Command Palette
Search for a command to run...
Logics-Parsing-Omni Technical Report
Logics-Parsing-Omni Technical Report
Logics Team
Abstract
Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables "evidence-based" logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench.
One-sentence Summary
The Logics Team proposes the Omni Parsing framework, which utilizes a progressive parsing paradigm across documents, images, and audio-visual streams to integrate hierarchical detection, recognition, and interpreting through an evidence anchoring mechanism, enabling the Logics-Parsing-Omni model to transform unstructured signals into traceable, machine-readable structured knowledge as evaluated by the OmniParsingBench.
Key Contributions
- The paper introduces the Omni Parsing framework, which establishes a unified taxonomy across documents, images, and audio-visual streams through a progressive paradigm that bridges perception and cognition. This framework utilizes an evidence anchoring mechanism to align high-level semantic descriptions with low-level facts, transforming unstructured signals into locatable, enumerable, and traceable standardized knowledge.
- This work presents Logics-Parsing-Omni, an advanced Multimodal Large Language Model (MLLM) optimized for holistic detection, fine-grained recognition, and multi-level interpreting. The model employs a data-centric strategy involving enriched knowledge-intensive image samples and optimized video annotations for shot analysis and long-form content to ensure semantically rich and verifiable outputs.
- The researchers developed OmniParsingBench, a standardized benchmark covering document, image, and audio-video content to quantitatively evaluate omni-modal parsing capabilities. Experimental results on this benchmark demonstrate that the model achieves state-of-the-art performance and maintains a strong balance between structural fidelity and semantic interpretation across all modalities.
Introduction
Effective multimodal parsing is essential for knowledge-intensive applications like Retrieval-Augmented Generation (RAG) and intelligent tutoring, where models must process complex documents, images, and long-form videos. Existing methods often suffer from a structural dilemma where low-level extraction tools lack semantic depth, while high-level generative models frequently lack layout fidelity and fine-grained grounding. This gap leads to information loss in charts, hallucinations in image descriptions, and a lack of structural granularity in audio-visual transcripts. The authors address these challenges by proposing the Omni Parsing framework, which introduces a progressive paradigm to bridge pixel-based perception and logic-based cognition. They leverage a three-level hierarchical approach consisting of holistic detection, fine-grained recognition, and multi-level interpreting to transform unstructured signals into standardized, traceable knowledge. To support this framework, the authors also release the Logics-Parsing-Omni model and the OmniParsingBench evaluation suite.
Dataset
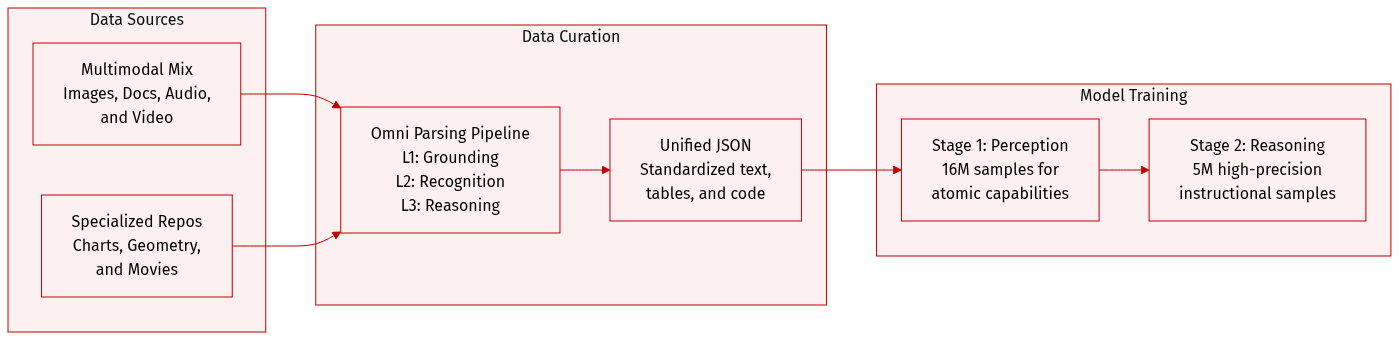
The authors constructed a large-scale, diverse, and high-quality corpus designed for unified multimodal parsing across four primary domains: Image, Document, Audio, and Video.
Dataset Composition and Subsets
- Image Domain:
- Natural Images: Includes single-image datasets for structured parsing and a multi-image difference dataset. The latter uses real-world image pairs with VLM-based filtering to ensure aesthetic quality and semantic consistency.
- Graphics: A specialized repository containing charts (line, bar, pie, flowcharts, etc.) sourced from various public datasets. These are annotated to decouple plotting regions from text.
- Geometric Figures: Includes single-image interpretations from K-12 textbooks and multi-image pairs representing atomic geometric operations (e.g., adding an angle bisector).
- Document Domain: Comprises over 300,000 high-quality page-level images. Sources include public datasets like olmOCR-mix-0225, FinTabNet, TNCR, and PubTabNet, alongside a large-scale in-house dataset.
- Audio Domain: Provides time-aligned semantic chunks that integrate speaker-attributed transcriptions with acoustic events and scene descriptions.
- Video Domain:
- General Video: Contains 511,000 captioning samples and 266,000 parsing samples, processed through a pipeline involving Voice Activity Detection and scene boundary detection.
- Camera-aware Video: A 191,000-sample dataset sourced from MovieNet and internal collections, focusing on precise spatiotemporal grounding of camera motions.
- Text-Rich Video: An in-house collection of educational YouTube videos, featuring 130,000 structured captions and 79,000 parsing entries.
Data Processing and Metadata Construction
- Three-Level Parsing Framework: The authors process data through a progressive pipeline: L1-Holistic Detection (spatio-temporal grounding), L2-Fine-grained Recognition (text, symbol, and attribute extraction), and L3-Multi-level Interpreting (semantic synthesis and logical reasoning).
- Standardized Output: All data is transformed into a unified JSON format. For images, this includes Entity Objects, Text Blocks, and Global Descriptions. For charts, statistical data is converted to HTML tables, while flowcharts are transcribed into Mermaid code.
- Knowledge Enhancement: A strict mechanism links entities to authoritative identifiers (e.g., landmarks or species) only when visual evidence is unambiguous.
- Video Synthesis: The authors use a multi-stage pipeline to fuse unimodal streams, calculating the intersection of visual boundaries and audio semantic chunks to ensure cross-modal consistency.
Model Training Usage
- Two-Stage Training Strategy:
- Stage 1: Uses a 16M scale corpus to establish atomic capabilities and basic perception.
- Stage 2: Employs 5M high-precision instructional samples for deep fine-tuning and complex reasoning.
- Hybrid Mixture: The training data is a hybrid mixture of the unified structured parsing data generated by the Omni Parsing framework and diverse Caption and QA data to ensure full-modal alignment.
Method
The Logics-Parsing-Omni methodology is built upon a three-level progressive paradigm that unifies perception and cognition across multiple modalities. The authors propose the Omni Parsing framework, which transitions from Holistic Detection (L1) to Fine-grained Recognition (L2) and finally to Semantic Interpretation (L3). This framework is designed to handle diverse inputs including documents, images, audio, and video streams.
As shown in the framework diagram:

The foundation of this approach lies in the construction of a large-scale unified corpus. This corpus integrates heterogeneous tasks such as structural parsing for documents, single and multi-image difference analysis for graphics, and complex temporal understanding for audio and video. To process the audio modality specifically, the authors implement a time-aligned parsing process. This involves speaker-attributed transcription using speaker diarization to create a "SpeakerID-ASR-Timestamp" triplet, alongside acoustic scene modeling to capture non-linguistic cues like environmental noise or music. These elements are synthesized into unified audio semantic chunks that provide high-resolution supervision for cross-modal alignment.
The training process follows a two-stage progressive strategy, initializing from the Qwen3-Omni-30B-A3B model. In the first stage, titled Panoramic Cognitive Foundation, the model undergoes full-parameter supervised fine-tuning (SFT) on a large-scale dataset of 16 million samples. This stage prioritizes data scale and coverage to establish foundational skills in holistic detection and fine-grained recognition. It includes massive visual knowledge injection through approximately 12.6 million image-based QA pairs and the aggregation of diverse atomic capabilities, such as document structure parsing and audio-visual captioning.
The second stage, Unified Parsing Alignment, focuses on refining the model through balanced instruction tuning. To rectify task distribution biases from the first stage, the authors utilize a high-quality dataset of 5 million samples. This stage activates the full L1-to-L3 progressive parsing pipeline across all domains.
Refer to the training pipeline diagram:
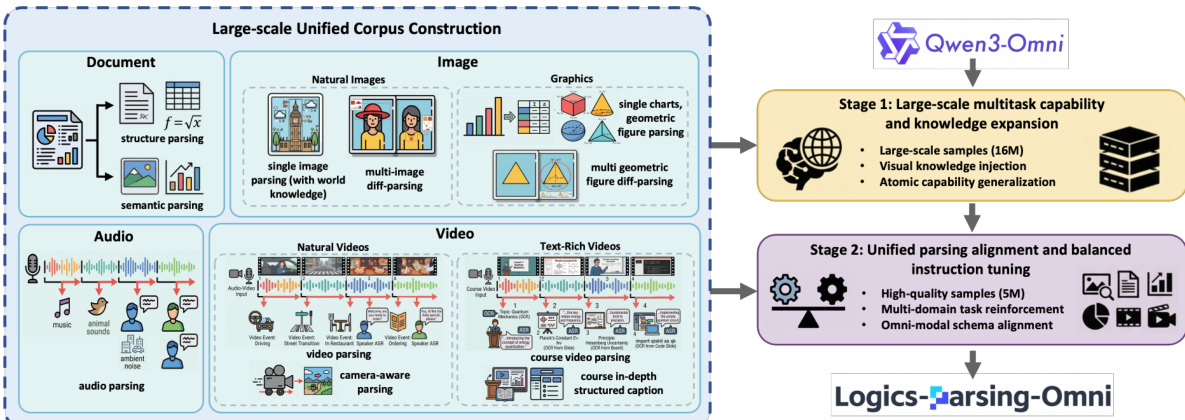
During this alignment phase, the model is trained to map heterogeneous omni-modal inputs into standardized JSON formats. This ensures a dual alignment where the model can perform both structured extraction and fluent natural language generation. By enforcing this unified schema, the model learns to bridge spatial-temporal grounding with high-level semantic reasoning, effectively achieving the synergy between signal-level perception and cognitive interpretation.
Experiment
The evaluation framework assesses model performance through two core dimensions: Perception, which validates signal detection and structural recovery, and Cognition, which measures semantic depth and logical reasoning. Experiments across natural images, graphics, documents, audio, and video demonstrate that Logics-Parsing-Omni achieves state-of-the-art or highly competitive results, often surpassing leading proprietary models like Gemini-3-Pro. The findings conclude that integrating fine-grained structural parsing with semantic descriptions provides a necessary foundation for robust, hallucination-resistant reasoning in complex, multi-modal scenarios.
The authors evaluate the Logics-Parsing-Omni model on the Natural Video module of OmniParsingBench, comparing it against Gemini-3-Pro and the Qwen3-Omni-30B-A3B baseline. Results show that while the model performs competitively in perception and cognition, it achieves significant advantages in specific areas like camera motion analysis. The model achieves a leading score in camera motion analysis within the perception dimension. In the cognition dimension, the model demonstrates strong performance in visual semantics and dynamics, particularly in camera captioning accuracy. The model maintains highly competitive results in audio-visual reasoning tasks, including emotion and causal reasoning.

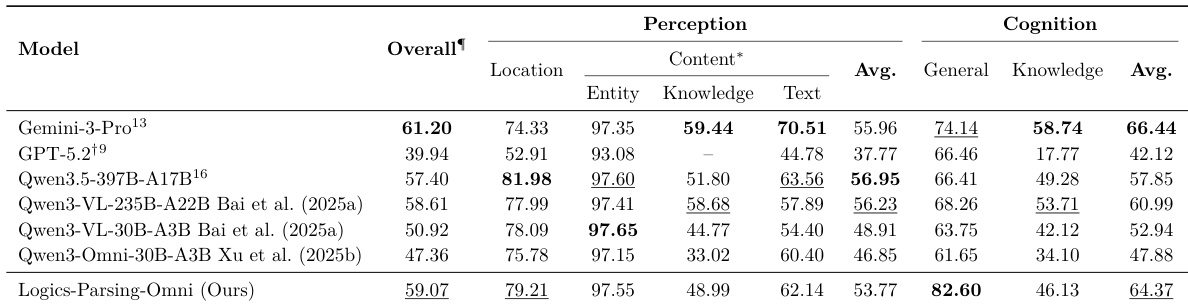
The the the table compares the performance of various vision-language models on entity, knowledge-aware entity, and text parsing tasks. The results show that while different models excel in specific sub-metrics like localization recall or semantic accuracy, their overall average performance varies significantly. The model with the highest overall average score demonstrates a strong balance across different parsing categories. Regarding text parsing, one model achieves the highest localization recall and language accuracy among the evaluated group. For knowledge-aware entities, the top-performing model shows superior localization recall compared to other evaluated models.

The authors evaluate several models on the Natural Image module of OmniParsingBench, comparing perception and cognition capabilities. Results show that the proposed model achieves a high score in general semantic understanding, outperforming both open-weight and proprietary models in that specific dimension. The proposed model achieves the highest score in general cognition, surpassing proprietary models. The model maintains a competitive balance between spatial localization and semantic content extraction. While the model excels in general semantic understanding, its performance in knowledge-aware entity parsing is lower compared to its general entity and text recognition capabilities.
The authors evaluate the Logics-Parsing-Omni model on the Audio Module of OmniParsingBench, comparing it against several baseline models. Results show that the proposed model achieves the highest overall score, driven by strong performance in cognitive tasks. Logics-Parsing-Omni achieves a state-of-the-art overall score on the audio module. The model demonstrates superior performance in audio recognition compared to the strongest baseline. The model shows high proficiency in audio information extraction, contributing to its leading cognitive average.

The authors evaluate the Logics-Parsing-Omni model on the Graphics module of OmniParsingBench, focusing on charts and geometric figures. Results show that the model achieves the highest overall accuracy, demonstrating superior performance in both perceptual extraction and cognitive reasoning compared to several state-of-the-art models. The model achieves leading performance in chart cognition, particularly in OCR and data extraction tasks. Logics-Parsing-Omni demonstrates exceptional capability in extracting visual elements within structured charts. The model's overall cognitive accuracy surpasses both open-weight and proprietary baselines in the graphics domain.

The Logics-Parsing-Omni model was evaluated across the Natural Video, Text, Natural Image, Audio, and Graphics modules of OmniParsingBench to validate its perception and cognition capabilities against various open-weight and proprietary baselines. The model demonstrates state-of-the-art performance in audio recognition, chart cognition, and camera motion analysis, while maintaining a strong balance in general semantic understanding and visual reasoning. Overall, the results indicate that the model excels in complex cognitive tasks and structured data extraction across diverse multimodal domains.