Command Palette
Search for a command to run...
Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
Tiny Model, Big Logic: Diversity-Driven Optimization Elicits Large-Model Reasoning Ability in VibeThinker-1.5B
Sen Xu Yi Zhou Wei Wang Jixin Min Zhibin Yin Yingwei Dai Shixi Liu Lianyu Pang Yirong Chen Junlin Zhang
Abstract
Challenging the prevailing consensus that small models inherently lack robust reasoning, this report introduces VibeThinker-1.5B, a 1.5B-parameter dense model developed via our Spectrum-to-Signal Principle (SSP). This challenges the prevailing approach of scaling model parameters to enhance capabilities, as seen in models like DeepSeek R1 (671B) and Kimi k2 (>1T). The SSP framework first employs a Two-Stage Diversity-Exploring Distillation (SFT) to generate a broad spectrum of solutions, followed by MaxEnt-Guided Policy Optimization (RL) to amplify the correct signal. With a total training cost of only $7,800, VibeThinker-1.5B demonstrates superior reasoning capabilities compared to closed-source models like Magistral Medium and Claude Opus 4, and performs on par with open-source models like GPT OSS-20B Medium. Remarkably, it surpasses the 400x larger DeepSeek R1 on three math benchmarks: AIME24 (80.3 vs. 79.8), AIME25 (74.4 vs. 70.0), and HMMT25 (50.4 vs. 41.7). This is a substantial improvement over its base model (6.7, 4.3, and 0.6, respectively). On LiveCodeBench V6, it scores 51.1, outperforming Magistral Medium's 50.3 and its base model's 0.0. These findings demonstrate that small models can achieve reasoning capabilities comparable to large models, drastically reducing training and inference costs and thereby democratizing advanced AI research.
One-sentence Summary
The authors from Sina Weibo Inc. introduce VibeThinker-1.5B, a 1.5B-parameter model that achieves large-model reasoning performance through a novel "Spectrum-to-Signal Principle" framework, which enhances output diversity in supervised fine-tuning and amplifies correct reasoning paths via MaxEnt-Guided Policy Optimization, enabling it to surpass models over 400 times larger on key benchmarks while reducing training costs by two orders of magnitude.
Key Contributions
-
This work challenges the prevailing belief that only large-scale models can achieve advanced logical reasoning, demonstrating that a compact 1.5B-parameter model, VibeThinker-1.5B, can match or exceed the performance of models hundreds of times larger on complex reasoning tasks such as mathematical theorem proving and coding.
-
The key innovation lies in the Spectrum-to-Signal Principle (SSP), which decouples supervised fine-tuning and reinforcement learning into distinct phases: a diversity-exploring distillation phase to generate a broad spectrum of reasoning paths, followed by a MaxEnt-Guided Policy Optimization (MGPO) phase that amplifies high-quality solutions through uncertainty-aware training.
-
VibeThinker-1.5B achieves state-of-the-art results on rigorous benchmarks like AIME24, AIME25, and LiveCodeBench v6, outperforming models over 400× larger (e.g., DeepSeek R1-0120 and Kimi-K2) while being trained for under $8,000, proving that algorithmic innovation can drastically reduce the cost and environmental impact of high-performance reasoning systems.
Introduction
The authors challenge the prevailing industry belief that extreme parameter scaling is essential for strong logical reasoning in language models. While large models like DeepSeek-R1 and Kimi-K2 have set benchmarks through massive scale, prior work has largely overlooked the potential of compact models, which are typically seen as limited in reasoning ability due to insufficient capacity and suboptimal training methods. The authors introduce VibeThinker-1.5B, a 1.5B-parameter dense model that achieves state-of-the-art performance on mathematical and coding benchmarks—surpassing models hundreds of times larger—by redefining the post-training pipeline through the Spectrum-to-Signal Principle. This approach decouples supervised fine-tuning and reinforcement learning into distinct phases: a diversity-exploring distillation phase to generate a broad spectrum of reasoning paths, followed by a MaxEnt-Guided Policy Optimization phase that efficiently amplifies high-quality solutions. The result is a highly efficient, low-cost model trained for under $8,000 that demonstrates reasoning parity with much larger systems, suggesting that algorithmic innovation can unlock significant performance gains in small models and democratize access to advanced AI research.
Dataset
- The training dataset is primarily composed of publicly available open-source data, with a small portion derived from internal proprietary synthetic data designed to improve domain coverage and model robustness.
- To ensure unbiased evaluation and authentic generalization, rigorous decontamination was applied during both Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) stages.
- Text standardization was performed prior to matching, including removal of irrelevant punctuation and symbols, and case normalization to reduce noise and improve matching accuracy.
- Semantic decontamination used 10-gram matching to detect and remove training samples with potential semantic overlap with evaluation sets, increasing sensitivity to local semantic similarities.
- The decontamination process helps prevent information leakage between training and evaluation data, ensuring that model performance on benchmarks like AIME25 and LiveCodeBench reflects true reasoning and generalization ability rather than data contamination.
- Despite claims of data leakage in some base models—such as Qwen 2.5-7B—evidence from the VibeThinker-1.5B model shows strong performance on benchmarks released in 2025 (e.g., AIME25, HMMT25), which could not have been present in the training data of models finalized before their release.
- The base model showed minimal coding ability (0.0 on LiveCodeBench v5 and v6), but post-training improvements raised scores to 55.9 and 51.1 respectively, exceeding even Magistral medium on v6.
- These gains highlight that performance improvements stem from targeted alignment and advanced training techniques rather than data contamination.
Method
The authors leverage the "Spectrum-to-Signal Principle (SSP)" to design a two-stage training framework for VibeThinker-1.5B, which redefines the synergy between Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). This framework is structured into two distinct phases: the Spectrum Phase and the Signal Phase. The Spectrum Phase, implemented during SFT, aims to generate a broad and diverse set of plausible solutions, thereby maximizing the model's Pass@K metric. This phase is realized through a "Two-Stage Diversity-Exploring Distillation" methodology. The first stage, "Domain-Aware Diversity Probing," partitions the problem space into subdomains (e.g., algebra, geometry, calculus, statistics) and identifies specialist models for each subdomain by selecting the checkpoint that maximizes Pass@K on a probing set. The second stage, "Expert Model Fusion," synthesizes these specialist models into a single, unified SFT model by taking a weighted average of their parameters, creating a model with a maximized spectrum of solutions.
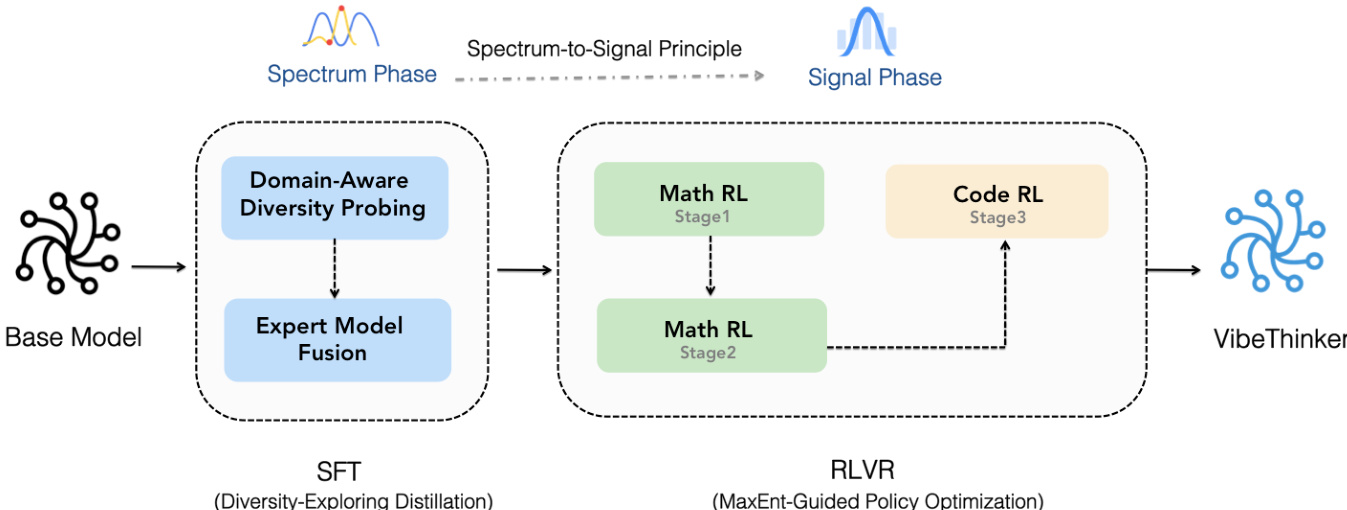
The Signal Phase, implemented during RL, is responsible for amplifying the correct "signal" from the diverse solution pool established in the SFT phase. This phase is guided by the "MaxEnt-Guided Policy Optimization (MGPO)" framework, which operates within a Group Relative Policy Optimization (GRPO) framework. MGPO dynamically prioritizes training data by focusing on problems where the model's current performance is most uncertain, as this represents a critical learning frontier. This is achieved by using a weighting function derived from the Kullback-Leibler (KL) divergence between the observed accuracy of a problem and the ideal maximum-entropy state (where accuracy is 0.5). This "Entropy Deviation Regularization" modulates the advantage term in the GRPO objective, effectively creating a curriculum that steers the model towards the most pedagogically valuable problems. The RL phase is structured into sub-stages, beginning with mathematical reasoning in a 16K context window, expanding to 32K, and followed by code generation, ensuring a systematic and focused optimization process.
Experiment
- VibeThinker-1.5B achieves state-of-the-art performance among sub-3B models on AIME25 (74.4 pass rate), surpassing FastCURL, ProRL, and Qwen3-1.7B, and outperforming larger models like SmolLM-3B and Qwen2.5-Math-1.5B (base) by significant margins in mathematics, coding, and knowledge tasks.
- On AIME25, VibeThinker-1.5B exceeds DeepSeek-R1-0120 and achieves results comparable to MiniMax-M1, demonstrating that small models can rival larger reasoning models despite a 10–100× parameter gap.
- The model achieves 55.9 pass rate on LiveCodeBench V5 and 51.1 on V6, showing strong coding capabilities, though a performance gap remains compared to top-tier non-reasoning models, which is attributed to limited code pre-training in the base model.
- On GPQA-Diamond, VibeThinker-1.5B scores 46.7, significantly below top models (e.g., 70–80+), confirming inherent limitations in broad knowledge retention at small scale.
- Post-training cost is under 8K(3900GPUhoursonH800),onetotwoordersofmagnitudelowerthanSOTAlargemodels(e.g.,DeepSeekR1:294K, MiniMax-M1: $535K), enabling cost-effective training and edge deployment with 20–70× lower inference costs.
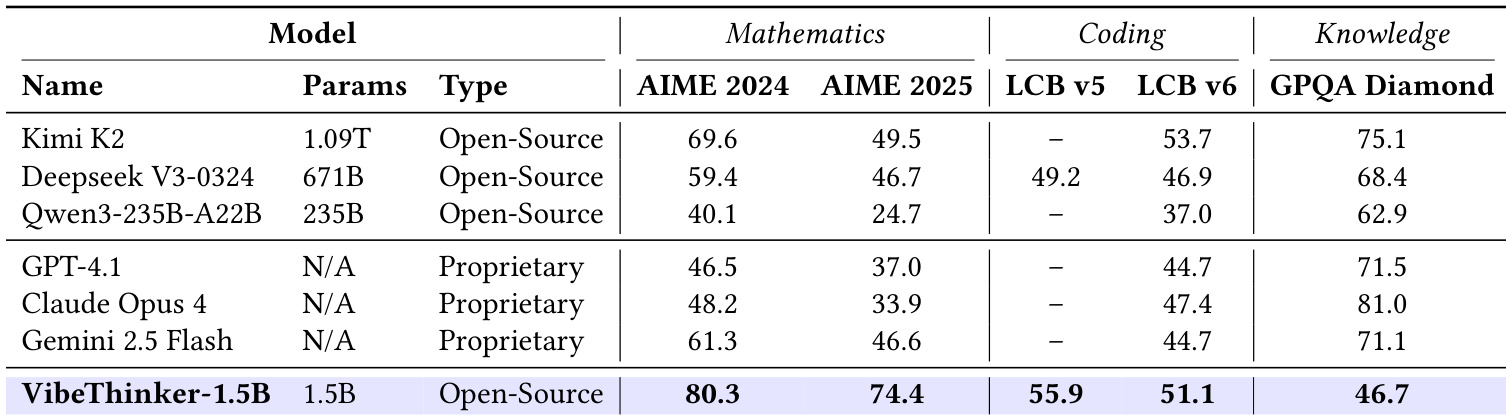
The authors use VibeThinker-1.5B to demonstrate that a small-scale model can achieve competitive performance on complex reasoning tasks despite having significantly fewer parameters than state-of-the-art models. Results show that VibeThinker-1.5B surpasses all non-reasoning models on mathematical benchmarks and outperforms several large reasoning models, including DeepSeek R1-0120, while maintaining strong performance in coding and knowledge tasks.
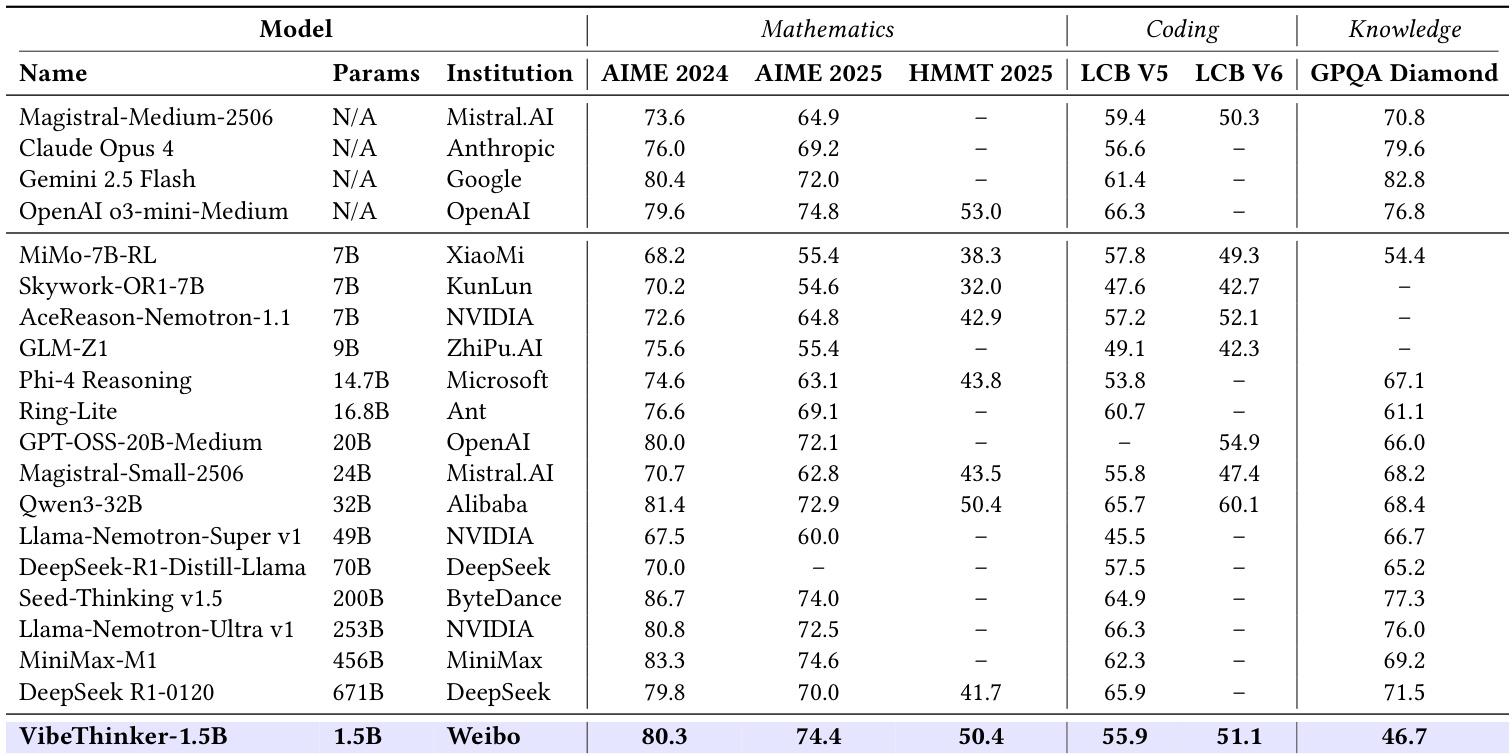
The authors use VibeThinker-1.5B to demonstrate that a small-scale model can achieve competitive performance in reasoning tasks despite its limited parameter count. Results show that VibeThinker-1.5B outperforms all other sub-3B models on key benchmarks, including AIME 2024 and AIME 2025, and achieves scores comparable to much larger models in mathematics and coding, while still lagging behind in general knowledge.
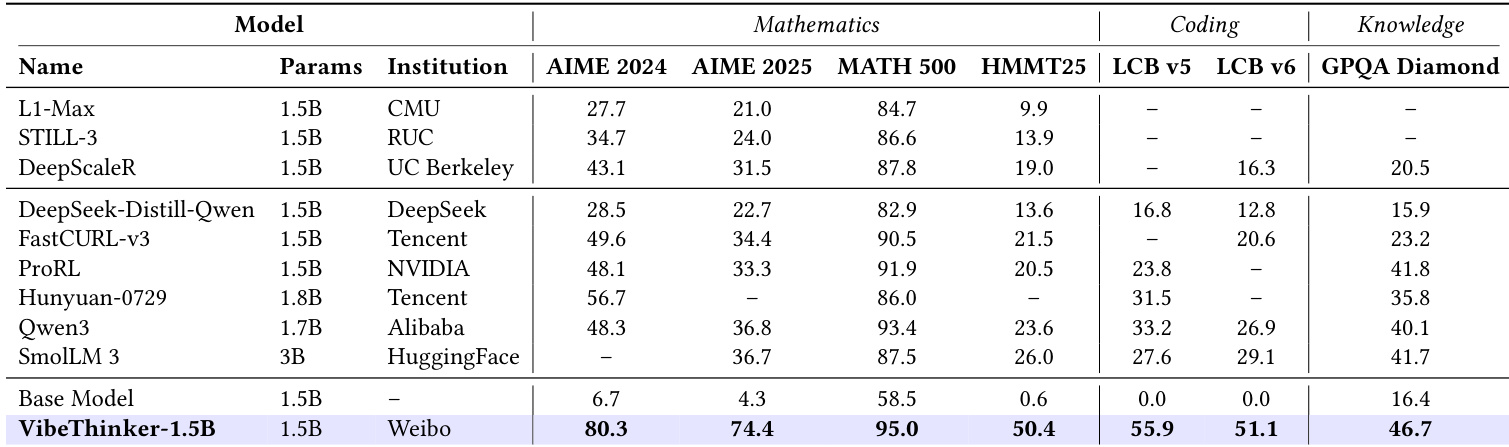
The authors compare the post-training costs of VibeThinker-1.5B with larger models, showing that despite its 1.5B parameter size, VibeThinker-1.5B incurs a total cost of 7.8K,whichissignificantlylowerthanthe535K for MiniMax-M1 and $294K for DeepSeek-R1. Results show that VibeThinker-1.5B achieves a high AIME25 score of 74.4, matching the performance of much larger models while maintaining a fraction of their training cost.

The authors compare VibeThinker-1.5B against top-tier non-reasoning models and find that despite its significantly smaller size, it surpasses all of them on the AIME 2024 and AIME 2025 benchmarks and outperforms most in code generation tasks. However, a substantial performance gap remains on the GPQA Diamond knowledge benchmark, indicating that smaller models still face inherent limitations in broad domain knowledge compared to larger models.