Command Palette
Search for a command to run...
Qwen-Image Technical Report
Qwen-Image Technical Report
Abstract
We present Qwen-Image, an image generation foundation model in the Qwen series that achieves significant advances in complex text rendering and precise image editing. To address the challenges of complex text rendering, we design a comprehensive data pipeline that includes large-scale data collection, filtering, annotation, synthesis, and balancing. Moreover, we adopt a progressive training strategy that starts with non-text-to-text rendering, evolves from simple to complex textual inputs, and gradually scales up to paragraph-level descriptions. This curriculum learning approach substantially enhances the model's native text rendering capabilities. As a result, Qwen-Image not only performs exceptionally well in alphabetic languages such as English, but also achieves remarkable progress on more challenging logographic languages like Chinese. To enhance image editing consistency, we introduce an improved multi-task training paradigm that incorporates not only traditional text-to-image (T2I) and text-image-to-image (TI2I) tasks but also image-to-image (I2I) reconstruction, effectively aligning the latent representations between Qwen2.5-VL and MMDiT. Furthermore, we separately feed the original image into Qwen2.5-VL and the VAE encoder to obtain semantic and reconstructive representations, respectively. This dual-encoding mechanism enables the editing module to strike a balance between preserving semantic consistency and maintaining visual fidelity. Qwen-Image achieves state-of-the-art performance, demonstrating its strong capabilities in both image generation and editing across multiple benchmarks.
One-sentence Summary
The Qwen Team presents Qwen-Image, a foundation model that advances complex text rendering—especially in logographic languages like Chinese—through a progressive curriculum learning pipeline and a dual-encoding mechanism for consistent image editing, achieving state-of-the-art performance in generation, editing, and text fidelity across multiple benchmarks.
Key Contributions
-
Qwen-Image addresses the challenge of complex text rendering in image generation by introducing a comprehensive data pipeline and a progressive curriculum learning strategy, enabling robust performance across both alphabetic (e.g., English) and logographic (e.g., Chinese) languages, particularly excelling in multi-line and paragraph-level text integration.
-
To achieve consistent image editing, the model employs a dual-encoding mechanism that separately extracts semantic features via Qwen2.5-VL and reconstructive features via a VAE encoder, which are jointly conditioned on the MMDiT architecture to preserve both semantic coherence and visual fidelity during edits.
-
Evaluated on multiple benchmarks including GenEval, GEdit, LongText-Bench, and CVTG-2K, Qwen-Image achieves state-of-the-art results in both general image generation and editing tasks, demonstrating superior performance in text rendering—especially for Chinese—while maintaining strong capabilities across diverse visual modalities.
Introduction
Image generation models have become central to modern AI, enabling the synthesis of high-quality, semantically rich visuals from text prompts. However, prior models struggle with complex prompt alignment—especially for multi-line text, non-alphabetical languages like Chinese, and precise text-image integration—and face challenges in image editing, where maintaining both visual consistency and semantic coherence during modifications remains difficult. The authors introduce Qwen-Image, a new foundation model in the Qwen series that addresses these limitations through a comprehensive data pipeline with curriculum learning, enabling robust handling of complex linguistic inputs across diverse languages. To improve editing fidelity, they propose a dual-conditioning framework that jointly uses semantic features from Qwen-VL and reconstructive features from a VAE within a shared MMDiT architecture, ensuring both high-level meaning and low-level visual details are preserved. The model is trained efficiently using a Producer-Consumer distributed framework with TensorPipe and Megatron, supporting scalable, stable training. Qwen-Image achieves state-of-the-art performance in text-to-image generation, image editing, and cross-benchmark tasks, demonstrating strong generalization to 3D view synthesis and pose editing, and establishing a new paradigm for unified vision-language generation.
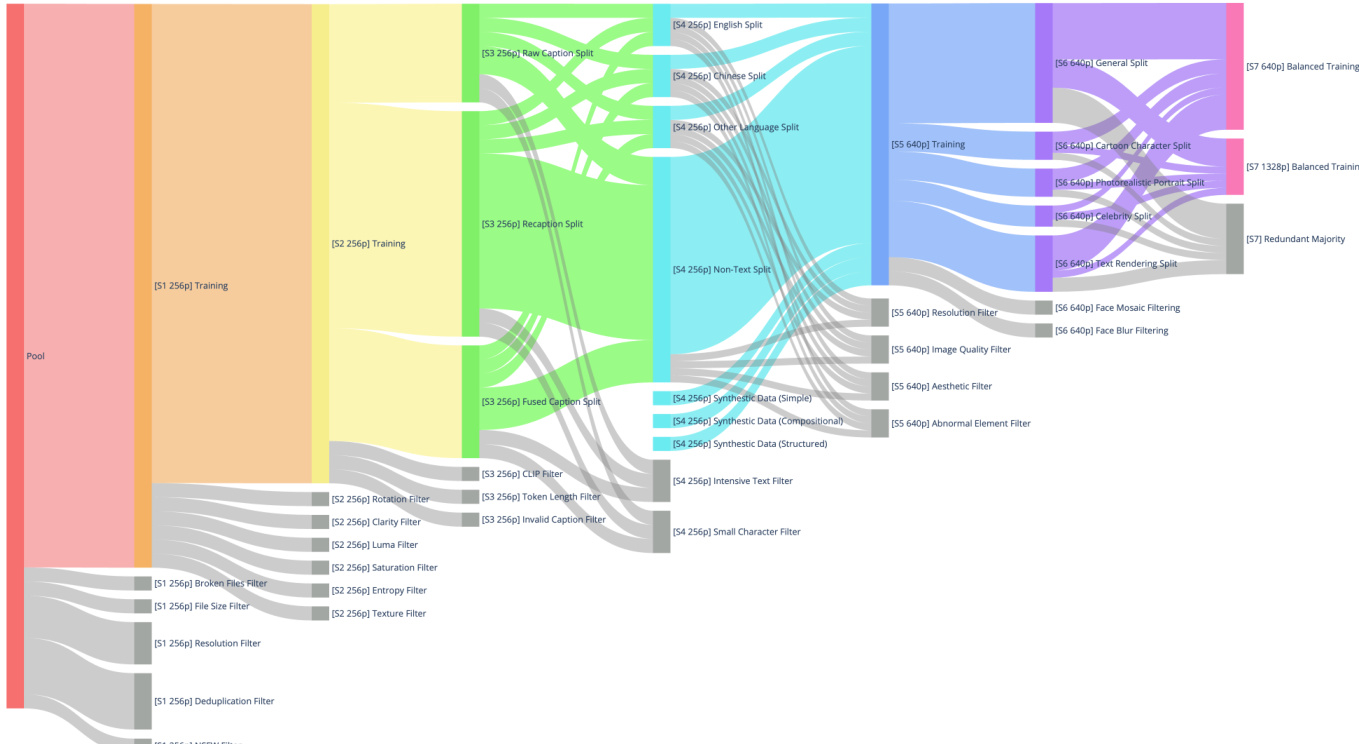
Dataset
- The dataset comprises billions of image-text pairs, organized into four main domains: Nature (55%), Design (27%), People (13%), and Synthetic Data (5%).
- Nature includes diverse subcategories like Objects, Landscape, Cityscape, Plants, Animals, Indoor, and Food, serving as the foundation for general-purpose image generation.
- Design covers structured visual content such as Posters, User Interfaces, Presentation Slides, and various art forms, enhancing the model’s ability to handle complex layouts, artistic styles, and text rendering.
- People includes portraits, sports, and human activities, crucial for generating realistic and diverse human-centric images.
- Synthetic Data consists of text-rendered images created via controlled, non-AI methods (as detailed in §3.4), avoiding risks from AI-generated content such as hallucinations or artifacts.
- Data is processed through a seven-stage filtering pipeline:
- Stage 1: Initial curation at 256p resolution with filters for broken files, small file size, low resolution, duplicates, and NSFW content.
- Stage 2: Image quality enhancement using Rotation, Clarity, Luma, Saturation, Entropy, and Texture filters to remove low-quality or unnatural images.
- Stage 3: Image-text alignment improvement via three caption splits—Raw, Recaption, and Fused—combined with CLIP and SigLIP filters, token length checks, and invalid caption removal.
- Stage 4: Text rendering enhancement by splitting data by language (English, Chinese, Other, Non-Text), incorporating synthetic text data, and applying Intensive Text and Small Character filters.
- Stage 5: High-resolution refinement at 640p with additional quality, resolution, aesthetic, and abnormal element filters.
- Stage 6: Category rebalancing into General, Portrait, and Text Rendering categories, with targeted augmentation using keyword and image retrieval, and enhanced captioning for portraits.
- Stage 7: Balanced multi-scale training at 640p and 1328p using a hierarchical taxonomy (inspired by WordNet), quality-based retention, and resampling to address long-tail token distributions.
- Metadata is constructed in a single pass using a structured annotation framework (e.g., Qwen2.5-VL), generating both rich captions and JSON-formatted metadata on object attributes, spatial relationships, visible text, image type, style, and presence of watermarks or anomalies.
- The model uses the dataset in a phased training strategy:
- Initial pre-training on 256p data with Stage 1–3 filtering.
- High-resolution training with 640p and 1328p data in Stage 7, enabling multi-scale learning.
- Supervised Fine-Tuning (SFT) uses human-annotated, high-quality, photorealistic images with detailed prompts to improve realism and fine-grained detail generation.
- A hierarchical taxonomy ensures balanced data distribution across categories, while resampling strategies mitigate long-tail issues in text rendering.
- No AI-generated images are used in synthetic data; all synthetic content is created through controlled text rendering techniques to maintain fidelity and avoid hallucinations.
Method
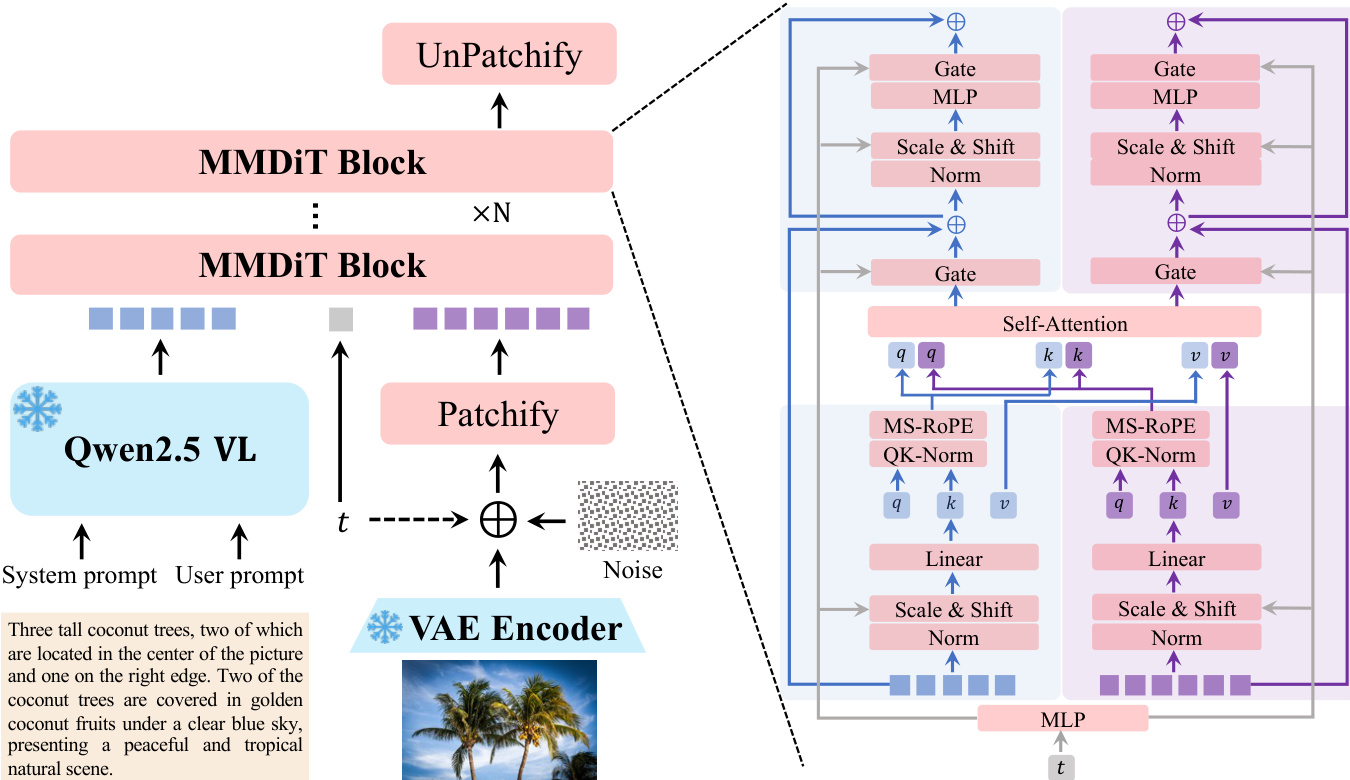
The Qwen-Image model is built upon a three-component architecture designed to enable high-fidelity text-to-image generation and precise image editing. The framework integrates a Multimodal Large Language Model (MLLM), a Variational AutoEncoder (VAE), and a Multimodal Diffusion Transformer (MMDiT) to process and generate images guided by textual and visual inputs. As shown in the framework diagram, the Qwen2.5-VL model serves as the condition encoder, extracting features from textual inputs. These features are then used to condition the MMDiT, which models the joint distribution between noise and image latents. The VAE functions as the image tokenizer, compressing input images into compact latent representations for encoding and decoding during inference. The MMDiT processes the combined text and image latent representations to generate the final output image.
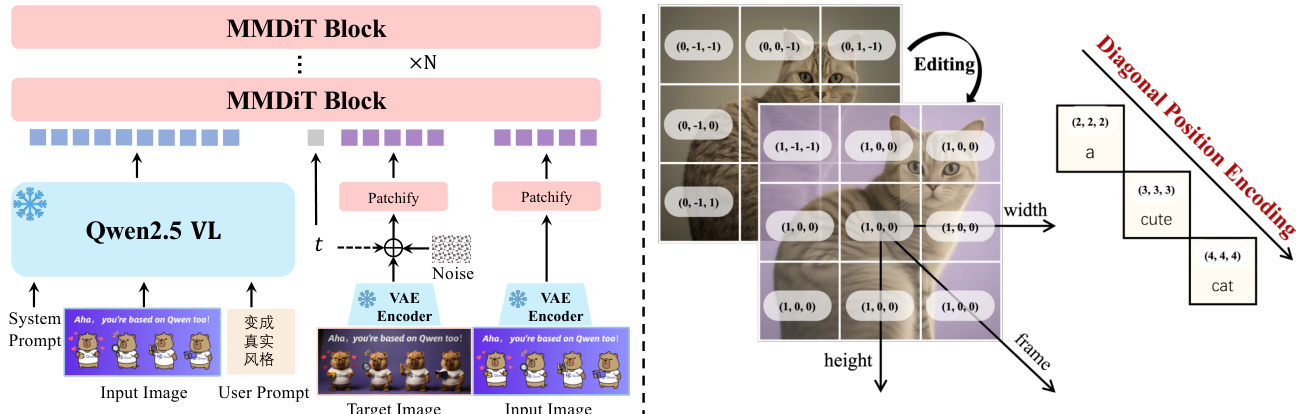
The Qwen2.5-VL model is employed as the feature extraction module for textual inputs due to its aligned language and visual spaces, strong language modeling capabilities, and support for multimodal inputs. For different tasks, distinct system prompts are designed to guide the model. For text-to-image generation, the system prompt template is illustrated in the figure below, where the user prompt is embedded within a structured format to provide clear instructions for the model.
The VAE is designed to provide a high-quality image representation, with a focus on enhancing reconstruction fidelity, particularly for small text and fine-grained details. The model uses a single-encoder, dual-decoder architecture, where a shared encoder is compatible with both images and videos, and separate decoders are used for each modality. The image decoder is fine-tuned on an in-house corpus of text-rich images to improve the rendering of small text. The training process employs a combination of reconstruction and perceptual losses, dynamically adjusting their ratio to avoid grid artifacts and improve visual quality.
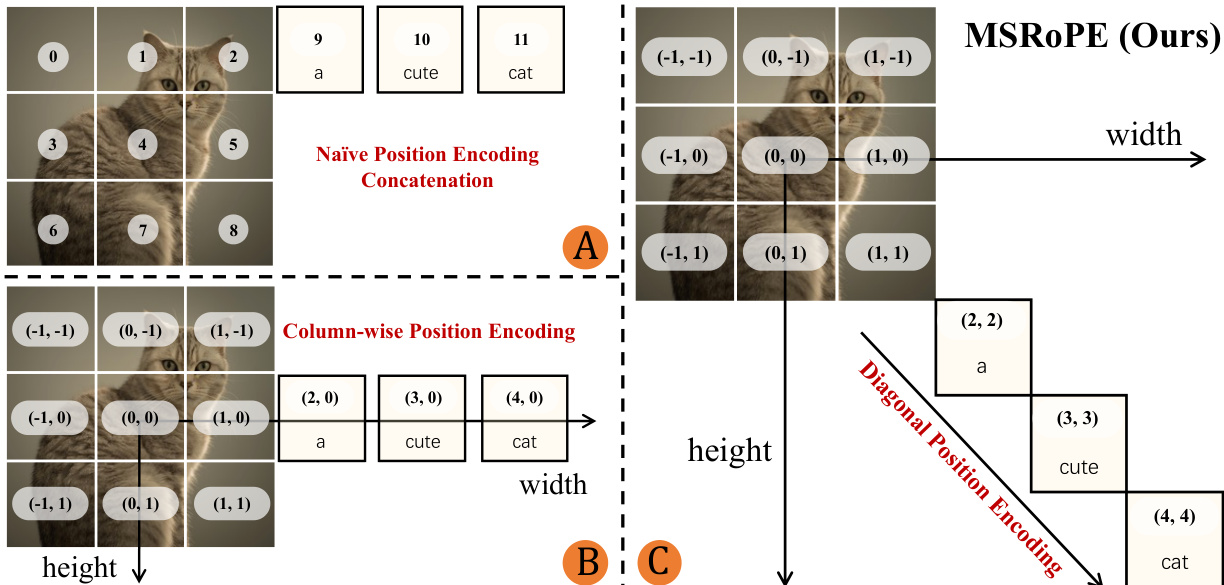
The MMDiT serves as the backbone diffusion model, jointly modeling text and images. A key innovation in the MMDiT block is the introduction of Multimodal Scalable RoPE (MSRoPE), a novel positional encoding method designed to address the challenges of text-image joint positional encoding. As illustrated in the figure below, MSRoPE treats text inputs as 2D tensors with identical position IDs applied across both dimensions, conceptualizing the text as being concatenated along the diagonal of the image grid. This design enables resolution scaling advantages on the image side while maintaining functional equivalence to 1D-RoPE on the text side, thereby improving text-image alignment.
The training process for Qwen-Image is structured in multiple stages to progressively enhance data quality, image resolution, and model performance. The pre-training phase adopts a flow matching objective, which facilitates stable learning dynamics via ordinary differential equations. The model is trained to predict the target velocity of the intermediate latent variable at each timestep, with the loss function defined as the mean squared error between the predicted and ground truth velocities. The training strategy includes enhancing resolution from low to high, integrating textual rendering from non-text to text, refining data quality from massive to refined, balancing data distribution from unbalanced to balanced, and augmenting with synthetic data from real-world to synthetic.
Post-training consists of two stages: supervised fine-tuning (SFT) and reinforcement learning (RL). The RL stage employs two distinct strategies: Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO). DPO is used for large-scale offline preference learning due to its scalability and computational efficiency, while GRPO is reserved for small fine-grained refinement. The GRPO algorithm formulates the training objective based on the advantage function, which is calculated as the normalized difference between the reward of a generated image and the mean reward of a group of images. The training objective includes a clipping term to ensure stable policy updates and a KL-divergence term to regularize the policy against the reference policy.
The model also supports multi-task training, incorporating not only traditional text-to-image (T2I) and text-image-to-image (T12I) tasks but also image-to-image (I2I) reconstruction. This multi-task paradigm aligns the latent representations between Qwen2.5-VL and MMDiT, enhancing image editing consistency. The dual-encoding mechanism, where the original image is separately fed into Qwen2.5-VL and the VAE encoder, enables the editing module to balance semantic consistency and visual fidelity. The system prompt for image editing tasks is designed to handle both image and text inputs, with the visual patches from the input image encoded by a Vision Transformer and concatenated with text tokens. The VAE-encoded latent representation of the input image is also fed into the image stream to maintain structural consistency. To distinguish between multiple images, the MSRoPE is extended by introducing an additional frame dimension.
Experiment
- Human evaluation on AI Arena demonstrates Qwen-Image ranks third among five leading closed-source APIs, achieving a 30 Elo point advantage over GPT Image 1 [High] and FLUX.1 Kontext [Pro], and trailing only Imagen 4 Ultra Preview 0606 by 30 Elo points, validating its strong open-source competitiveness.
- VAE reconstruction on ImageNet-1k and text-rich corpora shows Qwen-Image-VAE achieves state-of-the-art PSNR and SSIM scores, with only 19M encoder and 25M decoder parameters, indicating high reconstruction quality and computational efficiency.
- On text-to-image generation, Qwen-Image achieves the highest overall score on DPG, OneIG-Bench (English and Chinese), and ranks second on TIIF Bench, outperforming leading models in prompt adherence and text rendering.
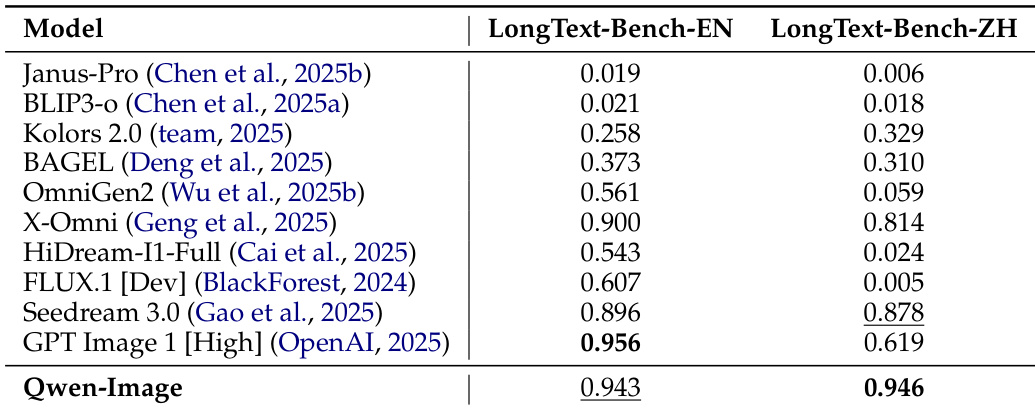
- On Chinese text rendering, Qwen-Image achieves the highest accuracy across all three difficulty levels in the new ChineseWord benchmark, and leads in LongText-Bench for long Chinese text rendering, demonstrating superior multilingual and long-text capabilities.
- In image editing, Qwen-Image ranks first on GEdit-Bench and ImgEdit, excels in novel view synthesis (GSO dataset), and matches state-of-the-art performance on depth estimation across NYUv2, KITTI, ScanNet, DIODE, and ETH3D, showcasing strong spatial reasoning and generalization.
- Qualitative results confirm Qwen-Image’s superior performance in complex text rendering (English and Chinese), multi-object generation, spatial relationship modeling, pose manipulation, and chained editing, with consistent fidelity to prompts and superior detail preservation.
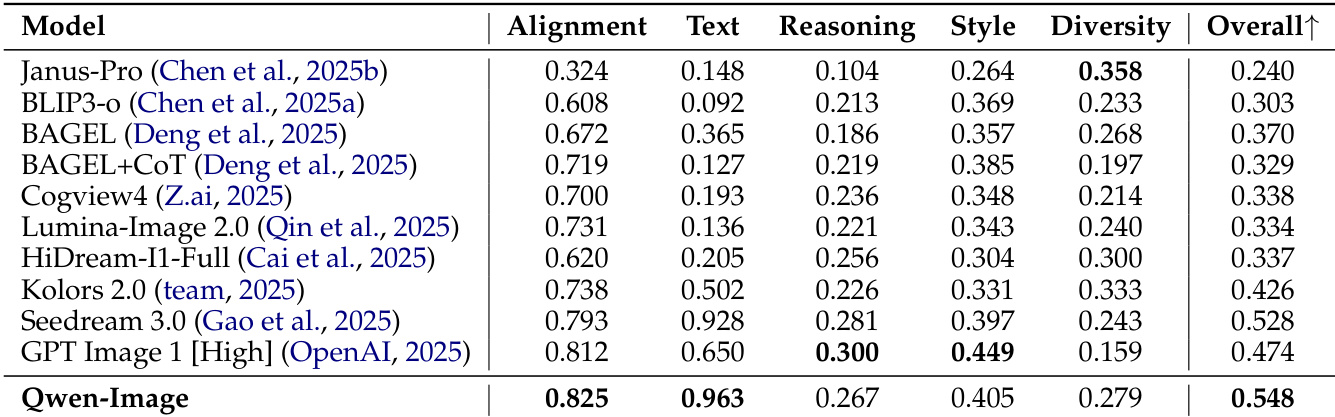
Results show that Qwen-Image achieves the highest overall score on the DPG benchmark, excelling in prompt adherence, particularly in interpreting attributes and other prompt facets. It also ranks first in the Alignment and Text categories on the OneIG-Bench, demonstrating strong general-purpose generation and text rendering capabilities.
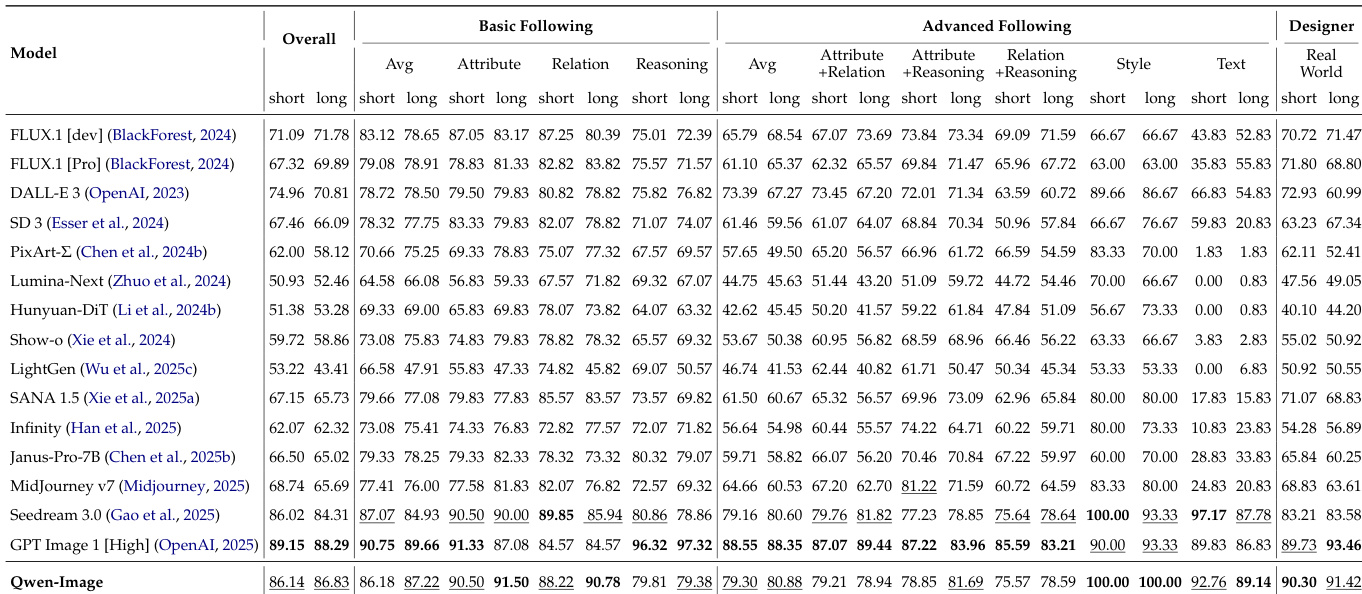
Results show that Qwen-Image achieves the highest accuracy on LongText-Bench, with scores of 0.943 for English and 0.946 for Chinese, outperforming all other models in both categories. This demonstrates Qwen-Image's superior capability in rendering long texts compared to state-of-the-art models.
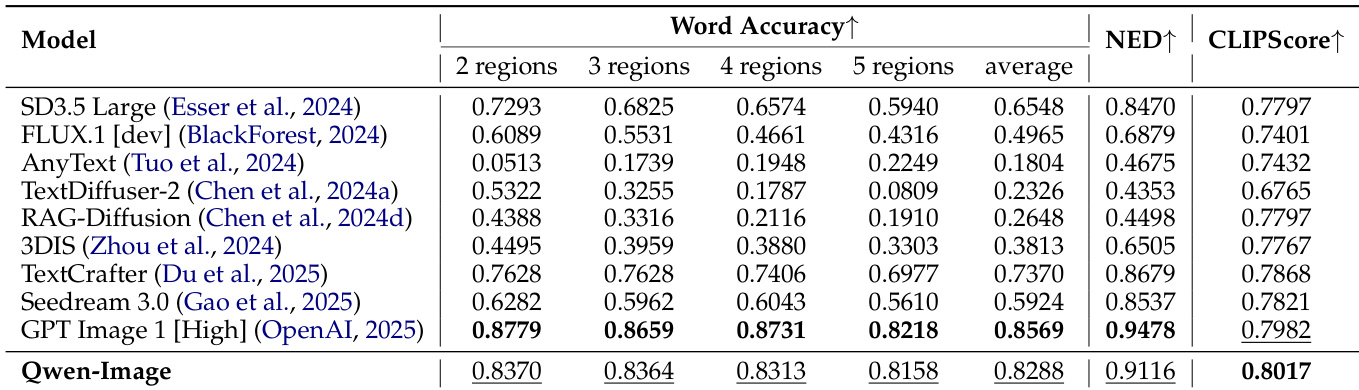
Results show that Qwen-Image achieves the highest word accuracy across all region counts and the average, outperforming all compared models. It also attains the best NED and CLIPScore, demonstrating superior performance in English text rendering on the CVTG-2K benchmark.
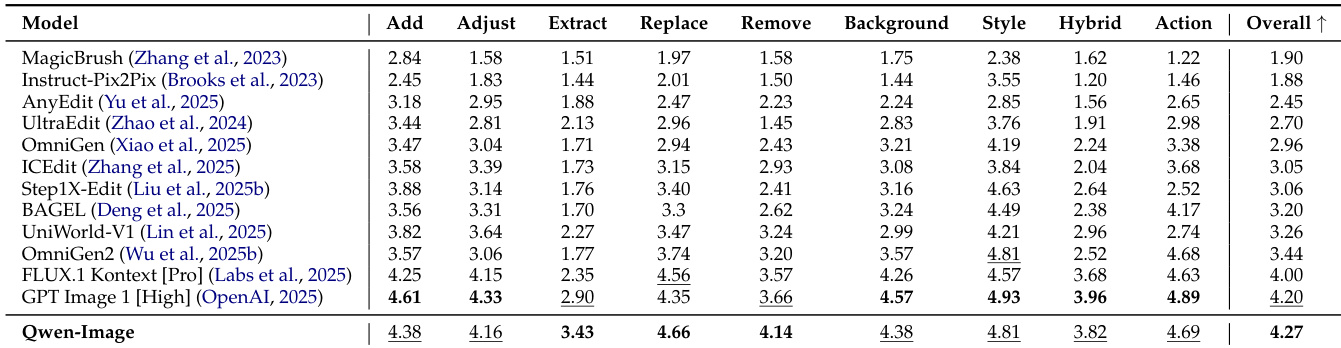
The authors evaluate Qwen-Image's image editing capabilities on the GEdit-Bench, comparing it against several state-of-the-art models across multiple editing tasks. Results show that Qwen-Image achieves the highest overall score, outperforming all competitors in both English and Chinese leaderboards, demonstrating strong editing capability and generalization to multilingual user instructions.
Results show that Qwen-Image achieves the highest overall score of 0.548 on the OneIG-Bench, outperforming all other models across both the Chinese and English tracks. It ranks first in the Alignment and Text categories, demonstrating superior prompt-following and text rendering capabilities.