Command Palette
Search for a command to run...
HuMo-1.7B: A Framework for Multimodal Video Generation
Date
Size
539.81 MB
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

HuMo, released in September 2025 by Tsinghua University and ByteDance's Intelligent Creation Lab, is a multimodal video generation framework focused on human-centered video generation. It can generate high-quality, detailed, and controllable human-like videos from multiple modal inputs, including text, images, and audio. HuMo supports powerful text cue following capabilities, consistent subject preservation, and audio-driven motion synchronization. It supports video generation from text-image (VideoGen from Text-Image), text-audio (VideoGen from Text-Audio), and text-image-audio (VideoGen from Text-Image-Audio), providing users with greater customization and control. Related research papers are available. HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning .
The HuMo project provides model deployment in two specifications: 1.7B and 17B. This tutorial uses the 1.7B model and a single RTX 5090 card as the resource.
→ Click to jump to experienceHuMo 17B: Multimodal Video Generation Framework".
2. Project Examples
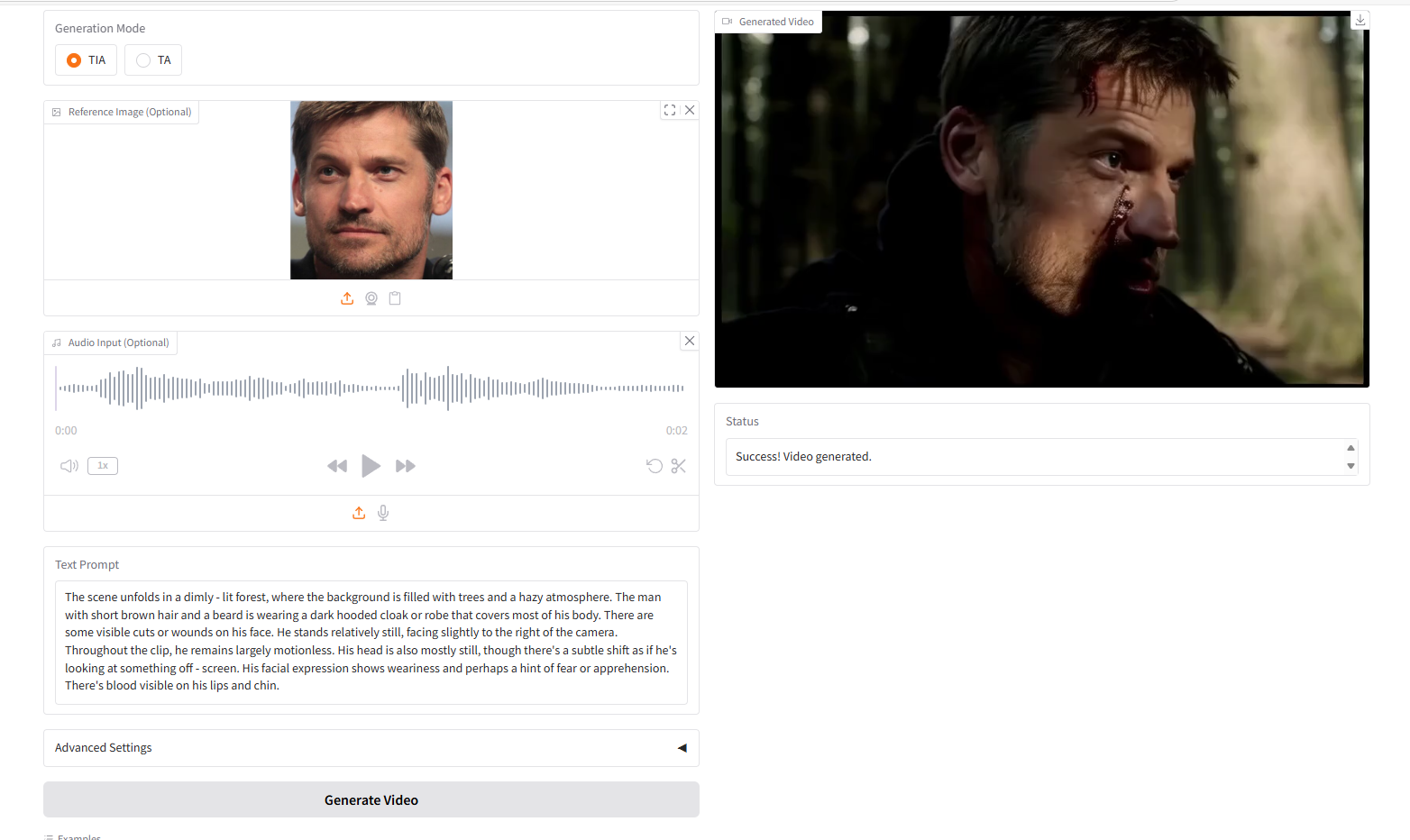
VideoGen from Text-Image-Audio,TIA
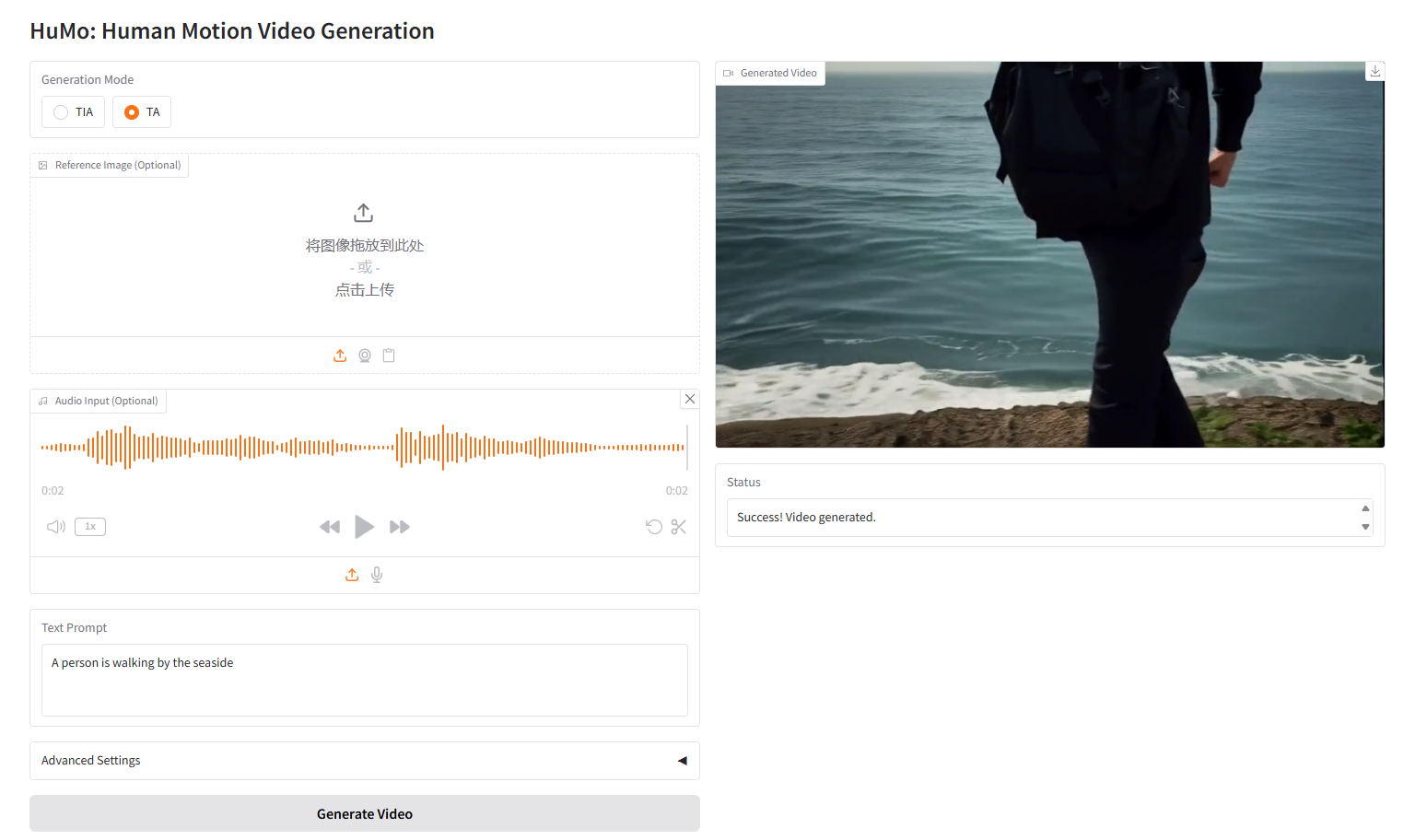
VideoGen from Text-Audio,TA
3. Operation steps
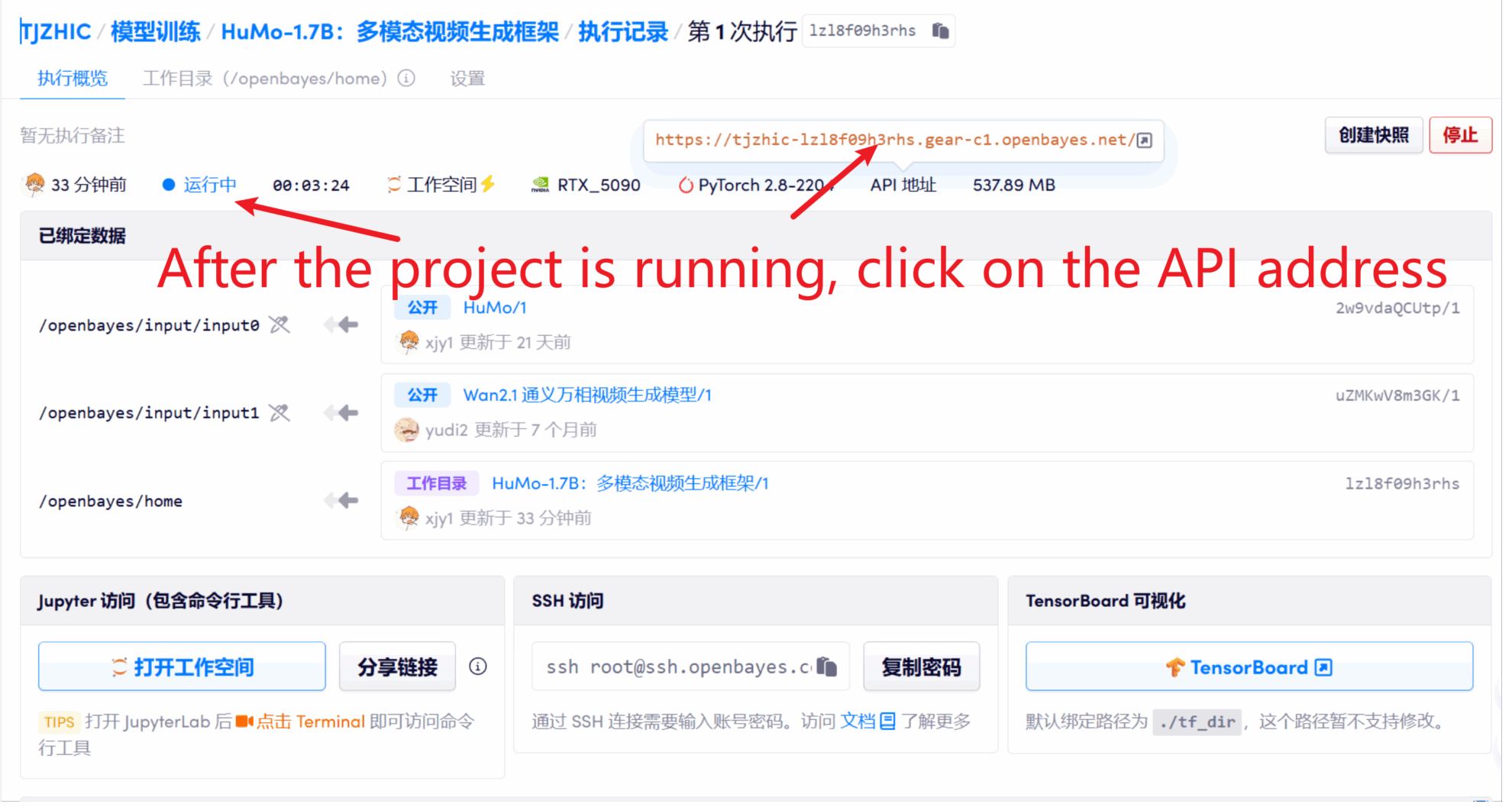
1. After starting the container, click the API address to enter the Web interface
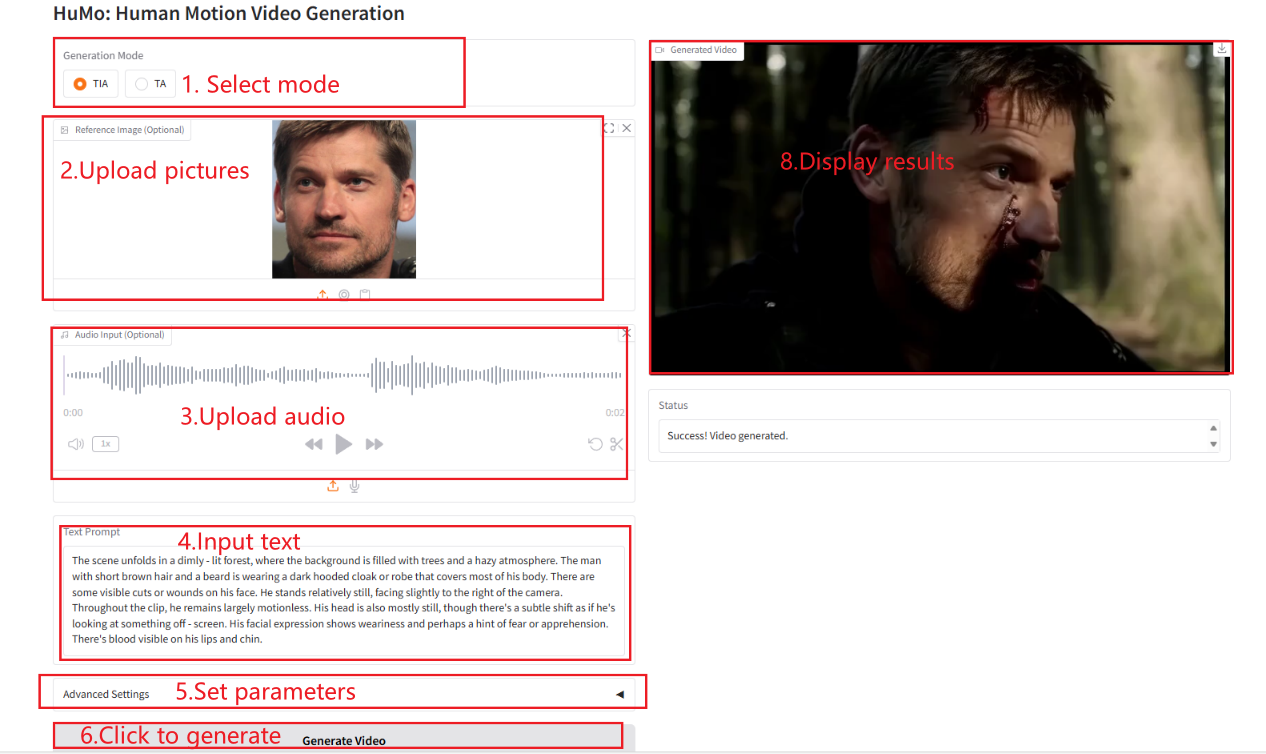
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page. Note: When Sampling Steps is set to 10, it takes approximately 3-5 minutes to generate results.
VideoGen from Text-Image-Audio (TIA)
VideoGen from Text-Audio (TA)
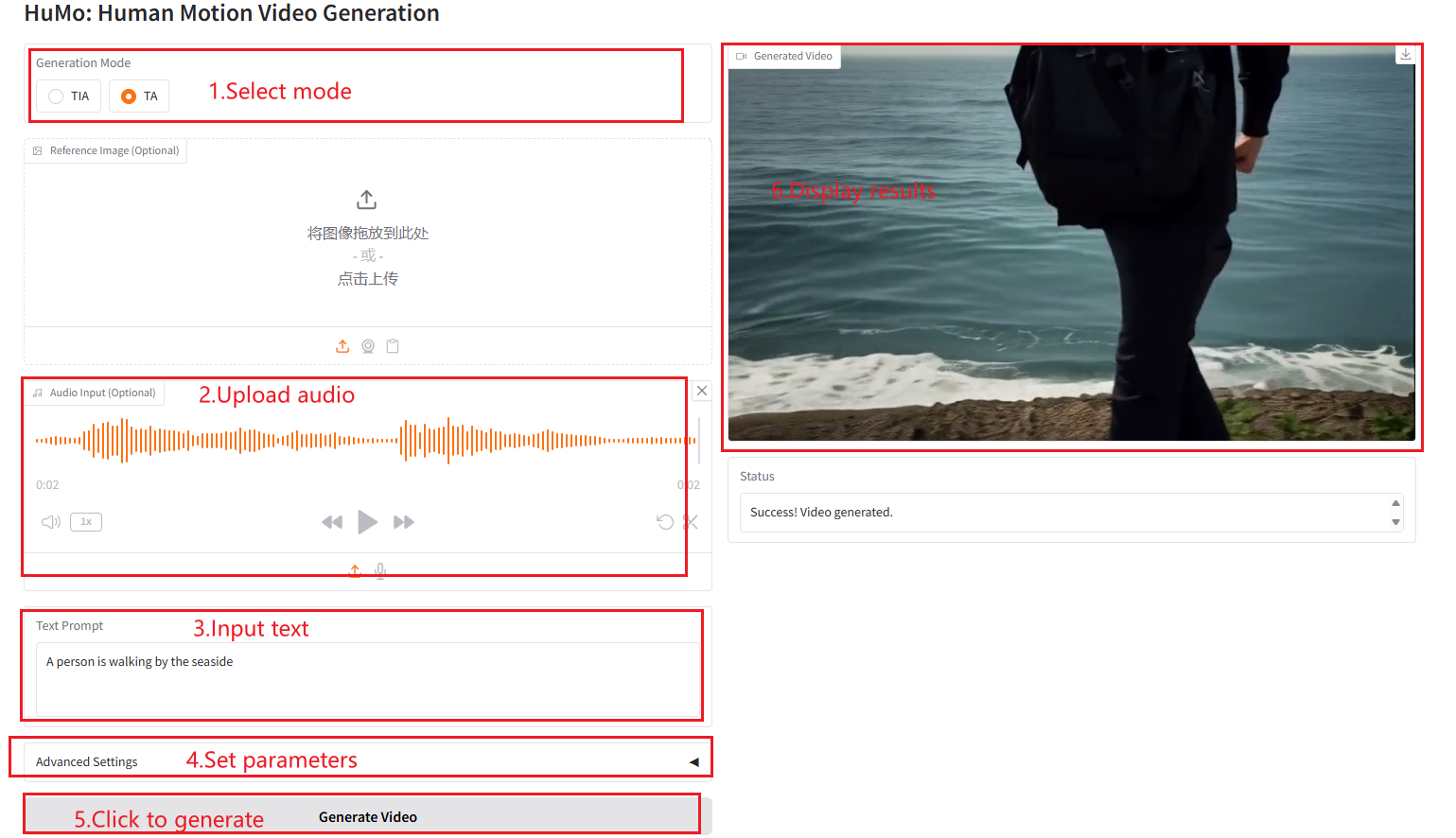
Parameter Description
- Height: Set the height of the video.
- Width: Set the width of the video.
- Frames: Set the number of video frames.
- Text Guidance Scale: Text guidance scaling, used to control the impact of text prompts on video generation.
- Image Guidance Scale: Image guidance scaling, used to control the influence of image cues on video generation.
- Audio Guidance Scale: Audio guidance scaling, used to control the influence of audio cues on video generation.
- Sampling Steps: The number of sampling steps used to control the quality and details of the generated video.
4. Discussion
Citation Information
The citation information for this project is as follows:
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.