Command Palette
Search for a command to run...
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and
Reasoning Modes
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Abstract
This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
One-sentence Summary
The authors propose EXAONE 4.0, a dual-mode language model series with 32B and 1.2B variants that integrate non-reasoning and reasoning capabilities, enabling agentic tool use and multilingual support including Spanish, achieving strong performance against open and leading proprietary models, with public release for research via Hugging Face.
Key Contributions
- EXAONE 4.0 unifies a NON-REASONING mode for fast, user-friendly interactions with a REASONING mode for deep, accurate problem-solving within a single model, enhancing both usability and advanced reasoning capabilities for real-world applications.
- The model introduces agentic tool use and extends multilingual support to include Spanish, while leveraging a hybrid global-local attention architecture to efficiently handle long contexts up to 128K tokens, improving performance in document QA and RAG tasks.
- EXAONE 4.0 achieves superior performance among open-weight models of similar scale and remains competitive with frontier models, particularly in mathematical reasoning, coding, and expert knowledge tasks, with both 32B and 1.2B variants publicly available for research.
Introduction
The authors leverage EXAONE 4.0 to address the growing demand for versatile, high-performance language models in the emerging agentic AI era. By unifying a non-reasoning mode for fast, user-friendly interactions with a reasoning mode for complex problem-solving, the model bridges the gap between usability and advanced cognitive capabilities. Prior work faced challenges in balancing real-world applicability with deep reasoning, often requiring separate models for each function, while also struggling with long-context processing and multilingual support. EXAONE 4.0 overcomes these limitations through a hybrid attention architecture that efficiently handles 128K-token contexts, integrates agentic tool use, and extends multilingual support to include Spanish—without degrading performance in English or Korean. The model achieves state-of-the-art results in reasoning, instruction following, and long-context tasks, while remaining competitive with larger frontier models.
Dataset
- The dataset for EXAONE 4.0 is composed of diverse, high-quality data sources collected from web corpora, code repositories, and domain-specific documents, with a focus on enhancing world knowledge, reasoning, and multilingual capabilities.
- Pre-training uses 14 trillion tokens—double the 6.5 trillion used in EXAONE 3.5 32B—drawn from large-scale web sources, with rigorous curation to improve cognitive behavior and post-training performance.
- Supervised fine-tuning (SFT) data is split into non-reasoning and reasoning modes and organized across five domains: World Knowledge, Math/Code/Logic, Agentic Tool Use, Long Context, and Multilinguality.
- For World Knowledge, high-educational-value web content is filtered, with specialized and high-difficulty data prioritized for reasoning tasks.
- Math, Code, and Logic data are limited by the difficulty of verifying ground truth; instead, multiple diverse responses per unique query are used to enhance training diversity, with careful filtering to prevent degeneration, especially in long-form code responses.
- The Code domain extends beyond problem-solving to include full-stack software engineering data from code corpora.
- Long Context data is built from web sources and restructured Korean legal, administrative, and technical documents to support varied input formats, with systematic variation in context length and key information location to train comprehensive understanding.
- Agentic Tool Use data includes multi-turn, multi-step user-agent interactions with environment feedback, designed to simulate real-world tool-calling workflows and iterative reasoning.
- Multilinguality data supports Korean and Spanish, incorporating culturally relevant content, local education and industry topics (especially for Korean), and translated existing samples to ensure natural, fluent conversations.
- Unified mode training combines non-reasoning and reasoning data at a 1.5:1 token ratio (reasoning to non-reasoning), determined through ablation studies to prevent over-reliance on reasoning behavior.
- A second round of fine-tuning uses high-quality reasoning data from Code and Tool Use domains to address domain imbalance and further boost performance.
- The dataset is processed to ensure consistency, with metadata constructed to reflect domain, task type, and context length, and no explicit cropping is mentioned—instead, data is structured to support long-form, multi-turn, and contextually rich interactions.
Method
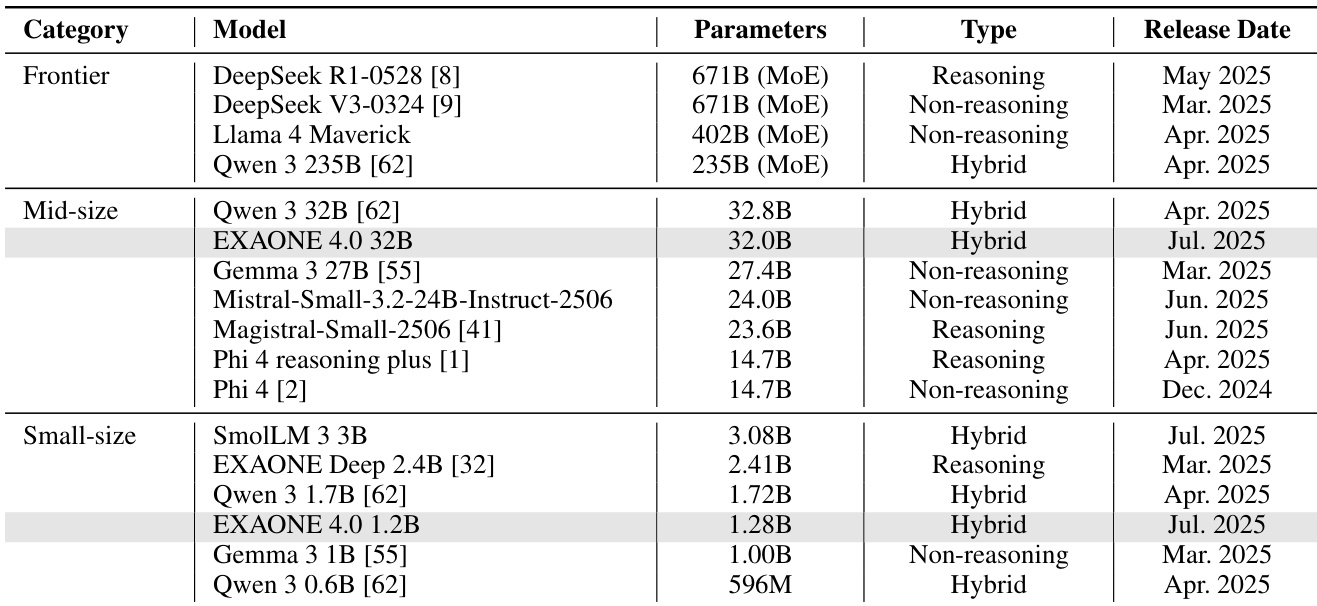
The EXAONE 4.0 model employs a transformer-based architecture with several key modifications to its attention mechanism and normalization strategy compared to its predecessor, EXAONE 3.5. The primary architectural innovation is the adoption of a hybrid attention mechanism that combines local and global attention in a 3:1 ratio. This design contrasts with the all-global attention approach used in EXAONE 3.5. The local attention component utilizes sliding window attention with a window size of 4K tokens, which is selected to minimize adverse effects on short-context performance while enabling efficient long-context processing. As shown in the figure below, sliding window attention restricts attention to a fixed-size window around each token, thereby reducing computational complexity and memory requirements. In contrast, global attention allows each token to attend to all other tokens in the sequence, preserving long-range dependencies. The hybrid approach balances these two regimes, ensuring the model maintains both local coherence and global context awareness.
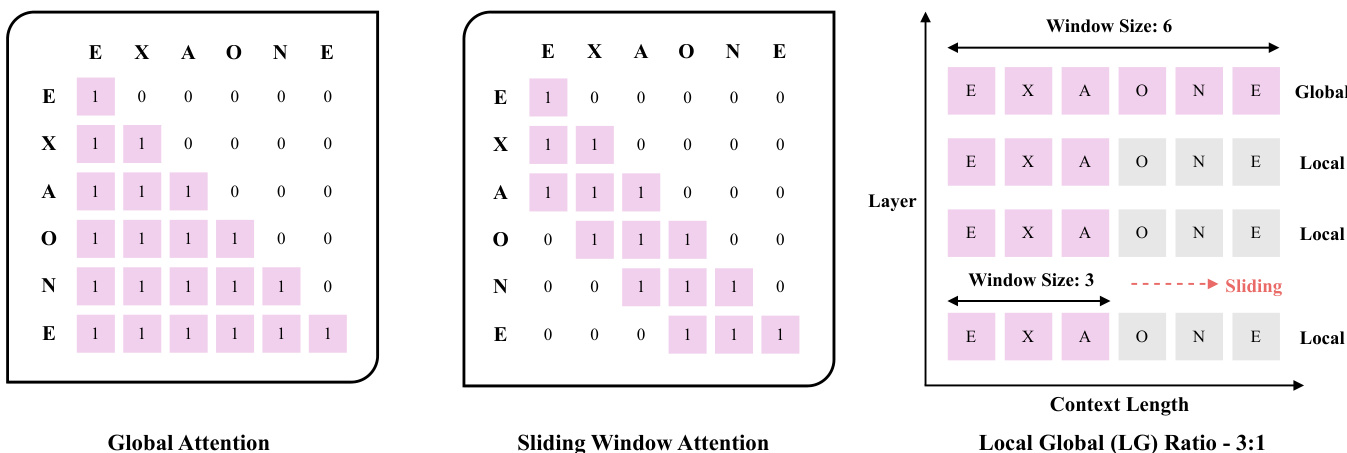
The model's attention mechanism is further refined by omitting Rotary Position Embedding for global attention, which helps prevent the model from developing biases toward sequence length and maintains a consistent global perspective. For the local attention mechanism, the model does not employ chunked attention; instead, it uses sliding window attention, a well-established sparse attention method known for its theoretical stability and broad support in open-source frameworks. This choice ensures robust implementation and ease of integration. To mitigate performance degradation in short-context scenarios during long-context fine-tuning, the model leverages a careful data selection methodology and a progressive training recipe.
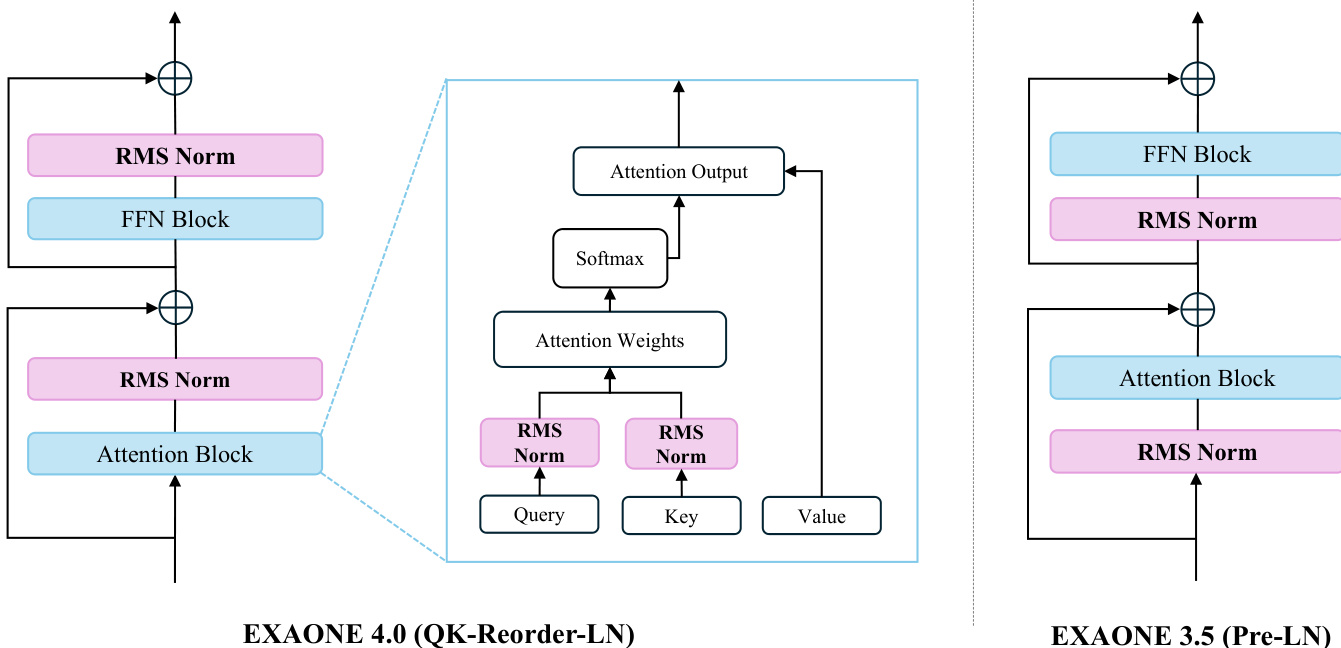
Another significant architectural change in EXAONE 4.0 is the repositioning of layer normalization. The model adopts the QK-Reorder-LN (Query-Key Reorder LayerNorm) approach, where RMSNorm is applied after the input queries and keys and again after the attention output. This differs from the Pre-LN architecture used in EXAONE 3.5, which applies normalization before the attention and feed-forward blocks. The QK-Reorder-LN method, as illustrated in the framework diagram, is designed to better control the variance of outputs across layers, leading to improved performance on downstream tasks despite higher computational cost. The normalization type RMSNorm, which was introduced in EXAONE 3.0, is retained in EXAONE 4.0.
The EXAONE 4.0 model series includes two configurations: a 32B parameter model and a 1.2B parameter model. Both models share the same vocabulary, which consists of Korean and English tokens in roughly equal proportions, along with a small number of multilingual tokens. The maximum context length for the 32B model is extended to 128K tokens through a two-stage process. Initially, a model pretrained with a 4K context length is extended to 32K tokens, and then further extended to 128K tokens. This process is validated at each stage using the Needle In A Haystack (NIAH) test to ensure the model's performance is maintained. For the 1.2B model, the context length is extended to 64K tokens, which is approximately twice the typical maximum length supported by most models in the 1B-parameter range.
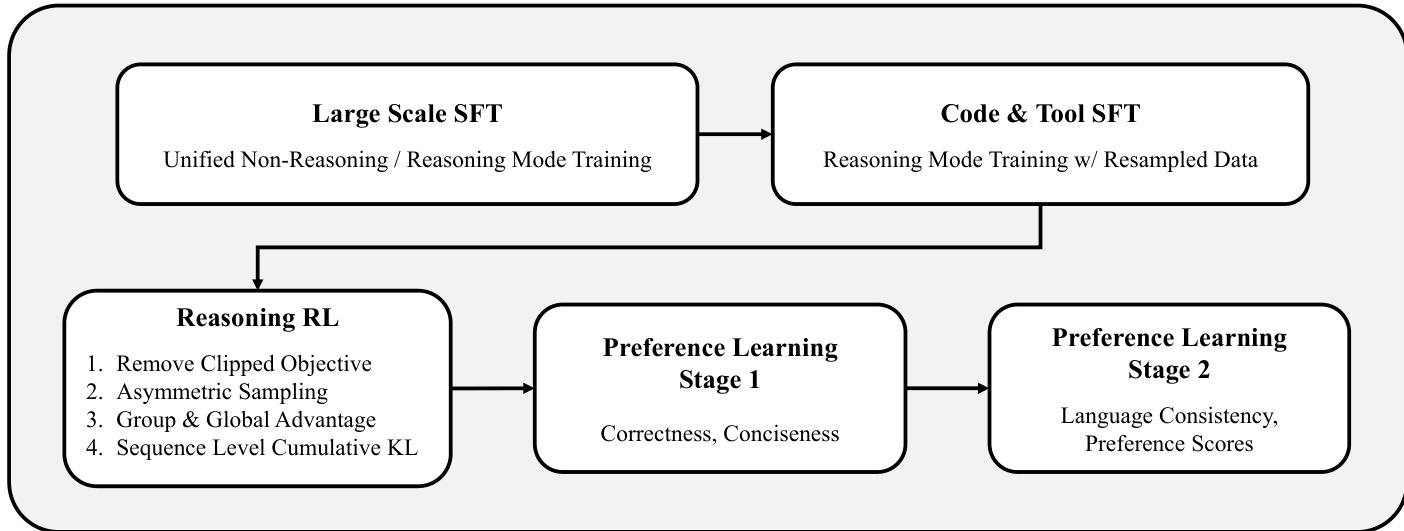
The post-training phase of EXAONE 4.0 is structured into three stages: supervised fine-tuning (SFT), reasoning reinforcement learning (RL), and preference learning. The SFT stage involves large-scale data expansion to enhance performance efficiently. The reasoning RL stage employs a novel algorithm called AGAPO (Asymmetric Sampling and Global Advantage Policy Optimization) to improve the model's reasoning capabilities. AGAPO removes the clipped objective from PPO, uses asymmetric sampling to include negative feedback, calculates group and global advantages, and applies sequence-level cumulative KL penalty. The preference learning stage integrates non-reasoning and reasoning modes through a two-stage process that optimizes for correctness, conciseness, language consistency, and preference scores.
Experiment
- Evaluated EXAONE 4.0 across six benchmark categories: World Knowledge, Math/Coding, Instruction Following, Long Context, Agentic Tool Use, and Multilinguality.
- On Math/Coding benchmarks (AIME 2025, HMMT FEB 2025, LIVECODEBENCH V5/6), EXAONE 4.0 32B achieved superior performance, outperforming Qwen3 235B in both REASONING and NON-REASONING modes; EXAONE 4.0 1.2B surpassed all baselines except EXAONE Deep 2.4B in REASONING mode.
- On GPQA-DIAMOND, EXAONE 4.0 32B and 1.2B achieved second-highest scores, demonstrating strong expert-level knowledge.
- On long-context benchmarks (HELMET, RULER, LONGBENCH), EXAONE 4.0 models showed competitive performance, with extended context support via YaRN enabling 64K token inference for smaller models.
- On tool-use benchmarks (BFCL-v3, TAU-BENCH), EXAONE 4.0 32B matched or exceeded larger baselines; EXAONE 4.0 1.2B achieved the highest TAU-BENCH (Retail) score among tested models.
- On multilingual tasks, EXAONE 4.0 demonstrated strong performance in Korean (KMMLU-PRO, KSM, KO-LONGBENCH) and Spanish (MMMLU (ES), MATH500 (ES), WMT24++), with high-quality translations assessed via LLM-as-a-judge.
- Reasoning budget ablation showed that even with a 32K reasoning budget, performance degradation was minimal (≤5% for most models), maintaining competitive results.
The authors use Table 3 to present the evaluation results of EXAONE 4.0 32B in REASONING mode across multiple benchmarks. Results show that EXAONE 4.0 32B achieves strong performance in Math/Coding and World Knowledge categories, outperforming several larger models such as Qwen 3 235B and DeepSeek R1-0528 on key benchmarks like AIME 2025 and GPQA-DIAMOND. The model also demonstrates competitive results in instruction following and agentic tool use, particularly in TAU-BENCH Retail, despite its smaller size compared to frontier models.
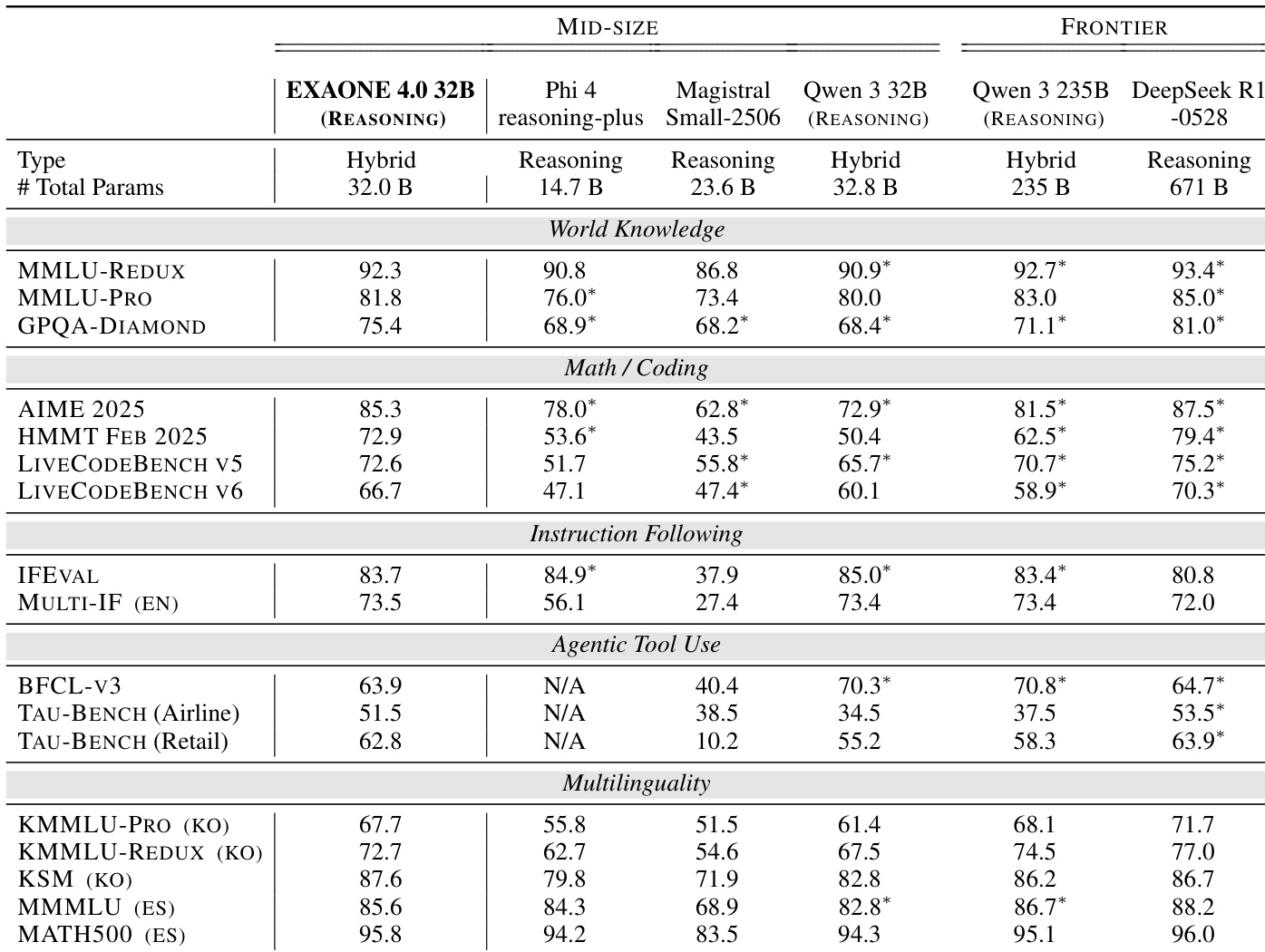
The authors use the HELMET benchmark to evaluate long-context capabilities across six tasks, including recall, retrieval-augmented generation, and summarization. Results show that EXAONE 4.0 32B achieves high accuracy across all context lengths, outperforming most mid-size models and demonstrating strong performance even at 128K context, while small-size models like EXAONE 4.0 1.2B show competitive results at shorter lengths but are limited at 64K and above.
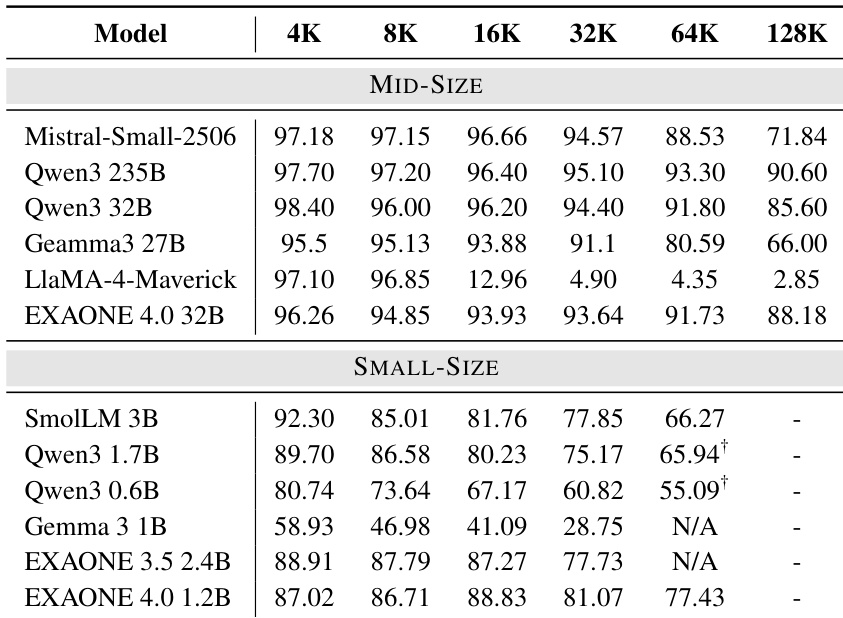
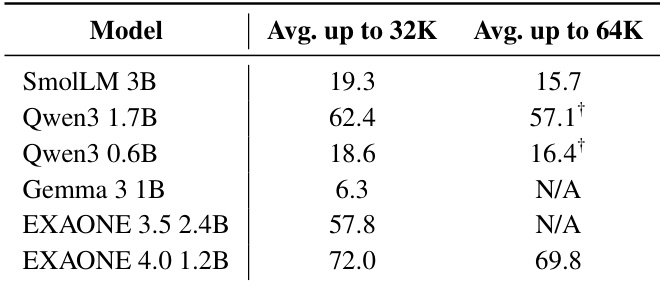
The authors evaluate the long-context performance of small models, including EXAONE 4.0 1.2B, on the HELMET benchmark by extending context lengths beyond 32K tokens using YaRN. Results show that EXAONE 4.0 1.2B achieves the highest average score up to 32K tokens and maintains strong performance up to 64K tokens, outperforming other small models in this range.
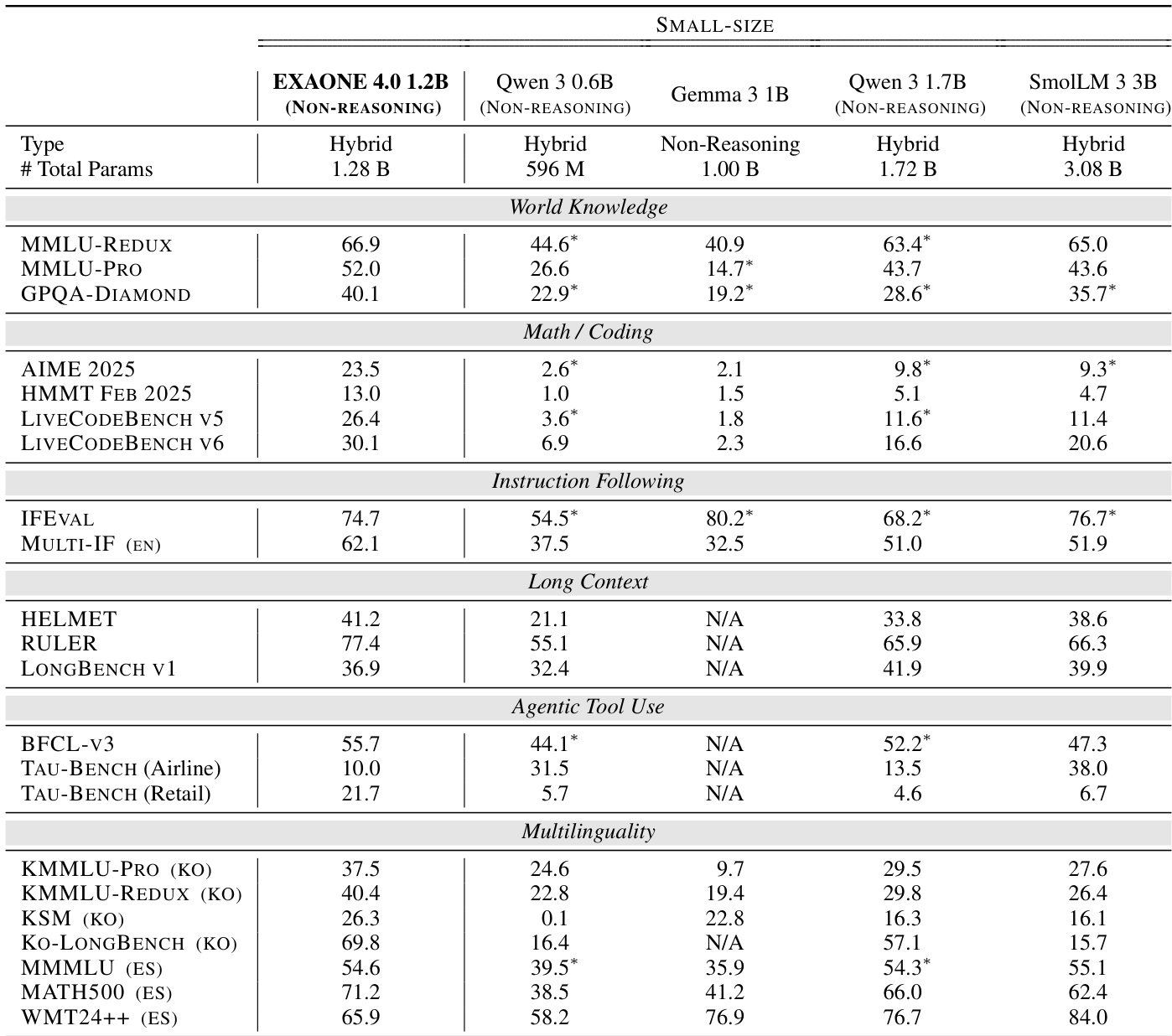
The authors use the table to compare the performance of EXAONE 4.0 1.2B in NON-REASONING mode against several small-size models across multiple benchmarks. Results show that EXAONE 4.0 1.2B achieves competitive results in most categories, particularly excelling in Math/Coding and multilingual tasks, while demonstrating strong performance in long-context and instruction-following benchmarks compared to other models.
The authors use a diverse set of benchmarks to evaluate EXAONE 4.0 across multiple domains, including World Knowledge, Math/Coding, Instruction Following, Long Context, Agentic Tool Use, and Multilinguality. Results show that EXAONE 4.0 models achieve competitive performance, particularly excelling in Math/Coding and World Knowledge tasks, with the 32B model outperforming larger baselines in several categories.