Command Palette
Search for a command to run...
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
ROCKET-2: Steering Visuomotor Policy via Cross-View Goal Alignment
Cai Shaofei Mu Zhancun Liu Anji Liang Yitao
Abstract
We aim to develop a goal specification method that is semantically clear, spatially sensitive, domain-agnostic, and intuitive for human users to guide agent interactions in 3D environments. Specifically, we propose a novel cross-view goal alignment framework that allows users to specify target objects using segmentation masks from their camera views rather than the agent's observations. We highlight that behavior cloning alone fails to align the agent's behavior with human intent when the human and agent camera views differ significantly. To address this, we introduce two auxiliary objectives: cross-view consistency loss and target visibility loss, which explicitly enhance the agent's spatial reasoning ability. According to this, we develop ROCKET-2, a state-of-the-art agent trained in Minecraft, achieving an improvement in the efficiency of inference 3x to 6x compared to ROCKET-1. We show that ROCKET-2 can directly interpret goals from human camera views, enabling better human-agent interaction. Remarkably, ROCKET-2 demonstrates zero-shot generalization capabilities: despite being trained exclusively on the Minecraft dataset, it can adapt and generalize to other 3D environments like Doom, DMLab, and Unreal through a simple action space mapping.
One-sentence Summary
Peking University and University of California, Los Angeles, in collaboration with Team CraftJarvis, propose ROCKET-2, a visuomotor policy that enables human agents to specify goals via segmentation masks from their own camera view, decoupling goal input from the agent’s perspective. By introducing cross-view consistency and target visibility losses, the model achieves robust spatial reasoning and 3× to 6× faster inference than ROCKET-1, eliminating the need for real-time segmentation. Remarkably, ROCKET-2 demonstrates zero-shot generalization across diverse 3D environments like Doom, DMLab, and Unreal Engine, showcasing its potential as a universal decision-making agent for embodied AI.
Key Contributions
- The paper introduces a novel cross-view goal alignment framework that enables human users to specify target objects in 3D environments using segmentation masks from their own camera view, decoupling goal specification from the agent’s perspective to improve intuitiveness and flexibility in human-agent interaction.
- To overcome the challenges of partial observability and view discrepancies, the authors propose two auxiliary losses—cross-view consistency loss and target visibility loss—enabling ROCKET-2 to autonomously track targets across different camera views without requiring real-time segmentation, resulting in 3× to 6× faster inference compared to ROCKET-1.
- ROCKET-2 demonstrates strong zero-shot generalization, successfully adapting to diverse 3D environments like Doom, DMLab, and Unreal through simple action space mapping despite being trained exclusively on Minecraft data, highlighting the domain-agnostic nature of the proposed cross-view alignment approach.
Introduction
The authors address the challenge of enabling intuitive, efficient human-agent interaction in partially observable 3D environments, where traditional goal specification methods—such as language or agent-centric visual cues—struggle with spatial ambiguity, real-time constraints, and poor generalization. Prior approaches relying on agent-view segmentation or trajectory sketches fail when targets are occluded or when camera perspectives diverge between human and agent, limiting scalability and robustness. To overcome this, the authors introduce ROCKET-2, a visuomotor policy trained via goal-conditioned imitation learning with a novel cross-view goal alignment framework. The key innovation lies in allowing humans to specify targets using segmentation masks from their own camera view, while the agent learns to align these goals with its own egocentric observations. This is enabled by two auxiliary losses: cross-view consistency loss, which enforces accurate spatial prediction of target centroids across views, and target visibility loss, which helps detect occlusions. As a result, ROCKET-2 eliminates the need for real-time segmentation during inference, achieving 3× to 6× faster execution than ROCKET-1. Remarkably, despite being trained exclusively on Minecraft data, ROCKET-2 demonstrates zero-shot generalization to diverse 3D environments like Doom, DMLab, and Unreal Engine through simple action space mapping, highlighting its domain-agnostic design and potential for scalable, universal policy learning.
Dataset
- The dataset comprises 1.6 billion frames of human gameplay from Minecraft, collected by OpenAI (Baker et al., 2022), featuring fine-grained interaction events such as mining, crafting, item usage, and combat.
- Each interaction is annotated with frame-level object masks that identify the target entity involved, ensuring all masks for a given event correspond to the same object.
- For training, one masked frame is randomly selected per interaction to serve as a cross-view goal specification, enabling the model to learn alignment between its current egocentric view and high-level goals from alternative perspectives.
- The interaction types used—use, break, approach, craft, and kill entity—follow the taxonomy from ROCKET-1 and cover a wide range of task structures and object affordances.
- The dataset supports training ROCKET-2 on diverse skills including combat, Ender portal discovery, bridge building, ore mining, and crafting, with visual goal understanding enhanced through masked, circled regions in cross-view inputs.
- During training, the model leverages the mixture of these interaction types and their associated masked frames to develop robust 3D visual goal alignment and action prediction capabilities.
Method
The authors leverage a multi-stage architecture to address the challenge of cross-view goal specification in embodied environments, enabling a visuomotor policy to interpret human-provided segmentation masks from arbitrary camera views. The overall framework, as illustrated in the diagram, processes both the agent's current observations and the cross-view goal condition through a sequence of spatial and temporal modules to generate actions, object centroids, and visibility predictions.
The method begins with encoding visual inputs. For each frame ot, a DINO-pretrained ViT-B/16 encoder processes the RGB image, producing a sequence of 196 tokens {o^ti}i=1196. Concurrently, the segmentation mask mt is encoded using a trainable ViT-tiny/16, yielding a corresponding token sequence {m^ti}i=1196. The cross-view condition (og,mg) is fused by concatenating the feature channels of the corresponding visual and mask tokens, which are then passed through a feed-forward network to produce the fused condition representation hgi.
Refer to the framework diagram to understand the spatial fusion process. The token sequences from the current observation and the fused cross-view condition are concatenated into a single sequence of length 392. A non-causal Transformer encoder is applied to this sequence to perform spatial fusion, resulting in a frame-level representation xt. This step allows the model to align visual features from the agent's perspective with the semantic information from the human's goal view, leveraging the self-attention mechanism to capture spatial relationships across the two views.
To capture temporal dependencies, the frame-level representations xt are fed into a causal TransformerXL architecture. This module processes the sequence of representations {xi}i=1t along with the interaction event cg to generate a temporal context ft. The causal nature of this Transformer ensures that the policy's decisions at time t are based only on past and current observations, which is essential for real-time control. The temporal context ft is then passed to a light network that predicts the action a^t, the centroid of the target object p^t, and the visibility of the target object v^t. The model is trained to minimize a cross-entropy loss over these predictions, which includes the behavior cloning loss for actions and auxiliary losses for centroid and visibility prediction.
Experiment
- ROCKET-2 achieves 3× to 6× faster inference than ROCKET-1 on the Minecraft Interaction Benchmark, matching or surpassing its peak performance across most tasks, with success rates exceeding 90% on key interaction tasks such as Hunt, Mine, and Navigate.
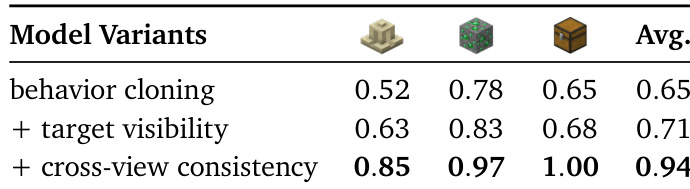
- On the Minecraft Interaction Benchmark, ROCKET-2 attains 94% average success rate with full auxiliary losses (behavior cloning + target visibility + cross-view consistency), outperforming the BC-only variant (65%) and demonstrating the critical role of vision-based auxiliary objectives.
- ROCKET-2 exhibits zero-shot generalization to unseen 3D environments, achieving 12% higher success than a strong baseline on the ATEC 2025 Robotics Challenge in Unreal Engine, despite no fine-tuning and differing observation resolution (640×480 vs. 640×360).
- Cross-episode cross-view goal alignment enables ROCKET-2 to interpret goal specifications from different episodes and biomes, successfully inferring semantic intent (e.g., building a bridge or finding a house) even without visual landmark overlap.
- Landmark attention visualization confirms ROCKET-2 implicitly learns spatial alignment, effectively matching non-goal landmarks across views under geometric deformations and distance variations, indicating robust cross-view perception.
- ROCKET-2 demonstrates strong generalization across diverse 3D environments (Unreal Engine, Doom, DeepMind Lab, Steam games) via rule-based action mapping, performing complex tasks like defeating the Ender Dragon and constructing bridges without environment-specific adaptation.
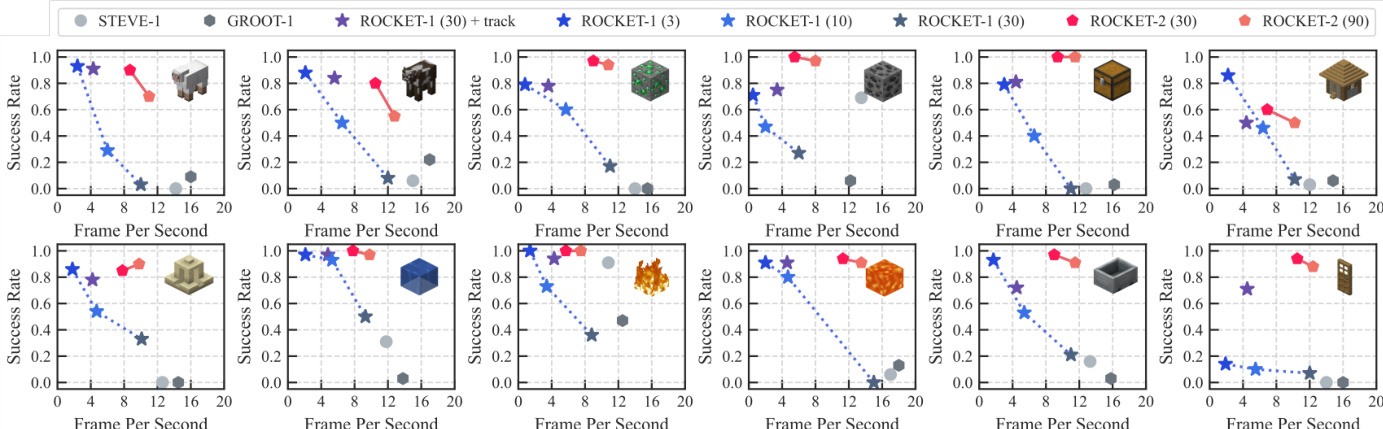
The authors use the Minecraft Interaction Benchmark to evaluate agent performance across six task categories, with success rates measured against inference speed. Results show that ROCKET-2 achieves comparable or superior success rates to ROCKET-1 while operating at significantly higher frame rates, demonstrating a 3× to 6× inference speedup without sacrificing task performance.
The authors use an ablation study to evaluate the impact of auxiliary objectives on model performance, comparing three variants: behavior cloning only, behavior cloning with target visibility loss, and the full model with cross-view consistency loss. Results show that adding target visibility loss improves the average success rate by 6%, while incorporating cross-view consistency loss further boosts it to 94%, demonstrating the effectiveness of these auxiliary losses in enhancing cross-view goal alignment.
The authors use the ATEC 2025 Robotics Challenge to evaluate ROCKET-2's zero-shot generalization to an unseen Unreal Engine environment, where it outperforms a strong baseline by 12% despite not being fine-tuned on the target domain. Results show that ROCKET-2 achieves a 38% success rate, ranking first among 57 agents, while the YOLO-Gemma 3 baseline achieves 26% success and ranks 20th.

The authors use a ViT-base/16 (DINO-v1) backbone for the view encoder and a ViT-tiny/16 (1-channel) mask backbone, with a PyTorch Transformer as the spatial transformer and a TransformerXL for temporal modeling. The model is trained with AdamW optimizer and a learning rate of 0.00004, using 128-step trajectory chunks and 4 spatial and temporal transformer blocks.
Results show that ROCKET-2 achieves comparable or superior performance to ROCKET-1 while significantly improving inference speed, as it decouples goal specification from the agent's current view and uses cross-view segmentation with a single third-person view update every 60 steps. This design enables faster inference with a 3× to 6× speedup compared to ROCKET-1, which relies on frequent mask generation every 3 to 30 steps.
