Command Palette
Search for a command to run...
BitNet b1.58 2B4T Technical Report
BitNet b1.58 2B4T Technical Report
Abstract
We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability. Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency. To facilitate further research and adoption, the model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures.
One-sentence Summary
The authors propose BitNet b1.58 2B4T, the first open-source 1.58-bit LLM at 2B parameters, achieving full-precision LLM-level performance on language, math, coding, and dialogue tasks while drastically reducing memory, energy, and latency via native 1-bit quantization—outperforming prior low-bit models in efficiency and enabling deployment on CPU and GPU through open-source releases.
Key Contributions
-
BitNet b1.58 2B4T is the first open-source, native 1-bit Large Language Model at the 2-billion parameter scale, trained from scratch on 4 trillion tokens to address the high computational cost and memory demands of deploying full-precision LLMs in resource-constrained environments.
-
The model employs a novel BitLinear layer architecture that enables efficient 1.58-bit weight representation and bitwise computation, allowing it to achieve performance on par with leading open-weight, full-precision LLMs of similar size across language understanding, mathematical reasoning, coding, and conversational benchmarks.
-
Released on Hugging Face with open-source inference code for both GPU and CPU, including GGUF and bf16 formats, BitNet b1.58 2B4T demonstrates substantial gains in memory efficiency, energy consumption, and decoding latency, advancing the Pareto frontier for open LLMs under 3B parameters.
Introduction
The authors leverage the growing demand for accessible, efficient large language models to address a key bottleneck: the high computational cost of deploying open-weight LLMs on resource-constrained systems. Prior work on 1-bit LLMs has been limited to either post-training quantization—which degrades performance—or small-scale native 1-bit models that fail to match full-precision counterparts in capability. To overcome these limitations, the authors introduce BitNet b1.58 2B4T, the first open-source, native 1-bit LLM trained from scratch at 2 billion parameters on 4 trillion tokens. Their key contribution is demonstrating that a scale-optimized, 1.58-bit model can achieve performance on par with leading full-precision LLMs of similar size across language understanding, math, coding, and conversation tasks, while drastically reducing memory, energy, and latency through efficient bitwise operations. The model is released with open-source inference code for both GPU and CPU, enabling broad research and deployment.
Dataset
- The pre-training data is a mixture of publicly available text and code datasets, including large-scale web crawls like DCLM (Li et al., 2024b) and educational web pages from FineWeb-EDU (Penedc et al., 2024), supplemented with synthetically generated mathematical content to strengthen reasoning capabilities.
- During Stage 1 of training, the majority of general web data was used, while higher-quality curated datasets were prioritized in Stage 2, during the cooldown phase with a reduced learning rate.
- For supervised fine-tuning (SFT), the authors used a diverse set of instruction-following and conversational datasets, including WildChat (Zhao et al., 2024), LMSYS-Chat-1M (Zheng et al., 2024), WizardLM Evol-Instruct (Xu et al., 2024a), and SlimOrca (Lian et al., 2023).
- To enhance reasoning and complex instruction handling, synthetic datasets generated via GLAN (Li et al., 2024a) and MathScale (Tang et al., 2024) were added to the SFT mix.
- The DPO preference training dataset was built from two publicly available sources: UltraFeedback (Cui et al., 2024) and MagPie (Xu et al., 2024c), combining diverse human judgments to guide the model toward more human-aligned responses.
- Data processing included filtering and cleaning to ensure quality, with synthetic data carefully constructed to match the style and complexity of real-world inputs.
- No explicit cropping strategy is described, but data was processed in a way that aligned with the two-stage training schedule, with emphasis on data quality and relevance in later stages.
- Metadata for each dataset subset was constructed to support training phase assignment and mixture ratio control, ensuring balanced and effective training across stages.
Method
The authors leverage a modified Transformer architecture, derived from the standard design (Vaswani et al., 2017), to implement BitNet b1.58 2B4T. The core innovation lies in the replacement of conventional full-precision linear layers with custom BitLinear layers, forming the foundation of the BitNet framework. Within these layers, weight quantization is applied during the forward pass, mapping model weights to ternary values {−1,0,+1} using an absolute mean (absmean) quantization scheme. This reduces the effective bitwidth to 1.58 bits, significantly decreasing model size and enabling efficient arithmetic operations. Concurrently, activations are quantized to 8-bit integers via an absolute maximum (absmax) strategy, applied per-token, to maintain numerical precision during computation. To enhance training stability, sub1n normalization is incorporated, a technique known to improve convergence in quantized training regimes.
Beyond the BitLinear layers, the model integrates several established techniques to improve performance and robustness. The feed-forward network (FFN) sub-layers employ squared ReLU (ReLU2) as the activation function, a choice motivated by its favorable sparsity and computational properties in the 1-bit context. Rotary Position Embeddings (RoPE) are used to encode positional information, a standard practice in modern large language models. Additionally, all bias terms are removed from linear and normalization layers throughout the network, consistent with architectures like LLaMA, to reduce parameter count and simplify quantization. For tokenization, the model uses the LLaMA 3 tokenizer, which implements a byte-level Byte-Pair Encoding (BPE) scheme with a vocabulary size of 128,256 tokens, ensuring broad coverage of text and code and compatibility with existing ecosystems.
The training process employs a two-stage weight decay schedule to manage regularization. In the first stage, weight decay follows a cosine schedule, peaking at 0.1, to prevent overfitting during the initial phase of training with higher learning rates. In the second stage, weight decay is disabled (set to zero), allowing the model parameters to converge to finer optima under a lower learning rate and curated data. Following pre-training, the model undergoes supervised fine-tuning (SFT) to improve its instruction-following capabilities and conversational performance. During SFT and inference, a specific chat template is used, structured as: <begin_of_text>System: {system_message}</eot_id>\nUser: {user_message_1}</eot_id>\nAssistant: {assistant_message_1}</eot_id>\nUser: {user_message_2}</eot_id>\nAssistant: {assistant_message_2}</eot_id>....
Efficient inference for BitNet b1.58 2B4T requires specialized implementations due to its unique W1.58A8 quantization scheme, which is not natively supported by standard deep learning libraries. To address this, the authors developed dedicated inference libraries for both GPU and CPU platforms. For GPU inference, a custom CUDA kernel was designed for W1.58A8 matrix multiplication. Ternary weights are packed into 8-bit integers, with four values encoded into each 'int8' for efficient storage in High Bandwidth Memory (HBM). The kernel loads these packed values into Shared Memory (SRAM), unpacks them into their ternary form, and performs the matrix multiplication with 8-bit activations. This pack-store-load-unpack-compute strategy minimizes memory bandwidth usage while enabling high-performance computation. For CPU inference, the authors released bitnet.cpp, a C++ library that provides optimized kernels for standard CPU architectures. These kernels are designed to efficiently handle the model's quantization scheme, ensuring accurate and fast inference without the overhead of generic quantization frameworks.
Experiment
- Main experiments: Pre-training, supervised fine-tuning (SFT), and direct preference optimization (DPO) were conducted to train BitNet b1.58 2B4T, validating the effectiveness of a native 1-bit architecture with optimized training strategies.
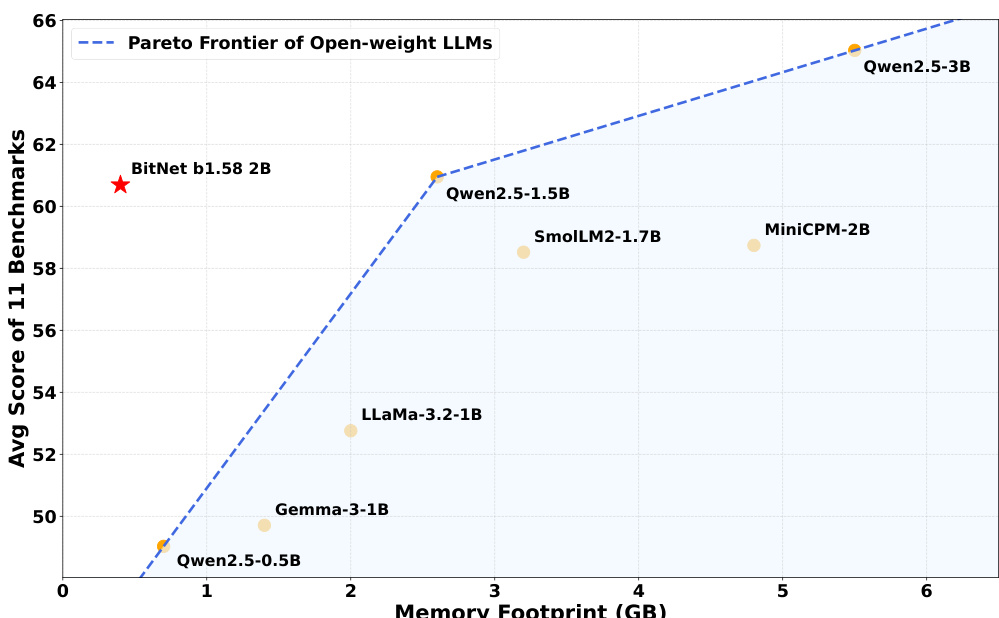
- Core results: On the evaluated benchmarks, BitNet b1.58 2B4T achieved state-of-the-art performance among 1-bit models, outperforming both smaller natively trained 1-bit models and larger models quantized to 1.58-bit. It matched or surpassed leading full-precision models of similar size (e.g., LLaMA 3.2 1B, Gemma-3 1B, Qwen2.5 1.5B) on key tasks including reasoning, math, and world knowledge, while achieving significantly lower memory footprint and energy consumption. On the MT-bench and IFEval benchmarks, it demonstrated strong instruction-following and conversational capabilities. The model also showed superior efficiency compared to INT4 post-training quantized versions of Qwen2.5 1.5B, maintaining higher performance with lower resource usage.
The authors use BitNet b1.58 2B4T to demonstrate that a 1-bit model can achieve performance competitive with full-precision models of similar size while significantly reducing memory and energy requirements. Results show that BitNet b1.58 2B4T achieves the lowest memory footprint and energy consumption, with latency of 29ms and an estimated energy use of 0.028J, outperforming all full-precision models on several benchmarks and setting a new state-of-the-art for 1-bit models.
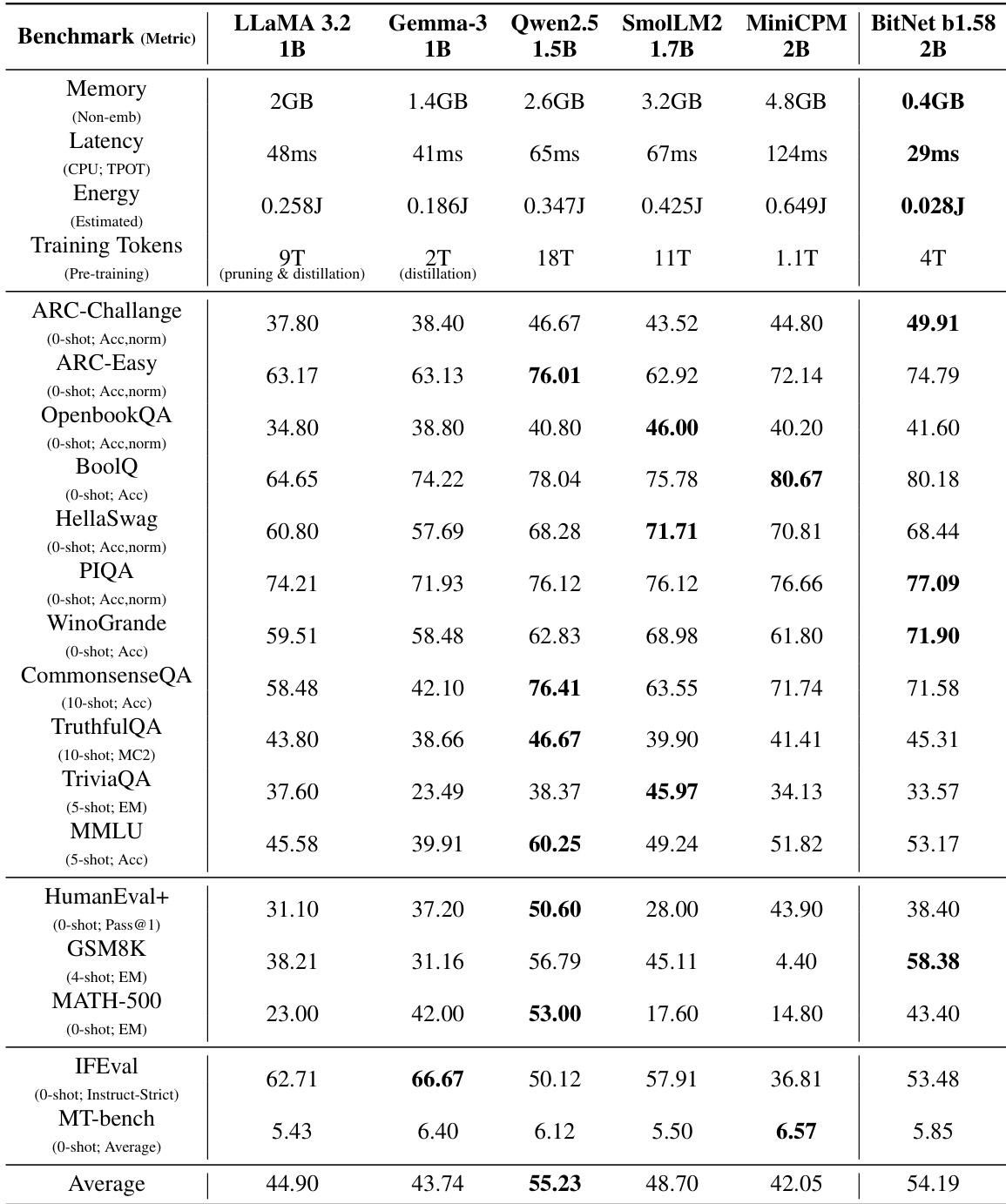
The authors compare BitNet b1.58 2B4T against other open-weight 1-bit models, including natively trained models and larger models quantized to 1.58-bit precision. Results show that BitNet b1.58 2B4T achieves the highest scores on the majority of benchmarks, significantly outperforming smaller 1-bit models and larger models subjected to post-training quantization, establishing it as the leading model in this category.
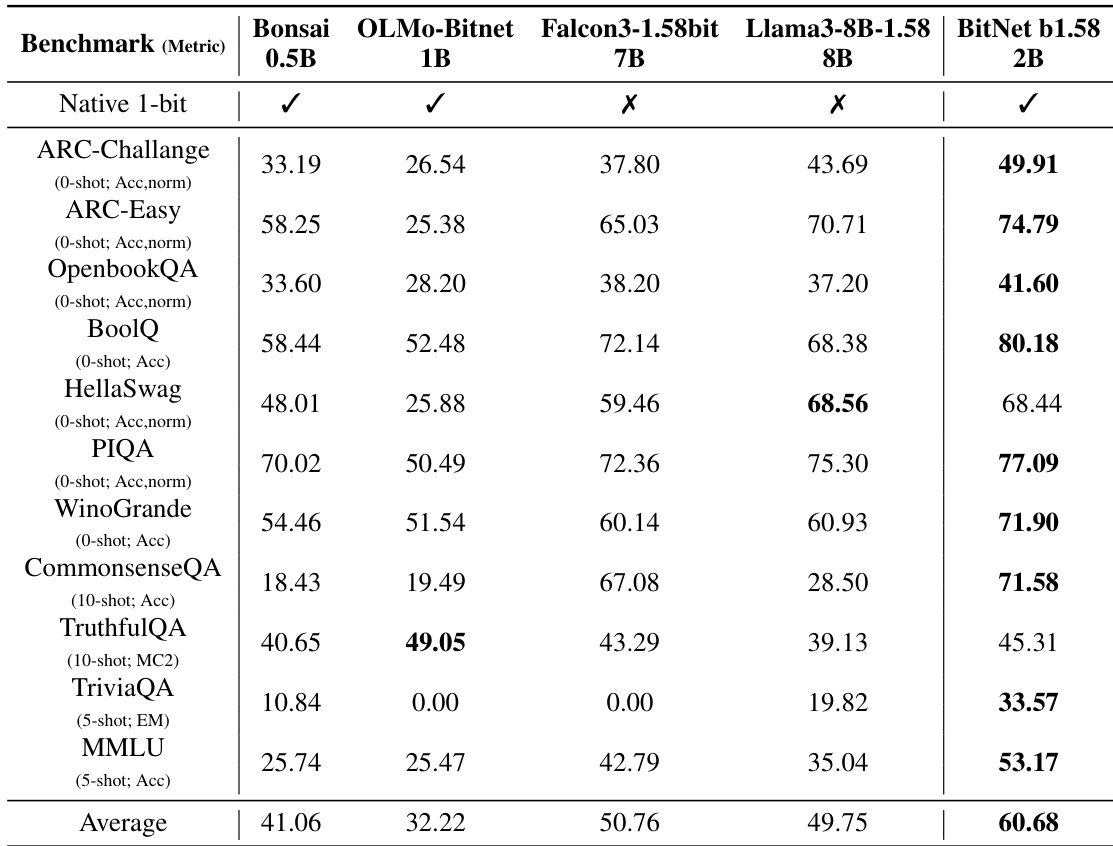
The authors compare BitNet b1.58 2B4T with post-training quantized versions of Qwen2.5 1.5B, showing that BitNet achieves a lower memory footprint while maintaining stronger performance across benchmarks. Results indicate that BitNet b1.58 2B4T outperforms the INT4 quantized models on MMLU, GSM8K, and IFEval, demonstrating superior efficiency and capability.

The authors use a table to compare the energy consumption of arithmetic operations for different precision formats, showing that INT8 requires significantly less energy than FP16 for both addition and multiplication. Results show that INT8 reduces ADD energy by 95.6% and MUL energy by 79.4% compared to FP16 at a 7nm process node.
