Command Palette
Search for a command to run...
IndexTTS-2: Breaking Through the Bottlenecks of Autoregressive TTS Duration and Emotion Control
Date
Size
111.82 MB
Tags
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

IndexTTS-2 is a novel text-to-speech (TTS) model open-sourced by the Bilibili Voice Team in June 2025. The model achieves significant breakthroughs in emotion expression and duration control, and is the first autoregressive TTS model to support precise duration control. It supports zero-sample voice cloning, accurately replicating timbre, rhythm, and speaking style from a single audio file, and supports multiple languages. IndexTTS-2 implements emotion-timbre separation control, allowing users to independently specify the timbre and emotion sources. The model features multimodal emotion input capabilities, supporting emotion control through emotion reference audio, emotion description text, or emotion vectors. Related research papers are available. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech .
This tutorial uses a single RTX 5090 graphics card as computing resource.
2. Effect display
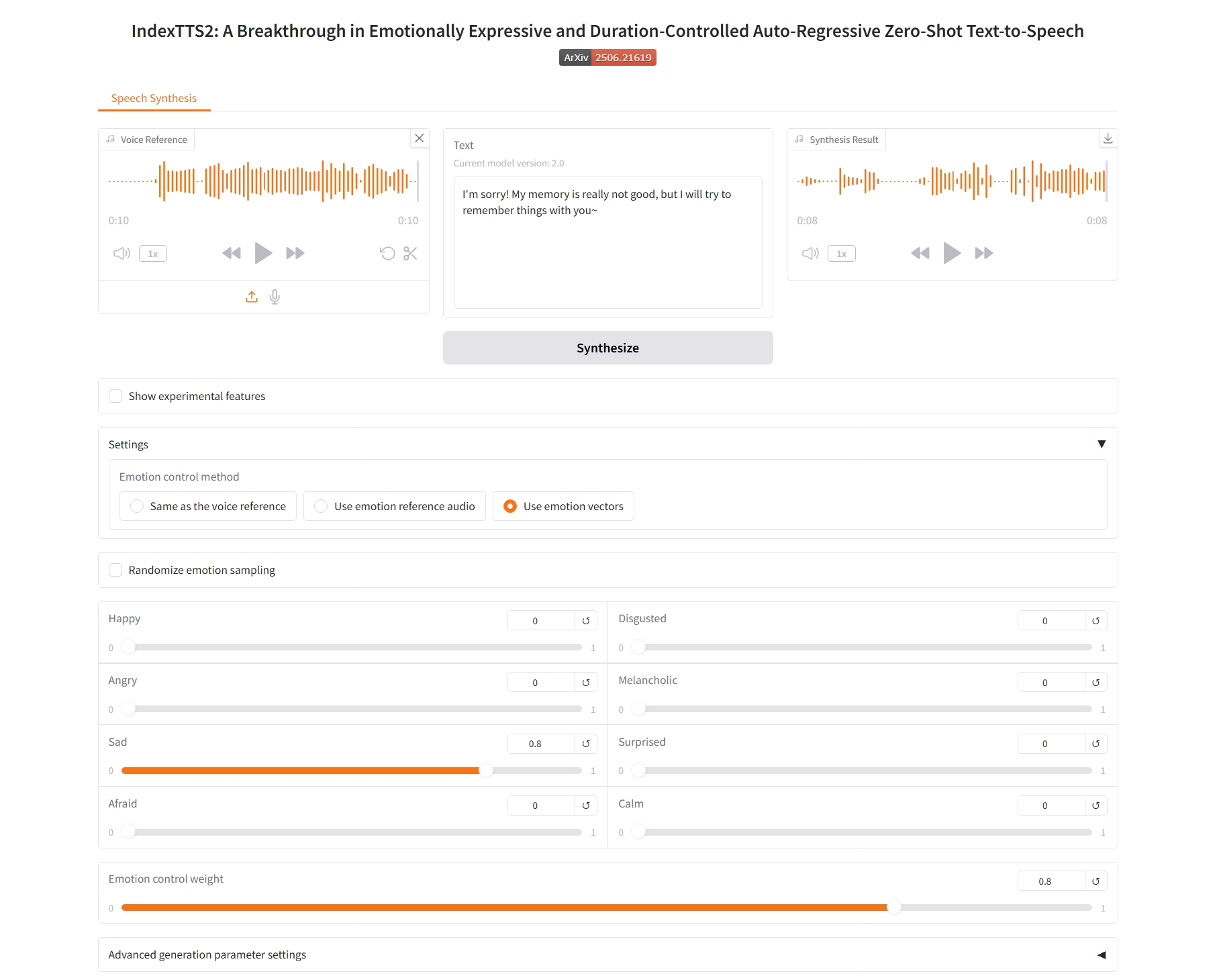
Same as the voice reference
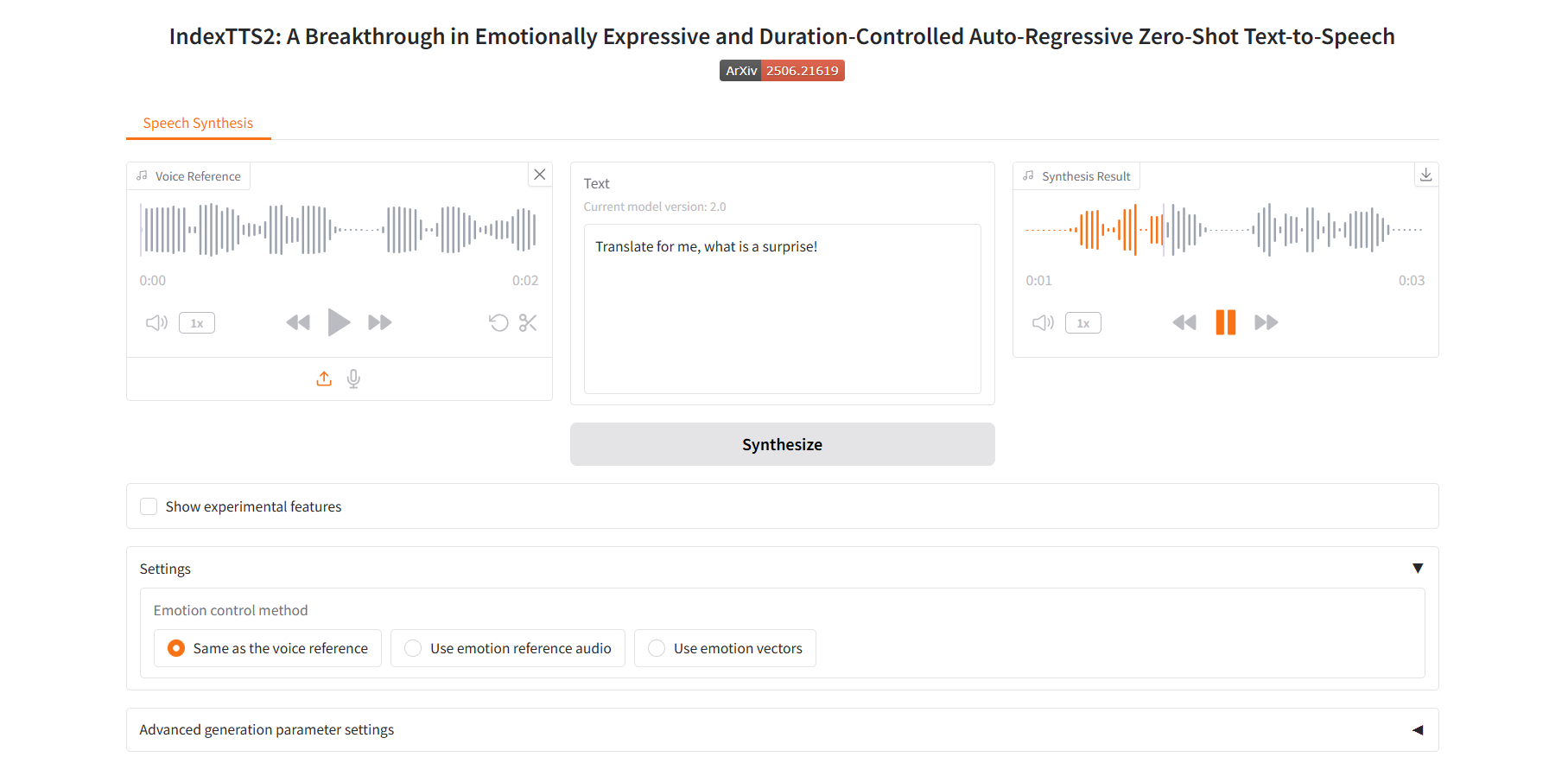
Use emotion reference audio
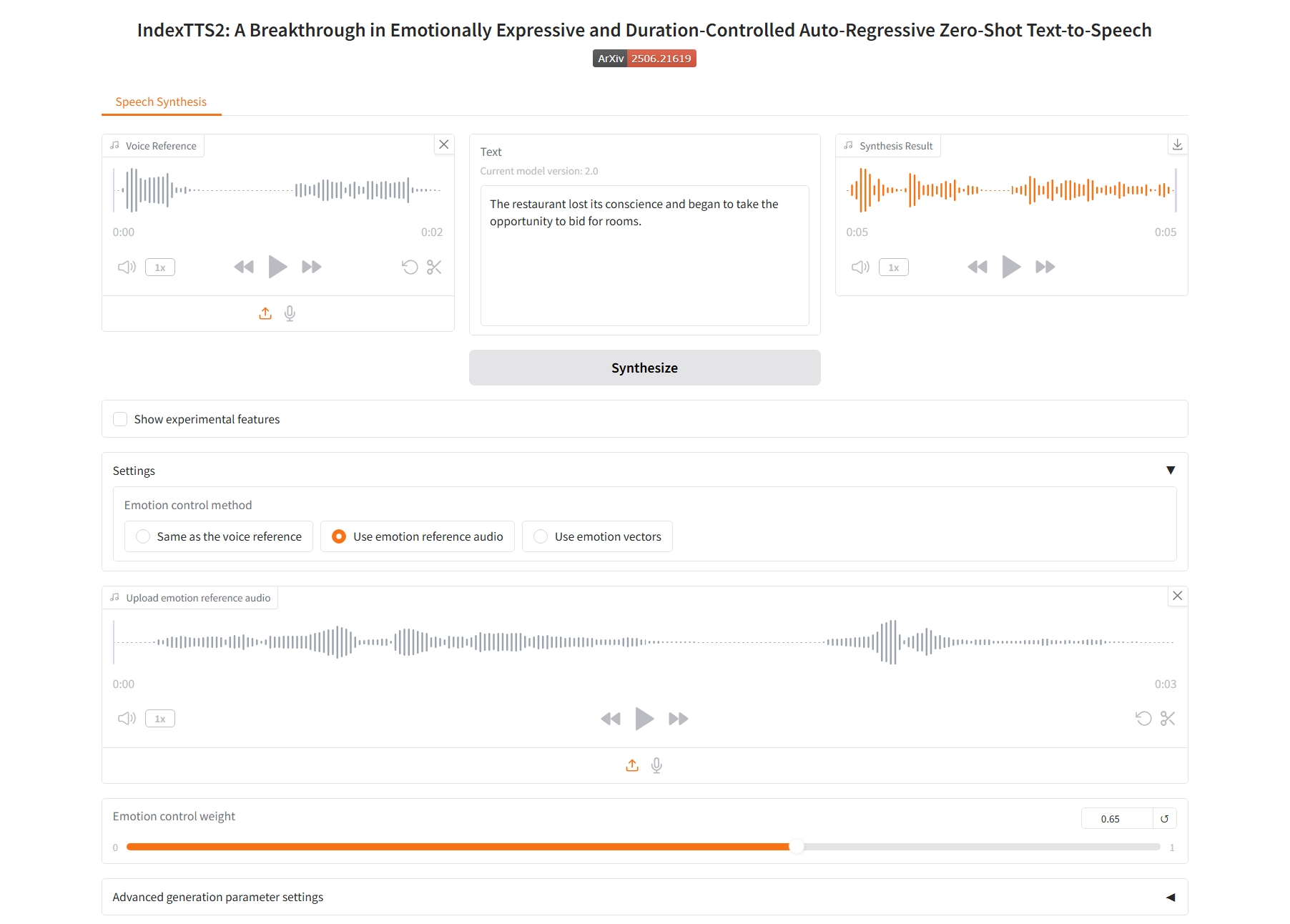
Use emotion vectors
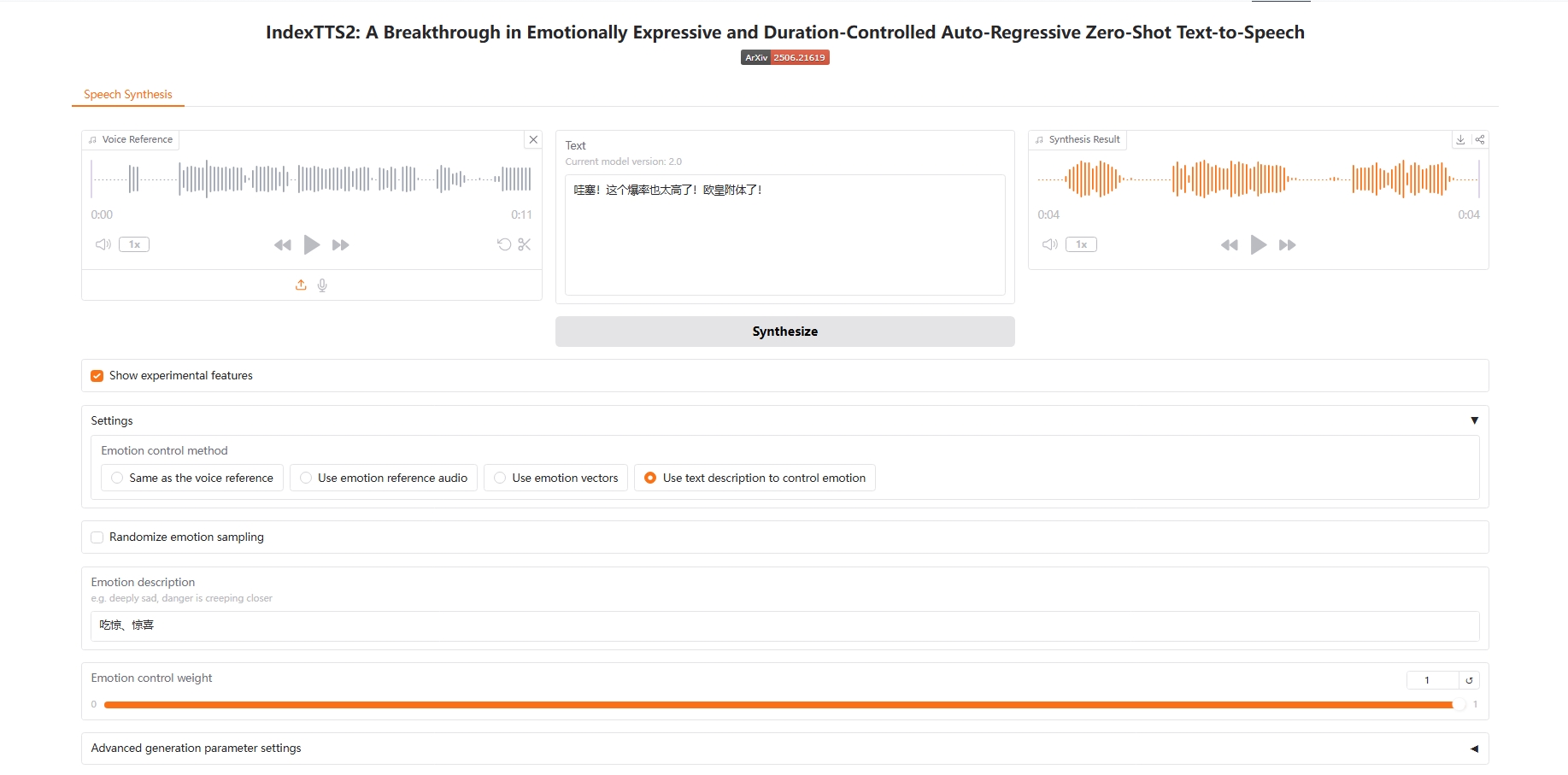
Use text description to control emotion
3. Operation steps
1. Start the container
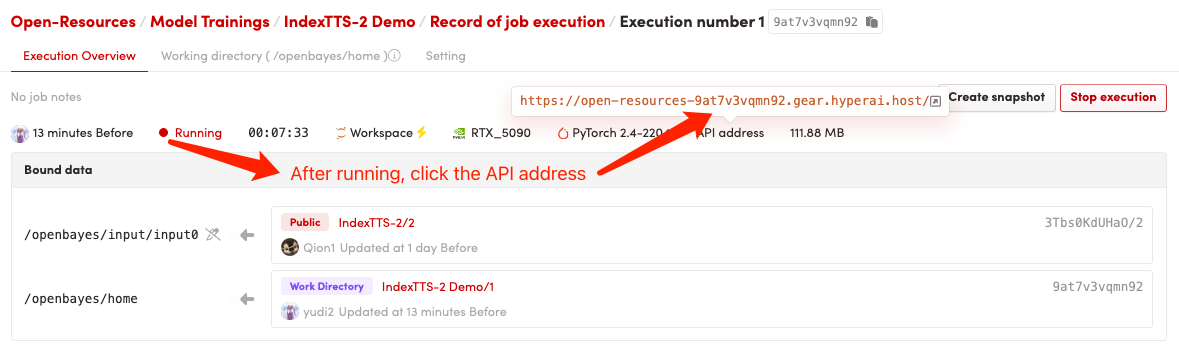
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
1. Same as the voice reference

Specific parameters:
- Advanced parameter settings:
- do_sample: whether to perform sampling.
- Temperature: controls the smoothness of the probability distribution during sampling.
- top_p: kernel sampling.
- top_k: At each generation step, only the K tokens with the highest probability are considered.
- num_beams: beam search width.
- repetition_penalty: Repeat penalty, which reduces the probability of the model generating the same token repeatedly.
- length_penalty: length penalty, which encourages or discourages the model from generating longer or shorter sequences. This is mainly effective when num_beams > 1 is used.
- max_mel_tokens: The maximum number of tokens generated.
2. Use emotion reference audio
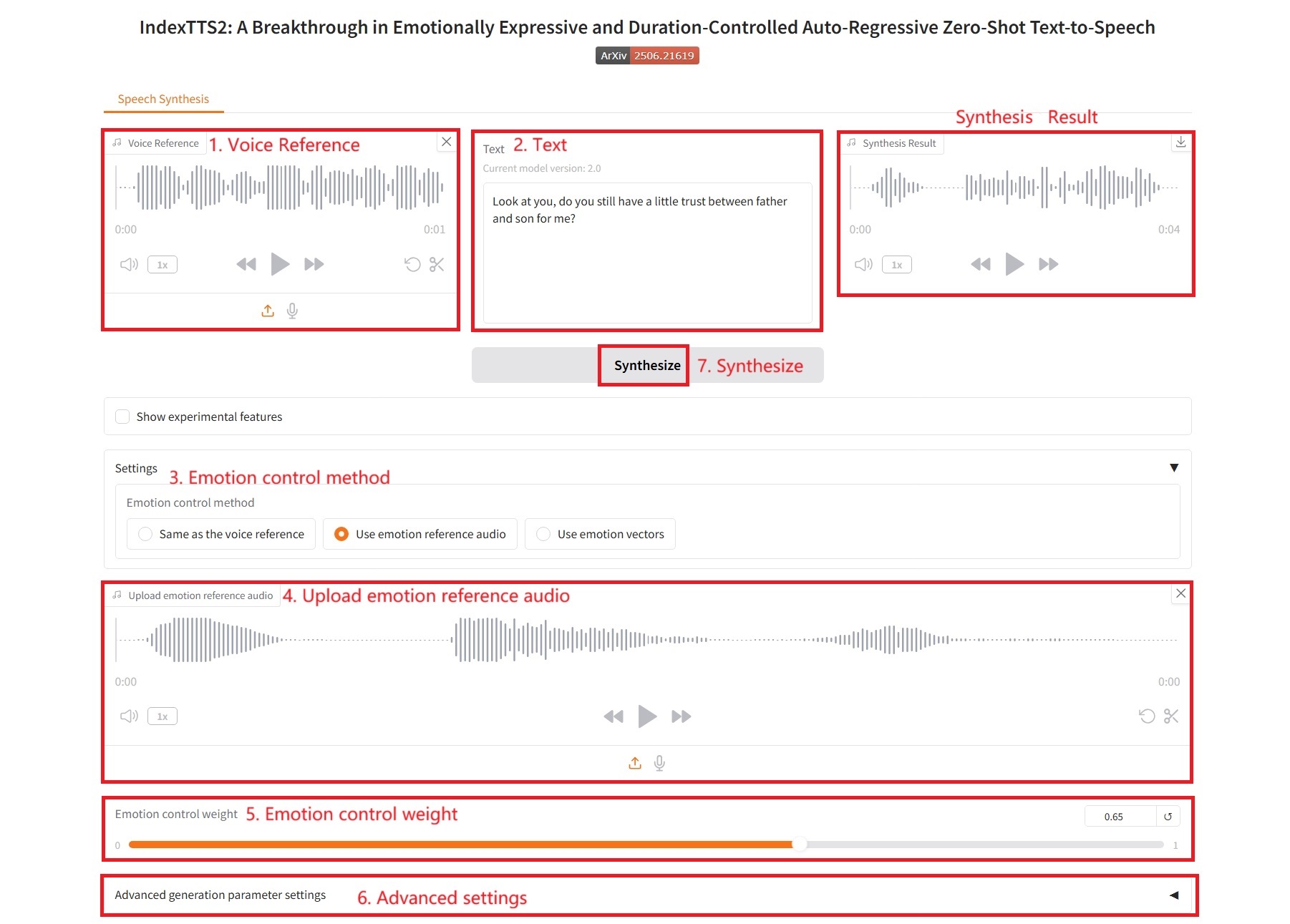
3. Use emotion vectors
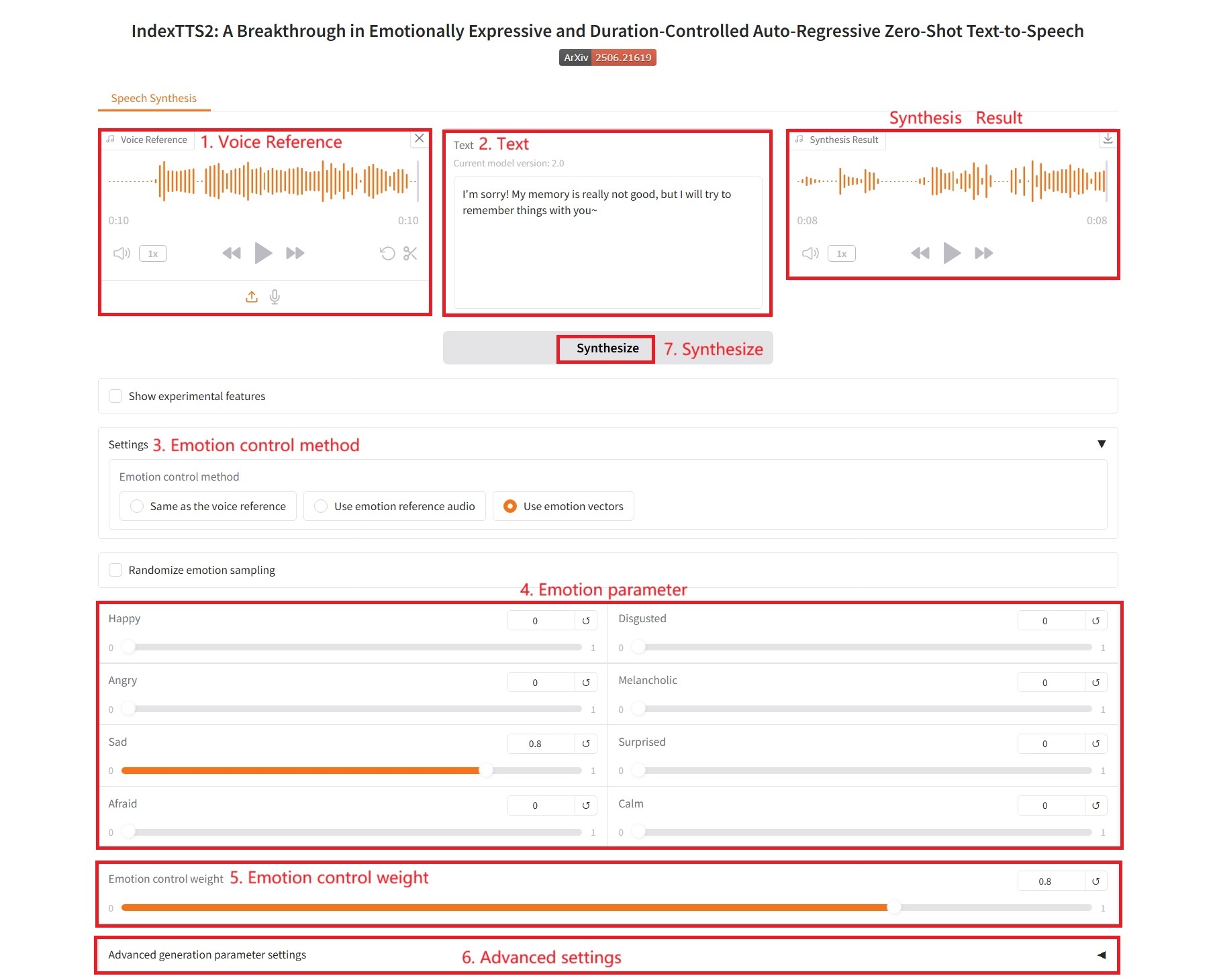
Emotional control parameters:
- Happy, Disgusted, Angry, Melancholic, Sad, Surprised, Afraid, Calm: These correspond to eight basic emotional dimensions. The value of each slider (usually between 0.0 and 1.0) indicates the intensity of the emotion you want to be reflected in the final speech.
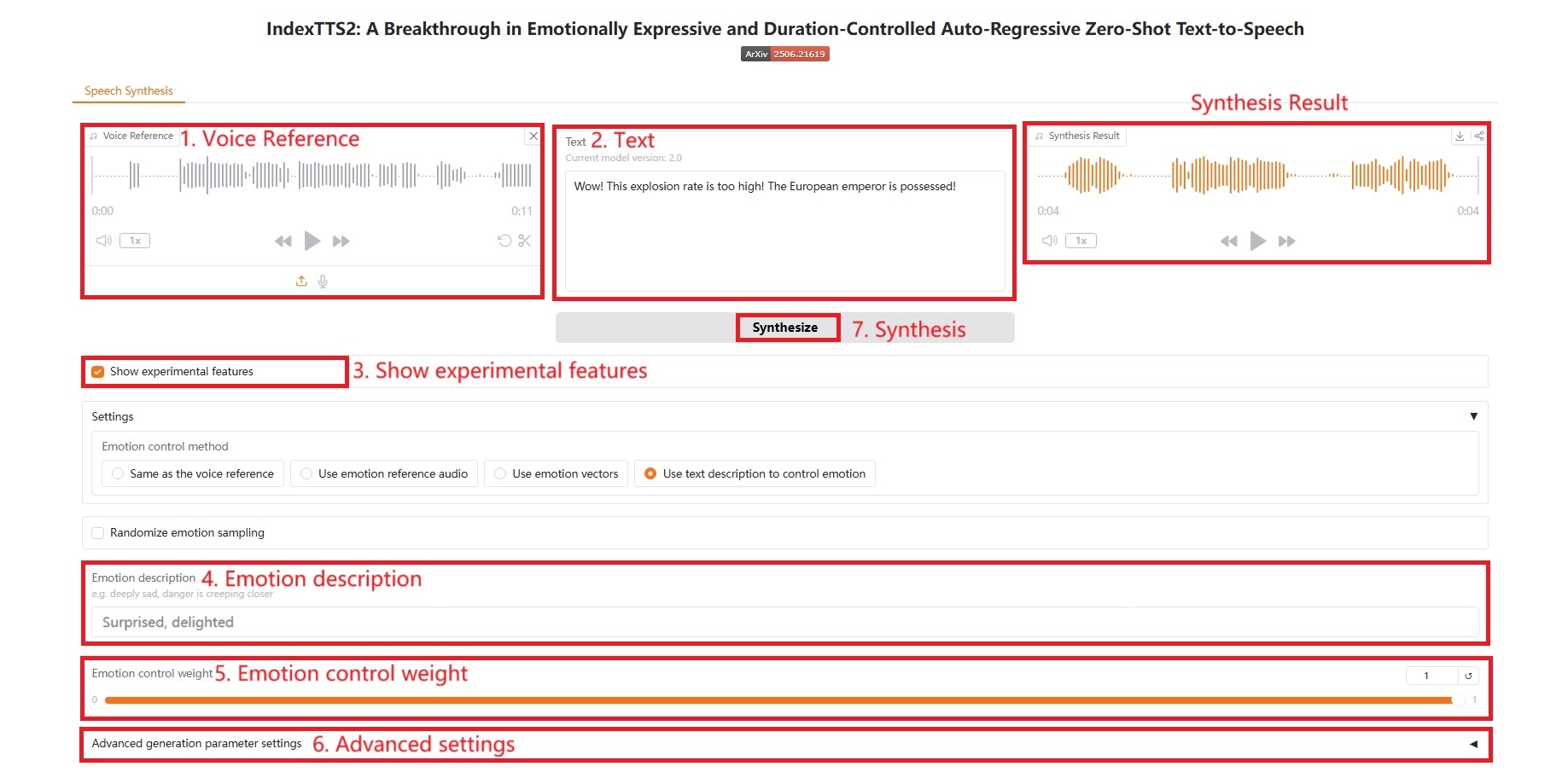
4. Use text description to control emotion
Citation Information
The citation information for this project is as follows:
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.