Command Palette
Search for a command to run...
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models
Abstract
This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
One-sentence Summary
The authors from Alibaba Group propose Wan, a scalable open-source video foundation model suite featuring a novel spatio-temporal VAE and large-scale pre-training, enabling state-of-the-art performance in text-to-video generation with dual 1.3B and 14B variants, supporting multilingual output and consumer-grade efficiency, and advancing video creation through comprehensive openness and automated evaluation.
Key Contributions
-
Wan introduces a novel spatio-temporal variational autoencoder (VAE) and a diffusion transformer-based architecture, enabling high-fidelity video generation with precise motion control, text controllability, and support for both Chinese and English visual text, addressing key limitations in existing open-source models.
-
The 14B parameter model is trained on a large-scale dataset of billions of images and videos, demonstrating state-of-the-art performance across multiple benchmarks and outperforming both open-source and commercial models, while the 1.3B variant achieves exceptional efficiency with only 8.19 GB VRAM, enabling consumer-grade GPU deployment.
-
Wan is fully open-sourced, including code, models, training pipelines, and automated evaluation metrics, and supports diverse downstream tasks such as image-to-video, instruction-guided editing, personalization, and real-time video generation, significantly advancing accessibility and innovation in the video generation community.
Introduction
The authors leverage the success of diffusion-based video generation, particularly Diffusion Transformers (DiT) and Flow Matching, to develop Wan—a high-performance, open-source foundational video model designed to bridge the gap between open-source and commercial systems. This work is critical in advancing accessible, scalable video synthesis, where prior open-source models lagged in performance, capability breadth, and inference efficiency, especially for creative professionals with limited hardware. To address these challenges, the authors introduce Wan, a 14-billion-parameter model trained on a massive dataset of billions of images and videos (O(1) trillion tokens), enabling state-of-the-art results in motion quality, text controllability, camera motion, and stylistic diversity. The model incorporates a spatio-temporal variational autoencoder and a fully optimized DiT architecture with efficient inference techniques, including diffusion caching, quantization, and parallelism strategies. Notably, they also release a lightweight 1.3B variant that runs on consumer GPUs (8.19GB VRAM), significantly improving accessibility. Beyond the core model, the authors present a unified framework for video editing, image-to-video generation, personalization, real-time streaming, and audio generation, all built on Wan’s foundation. They further open-source the full training pipeline, evaluation protocols, and design insights to empower community-driven innovation in video generation.
Dataset
- The dataset is built on billions of videos and images sourced from internal copyrighted materials and publicly available data, emphasizing high quality, diversity, and scale.
- A four-step data cleaning pipeline filters out low-quality content based on fundamental dimensions: text coverage (via lightweight OCR), aesthetic quality (using LAION-5B classifier), NSFW content (via internal safety model), watermarks/logos (detection and cropping), black borders (heuristic-based cropping), overexposure (expert classifier), synthetic images (specialized classifier), blur (internal blur scoring model), and duration/resolution constraints (minimum 4 seconds, resolution thresholds per stage). This reduces the initial dataset by ~50%.
- Visual quality is refined through clustering (100 clusters) and scoring: data is split into clusters to preserve long-tail diversity, then manually scored (1–5) and used to train an expert model for full dataset scoring.
- Motion quality is assessed across six tiers: optimal motion (smooth, rich movement), medium-quality motion (noticeable but imperfect), static videos (low motion, high quality), camera-driven motion (camera movement only), low-quality motion (crowded, occluded), and shaky footage (excluded). Sampling ratios are adjusted dynamically per training phase to balance motion, quality, and category distribution.
- For visual text generation, the authors synthesize hundreds of millions of text-containing images with Chinese characters on white backgrounds and collect real-world text-rich images. OCR models extract text from images/videos, which are fed into Qwen2-VL to generate accurate, descriptive captions, combining synthetic and real data to improve glyph accuracy and realism.
- Post-training data is processed separately: high-scoring images are refined via expert-based (top 20% by model score) and manual collection to ensure quality, composition, and category diversity, resulting in millions of curated images. For videos, top-ranked clips are selected based on visual quality and motion classification, with separate collections for simple and complex motion, balanced across 12 major categories (e.g., animals, vehicles, technology).
- Dense video captions are generated using an internal caption model trained on open-source vision-language datasets (image and video captions, visual Q&A, OCR) and in-house data. The in-house data includes: celebrity/landmark/character identities (via LLMs and TEAM model retrieval with keyword filtering), object counting (using LLMs and Grounding DINO for validation), OCR-augmented captions (using OCR output as prior), camera angle and motion annotations (to improve motion controllability), fine-grained categories (millions of images), relational understanding (spatial relationships), re-captioning (expanding brief tags), editing instructions (difference descriptions), group image descriptions, and human-annotated dense captions (highest quality, used in final training).
- During joint training, the same T2V dataset is used to enable image-driven video generation. For image-to-video (I2V), videos are filtered based on cosine similarity between the first frame and the mean of subsequent frames (SigLIP features), retaining only those with high similarity to ensure consistency.
- For video continuation, videos are filtered based on similarity between the first 1.5 seconds and last 3.5 seconds (SigLIP features) to ensure temporal coherence.
- For first-last frame transformation tasks, data with significant visual transition between start and end frames is prioritized to improve smoothness.
- For controllable generation and editing, videos undergo shot slicing, resolution/aesthetic/motion filtering, and first-frame labeling via RAM. Grounding DINO detects objects for secondary filtering (size constraints), and SAM2 enables instance-level segmentation. Temporal filtering is applied based on mask area thresholds to retain stable, meaningful instances.
- Personalization data is constructed by filtering ~100M videos using human classifiers, face detection (1 FPS), and ArcFace similarity across frames (discarding videos with multiple faces or low face presence). Face segmentation removes backgrounds, and landmark detection enables alignment. This yields ~10M personalized videos with ~5 segmented faces per video on average.
- To boost facial diversity, ~1M personalized videos are used as input to Instant-ID with randomized style prompts (e.g., anime, cinematic, Minecraft) and pose estimates, generating diverse faces. Generated faces are filtered via ArcFace similarity to ensure identity consistency, resulting in ~1M additional personalized videos with enhanced variation in style, pose, lighting, and occlusion.
Method
The Wan video generation framework is built upon a diffusion transformer (DiT) architecture, which is structured around three primary components: a spatio-temporal variational autoencoder (Wan-VAE), a diffusion transformer, and a text encoder. The overall process begins with the input video, which is first compressed into a lower-dimensional latent space by the Wan-VAE. This encoder reduces the spatio-temporal dimensions of the video by a factor of 4×8×8, transforming the input from [1+T,H,W,3] to [1+T/4,H/8,W/8,C]. The compressed latent representation is then fed into the diffusion transformer, which models the denoising process to generate the final video. The text encoder, specifically the umT5 model, processes the input text prompt and provides textual conditioning to the diffusion transformer via cross-attention mechanisms. This integration allows the model to generate videos that are semantically aligned with the provided text. The framework is designed to be highly scalable and efficient, enabling the generation of high-quality videos across various applications.
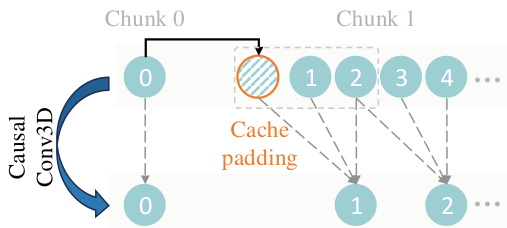
The Wan-VAE is a novel 3D causal variational autoencoder specifically designed to address the challenges of video generation, including capturing complex spatio-temporal dependencies, managing high-dimensional data, and ensuring temporal causality. The architecture is built to achieve a bidirectional mapping between the high-dimensional pixel space and the low-dimensional latent space. It employs a 3D causal convolutional structure, where the first frame is spatially compressed to better handle image data, while the remaining frames undergo spatio-temporal compression. To preserve temporal causality, all GroupNorm layers are replaced with RMSNorm layers, which enables the use of a feature cache mechanism. This mechanism is crucial for efficient inference, as it allows the model to process arbitrarily long videos by dividing them into chunks and maintaining frame-level feature caches from preceding chunks. This ensures temporal continuity between context chunks, thereby supporting stable inference for infinite-length videos. The feature cache mechanism is illustrated in the figure below, which shows how the model maintains and reuses cached features during the processing of subsequent chunks.
The diffusion transformer, which is the core generative component of the Wan model, consists of a patchifying module, transformer blocks, and an unpatchifying module. The patchifying module uses a 3D convolution with a kernel size of (1,2,2) to convert the latent features into a sequence of features with the shape of (B,L,D), where B is the batch size, L is the sequence length, and D is the latent dimension. Within each transformer block, the model effectively models spatio-temporal contextual relationships and embeds text conditions alongside time steps. The cross-attention mechanism is used to embed the input text conditions, ensuring the model's ability to follow instructions even under long-context modeling. Additionally, an MLP with a Linear layer and a SiLU layer is employed to process the input time embeddings and predict six modulation parameters individually. This design reduces the parameter count by approximately 25% and reveals a significant performance improvement at the same parameter scale. The text encoder, umT5, is chosen for its strong multilingual encoding capabilities, which allow it to understand both Chinese and English effectively, as well as input visual text. This choice is supported by experimental results showing that umT5 outperforms other unidirectional attention mechanism LLMs in composition and achieves faster convergence.
The training of the Wan model is conducted in a three-stage process. The first stage involves freezing the ViT and LLM, and training only the multi-layer perceptron to align the visual embeddings with the LLM input space. The second stage makes all parameters trainable, and the final stage conducts end-to-end training on a small set of high-quality data. For the last two stages, the learning rates are set to 1e−5 for the LLM and MLP, and 1e−6 for the ViT. The Wan-VAE is trained using a three-stage approach. First, a 2D image VAE with the same structure is trained on image data. Then, this well-trained 2D image VAE is inflated into a 3D causal Wan-VAE to provide an initial spatial compression prior, which drastically improves the training speed. At this stage, the Wan-VAE is trained on low-resolution (128×128) and small frame number (5-frame) videos to accelerate convergence speed. The training losses include L1 reconstruction loss, KL loss, and LPIPS perceptual loss, which are weighted by coefficients of 3, 3e-6, and 3, respectively. Finally, the model is fine-tuned on high-quality videos with different resolutions and frame numbers, integrating the GAN loss from a 3D discriminator.
The Wan model is trained using the flow matching framework, which provides a theoretically grounded framework for learning continuous-time generative processes in diffusion models. The training objective is to predict the velocity of the denoising process, which is defined as the derivative of the linear interpolation between the original latent x1 and the random noise x0. The model is trained to predict this velocity, and the loss function is formulated as the mean squared error (MSE) between the model output and the ground truth velocity. The training protocol comprises three distinct stages differentiated by spatial resolution. The first stage involves joint training with 256 px resolution images and 5-second video clips (192 px resolution, 16 fps). The second stage upgrades both image and video resolutions to 480px while maintaining a fixed 5-second video duration. The final phase escalates spatial resolution to 720px for both images and 5-second video clips. This resolution-progressive curriculum helps mitigate the challenges of extended sequence lengths and excessive GPU memory consumption, ensuring stable training and model convergence.
The Wan model's training and inference are optimized for large-scale distributed computing. The model consists of three modules: VAE, text encoder, and DiT. The VAE module exhibits minimal GPU memory usage and can seamlessly adopt Data Parallelism (DP). In contrast, the text encoder requires over 20 GB of GPU memory, necessitating the use of model weight sharding to conserve memory for the subsequent DiT module. To address this, a Data Parallel (DP) approach combined with Fully Sharded Data Parallel (FSDP) strategy is employed. The DiT module, which accounts for a significant proportion of the overall computational workload, is optimized using a combination of FSDP and Context Parallelism (CP). The CP strategy is designed to reduce the activation memory footprint on each GPU by sharding the sequence length dimension. A two-dimensional (2D) CP is proposed, which combines the characteristics of Ulysses and Ring Attention, mitigating the slow cross-machine communication inherent in Ulysses and addressing the need for large block sizes after sharding in Ring Attention. This design maximizes the overlap between outer-layer communication and inner-layer computation, reducing the communication overhead of 2D Context Parallelism to below 1%. The FSDP group and CP group intersect within the FSDP group, and the DP size equals the FSDP size divided by the CP size. This distributed scheme allows for efficient scaling of the DiT module.
Memory optimization is a critical aspect of the Wan model's training and inference. The computational cost in Wan grows quadratically with sequence length, whereas GPU memory usage scales linearly with sequence length. This means that in long sequence scenarios, computation time can eventually exceed the PCIe transfer time required for offloading activations. To address this, activation offloading is prioritized to reduce GPU memory usage without sacrificing end-to-end performance. Since CPU memory is also prone to exhaustion in long sequence scenarios, a combination of offloading with gradient checkpointing (GC) strategies is used, prioritizing gradient checkpointing for layers with high GPU memory-to-computation ratios. During inference, the primary objective is to minimize the latency of video generation. Techniques such as quantization and distributed computing are employed to reduce the time required for each individual step. The attention similarities between steps are leveraged to decrease the overall computational load. For classifier-free guidance (CFG), the inherent similarities are exploited to further minimize computational requirements. The inference process is optimized using a combination of 2D Context Parallelism and FSDP, which enables nearly linear speedup on the Wan 14B model. The use of FP8 GEMM and 8-bit FlashAttention further enhances inference efficiency, achieving a 1.13× speedup in the DiT module and boosting the inference efficiency by more than 1.27×.
Experiment
- Wan-VAE demonstrates competitive performance in video reconstruction, achieving high PSNR and 2.5× faster reconstruction speed than HunYuan Video under the same hardware, with superior qualitative results in texture, face, text, and high-motion scenes.
- On the VBench leaderboard, Wan 14B achieves a state-of-the-art aggregate score of 86.22%, including 86.67% in visual quality and 84.44% in semantic consistency, outperforming commercial models like Sora and Hailuo, and open-source models such as CogVideoX and HunyuanVideo.
- The Wan 1.3B variant achieves 83.96% on VBench, surpassing HunyuanVideo, Kling 1.0, and CogVideoX1.5-5B, demonstrating strong efficiency and competitiveness despite smaller size.
- Ablation studies confirm that fully shared AdaLN reduces parameters without sacrificing performance, and umT5 outperforms other text encoders in text embedding quality, while the VAE with reconstruction loss achieves lower FID than VAE-D with diffusion loss.
- Diffusion caching improves inference speed by 1.62× by leveraging attention and CFG similarity across sampling steps, enabling efficient high-resolution generation.
- Wan excels in text-to-video generation, producing high-quality, dynamic, and cinematic videos with accurate multilingual text integration and complex motion synthesis, validated through human evaluation and benchmarking.
- Video personalization achieves high ArcFace similarity on unseen identities, demonstrating strong identity preservation in generated videos.
- The V2A model generates more consistent, cleaner, and rhythmically accurate audio than MMAudio, though it currently struggles with human vocal sounds due to exclusion of speech data in training.
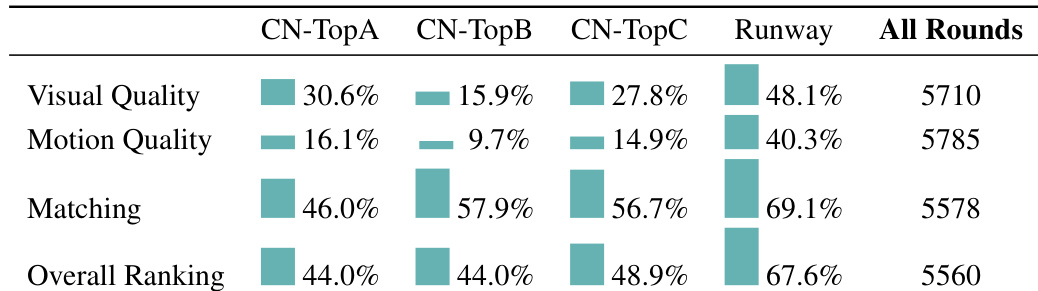
The authors use a human evaluation framework to assess the performance of their model across multiple dimensions, including visual quality, motion quality, matching, and overall ranking. Results show that the model achieves the highest win rates in motion quality and overall ranking, with particularly strong performance in the CN-TopD category, while it underperforms in matching compared to other models.

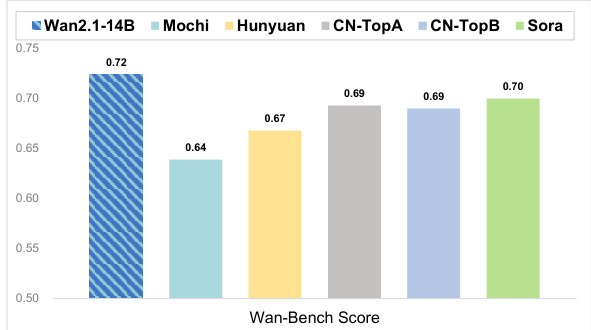
The authors evaluate their model, Wan-2.1-14B, against several commercial and open-source text-to-video models using the Wan-Bench evaluation framework. Results show that Wan-2.1-14B achieves the highest Wan-Bench score of 0.72, outperforming models such as Mochi, Hunyuan, CN-TopA, CN-TopB, and Sora.
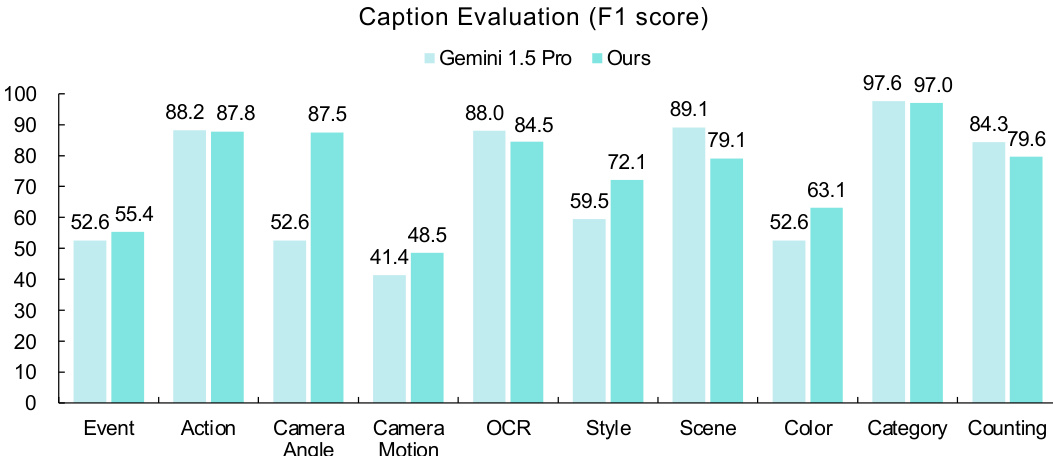
Results show that the proposed model outperforms Gemini 1.5 Pro in video event, camera angle, camera motion, style, and object color, while Gemini excels in action, OCR, scene, object category, and object counting. The model achieves higher F1 scores than Gemini in most visual dimensions, with the largest improvements observed in event, camera angle, and style.
The authors use a human evaluation framework to compare the Wan 14B model against several commercial and open-source text-to-video models across multiple dimensions. Results show that Wan outperforms competitors in overall ranking, with the highest win rates in matching and motion quality, and achieves the best performance in visual quality and overall ranking across all evaluation rounds.
The authors evaluate their model against several state-of-the-art text-to-video systems using the Wan-Bench evaluation framework, focusing on dimensions such as motion generation, image quality, and instruction following. Results show that the Wan 14B model achieves the highest weighted score and outperforms competitors like Sora and Hunyuan in most dimensions, particularly in large motion generation, physical plausibility, and action instruction following.