HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

AnyRecon:基于视频扩散模型的任意视角 3D 重建

AgentSPEX:一种 agent 规范与执行语言



























AnyRecon:基于视频扩散模型的任意视角 3D 重建
AgentSPEX:一种 agent 规范与执行语言
CoInteract:通过空间结构化协同生成实现物理一致性的人机交互视频合成
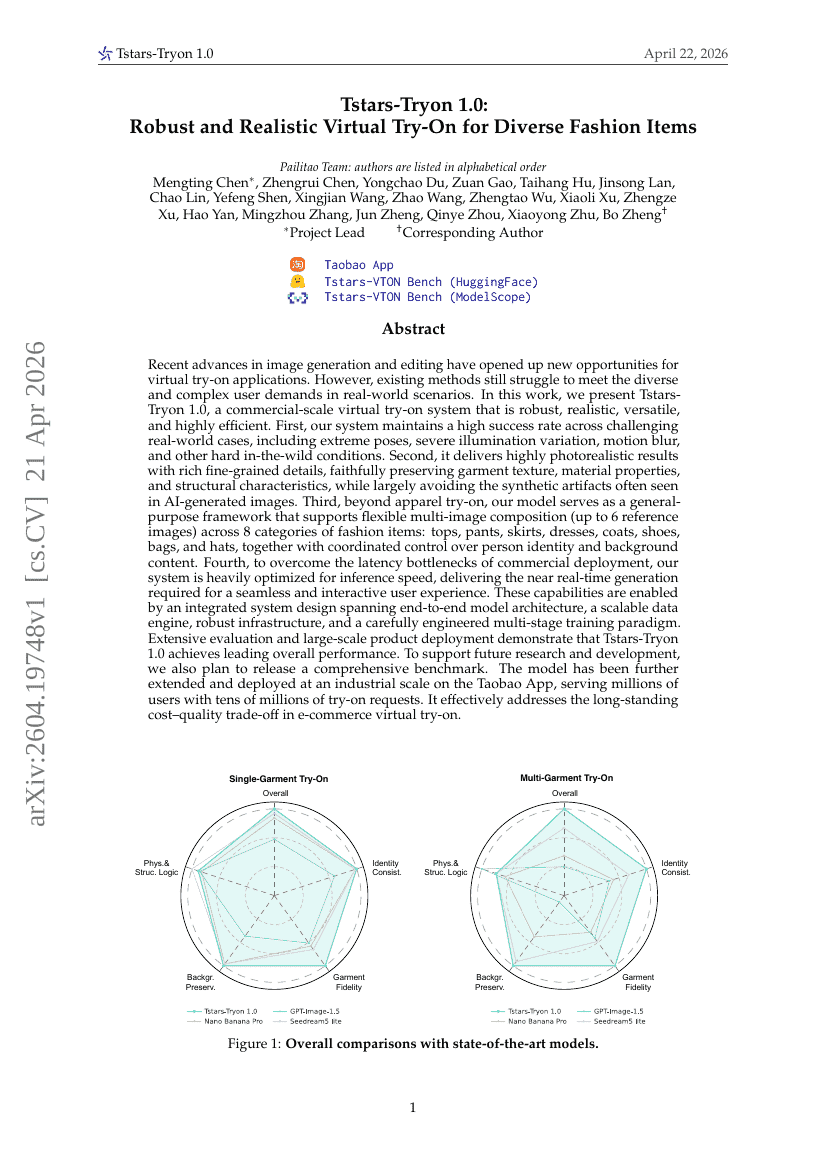
Tstars-Tryon 1.0:针对多样化时尚单品的鲁棒且逼真的虚拟试穿研究
用于 Large Language Model 推理的快速 NF4 量化反量化 Kernel
EasyVideoR1:面向视频理解的更简便强化学习方法
MultiWorld:可扩展的多 agent 多视角视频世界模型
OpenGame:面向游戏的开放式 agentic 编程
Agent-World:为演进式通用 agent intelligence 扩展真实世界环境合成规模
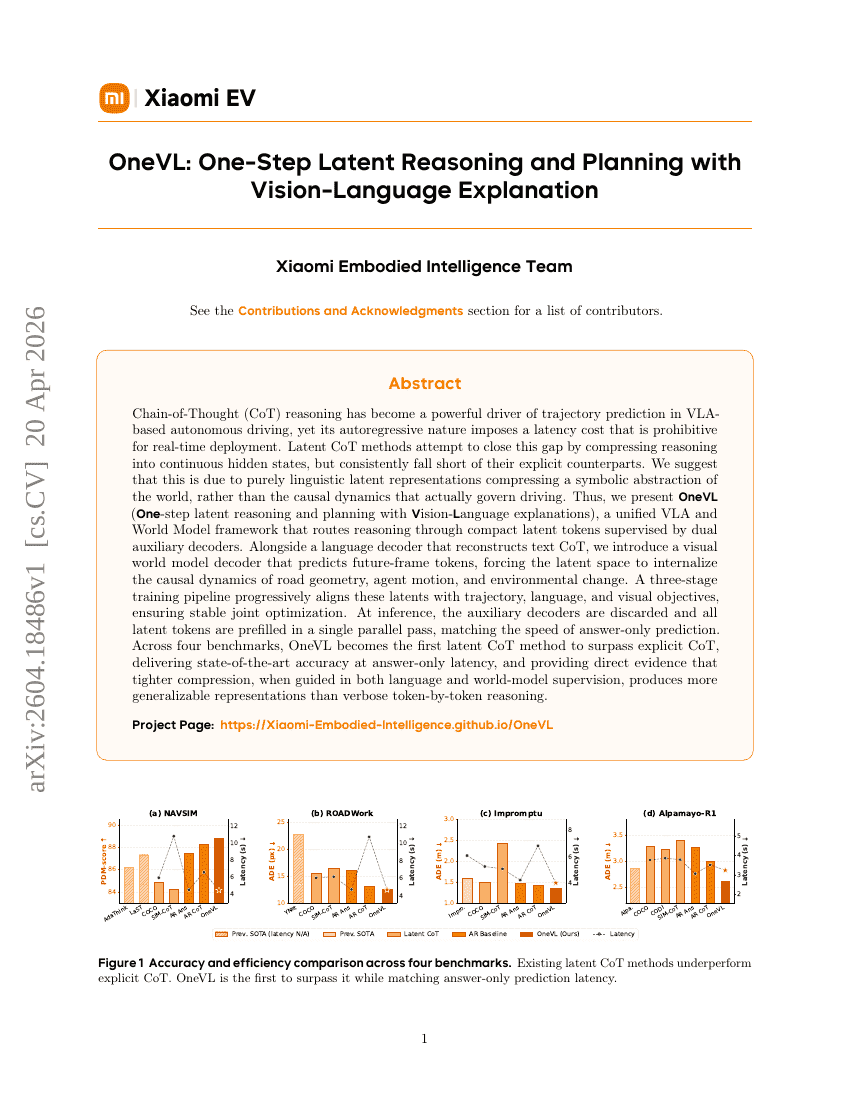
OneVL:结合视觉-语言解释的一步式潜在推理与规划
通过判别式文本表示将单步图像生成从类别标签扩展至文本
ScribblePrompt: 面向各类生物医学图像的高效且灵活的交互式分割方法
Long-VITA: 将 Large Multi-modal Models 扩展至 100 万 tokens 并保持领先的短上下文准确率
UI-TARS:开创基于 Native Agent 的自动化 GUI 交互研究
HunyuanVideo: 大规模视频生成模型的系统性框架
MathNet:一个用于数学推理与检索的全球多模态基准测试
LLM Agents 中的外部化:关于 Memory、Skills、Protocols 与 Harness Engineering 的统一综述
主动上下文压缩:LLM Agents 中的自主内存管理
及时止损!通过早期路径剪枝实现高效的并行推理学习
Qwen3.5-Omni 技术报告
面向高效与低成本检索增强生成系统的网页检索感知分块方法(W-RAC)
PersonaVLM:长期的个性化 Multimodal LLMs
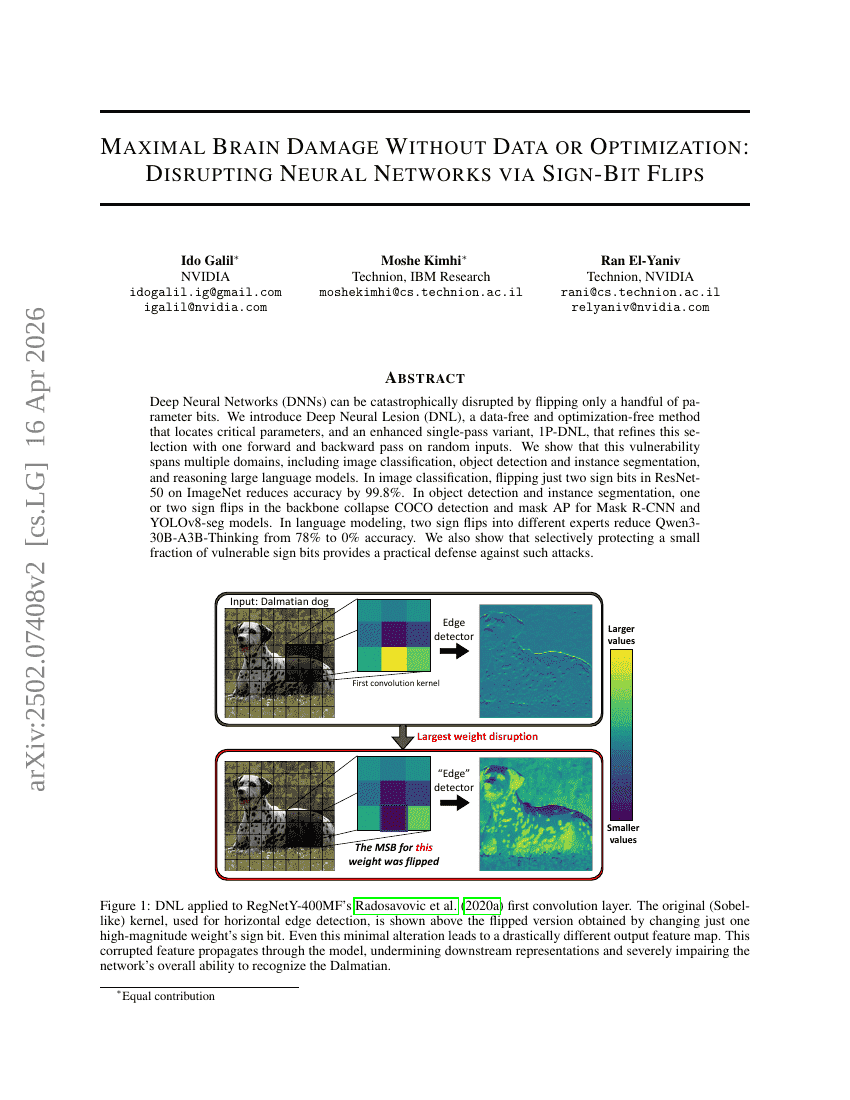
无需数据或优化实现最大脑损伤:通过 Sign-Bit Flips 破坏 Neural Networks
阐明扩散概率模型中的 SNR-t 偏差
多模态 OCR:解析文档中的一切内容
Granite-speech:具备强大英语 ASR 能力的开源语音感知 LLMs
Fish-Speech:利用 Large Language Models 实现先进的多语言 Text-to-Speech 合成
视频对象与交互删除
VoxCPM:面向上下文感知语音生成与高保真声音克隆的 Tokenizer-Free TTS
OmniVoice: 迈向基于 Diffusion Language Models 的全语种 Zero-Shot Text-to-Speech 研究
视觉如何转化为文本:定位 Vision-Language Models 中的 OCR Routing 瓶颈
OCR 还是非 OCR?在 MLLMs 时代利用真实世界大规模数据集重新思考文档信息抽取
CoInteract:通过空间结构化协同生成实现物理一致性的人机交互视频合成
Tstars-Tryon 1.0:针对多样化时尚单品的鲁棒且逼真的虚拟试穿研究
用于 Large Language Model 推理的快速 NF4 量化反量化 Kernel
EasyVideoR1:面向视频理解的更简便强化学习方法
MultiWorld:可扩展的多 agent 多视角视频世界模型
OpenGame:面向游戏的开放式 agentic 编程
Agent-World:为演进式通用 agent intelligence 扩展真实世界环境合成规模
OneVL:结合视觉-语言解释的一步式潜在推理与规划
通过判别式文本表示将单步图像生成从类别标签扩展至文本
ScribblePrompt: 面向各类生物医学图像的高效且灵活的交互式分割方法
Long-VITA: 将 Large Multi-modal Models 扩展至 100 万 tokens 并保持领先的短上下文准确率
UI-TARS:开创基于 Native Agent 的自动化 GUI 交互研究
HunyuanVideo: 大规模视频生成模型的系统性框架
MathNet:一个用于数学推理与检索的全球多模态基准测试
LLM Agents 中的外部化:关于 Memory、Skills、Protocols 与 Harness Engineering 的统一综述
主动上下文压缩:LLM Agents 中的自主内存管理
及时止损!通过早期路径剪枝实现高效的并行推理学习
Qwen3.5-Omni 技术报告
面向高效与低成本检索增强生成系统的网页检索感知分块方法(W-RAC)
PersonaVLM:长期的个性化 Multimodal LLMs
无需数据或优化实现最大脑损伤:通过 Sign-Bit Flips 破坏 Neural Networks
阐明扩散概率模型中的 SNR-t 偏差
多模态 OCR:解析文档中的一切内容
Granite-speech:具备强大英语 ASR 能力的开源语音感知 LLMs
Fish-Speech:利用 Large Language Models 实现先进的多语言 Text-to-Speech 合成
视频对象与交互删除
VoxCPM:面向上下文感知语音生成与高保真声音克隆的 Tokenizer-Free TTS
OmniVoice: 迈向基于 Diffusion Language Models 的全语种 Zero-Shot Text-to-Speech 研究
视觉如何转化为文本:定位 Vision-Language Models 中的 OCR Routing 瓶颈
OCR 还是非 OCR?在 MLLMs 时代利用真实世界大规模数据集重新思考文档信息抽取