Command Palette
Search for a command to run...
HealthGPT: A Medical Large Vision-Language Model for Unifying
Comprehension and Generation via Heterogeneous Knowledge Adaptation
HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heterogeneous Knowledge Adaptation
Abstract
We present HealthGPT, a powerful Medical Large Vision-Language Model (Med-LVLM) that integrates medical visual comprehension and generation capabilities within a unified autoregressive paradigm. Our bootstrapping philosophy is to progressively adapt heterogeneous comprehension and generation knowledge to pre-trained large language models (LLMs). This is achieved through a novel heterogeneous low-rank adaptation (H-LoRA) technique, which is complemented by a tailored hierarchical visual perception approach and a three-stage learning strategy. To effectively learn the HealthGPT, we devise a comprehensive medical domain-specific comprehension and generation dataset called VL-Health. Experimental results demonstrate exceptional performance and scalability of HealthGPT in medical visual unified tasks. Our project can be accessed at https://github.com/DCDmllm/HealthGPT.
One-sentence Summary
The authors from Zhejiang University, University of Electronic Science and Technology of China, Alibaba, The Hong Kong University of Science and Technology, and National University of Singapore propose HealthGPT, a unified autoregressive Medical Large Vision-Language Model that leverages heterogeneous low-rank adaptation (H-LoRA) and hierarchical visual perception to integrate medical image comprehension and generation, outperforming existing models on a new VL-Health dataset for complex healthcare applications.
Key Contributions
-
HealthGPT introduces a unified medical large vision-language model (Med-LVLM) that integrates both visual comprehension and generation within a single autoregressive framework, addressing the gap in existing models that typically focus on one capability at a time, especially in the data-scarce medical domain.
-
The proposed Heterogeneous Low-Rank Adaptation (H-LoRA) method decouples comprehension and generation learning through independent LoRA "plugs" and employs a reversible matrix block multiplication design with LoRA experts, enabling efficient, conflict-free training and reducing computational overhead by 33% compared to MoELoRA.
-
HealthGPT is trained on VL-Health, a comprehensive medical dataset with seven comprehension and five generation tasks, demonstrating state-of-the-art performance across diverse medical multi-modal benchmarks, outperforming both general-purpose and domain-specific models in unified tasks despite limited training data.
Introduction
The authors leverage large vision-language models (LVLMs) to address the growing need for intelligent, multi-functional medical AI systems capable of both understanding and generating medical visual content—critical for applications like diagnostic support, treatment planning, and automated report synthesis. Prior work in medical LVLMs has largely focused on comprehension tasks such as visual question answering or report generation, often lacking robust visual generation capabilities, while unified LVLMs in general domains face challenges in medical settings due to limited high-quality data and inherent conflicts between comprehension (which abstracts details) and generation (which requires fine-grained fidelity). These issues lead to performance degradation when jointly training for both tasks. To overcome this, the authors propose HealthGPT, a unified medical LVLM that uses a novel Parameter-Efficient Fine-Tuning method called Heterogeneous Low-Rank Adaptation (H-LoRA). H-LoRA decouples comprehension and generation learning through task-specific, plug-and-play LoRA modules, mitigating interference and enabling efficient adaptation. It further incorporates a Mixture-of-Experts design with reversible matrix block multiplication to reduce training overhead. A hierarchical visual perception module and a three-stage learning strategy ensure effective knowledge integration. The authors also introduce VL-Health, a comprehensive dataset with diverse medical comprehension and generation tasks. HealthGPT achieves state-of-the-art performance across multiple benchmarks, demonstrating the first effective unification of medical vision-language comprehension and generation under data-constrained conditions.
Dataset
-
The VL-Health dataset is composed of multiple medical-specific and general-purpose multimodal datasets, including VQA-RAD, SLAKE, PathVQA, MIMIC-CXR-VQA, LLaVA-Med, PubMedVision, and LLaVA-1.5, for visual comprehension tasks. For generation tasks, it incorporates data from IXI (for super-resolution), SynthRAD2023 (for modality conversion), MIMIC-CHEST-XRAY (for text-to-image generation), and a reprocessed version of LLaVA-558k (for image reconstruction).
-
The dataset includes 765,802 visual question-answer (VQA) samples for comprehension and 783,045 generation samples for tasks like reconstruction, super-resolution, and modality conversion. Medical image sources span 11 modalities—CT, MRI, X-ray, microscopy, OCT, ultrasound, fundus photography, and others—covering a broad range of diseases from common to rare, including pulmonary, skeletal, brain, cardiovascular, and cellular abnormalities.
-
Data processing involved filtering out multi-image samples to reduce training overhead, standardizing questions into open-ended and single-choice formats, and applying slicing, registration, augmentation, and normalization to scanned images. For generation tasks, 2D images were prepared as visual inputs, and VQGAN-generated indices were used to supervise autoregressive generation.
-
All data is converted into a unified instruction-response format with structured components: task type, task instruction, response, input image, and target image index (for generation tasks). The task type determines the visual feature granularity and selects the appropriate H-LoRA submodule.
-
The model uses the dataset in a three-stage learning strategy, with a mixed-47k subset derived from stage-1 data. Training leverages H-LoRA with rank 16 and 64 and four experts, and the visual encoder uses CLIP-L/14 with features from its second and penultimate layers for hierarchical perception. The f8-8192 VQGAN serves as the image indexing and upsampling module.
Method
The authors leverage a unified autoregressive framework to integrate medical visual comprehension and generation capabilities within a single model, HealthGPT. This framework treats both tasks as sequential token prediction problems, where the model generates either text responses for comprehension or discrete VQGAN index sequences for image generation, using a shared large language model (LLM) backbone. The input to the model consists of a joint sequence of visual and text tokens, which are processed through a series of modules to produce the final output. The overall architecture is designed to handle the distinct requirements of comprehension and generation by dynamically routing visual features and adapting knowledge through specialized modules.
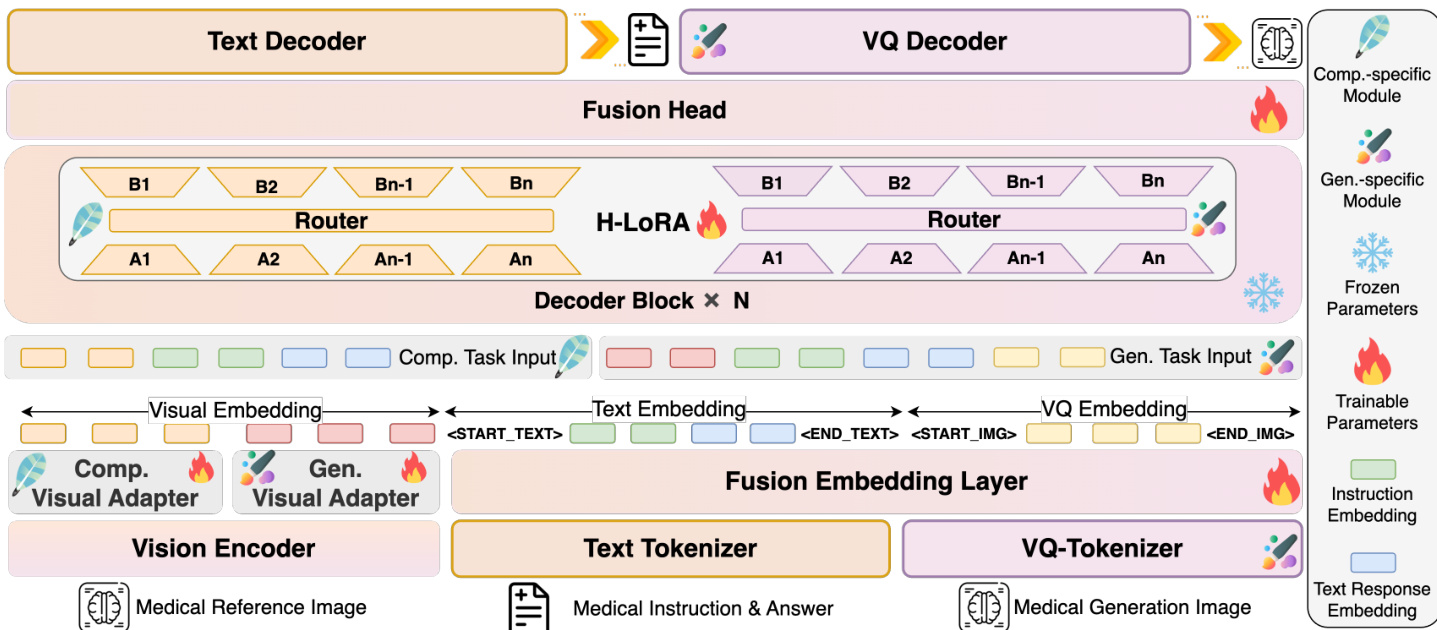
Refer to the framework diagram. The model begins with a vision encoder, which processes a medical reference image to extract visual features. These features are then passed through a visual adapter, which is task-specific: a comprehension-specific adapter for abstract features and a generation-specific adapter for concrete features. The visual features are converted into visual tokens via a visual embedding layer. Concurrently, a medical instruction and answer are processed by a text tokenizer to generate text tokens, which are embedded in the text embedding layer. For generation tasks, a medical generation image is processed by a VQ-tokenizer to produce VQ tokens, which are embedded in the VQ embedding layer. The visual, text, and VQ embeddings are concatenated into a joint sequence, which is fed into the fusion embedding layer. This layer combines the embeddings and adds instruction and task-specific embeddings to guide the model. The fused sequence is then processed by a series of decoder blocks, each containing a fusion head and an H-LoRA module. The H-LoRA module dynamically selects and combines knowledge from task-specific LoRA experts based on the input, enabling efficient adaptation to different tasks. The final output is generated by a text decoder for comprehension tasks or a VQ decoder for generation tasks.
The model employs a hierarchical visual perception approach to address the differing visual requirements of comprehension and generation. The vision encoder, based on a Vision Transformer (ViT), processes the input image to produce a sequence of features at multiple hierarchical levels. These features are divided into two types: concrete-grained features from the shallower layers of the ViT, which contain global information suitable for generation, and abstract-grained features from the deeper layers, which capture semantic information closer to the text space and are suitable for comprehension. The task type determines which set of features is selected as input for the downstream LLM. This selection is performed by a task-specific hard router, which routes the appropriate visual features to the fusion head.
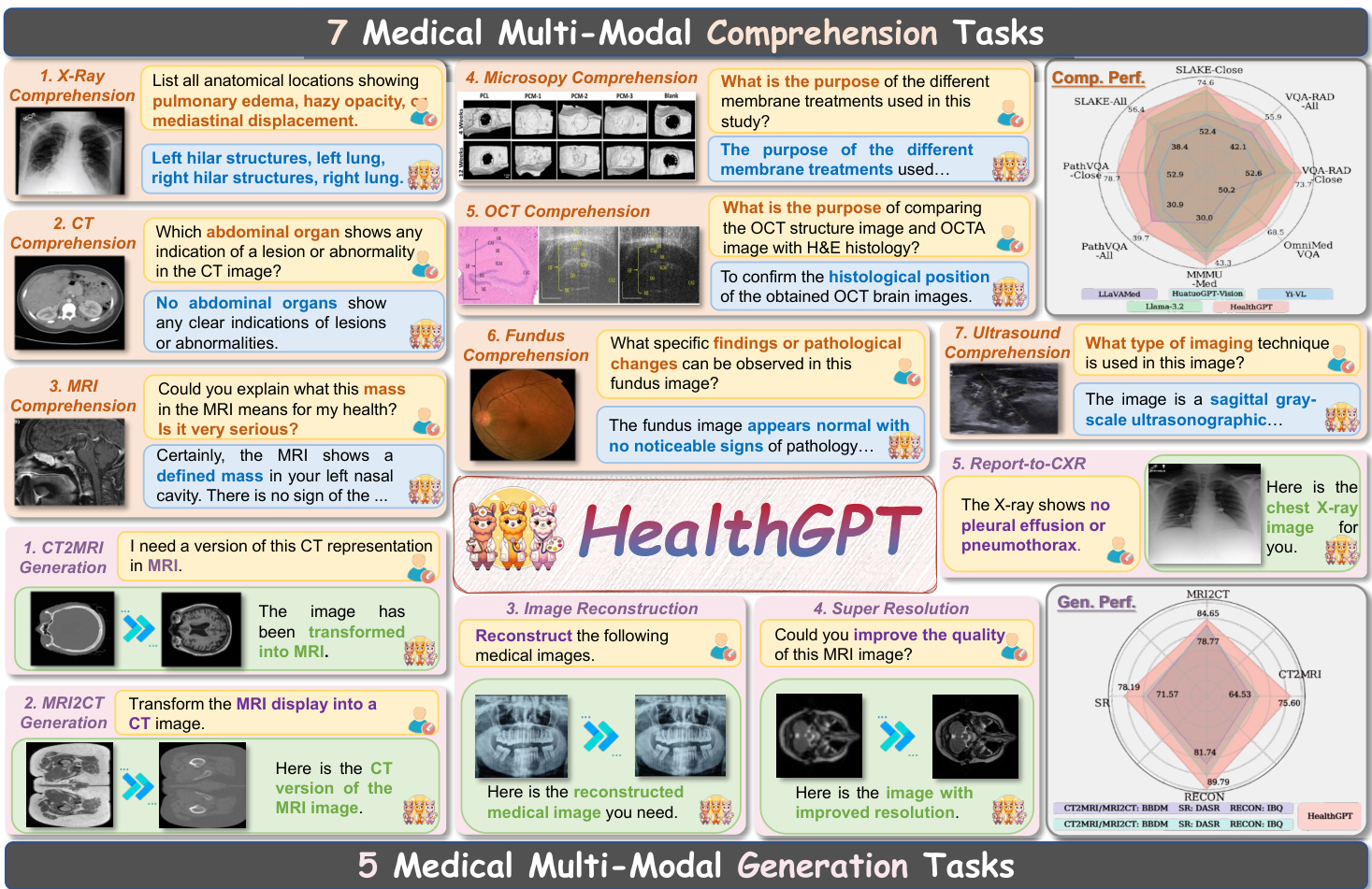
The model's ability to handle diverse medical tasks is illustrated in the figure above, which shows a range of comprehension and generation tasks. For comprehension, the model can answer questions about X-rays, CT scans, MRIs, and other medical images, identifying anatomical structures, abnormalities, and the purpose of medical procedures. For generation, the model can perform tasks such as transforming a CT scan into an MRI, reconstructing medical images from a description, and improving the resolution of an MRI. The model's performance on these tasks is evaluated using a comprehensive medical domain-specific dataset called VL-Health.
The core of the model's adaptation strategy is the heterogeneous low-rank adaptation (H-LoRA) technique. This method stores knowledge from comprehension and generation tasks in separate modules and dynamically routes to extract task-relevant knowledge. At the task level, a dedicated H-LoRA submodule is assigned for each task type. At the feature level, H-LoRA integrates the idea of Mixture of Experts (MoE) but avoids the computational overhead of matrix splitting by merging the low-rank matrices of multiple LoRA experts into a single unified matrix. A routing layer generates expert weights based on the input hidden state, which are then expanded and used to compute the final output through element-wise multiplication and matrix multiplication. This design allows the model to efficiently learn and apply heterogeneous knowledge from different tasks without significant computational delay.
The training process for HealthGPT is structured in three stages to ensure effective learning and model stability. The first stage, multi-modal alignment, involves training separate visual adapters and H-LoRA submodules for medical comprehension and generation tasks. The second stage, heterogeneous H-LoRA plugin adaptation, fine-tunes the word embedding layer and output head using mixed data to ensure consistency across the different H-LoRA plugins, forming a unified base. The third stage, visual instruction fine-tuning, introduces additional task-specific data to further optimize the model and enhance its adaptability to downstream tasks. This staged approach allows the model to accumulate foundational knowledge and effectively mitigate inter-task conflicts, leading to improved performance on both comprehension and generation tasks.
Experiment
-
Main Experiments:
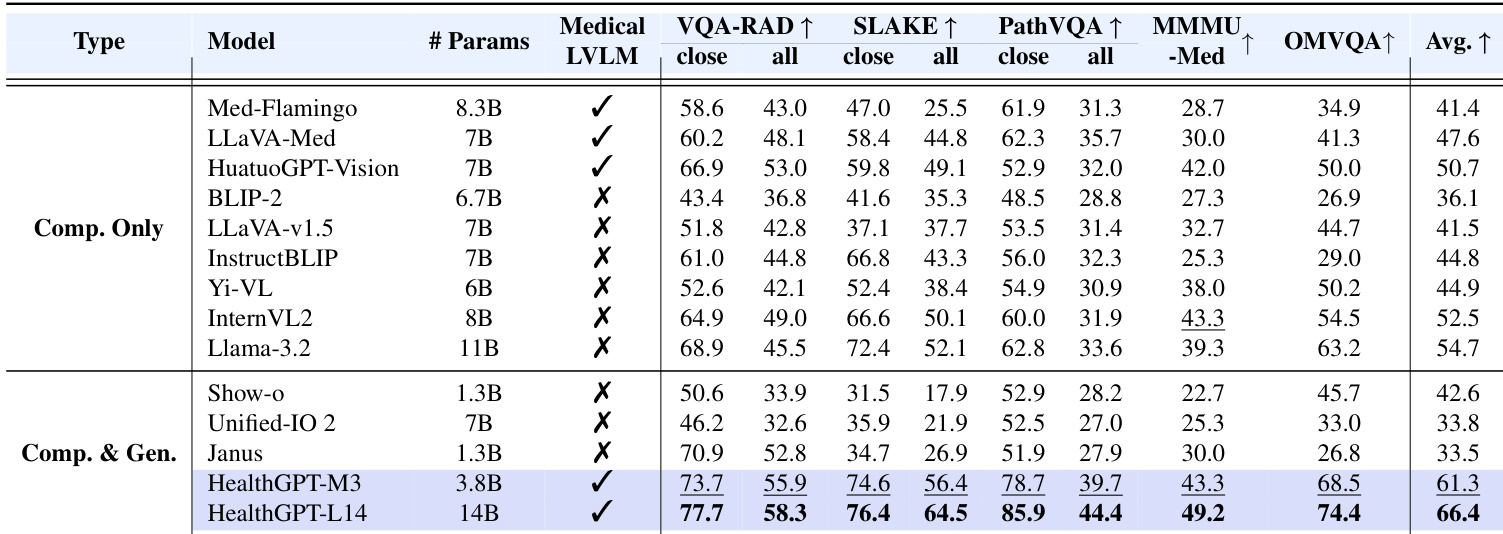
- Medical visual comprehension: HealthGPT-M3 achieves 61.3 on the medical multi-modal unified task, outperforming medical-specific models (e.g., HuatuoGPT-Vision) and general-purpose models (e.g., Llama-3.2), while HealthGPT-L14 reaches 66.4, demonstrating strong scalability.
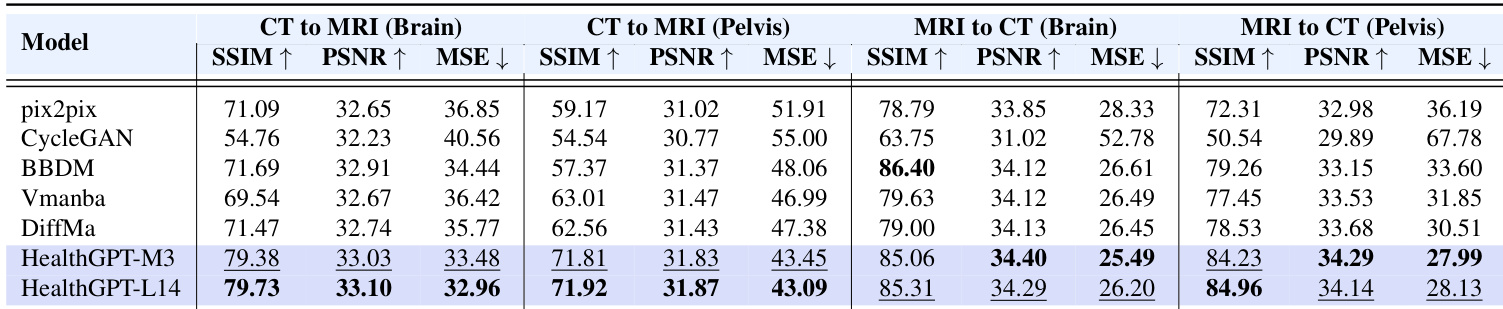
- Modality conversion (CT/MRI): HealthGPT-M3 achieves SSIM of 79.38 in CT2MRI-Brain, surpassing Pix2Pix (71.09) and DiffMa (71.47).
- Super-resolution (4x on IXI): HealthGPT-M3 attains SSIM of 78.19, PSNR of 32.76, ISE of 34.47, and a human perception score of 12.34, significantly outperforming existing methods.
- Image reconstruction: HealthGPT shows superior controllability and stability, outperforming Unified-IO 2 and SEED-X with minimal data.
- Report-to-CXR generation: HealthGPT generates accurate CXR images based on textual instructions, demonstrating potential for medical education and diagnosis.
-
Core Results:
- On OmniMedVQA benchmark, HealthGPT-L14 achieves an average score of 74.4, surpassing all compared models across all sub-tasks.
- In human evaluation on VQA-RAD, SLAKE, and PathVQA, HealthGPT-L14 is ranked as the best response most frequently by clinicians.
- H-LoRA consistently outperforms LoRA and MoELoRA across tasks, with no additional training overhead even at 32 experts, while MoELoRA’s training time increases significantly.
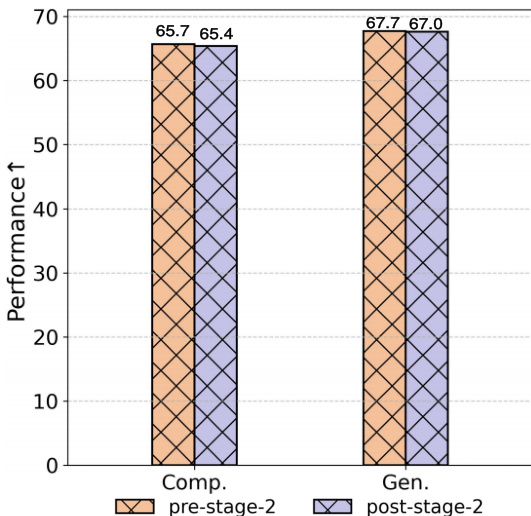
The authors use a three-stage learning strategy to improve performance in medical visual comprehension and generation tasks. Results show that the proposed method achieves higher performance in both tasks after the second stage, with comprehension improving from 65.7 to 67.7 and generation from 65.4 to 67.0.
The authors compare the performance of HealthGPT with MoELoRA and H-LoRA across different numbers of LoRA experts, showing that H-LoRA consistently outperforms MoELoRA in both comprehension and generation tasks while maintaining similar or reduced training time. Results indicate that H-LoRA achieves higher scores across all configurations, with the best performance at n=32, where MoELoRA fails to complete training.

Results show that HealthGPT-M3 and HealthGPT-L14 outperform other models across all sub-tasks in the modality conversion experiment, with HealthGPT-L14 achieving the highest scores in most metrics. Specifically, HealthGPT-M3 achieves SSIM values of 79.38 and 71.81 for CT to MRI conversion in the brain and pelvis, respectively, while HealthGPT-L14 further improves these results to 79.73 and 71.92, demonstrating superior performance in modality transformation tasks.
Results show that HealthGPT-M3 and HealthGPT-L14 outperform all compared models across multiple medical visual comprehension benchmarks, with HealthGPT-L14 achieving the highest average score of 66.4. The authors use a three-stage learning strategy with H-LoRA to enhance performance, demonstrating that their approach significantly surpasses both medical-specific and general-purpose models in medical downstream tasks.
The authors use a three-stage learning strategy to train HealthGPT, which significantly outperforms mixed training across all evaluated tasks. Results show that the three-stage approach achieves higher scores in both comprehension and generation tasks, with improvements ranging from 15.9 to 27.9 points in various benchmarks, demonstrating its effectiveness in reducing task conflicts and enhancing model performance.
