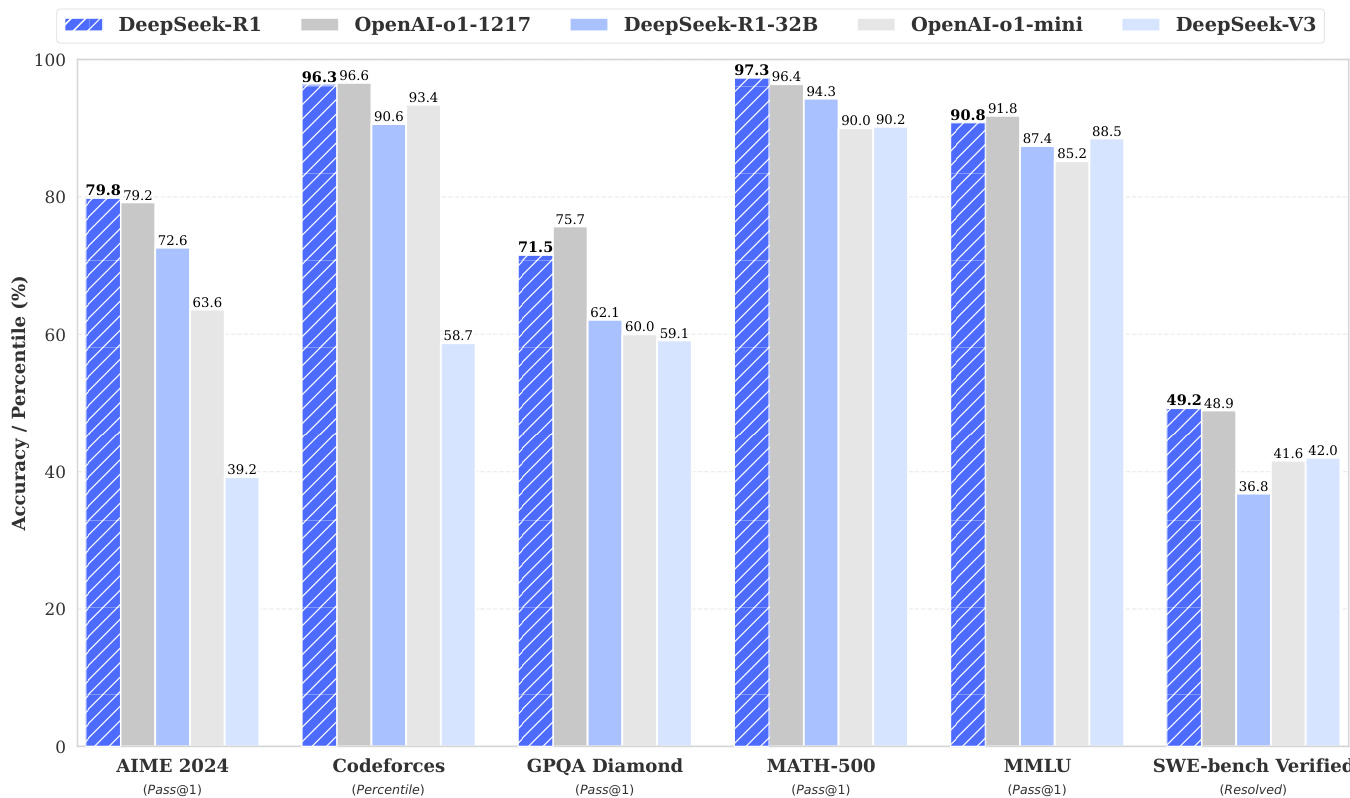
The authors use the table to compare DeepSeek-R1 with several strong baselines across multiple benchmarks. Results show that DeepSeek-R1 achieves state-of-the-art performance on most tasks, particularly excelling in math and coding benchmarks, where it surpasses models like GPT-4o and OpenAI-o1-mini. It also demonstrates strong capabilities in knowledge and reasoning tasks, outperforming DeepSeek-V3 and matching or exceeding OpenAI-o1-1217 on key metrics.
The authors compare the performance of distilled and RL-trained models on reasoning benchmarks, showing that DeepSeek-R1-Distill-Qwen-32B outperforms both DeepSeek-R1-Zero-Qwen-32B and QwQ-32B-Preview across all evaluated tasks. Results indicate that distillation from a powerful model yields better performance than large-scale RL training on a smaller base model, highlighting the effectiveness of knowledge transfer.

The authors use the table to compare the performance of distilled models based on DeepSeek-R1 against several strong baselines across multiple benchmarks. Results show that DeepSeek-R1-Distill-Qwen-32B achieves 72.6% on AIME 2024 and 94.3% on MATH-500, outperforming OpenAI-o1-mini and QwQ-32B-Preview, while also achieving a Codeforces rating of 1691, surpassing most other models.