HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

ACC:编译 Agent 轨迹以进行长上下文训练
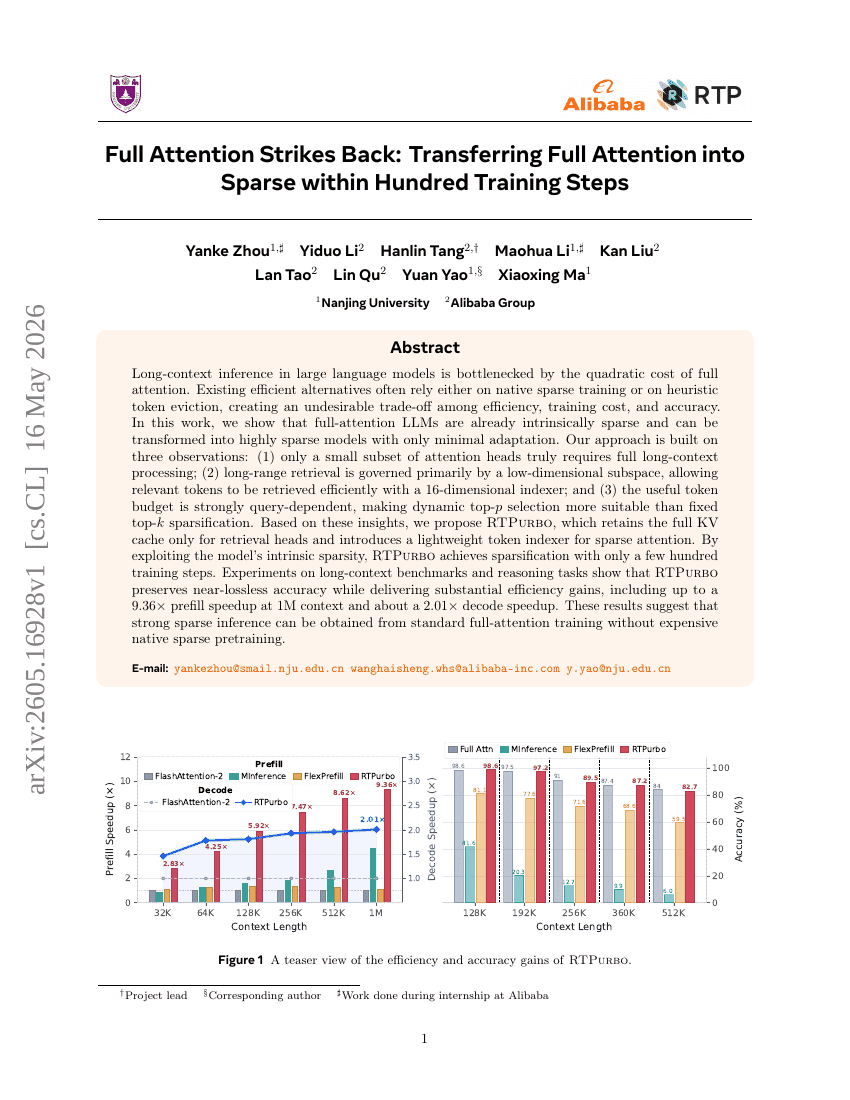
全注意力卷土重来:在百步训练内将全注意力转移至稀疏



















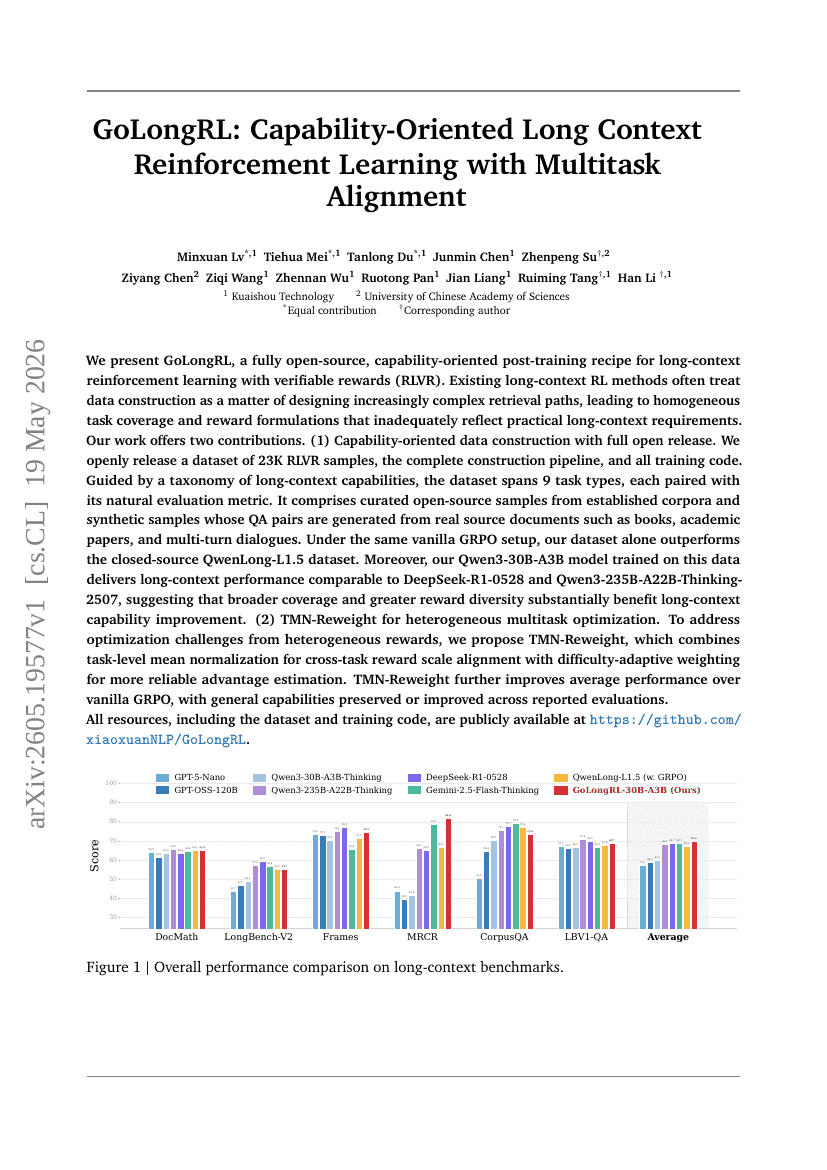







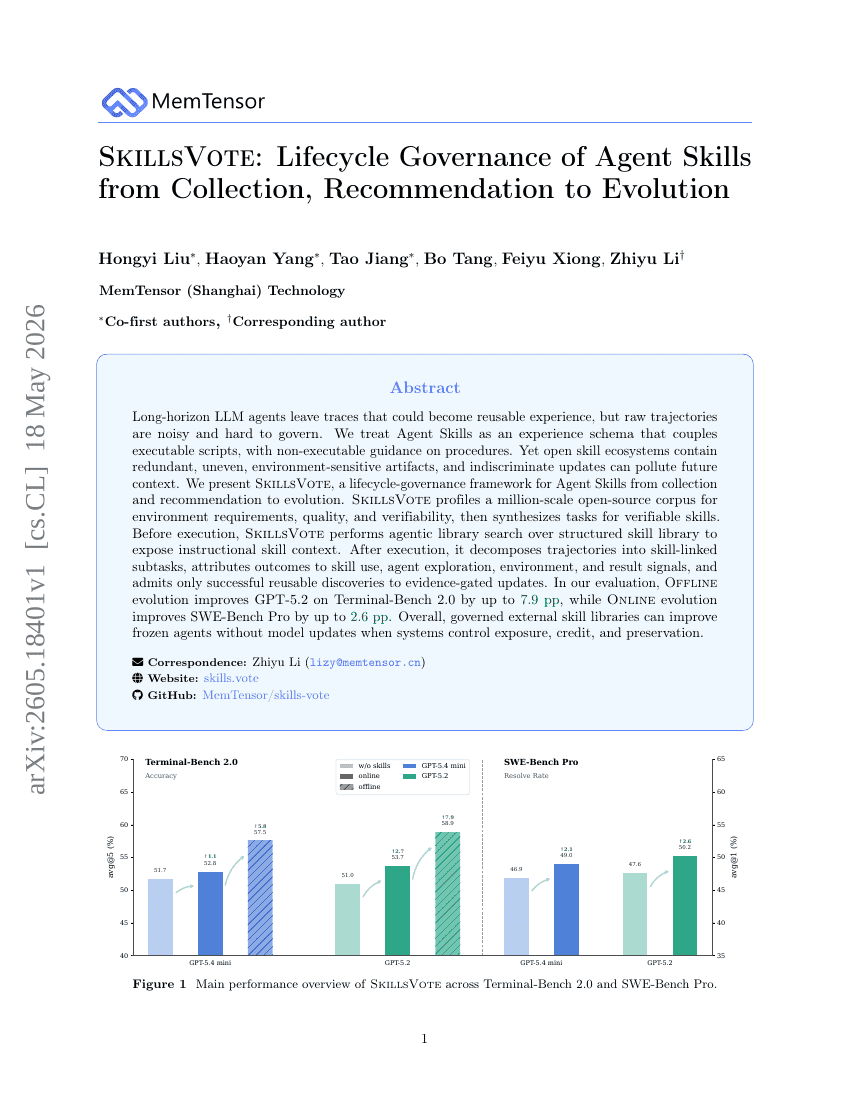

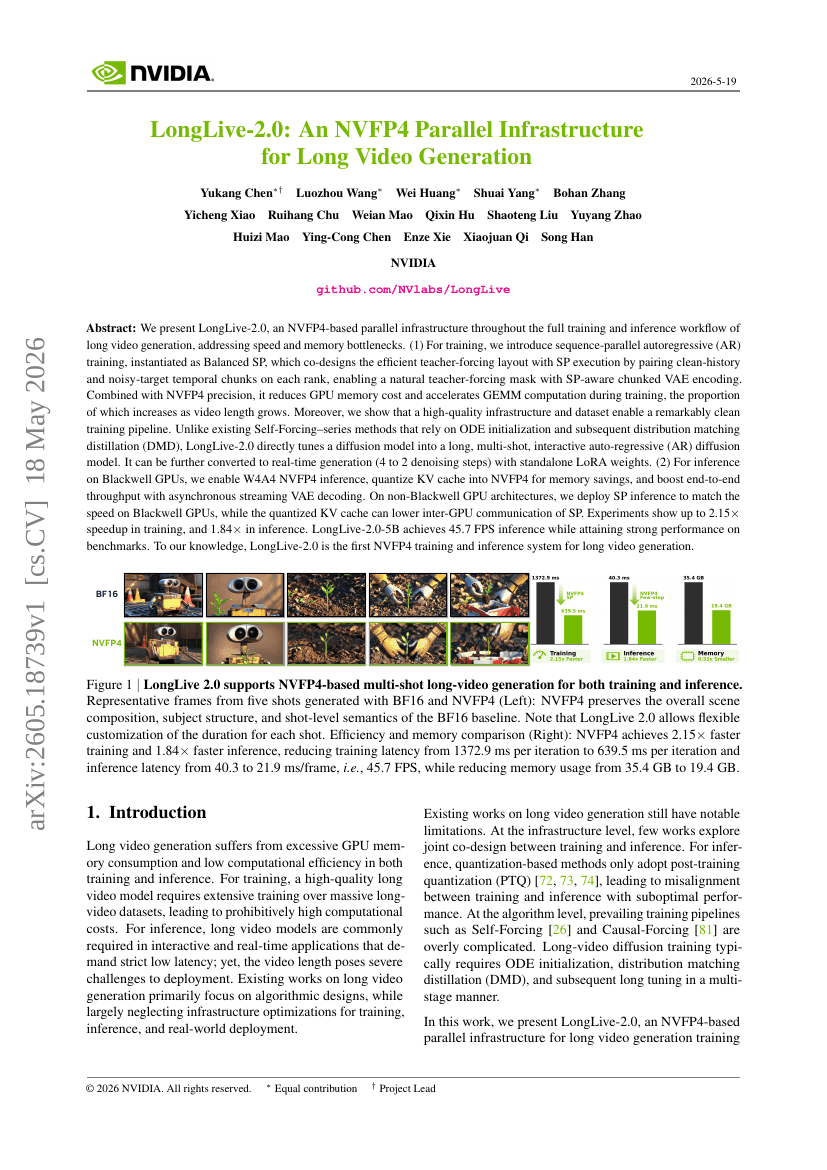
ACC:编译 Agent 轨迹以进行长上下文训练
全注意力卷土重来:在百步训练内将全注意力转移至稀疏
π-Bench:在长周期工作流中评估主动式个人助理 Agent
感知还是偏见:多模态大语言模型能否超越对人格的初印象?
TransitLM:面向无地图 transit 路线生成的超大规模数据集与基准
DelTA:基于可验证奖励强化学习的判别性 Token 信用分配
交互评估需要一种设计科学
ESI-BENCH:迈向闭环感知-行动的具身空间智能
基于多视觉光谱无人机影像的军事目标检测对比分析
精神科诊断的自动化ICD分类:从经典NLP到大语言模型
利用社区 IBR 的剩余容量实现配电网中协调的最优电能质量管理
EllipseLIO:基于椭球表示的自适应激光雷达惯性里程计
SMoA:用于参数高效微调的频谱调制适配器
通过谱回归分析检测被植入特洛伊木马的深度神经网络
思维幻象:基于问题复杂度的视角理解推理模型的优势与局限
生成式递归推理
安全预训练:迈向下一代安全人工智能
RubricEM:超越可验证奖励的基于评分指南的策略分解元强化学习
当视觉为声音代言
AutoResearchClaw:基于人机协作的自我强化自主研究
使用学习到的可靠性进行过程奖励
GoLongRL:面向能力的多任务对齐长上下文强化学习
OpenComputer:面向 Computer-Use Agent 的可验证软件世界
基于点互信息的推理强化学习中的反自蒸馏
通过对比对搜索实现靶向神经元调控
连续扩散模型在语言任务中与离散扩散模型具有相当的竞争力
KVPO:基于KV语义探索的自回归视频对齐的ODE原生GRPO
代码即房间:通过 Agent 代码合成从俯视图图像生成 3D 房间
用于自动研究的 AI:路线图与用户指南
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理
Lance:通过多任务协同实现统一的多模态建模
LongLive-2.0:用于长视频生成的NVFP4并行基础设施
π-Bench:在长周期工作流中评估主动式个人助理 Agent
感知还是偏见:多模态大语言模型能否超越对人格的初印象?
TransitLM:面向无地图 transit 路线生成的超大规模数据集与基准
DelTA:基于可验证奖励强化学习的判别性 Token 信用分配
交互评估需要一种设计科学
ESI-BENCH:迈向闭环感知-行动的具身空间智能
基于多视觉光谱无人机影像的军事目标检测对比分析
精神科诊断的自动化ICD分类:从经典NLP到大语言模型
利用社区 IBR 的剩余容量实现配电网中协调的最优电能质量管理
EllipseLIO:基于椭球表示的自适应激光雷达惯性里程计
SMoA:用于参数高效微调的频谱调制适配器
通过谱回归分析检测被植入特洛伊木马的深度神经网络
思维幻象:基于问题复杂度的视角理解推理模型的优势与局限
生成式递归推理
安全预训练:迈向下一代安全人工智能
RubricEM:超越可验证奖励的基于评分指南的策略分解元强化学习
当视觉为声音代言
AutoResearchClaw:基于人机协作的自我强化自主研究
使用学习到的可靠性进行过程奖励
GoLongRL:面向能力的多任务对齐长上下文强化学习
OpenComputer:面向 Computer-Use Agent 的可验证软件世界
基于点互信息的推理强化学习中的反自蒸馏
通过对比对搜索实现靶向神经元调控
连续扩散模型在语言任务中与离散扩散模型具有相当的竞争力
KVPO:基于KV语义探索的自回归视频对齐的ODE原生GRPO
代码即房间:通过 Agent 代码合成从俯视图图像生成 3D 房间
用于自动研究的 AI:路线图与用户指南
SkillsVote:从收集、推荐到演进的 Agent 技能生命周期治理
Lance:通过多任务协同实现统一的多模态建模
LongLive-2.0:用于长视频生成的NVFP4并行基础设施