Command Palette
Search for a command to run...
Wan-S2V: Audio-Driven Cinematic Video Generation
Wan-S2V: Audio-Driven Cinematic Video Generation
Abstract
Current state-of-the-art (SOTA) methods for audio-driven character animation demonstrate promising performance for scenarios primarily involving speech and singing. However, they often fall short in more complex film and television productions, which demand sophisticated elements such as nuanced character interactions, realistic body movements, and dynamic camera work. To address this long-standing challenge of achieving film-level character animation, we propose an audio-driven model, which we refere to as Wan-S2V, built upon Wan. Our model achieves significantly enhanced expressiveness and fidelity in cinematic contexts compared to existing approaches. We conducted extensive experiments, benchmarking our method against cutting-edge models such as Hunyuan-Avatar and Omnihuman. The experimental results consistently demonstrate that our approach significantly outperforms these existing solutions. Additionally, we explore the versatility of our method through its applications in long-form video generation and precise video lip-sync editing.
One-sentence Summary
The authors from Tongyi Lab, Alibaba, propose Wan-S2V, an audio-driven model built upon Wan, which significantly enhances expressiveness and fidelity in film-level character animation by enabling nuanced interactions, realistic body movements, and dynamic camera work, outperforming SOTA methods like Hunyuan-Avatar and Omnihuman in long-form video generation and precise lip-sync editing.
Key Contributions
-
We address the limitations of existing audio-driven video generation by enabling film-level character animation through a novel integration of audio and text control, where audio governs fine-grained expressions and gestures while text directs global scene dynamics, camera movements, and character interactions.
-
Our model, Wan-S2V, is trained on a large-scale, diverse dataset combining open-source film and TV content with proprietary talking and singing character videos, and employs a multi-stage training strategy with full-parameter optimization using hybrid FSDP and Context Parallelism to ensure robust and harmonious text-audio control.
-
We achieve stable long-form video generation by introducing an adaptive motion frame token compression method that reduces computational overhead while preserving temporal consistency, and demonstrate superior performance over SOTA models like Hunyuan-Avatar and Omnihuman in both quantitative benchmarks and qualitative evaluations.
Introduction
Audio-driven human video generation has advanced significantly with the rise of diffusion models, particularly DiT-based video foundation models, enabling high-quality synthesis from text or audio inputs. However, prior work remains largely limited to single-character, single-scene scenarios, struggling to handle complex cinematic contexts involving multi-person interactions, coordinated motion, and dynamic camera behavior. A key challenge lies in balancing fine-grained audio control—governing expressions and gestures—with high-level text guidance for scene-wide coherence, often leading to conflicting or unstable outputs. The authors introduce WAN-S2V, a model that unifies text and audio control for film-quality video generation by leveraging a large-scale, curated dataset combining open-source and proprietary audio-visual data from film and television. They employ a hybrid training strategy using FSDP and Context Parallel to enable full-parameter training, along with a multi-stage training pipeline to ensure stability and fidelity. To address long-video generation, they adopt adaptive token compression for motion frames, reducing computational load while improving temporal consistency. The result is a robust system that achieves coordinated, expressive, and cinematic video synthesis, marking a significant step toward practical audio-driven production.
Dataset
- The dataset is composed of two primary sources: videos collected from large-scale open-source datasets (e.g., Li et al. 2024, Wang et al. 2024) and manually curated high-quality samples from public sources, focusing on intentional and complex human activities such as speaking, singing, and dancing.
- The initial pool includes millions of human-centric video samples, which undergo a multi-stage filtering pipeline to ensure quality and relevance.
- 2D pose tracking is performed using VitPose followed by DWPose to extract motion data, which serves both as a multi-modal control signal for the generation model and as a basis for fine-grained filtering.
- Videos are filtered based on pose data to exclude those where characters occupy minimal space temporally or spatially, and only clips with consistent, visible human faces throughout the sequence are retained.
- Video quality is assessed using five metrics: clarity (Dover metric), motion stability (optical flow via UniMatch), facial and hand sharpness (Laplacian operator), aesthetic quality (improved predictor by Schuhmann 2022), and subtitle occlusion (OCR-based detection).
- Audio-visual alignment is enforced using Light-ASD to exclude videos with unsynchronized audio or missing active speakers.
- Dense video captions are generated using QwenVL2.5-72B, with instructions to describe camera angles, physical appearance, specific actions, and background features in detail, while avoiding subjective or emotional interpretations.
- The final training set combines filtered data from OpenHumanViD and a self-constructed internal talking head dataset, used to train the Wan-S2V-14B model for audio-driven human video generation.
- The model is trained using a mixture of these data subsets, with processing ensuring temporal alignment, high visual fidelity, and strong audio-visual correspondence.
Method
The authors leverage a diffusion-based framework for audio-driven video generation, where the model learns to denoise latent representations of video frames conditioned on audio input, a reference image, and a textual prompt. The overall architecture operates on a sequence of noisy latent tokens derived from the target video frames, which are progressively refined to produce coherent and audio-synchronized output. As shown in the figure below, the framework begins with a 3D Variational Autoencoder (VAE) that encodes the input video frames into a lower-dimensional latent space, enabling efficient processing. The reference image, target frames, and optional motion frames are all encoded into latent representations, which are then patchified and flattened into a sequence of visual tokens. The motion frames, when provided, serve as a continuity condition, ensuring temporal consistency in the generated video. To manage computational complexity during long video generation, the motion latent is further compressed using a Frame Pack module, which applies higher compression to earlier frames, thereby reducing the memory footprint while preserving historical context.
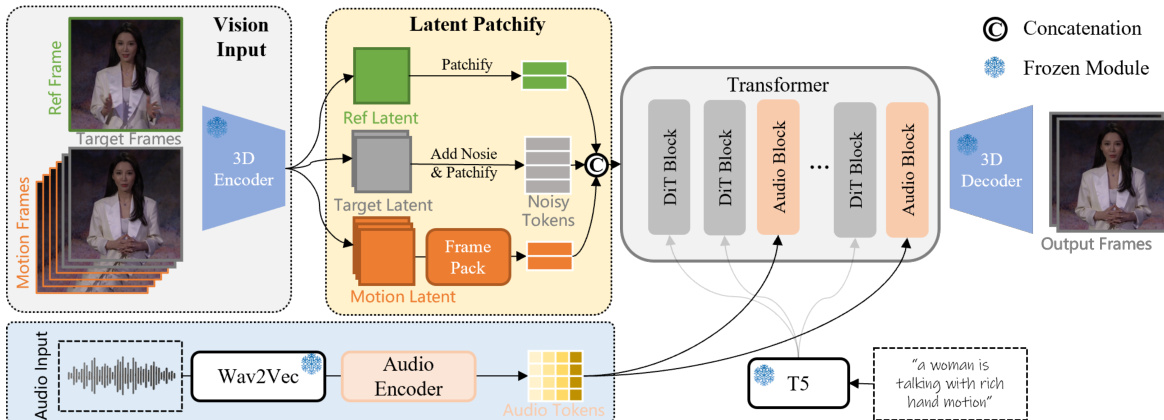
The audio input is processed through a Wav2Vec encoder to extract frame-wise acoustic features. To capture both low-level rhythmic and emotional cues and high-level lexical content, the model employs a weighted average layer that combines features from multiple layers of the Wav2Vec model using learnable weights. These features are then compressed along the temporal dimension via causal 1D convolutional modules, resulting in audio tokens that are temporally aligned with the video latent frames. The audio tokens are subsequently fed into the transformer backbone, where they are used to condition the denoising process. Specifically, the model predicts the velocity of the latent diffusion process, dtdx=ϵ−x0, by attending to the audio features and visual tokens in a cross-modal manner. To reduce computational overhead, attention is computed between the audio features and segments of the visual tokens along the temporal dimension, rather than performing full 3D attention across all tokens.
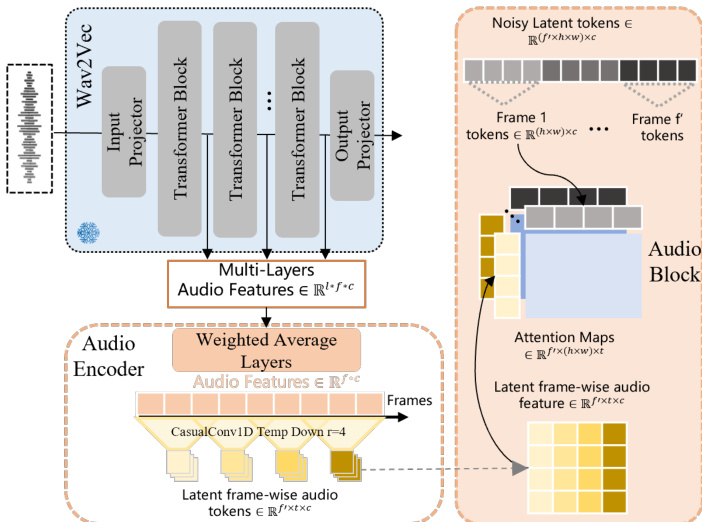
The core of the model consists of a transformer architecture composed of DiT (Diffusion Transformer) blocks and Audio Blocks. The DiT blocks process the visual latent tokens, while the Audio Blocks integrate the audio features into the visual stream. The model is trained using a flow matching objective, where the noise xt at a continuous time step t is defined as xt=tϵ+(1−t)x0, and the model learns to predict the velocity ϵ−x0. During inference, the model iteratively denoises the input latent tokens to reconstruct the target video frames, conditioned on the reference image, audio input, and prompt. The final output is decoded back into pixel space using a 3D decoder, producing a video that is synchronized with the audio and consistent with the reference image.

The training process employs a hybrid-parallel scheme combining Fully Sharded Data Parallelism (FSDP) and context parallelism to enable large-scale, full-parameter training. The model is trained in a three-stage process: first, the audio encoder is trained; second, the model is trained on speech videos; third, it is trained on a combination of film and television videos with speech; and finally, a high-quality Supervised Fine-Tuning (SFT) stage is applied to refine the output quality. This staged approach, combined with the use of a large-scale, diverse dataset, allows the model to generate expressive and natural character movements in complex scenarios, extending beyond simple talking-head animations to include text-guided global motion and audio-driven local motion.
Experiment
- Hybrid parallel training combining FSDP and Context Parallelism (RingAttention + Ulysses) enables near-linear speedup, reducing single iteration time from ~100 seconds to ~12 seconds on 8 GPUs, supporting training of models over 16B parameters and high-resolution video generation up to 48 frames at 1024×768 resolution.
- Variable-length resolution training using token count as a metric ensures efficient training by resizing or cropping videos exceeding a maximum token limit M.
- Compared to Ominihuman and Hunyuan-Avatar, our method achieves superior identity consistency, reduced facial distortion, and significantly greater motion diversity, especially during large-scale movements.
- FramePack integration enables long-term temporal coherence across multiple video clips, successfully preserving motion trends (e.g., consistent train direction and speed) and object identity (e.g., matching paper pickup across clips), outperforming OmniHuman and methods without FramePack.
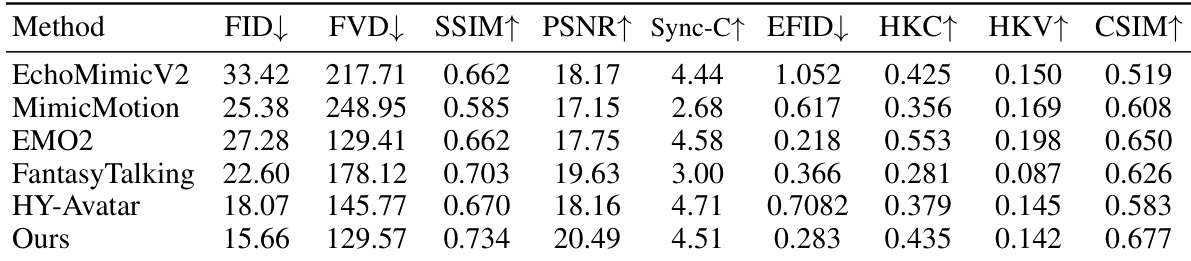
- On the EMTD dataset, our method achieves state-of-the-art results: lower FID (12.3), FVD (45.1), and higher SSIM (0.92), PSNR (28.7), CSIM (0.94), Sync-C (0.91), HKC (0.89), and HKV (0.76), demonstrating superior frame quality, video coherence, identity preservation, and rich hand motion generation.
Results show that the proposed method achieves the best performance across multiple metrics compared to state-of-the-art approaches. It outperforms all competitors in frame quality, as indicated by the lowest FID and FVD scores, and achieves the highest SSIM, PSNR, and CSIM values, demonstrating superior image quality and identity consistency. Additionally, the method produces more accurate hand shapes and richer hand motion, as reflected by higher HKC and HKV scores, while maintaining strong audio-visual synchronization.