Command Palette
Search for a command to run...
One-click Deployment of QwQ-32B-AWQ
Date
Size
3.2 MB

1. Tutorial Introduction
QwQ is the inference model of the Qwen series. Compared with traditional instruction tuning models, QwQ has thinking and reasoning capabilities, and can achieve significant performance improvements on downstream tasks, especially difficult problems. QwQ-32B is a medium-sized inference model that can achieve competitive performance with the most advanced inference models such as DeepSeek-R1 and o1-mini.
This tutorial uses QwQ-32B-AWQ as a demonstration, and the computing resource uses RTX4090.
2. Operation steps
1. After starting the container, click the API address to enter the web interface (If "Model" is not displayed, it means the model is being initialized. Since the model is large, please wait about 1-2 minutes and refresh the page.)
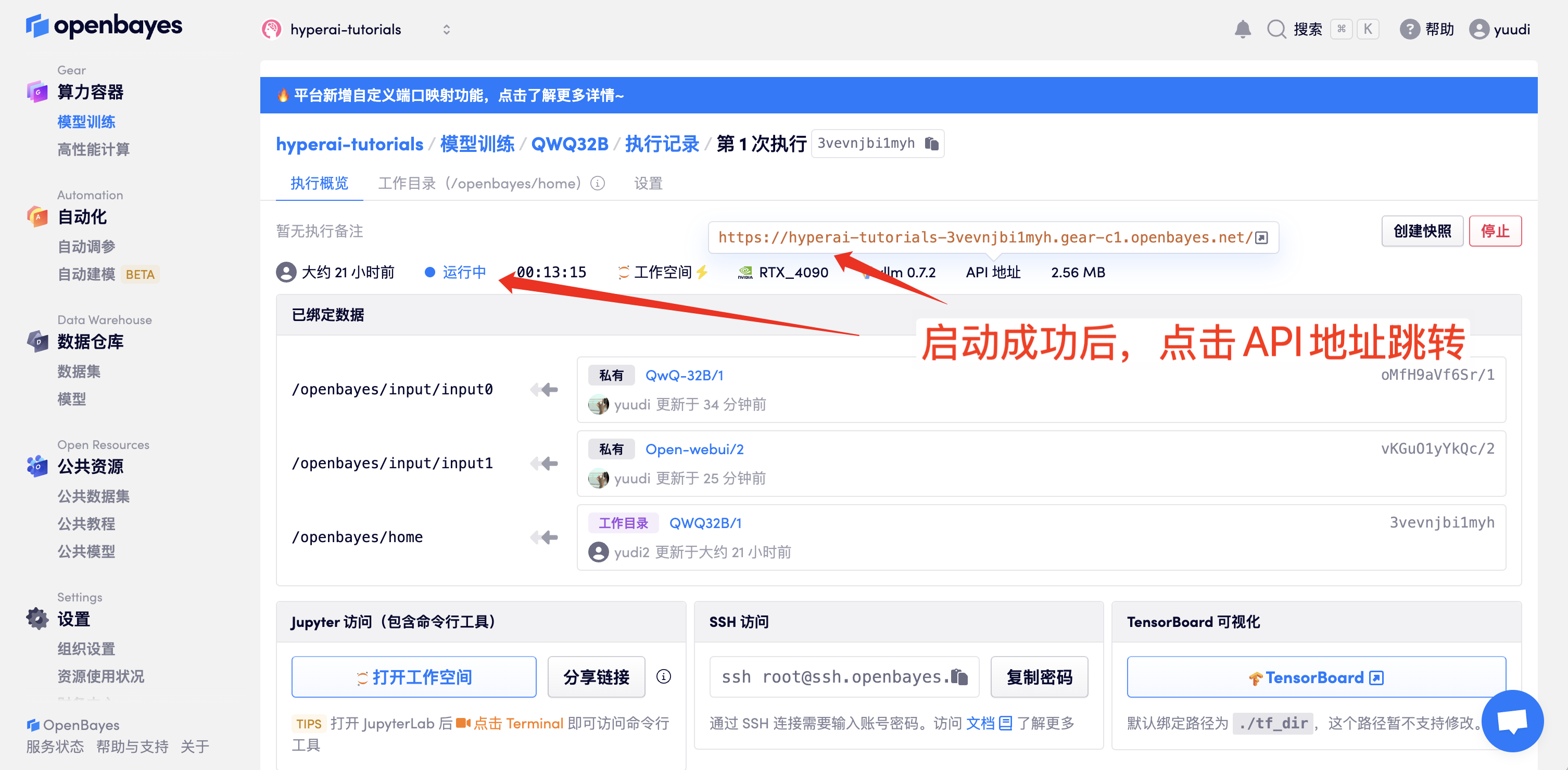
2. After entering the webpage, you can start a conversation with the model


Exchange and discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓ 
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.