HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

AGENTIC-IMODELS:通过自动研究进化智能代理可解释性工具

HEAVYSKILL:作为代理驾驭中内在能力的深度思考


























AGENTIC-IMODELS:通过自动研究进化智能代理可解释性工具
HEAVYSKILL:作为代理驾驭中内在能力的深度思考
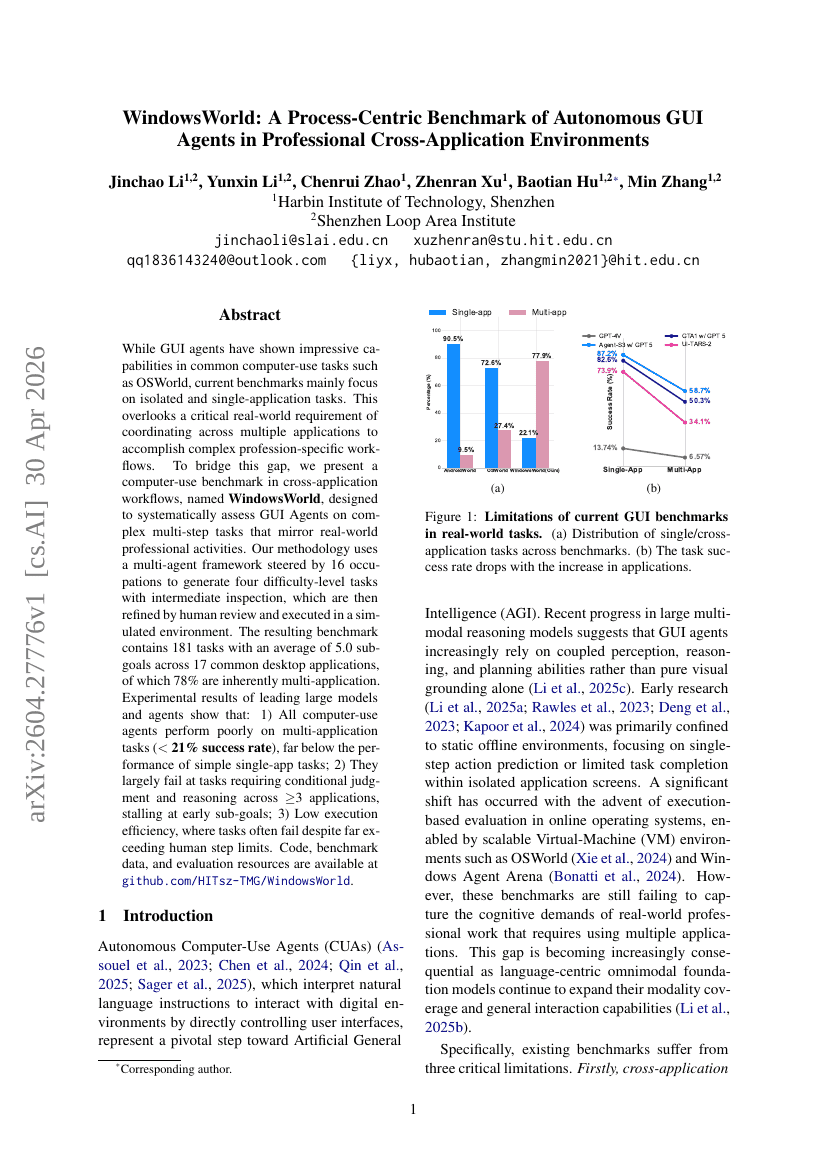
WindowsWorld:面向专业跨应用环境中自主GUI智能体的以进程为中心的基准测试
幻觉削弱信任;元认知是前进之路
X2SAM:图像与视频中的任意分割
OpenSeeker-v2:通过信息丰富和高难度轨迹推动搜索智能体的极限
PRISM:面向多模态强化学习的黑盒在线蒸馏预对齐
ARIS:通过对抗性多智能体协作实现自主研究
ProgramBench:语言模型能否从零开始重建程序?
基于GPU的高效加速图编辑距离计算
基于LLM的社会媒体情境信号危机报道不确定性评估
标准LST:一种面向Tezos的原生协议流动性质押解决方案
分离智力与执行:面向模型上下文协议的工作流引擎
理解文本到视频检索中的性能瓶颈:一项综合的经验与语言学分析
持久视觉记忆:在LVLMs的深度生成中维持感知
EnergAIzer:面向 AI 工作负载的快速且准确 GPU 功耗估算框架
利用基于验证器的强化学习进行图像编辑
使用RoundPipe在多个消费级GPU上实现高效训练
ExoActor:作为可泛化交互人形控制的偏中心视频生成
联合演化的策略蒸馏
新时代视觉生成:从原子映射到代理世界建模的演变
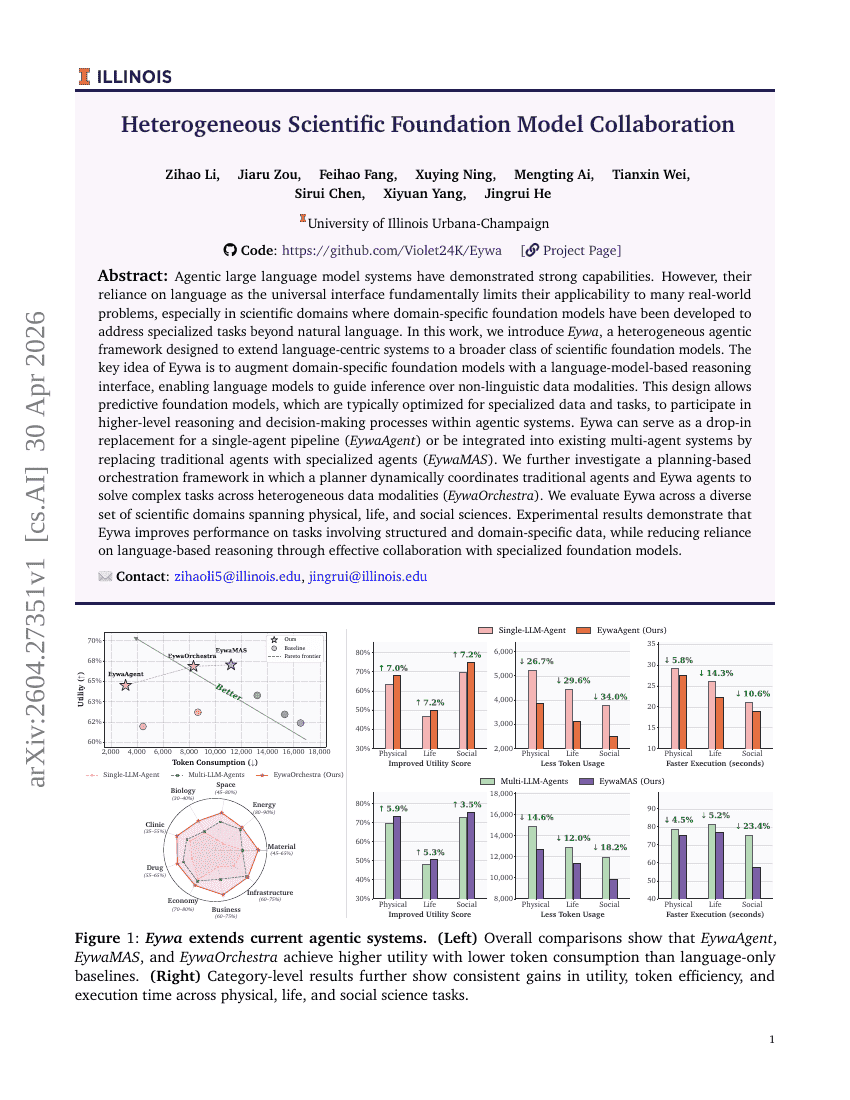
异构科学基础模型协作
扩散模板:一种用于可控扩散的统一插件框架
RADIO-ViPE:动态环境中开放词汇语义SLAM的在线紧耦合多模态融合
ClawGym:构建高效Claw代理的可扩展框架
扭转局势:扩散大型语言模型的跨架构知识蒸馏
大语言模型通过潜在蒸馏进行探索
GLM-5V-Turbo:迈向面向多模态 agents 的原生基础模型
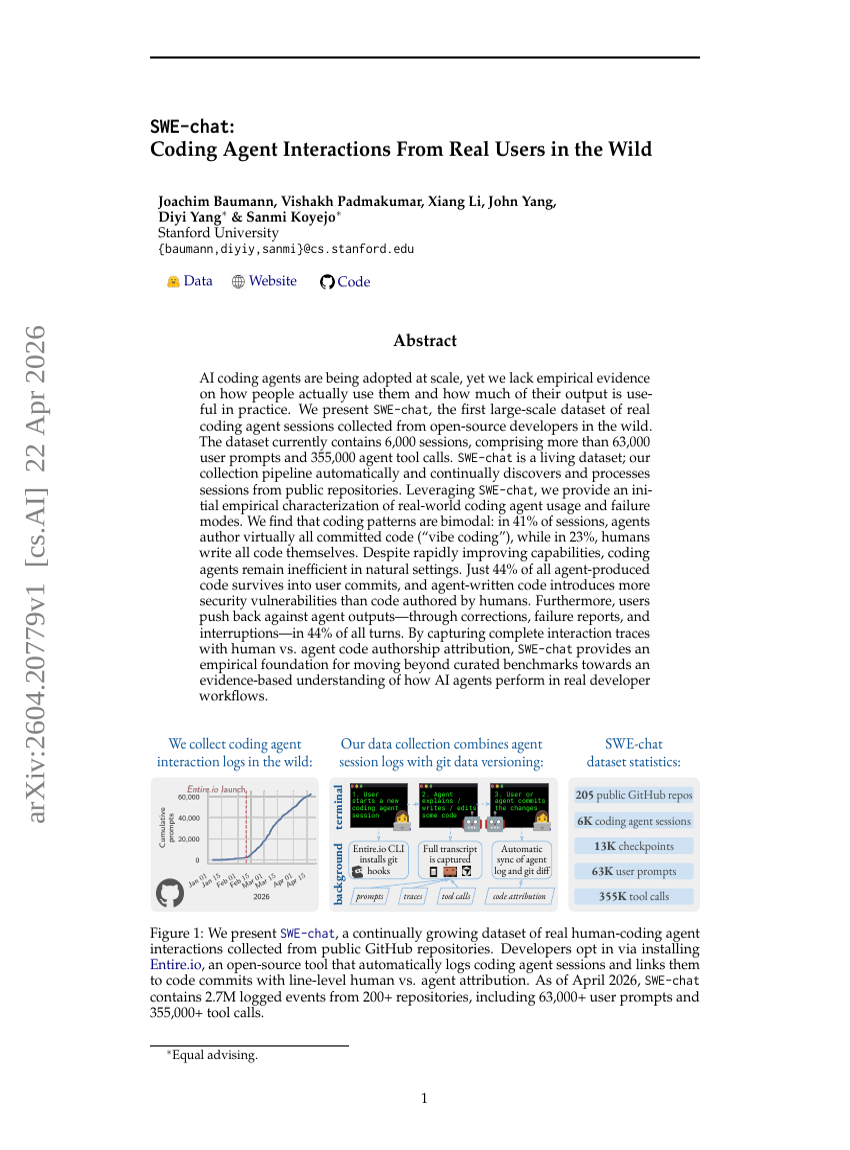
SWE-chat:来自真实用户在自然环境下编码智能体交互的研究
AdaExplore:面向高效内核生成的失败驱动自适应与多样性保持搜索
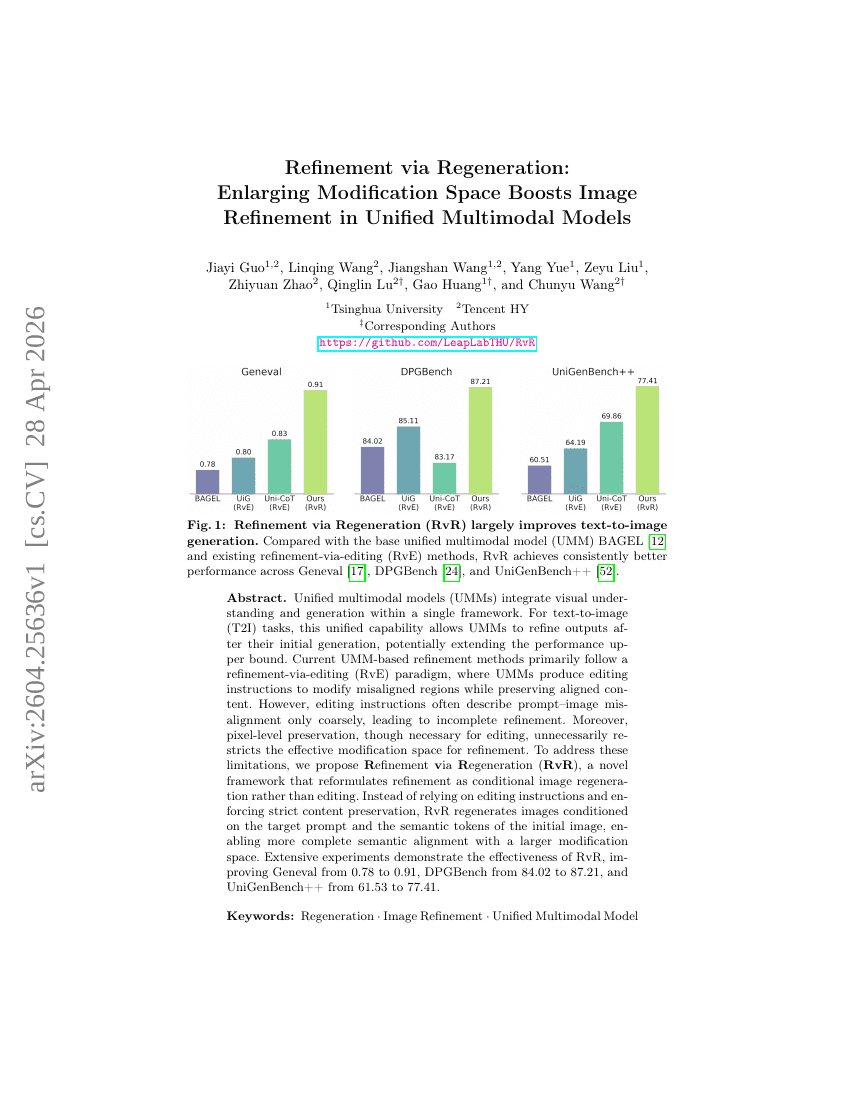
通过再生进行优化:扩展修改空间可提升统一多模态模型中的图像优化效果
AutoResearchBench: 在复杂科学文献发现中评估AI代理的基准测试
WindowsWorld:面向专业跨应用环境中自主GUI智能体的以进程为中心的基准测试
幻觉削弱信任;元认知是前进之路
X2SAM:图像与视频中的任意分割
OpenSeeker-v2:通过信息丰富和高难度轨迹推动搜索智能体的极限
PRISM:面向多模态强化学习的黑盒在线蒸馏预对齐
ARIS:通过对抗性多智能体协作实现自主研究
ProgramBench:语言模型能否从零开始重建程序?
基于GPU的高效加速图编辑距离计算
基于LLM的社会媒体情境信号危机报道不确定性评估
标准LST:一种面向Tezos的原生协议流动性质押解决方案
分离智力与执行:面向模型上下文协议的工作流引擎
理解文本到视频检索中的性能瓶颈:一项综合的经验与语言学分析
持久视觉记忆:在LVLMs的深度生成中维持感知
EnergAIzer:面向 AI 工作负载的快速且准确 GPU 功耗估算框架
利用基于验证器的强化学习进行图像编辑
使用RoundPipe在多个消费级GPU上实现高效训练
ExoActor:作为可泛化交互人形控制的偏中心视频生成
联合演化的策略蒸馏
新时代视觉生成:从原子映射到代理世界建模的演变
异构科学基础模型协作
扩散模板:一种用于可控扩散的统一插件框架
RADIO-ViPE:动态环境中开放词汇语义SLAM的在线紧耦合多模态融合
ClawGym:构建高效Claw代理的可扩展框架
扭转局势:扩散大型语言模型的跨架构知识蒸馏
大语言模型通过潜在蒸馏进行探索
GLM-5V-Turbo:迈向面向多模态 agents 的原生基础模型
SWE-chat:来自真实用户在自然环境下编码智能体交互的研究
AdaExplore:面向高效内核生成的失败驱动自适应与多样性保持搜索
通过再生进行优化:扩展修改空间可提升统一多模态模型中的图像优化效果
AutoResearchBench: 在复杂科学文献发现中评估AI代理的基准测试