HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

DeepCrack:一种用于裂纹分割的深度层次化特征学习架构

VideoMLA:用于分钟级自回归视频扩散的低秩潜在KV缓存



























DeepCrack:一种用于裂纹分割的深度层次化特征学习架构
VideoMLA:用于分钟级自回归视频扩散的低秩潜在KV缓存
Draft-OPD:面向投机草稿模型的在线策略蒸馏
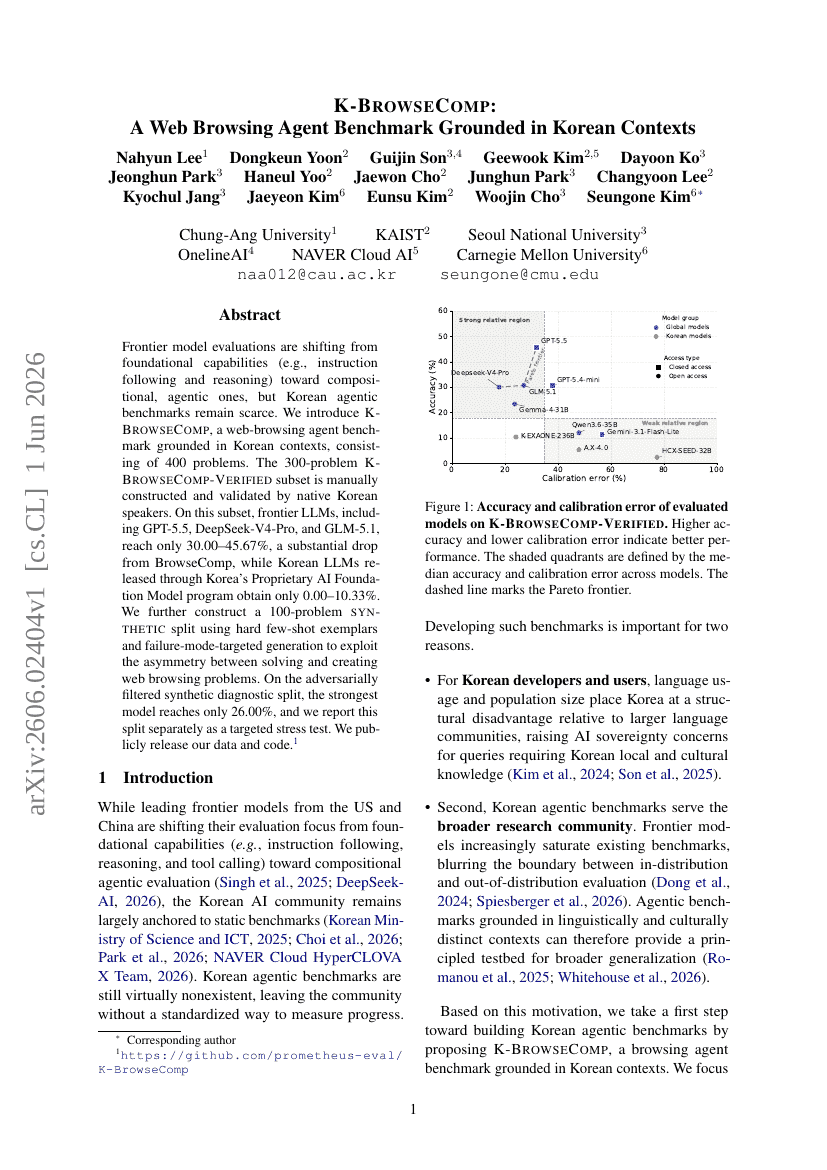
K-BrowseComp:基于韩国语境的 Web 浏览 Agent 基准测试
关键在于TASTE:提升 Agent 基准的覆盖率与难度
关于 PEFT 的扩展:迈向万亿参数的百万级个性化模型
Crafter:用于从多样化输入生成可编辑科学图表的多 Agent 框架
TACK:针对新型靶向嵌合体知识数据集(TArgeting Chimeras Knowledge)的降解活性统计评估
叙事织者:基于多模态条件控制的长程视觉一致性研究
框架更新并非框架增益:解耦自进化大语言模型智能体中的进化能力
LongTraceRL:从搜索 Agent 轨迹与评分标准奖励中学习长上下文推理
用于同策略蒸馏的信赖域行为混合
SwanVoice:面向独白与对话的富有表现力长文本零样本语音合成
面向无瓶颈统一多模态模型的表示强制
GrepSeek:用于直接语料库交互的搜索 Agents 训练
COLLEAGUE.SKILL:基于专家知识蒸馏的自动化AI技能生成
以智能体系统增强弱推理模型
YoCausal:视频生成距离世界模型还有多远?——因果视角
minWM:面向实时交互式视频世界模型的全栈开源框架
CollectionLoRA:通过多教师在线策略蒸馏在1个LoRA中收集50种效果
OmniRetrieval:跨异构知识源的统一检索
Qwen-VLA:统一任务、环境与机器人具身中的视觉-语言-动作建模
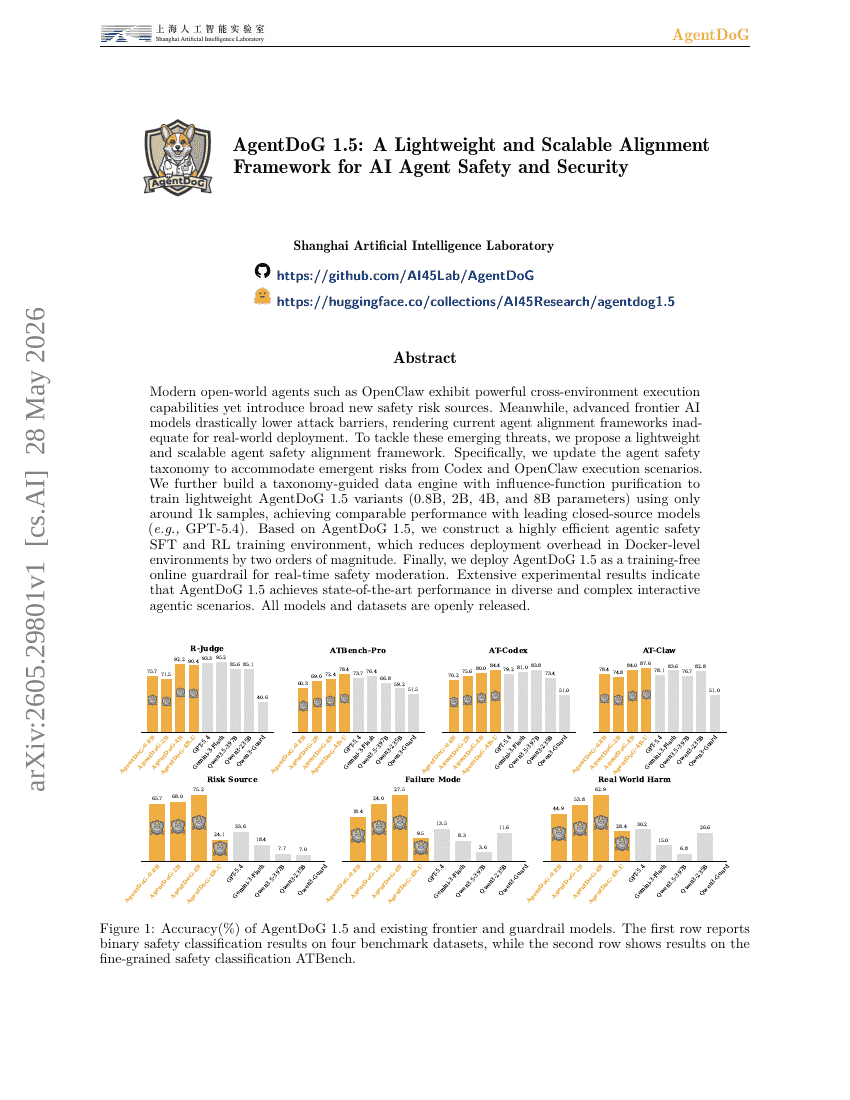
AgentDoG 1.5:一种轻量级且可扩展的面向 AI Agent 安全与防护的对齐框架
世界动作模型:具身智能的下一前沿
世界动作模型是零样本策略
ResearchMath-14K:通过 Agents 扩展研究级数学
结合双向进化搜索的自我改进语言模型
从像素到文本——迈向大规模原生统一视觉模型
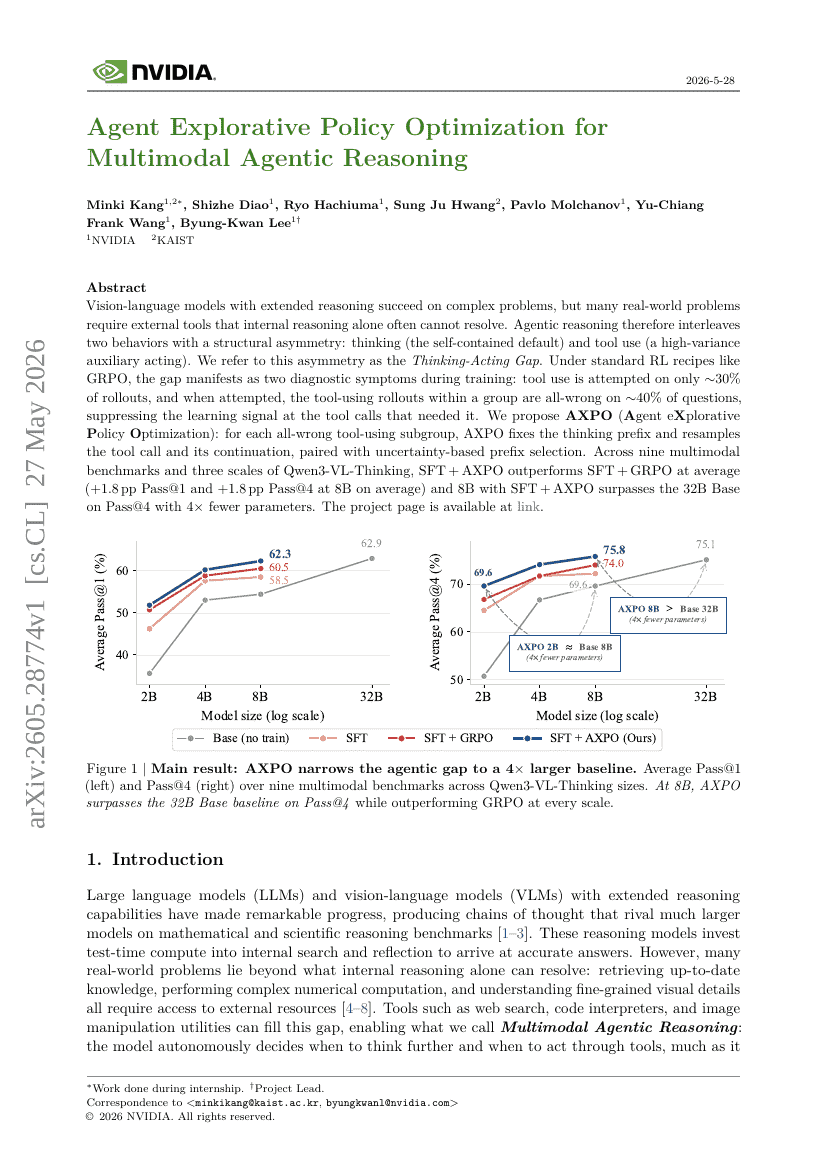
Agent探索性策略优化用于多模态Agent推理
ProRL:基于修正策略梯度估计的高效主动推荐强化学习
Gamma-World:超越双玩家的生成式多 Agent 世界建模
AutoFigure:生成与优化可供出版的科学插图
Draft-OPD:面向投机草稿模型的在线策略蒸馏
K-BrowseComp:基于韩国语境的 Web 浏览 Agent 基准测试
关键在于TASTE:提升 Agent 基准的覆盖率与难度
关于 PEFT 的扩展:迈向万亿参数的百万级个性化模型
Crafter:用于从多样化输入生成可编辑科学图表的多 Agent 框架
TACK:针对新型靶向嵌合体知识数据集(TArgeting Chimeras Knowledge)的降解活性统计评估
叙事织者:基于多模态条件控制的长程视觉一致性研究
框架更新并非框架增益:解耦自进化大语言模型智能体中的进化能力
LongTraceRL:从搜索 Agent 轨迹与评分标准奖励中学习长上下文推理
用于同策略蒸馏的信赖域行为混合
SwanVoice:面向独白与对话的富有表现力长文本零样本语音合成
面向无瓶颈统一多模态模型的表示强制
GrepSeek:用于直接语料库交互的搜索 Agents 训练
COLLEAGUE.SKILL:基于专家知识蒸馏的自动化AI技能生成
以智能体系统增强弱推理模型
YoCausal:视频生成距离世界模型还有多远?——因果视角
minWM:面向实时交互式视频世界模型的全栈开源框架
CollectionLoRA:通过多教师在线策略蒸馏在1个LoRA中收集50种效果
OmniRetrieval:跨异构知识源的统一检索
Qwen-VLA:统一任务、环境与机器人具身中的视觉-语言-动作建模
AgentDoG 1.5:一种轻量级且可扩展的面向 AI Agent 安全与防护的对齐框架
世界动作模型:具身智能的下一前沿
世界动作模型是零样本策略
ResearchMath-14K:通过 Agents 扩展研究级数学
结合双向进化搜索的自我改进语言模型
从像素到文本——迈向大规模原生统一视觉模型
Agent探索性策略优化用于多模态Agent推理
ProRL:基于修正策略梯度估计的高效主动推荐强化学习
Gamma-World:超越双玩家的生成式多 Agent 世界建模
AutoFigure:生成与优化可供出版的科学插图