Command Palette
Search for a command to run...
MuseTalk High Quality Lip Sync Model Demo
Date
Size
2.41 GB
MuseTalk features include:
- Real-time: Able to run in a real-time environment, achieving a processing speed of more than 30 frames per second to ensure smooth lip synchronization.
- High-quality sync: A latent space inpainting method is used to adjust the mouth shape based on the input audio while maintaining facial features, achieving high-quality lip sync.
- Works with MuseV: MuseTalk can be used with the MuseV model, which is a video generation framework that can generate virtual human videos.
- Open Source: MuseTalk's code has been open sourced to facilitate community contributions and further development.
MuseTalk performs well in lip-syncing, generating accurate lip-syncing with good picture consistency, especially for live video generation. It also has advantages when compared with other products such as EMO, AniPortrait, Vlogger, and Microsoft's VASA-1.
Effect examples
Model framework
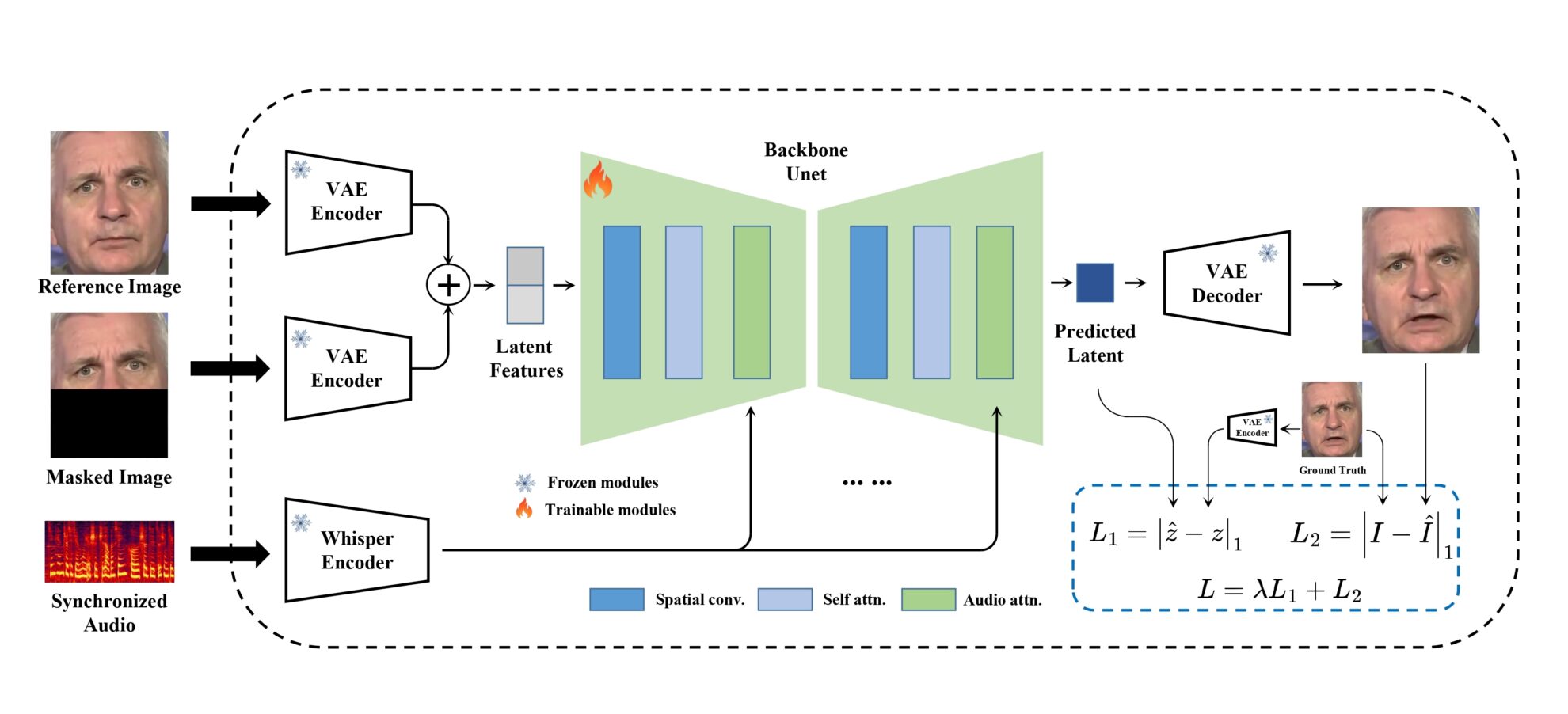
MuseTalk Training is done in latent space, where images are encoded by frozen VAEs. Audio is encoded by frozen whisper-tiny models. The architecture of the generator network is inspired by UNet from stable-diffusion-v1-4, where audio embeddings are fused with image embeddings via cross-attention.
Run steps
1. Click "Clone" in the upper right corner of the project, and then click "Next" to complete the following steps: Basic Information > Select Computing Power > Review. Finally, click "Continue" to open the project in your personal container.
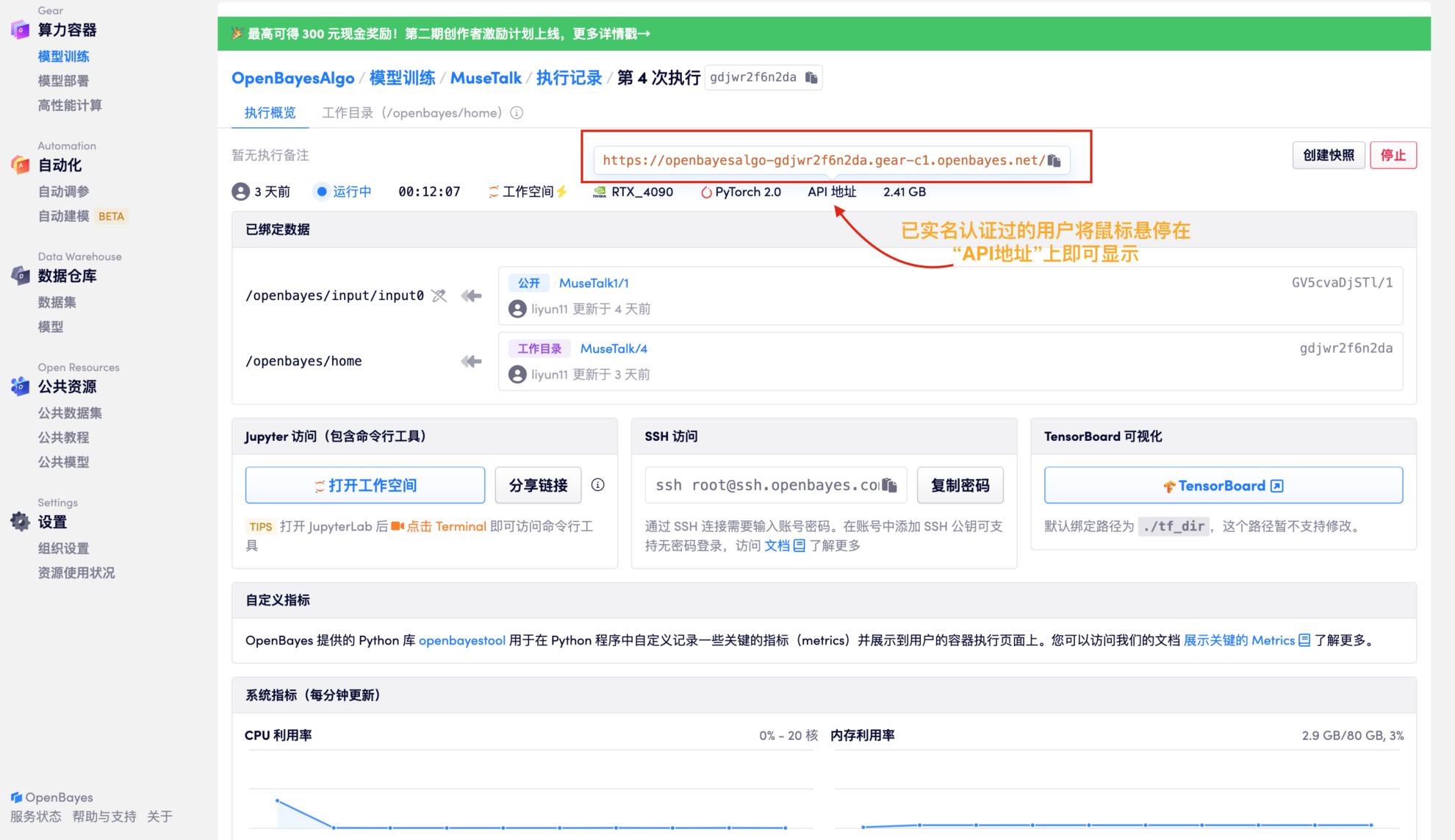
2. After the resource allocation is completed, directly copy the API address and paste it into any URL (real-name authentication must have been completed, and there is no need to open the workspace for this step)
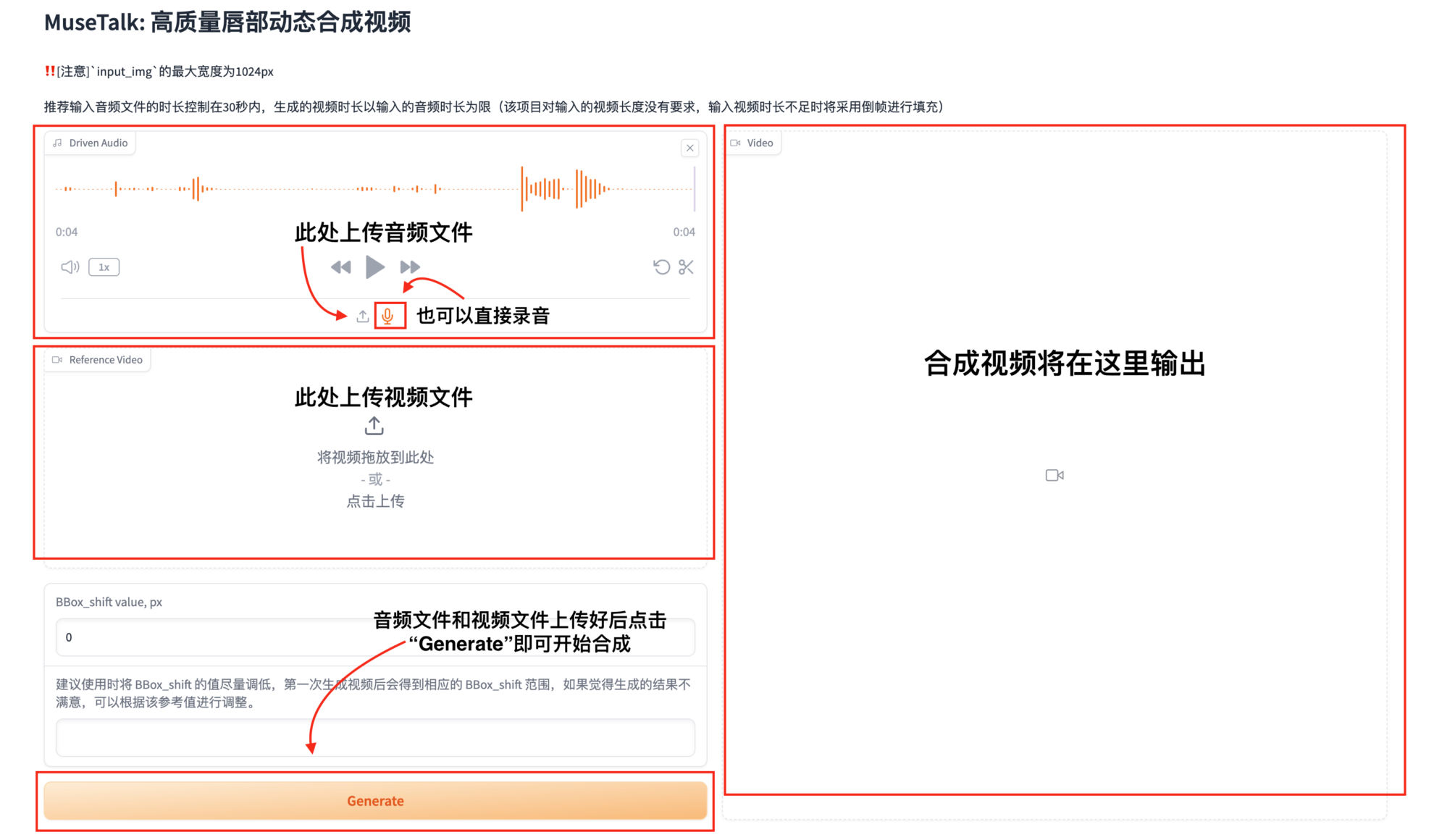
3. Upload audio and video files for synthesis
After testing: it takes about 3 minutes to generate an audio file with a duration of 17 seconds; it takes about 6 minutes to generate an audio file with a duration of about one minute.
-|MuseTalk The face and mouth shape can be modified according to the input audio. The size of the face area is preferably 256 x 256. MuseTalk It also supports modifying the facial region center point proposals, which will significantly affect the generation results.
-|Currently MuseTalk Supports audio input in multiple languages including Chinese, English, Japanese, etc.
-|The final generated video duration is based on the audio duration.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.