Command Palette
Search for a command to run...
Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and
Preference Alignment
Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
Kim Bryan Sangwoo Kim Jeongsol Ye Jong Chul
Abstract
Modern single-image super-resolution (SISR) models deliver photo-realistic results at the scale factors on which they are trained, but collapse when asked to magnify far beyond that regime. We address this scalability bottleneck with Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes SISR into an autoregressive chain of intermediate scale-states with multi-scale-aware prompts. CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems to achieve extreme resolutions without additional training. Because visual cues diminish at high magnifications, we augment each zoom step with multi-scale-aware text prompts generated by a vision-language model (VLM). The prompt extractor itself is fine-tuned using Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning text guidance towards human preference. Experiments show that a standard 4x diffusion SR model wrapped in CoZ attains beyond 256x enlargement with high perceptual quality and fidelity. Project Page: https://bryanswkim.github.io/chain-of-zoom/ .
One-sentence Summary
The authors from KAIST AI propose Chain-of-Zoom (CoZ), a model-agnostic framework that enables extreme super-resolution up to 256× by decomposing the task into an autoregressive chain of intermediate scale-steps enhanced with multi-scale-aware text prompts generated via a fine-tuned vision-language model, achieving high perceptual quality without retraining, outperforming standard models limited to their training scale.
Key Contributions
- Existing single-image super-resolution (SISR) models are limited to magnification factors within their training regime, failing catastrophically when asked to upscale beyond these bounds due to rigid learned assumptions about scale and degradation.
- Chain-of-Zoom (CoZ) introduces a model-agnostic, scale-level autoregressive framework that decomposes extreme super-resolution into a sequence of intermediate scale-states, using a pretrained SR backbone iteratively with multi-scale-aware text prompts generated by a vision-language model (VLM).
- The prompt extraction VLM is fine-tuned via Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning generated prompts with human preference and enabling a standard 4× diffusion SR model to achieve high-fidelity results up to 256× magnification without retraining.
Introduction
The authors leverage recent advances in diffusion-based generative models to address the challenge of single-image super-resolution (SISR), where the goal is to reconstruct high-resolution (HR) images from low-resolution (LR) inputs. While state-of-the-art models achieve impressive results at fixed magnification factors, they are limited to their training configurations and fail catastrophically when applied to higher scales due to rigid, scale-specific learned priors. This restricts practical use, especially for extreme magnifications like 16x or 32x, which are computationally prohibitive to train directly. To overcome this, the authors propose Chain-of-Zoom (CoZ), a model-agnostic, scale-level autoregressive framework that decomposes the super-resolution task into a sequence of intermediate scale-states. By iteratively applying a pretrained SR model and generating multi-scale-aware text prompts via a vision-language model (VLM), CoZ enables arbitrary-scale upscaling without retraining. The VLM is fine-tuned using a novel GRPO-based reinforcement learning with human feedback (RLHF) pipeline, ensuring prompts remain semantically coherent and aligned with human preferences, even as visual detail diminishes at extreme resolutions. This approach achieves sharp, realistic results at high magnifications while maintaining efficiency and scalability.
Dataset
- The dataset is composed of image-text pairs derived from two primary sources: the Qwen2.5-VL-3B-Instruct and InternVL2.5-8B pretrained vision-language models, both available on Hugging Face.
- The Qwen2.5-VL-3B-Instruct subset includes close-up images of textured surfaces such as animal fur and feathers, with descriptive captions focusing on visual attributes like texture, color gradients, and surface details.
- Each image-text pair is filtered to emphasize high-quality, visually distinct textures, with captions generated to reflect fine-grained perceptual features such as wavy patterns, depth cues, and color transitions.
- The authors use this dataset for training via GRPO (Generalized Reward Policy Optimization), where the model learns to generate accurate and detailed image descriptions.
- No explicit cropping strategy is applied; images are used in their original resolution. Metadata is constructed directly from the caption-text pairs, capturing structural and perceptual characteristics of the textures.
- The dataset is integrated into a training mixture that combines multiple sources, with the Qwen2.5-VL-3B-Instruct data contributing to the visual reasoning and description generation components of the model.
- Evaluation of image quality and descriptive accuracy is conducted using the IQA testing script from the 0SEDiff repository.
Method
The Chain-of-Zoom (CoZ) framework addresses the scalability limitations of single-image super-resolution (SISR) by decomposing the high-magnification task into a sequence of manageable intermediate scale-ups. The core of the method is an autoregressive (AR) process that models the generation of a high-resolution image xH from a low-resolution input xL through a series of intermediate scale-states xi. This process is structured as an AR-2 model, where each state xi is conditioned not only on the immediately preceding state xi−1 but also on the state before that, xi−2. This two-step dependency is crucial for maintaining high-frequency details across large magnification factors, as it allows the model to leverage information from a broader context, mitigating the information loss that occurs in a standard Markov chain. The framework introduces latent variables ci, which are text embeddings serving as multi-scale-aware prompts. These prompts are generated by a Vision-Language Model (VLM) conditioned on the current and previous scale-states, xi−1 and xi−2, to provide semantic guidance that steers the super-resolution process. The joint distribution of the image sequence and the prompt sequence is defined by the product of the initial distribution p(x0,x1) and the conditional probabilities for each subsequent step, p(xi∣xi−1,xi−2,ci), multiplied by the prompt generation probability p(ci∣xi−1,xi−2). This formulation enables the independent optimization of the super-resolution model and the prompt-extraction VLM.

The inference process, as illustrated in the framework diagram, begins with the low-resolution input x0. At each step i, a text prompt ci is first sampled from the VLM, ci∼pϕ(ci∣xi−1,xi−2). This prompt is then used as a conditional input to the super-resolution (SR) model, which generates the next scale-state xi∼pθ(xi∣xi−1,xi−2,ci). This recursive procedure continues until the target high-resolution image xn is produced. The SR model, which can be any pre-trained model, operates on local image patches, and the framework is designed to be model-agnostic, allowing it to leverage existing SISR backbones. The use of a fixed-size window for the SR model ensures compatibility with models that require identical input and output dimensions, such as diffusion-based models.

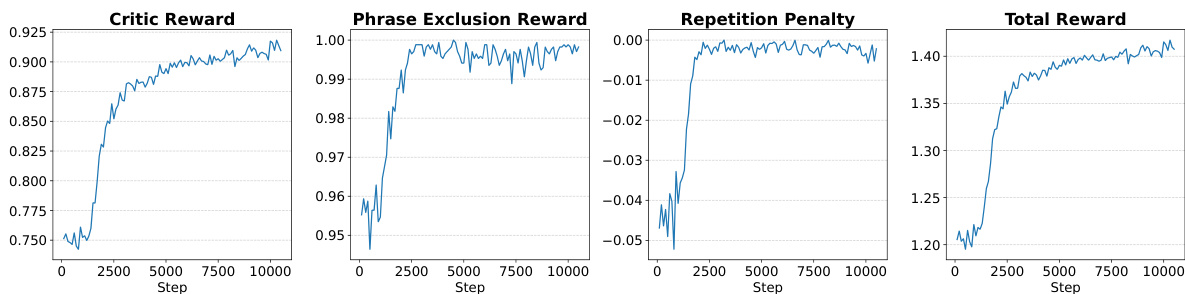
The training of the prompt-extraction VLM is a critical component of the framework, as it ensures that the textual guidance is aligned with human preferences and avoids hallucinations. This is achieved through a reinforcement learning (RL) pipeline based on Generalized Reward Policy Optimization (GRPO). The VLM is fine-tuned to generate prompts that are not only semantically relevant but also concise and free of redundant or meaningless phrases. The training process, depicted in the diagram, involves a base VLM that generates candidate prompts from multi-scale image crops. These prompts are then evaluated by a critic VLM, which scores them on a scale of 0 to 100 based on their quality in describing the target image. This raw score is rescaled to a [0, 1] range to serve as the critic reward. To enforce conciseness and relevance, a phrase-exclusion reward is applied, which gives a score of 1 if the prompt does not contain a predefined list of meaningless phrases (e.g., "first image") and 0 otherwise. A repetition penalty is also applied, which assigns a negative reward based on the fraction of repeated n-grams in the prompt, discouraging verbose and redundant descriptions. The final reward signal is a weighted sum of these three components, which is used to update the VLM's parameters via the GRPO algorithm. This process iteratively refines the VLM to produce high-quality, human-aligned prompts that effectively guide the SR model to generate realistic and detailed high-resolution images.
Experiment
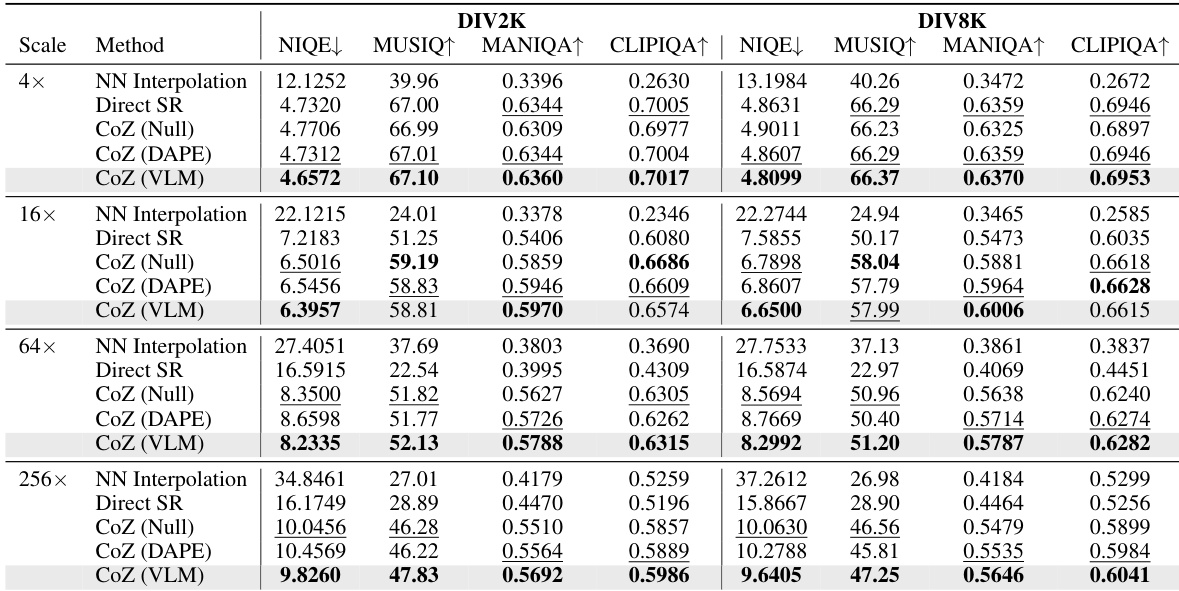
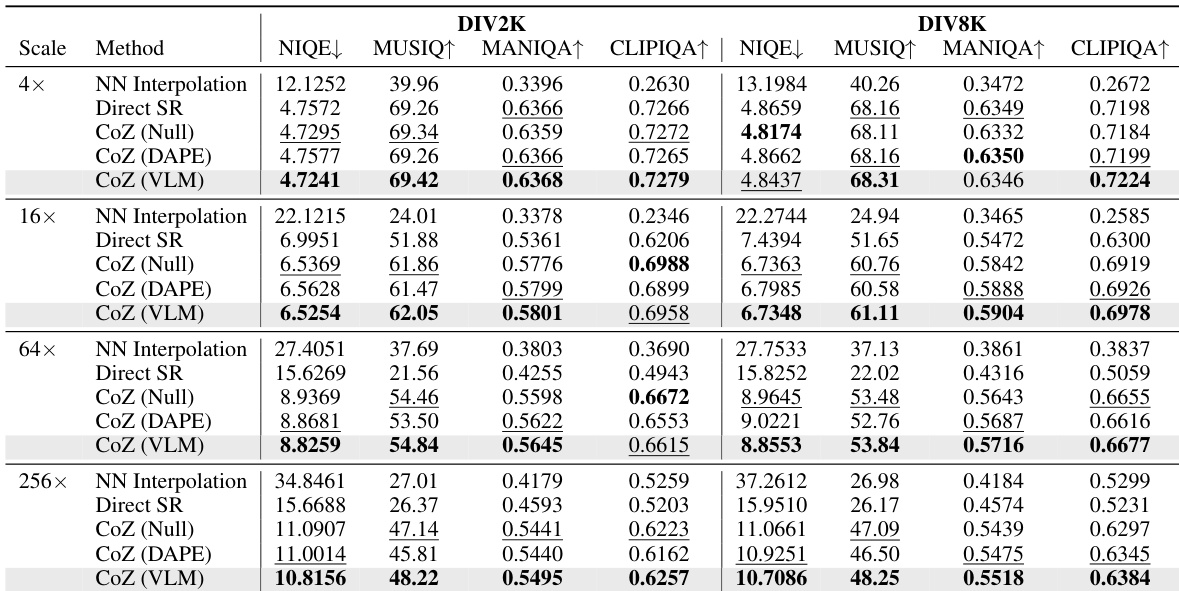
- Compared four recursion methods: nearest neighbor interpolation, one-step SR, and three CoZ variants (Null, DAPE, VLM). CoZ with VLM prompts achieves superior image quality at high magnifications (64×, 256×), outperforming others in both qualitative and quantitative evaluations.
- On no-reference metrics (NIQE, MUSIQ, MANIQA-pipal, CLIPIQA), CoZ with VLM prompts achieves the best results at 64× and 256× scales, significantly surpassing baseline methods and DAPE prompts, which degrade at higher scales.
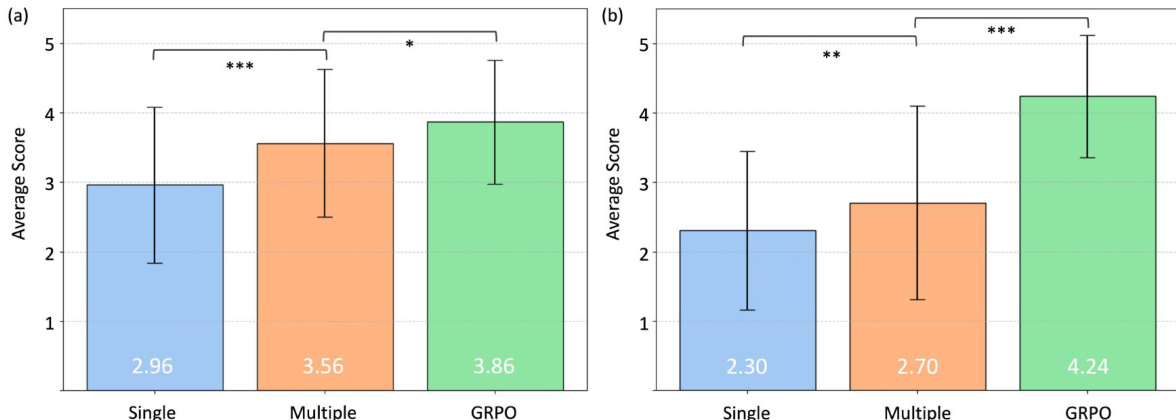
- GRPO fine-tuning of the VLM improves prompt quality and reduces hallucinations, as shown in Fig. 7 and confirmed by MOS user study: GRPO-finetuned prompts receive significantly higher preference scores (p < 0.001) for both image and text generation compared to base VLM and multi-scale-only prompts.
- User study with 25 participants confirms that GRPO-aligned VLM prompts lead to more preferred zoom sequences and text explanations, with statistically significant improvements (p < 0.05 to p < 0.001).
- CoZ framework is effective with open-source OSEDiff (Stable Diffusion v2.1), achieving strong performance on DIV2K and DIV8K datasets, demonstrating robustness and generalizability.
- Extreme super-resolution results up to 256× magnification show CoZ generates photorealistic images with fine details, validating its capability for high-scale image zooming.
The authors use a user study to evaluate the quality of image and text generation under different prompt extraction methods. Results show that the GRPO fine-tuned VLM significantly outperforms both single-scale and multi-scale prompt methods in both image and text generation, with statistically significant improvements in mean opinion scores.
Results show that the proposed CoZ framework, particularly with VLM-generated prompts, outperforms baseline methods like nearest neighbor interpolation and direct SR at higher magnification scales. At 256×, CoZ (VLM) achieves the best or second-best scores across all no-reference metrics, demonstrating superior image quality and realism compared to other methods.
Results show that the proposed CoZ framework, particularly with VLM-generated prompts, outperforms baseline methods across all magnification scales, with significant improvements at higher scales such as 64× and 256×. At 256× magnification, CoZ (VLM) achieves the best or second-best scores on all no-reference metrics, demonstrating its effectiveness in generating high-quality images where other methods degrade.
Results show that the reward components during GRPO training converge as expected: the critic reward increases steadily, the phrase exclusion reward approaches 1.00, and the repetition penalty decreases to near 0.00, indicating effective alignment with human preferences. The total reward also rises and stabilizes, reflecting the overall improvement in the VLM's prompt-extraction quality throughout training.