Command Palette
Search for a command to run...
LFM2-1.2B: A Text Generation Model for Efficient Edge Deployment
1. Tutorial Introduction
LFM2-1.2B is the second generation of Liquid Foundation Model (LFMs) launched by Liquid AI on July 10, 2025. It is a generative AI model based on a hybrid architecture. It aims to provide the fastest on-device generative AI experience in the industry and is designed for low-latency on-device language model workloads.
As a model using a new hybrid architecture, LFM2-1.2B innovatively combines multiplication gating and short convolution, and contains 16 blocks (10 dual-gated short-range LIV convolution blocks and 6 group query attention blocks), which solves the shortcomings of traditional models in processing efficiency and performance. Its training is based on a pre-training corpus of 10 trillion tokens, and adopts multi-stage training strategies such as knowledge distillation, large-scale supervised fine-tuning (SFT), and custom direct preference optimization (DPO). It outperforms models of the same scale in multiple benchmark categories such as knowledge, mathematics, instruction following, and multi-language capabilities, and can even compete with models with larger parameter scales. At the same time, its decoding and pre-filling speed on the CPU is 2 times faster than Qwen 3, and its training efficiency is 3 times higher than the previous generation LFM. It can run efficiently on CPU, GPU and NPU hardware, providing a flexible and efficient solution for edge device deployment.
This tutorial uses LFM2-1.2B as a demonstration, and the computing resource uses RTX 4090. Supported languages: English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
2. Project Examples
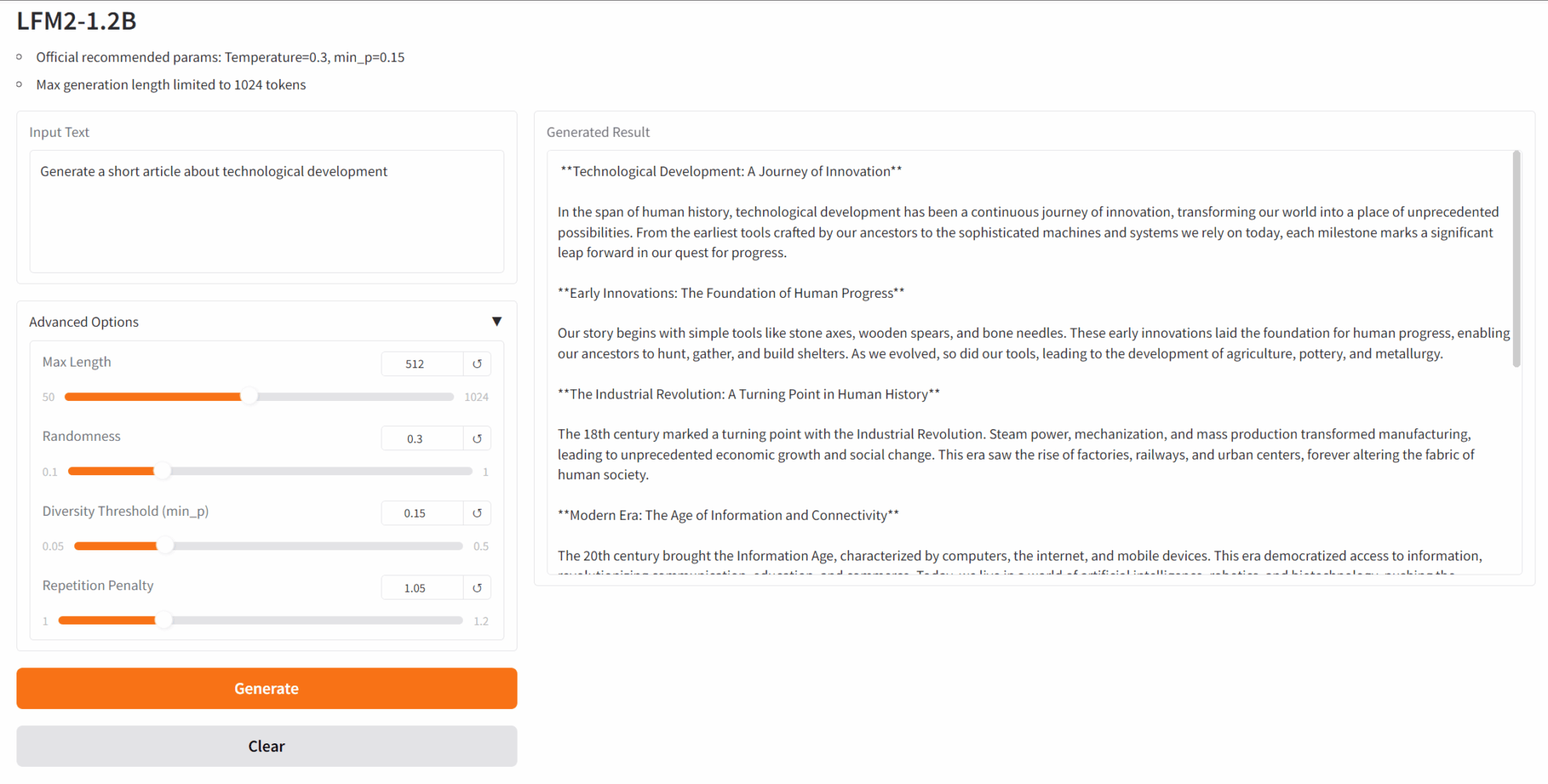
3. Operation steps
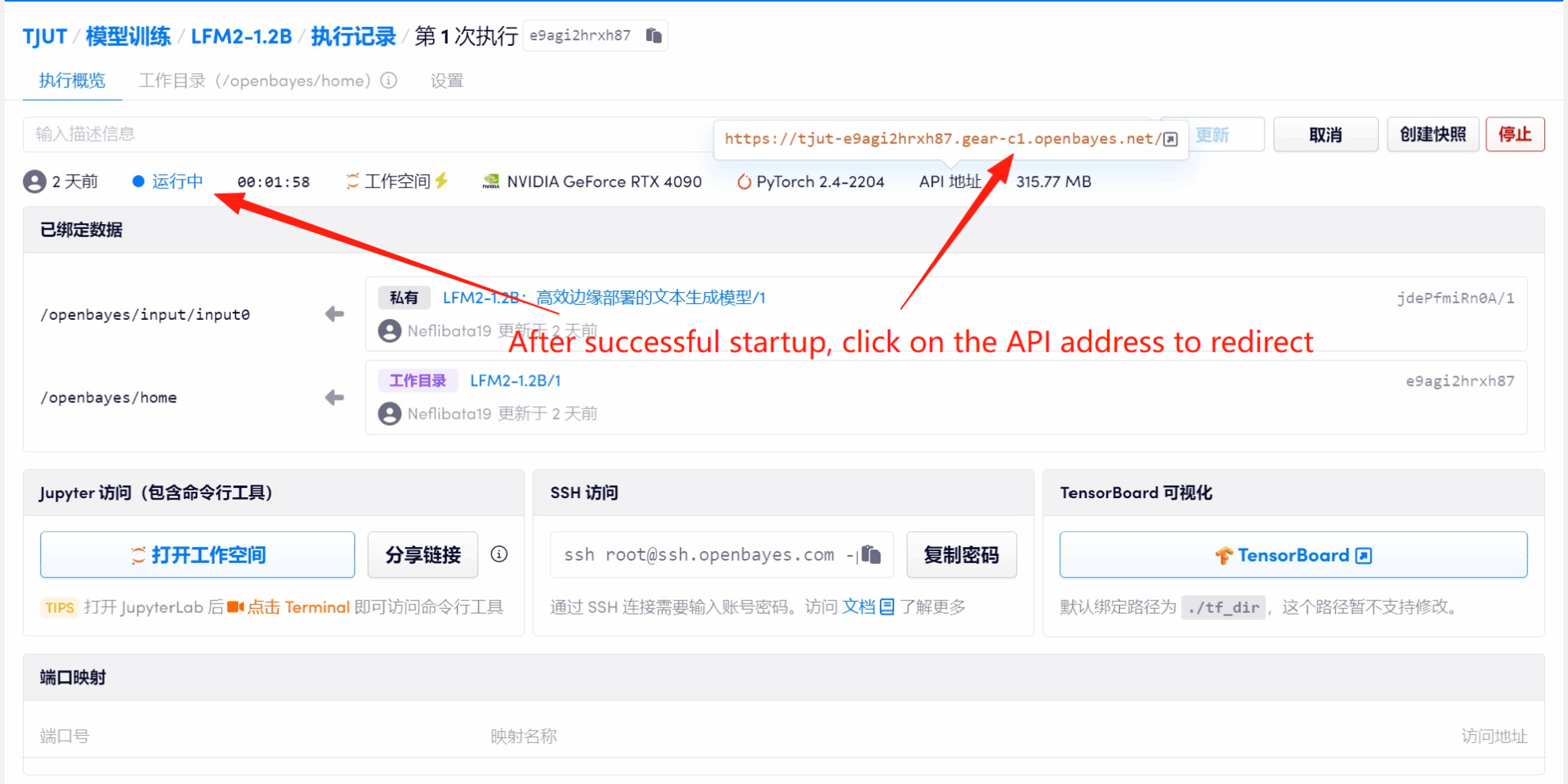
1. After starting the container, click the API address to enter the Web interface
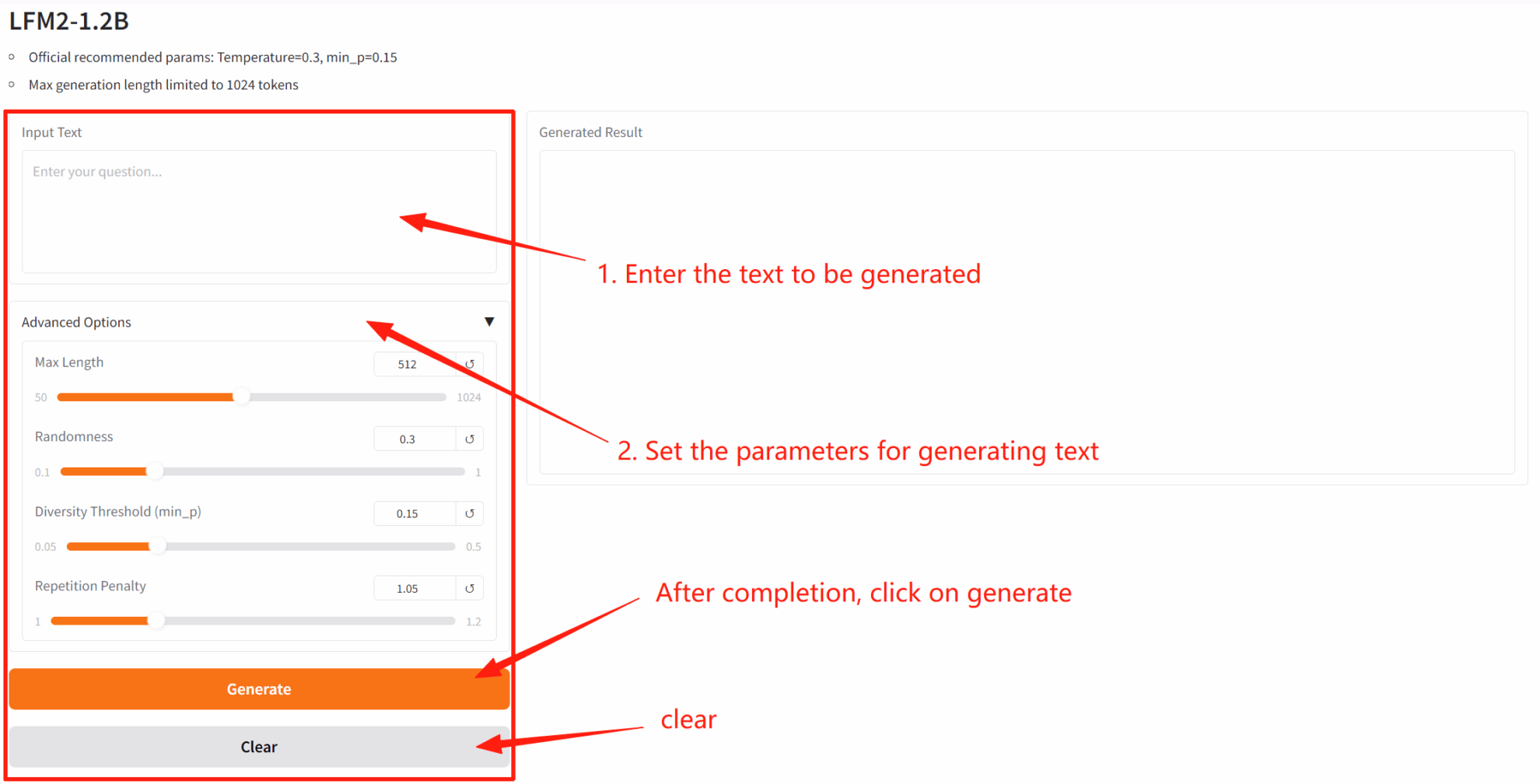
2. After entering the webpage, you can start a conversation with the model
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
4. Discussion
If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application results↓

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.