HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

GameCraft-Bench:Agents能否在真实游戏引擎中端到端地构建可玩的游戏?
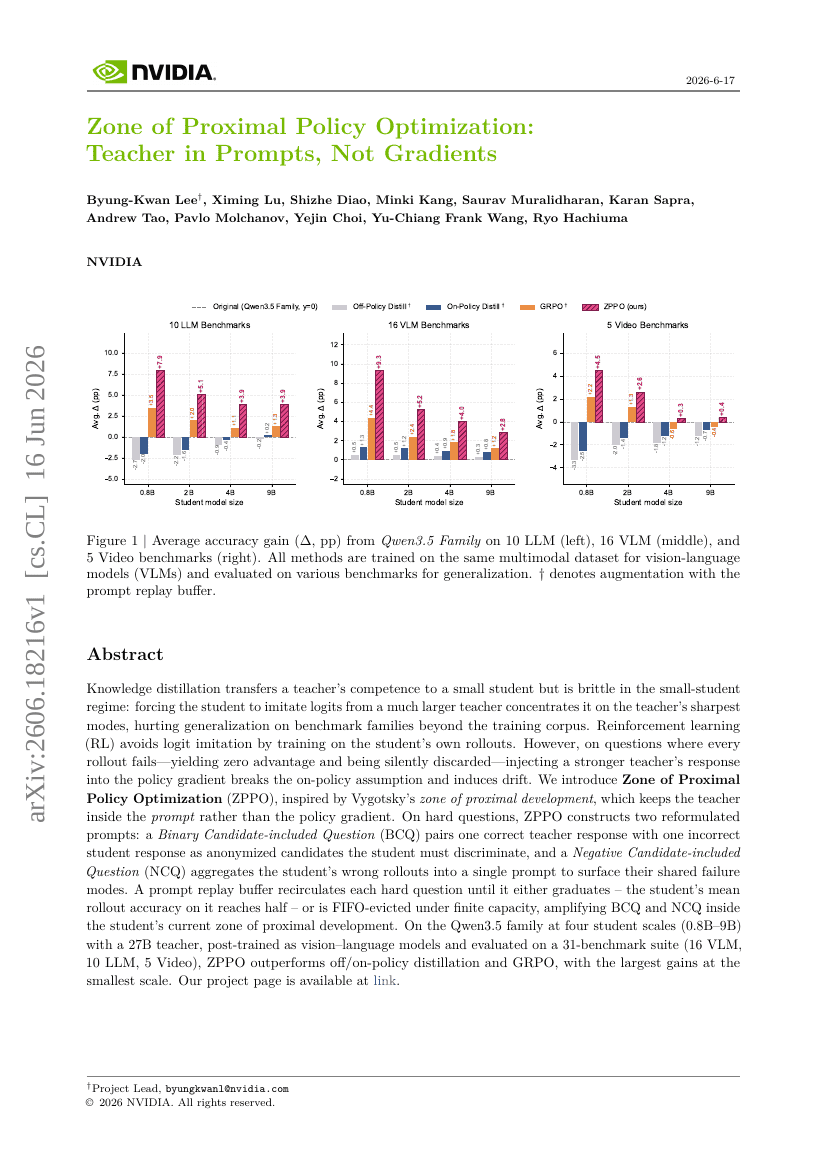
近端策略优化的最近发展区:提示中的教师,而非梯度
























GameCraft-Bench:Agents能否在真实游戏引擎中端到端地构建可玩的游戏?
近端策略优化的最近发展区:提示中的教师,而非梯度
ACE-Ego-0:统一第一人称视角的人类与机器人数据用于VLA预训练
LoopCoder-v2:仅循环一次以实现高效的测试时计算扩展
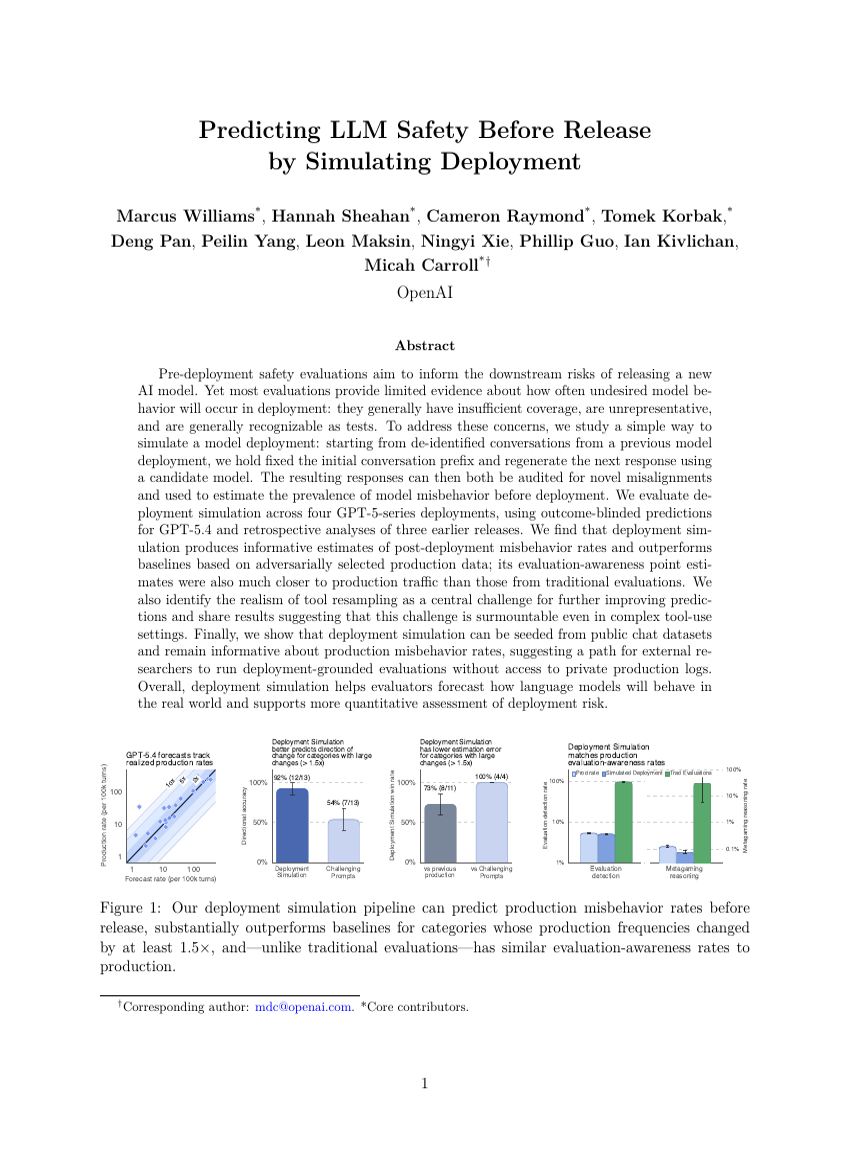
通过模拟部署预测大语言模型发布前的安全性
FastContext:训练面向 Coding Agents 的高效仓库探索器
VibeThinker-3B:探索小型语言模型中可验证推理的前沿
DreamX-World 1.0:一种通用的交互式世界模型
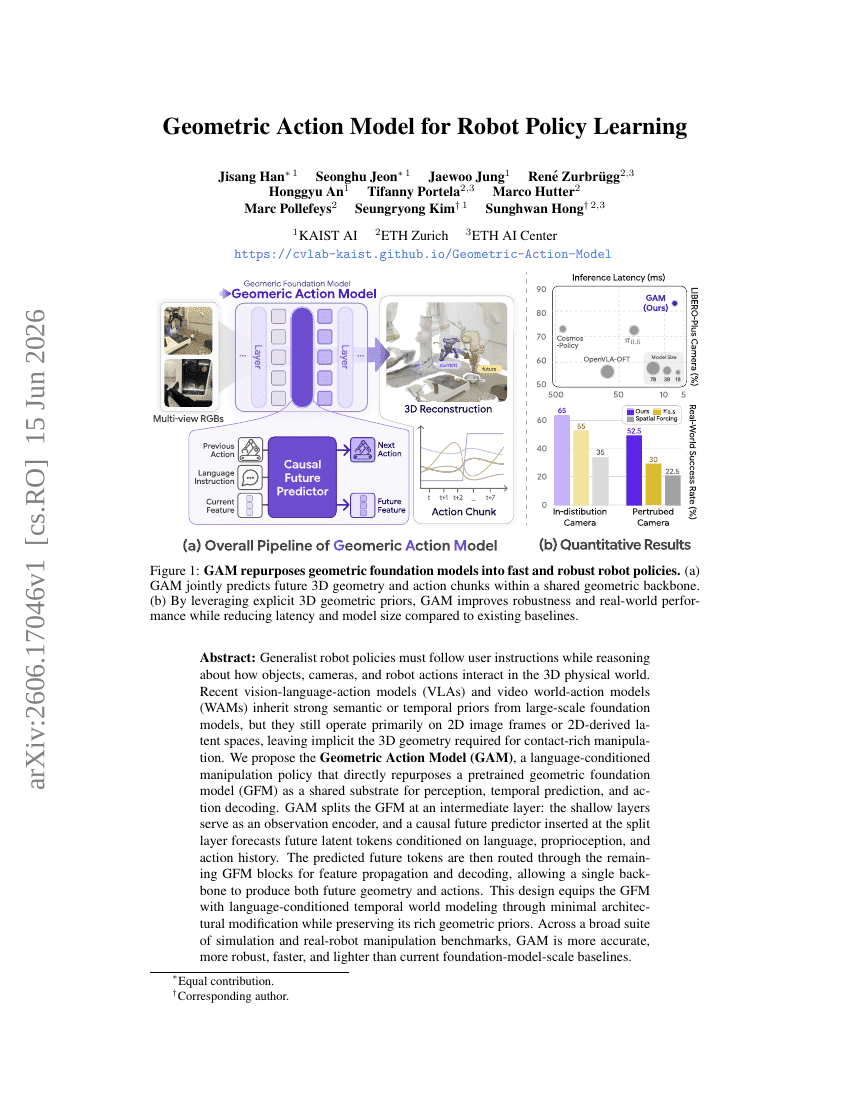
用于机器人策略学习的几何动作模型
数据记者 Agent:将数据转化为可验证的多模态故事
JoyAI-VL-Interaction:实时视觉-语言交互智能
dots.tts 技术报告
基于生成先验的确定性视频深度估计
基于展开式 Plug-and-Play ADMM 的弱引力透镜星系图像解卷积
AI必须通过超人类自适应智能拥抱专业化
奉承型聊天机器人会导致妄想性螺旋,即使在理想贝叶斯主义者中也是如此
混沌代理
HarnessX:一个可组合、自适应且可演化的智能体制造工厂
Orchestra-o1:全模态 Agent 编排
从聊天机器人到数字同事:迈向持久自主人工智能的范式转变
记忆是重构的,而非检索的:面向 LLM Agents 的图记忆
APPO:智能体过程策略优化
OmniDirector:无需跨配对数据的一般性多样本摄像机克隆
InterleaveThinker:强化代理式交错生成
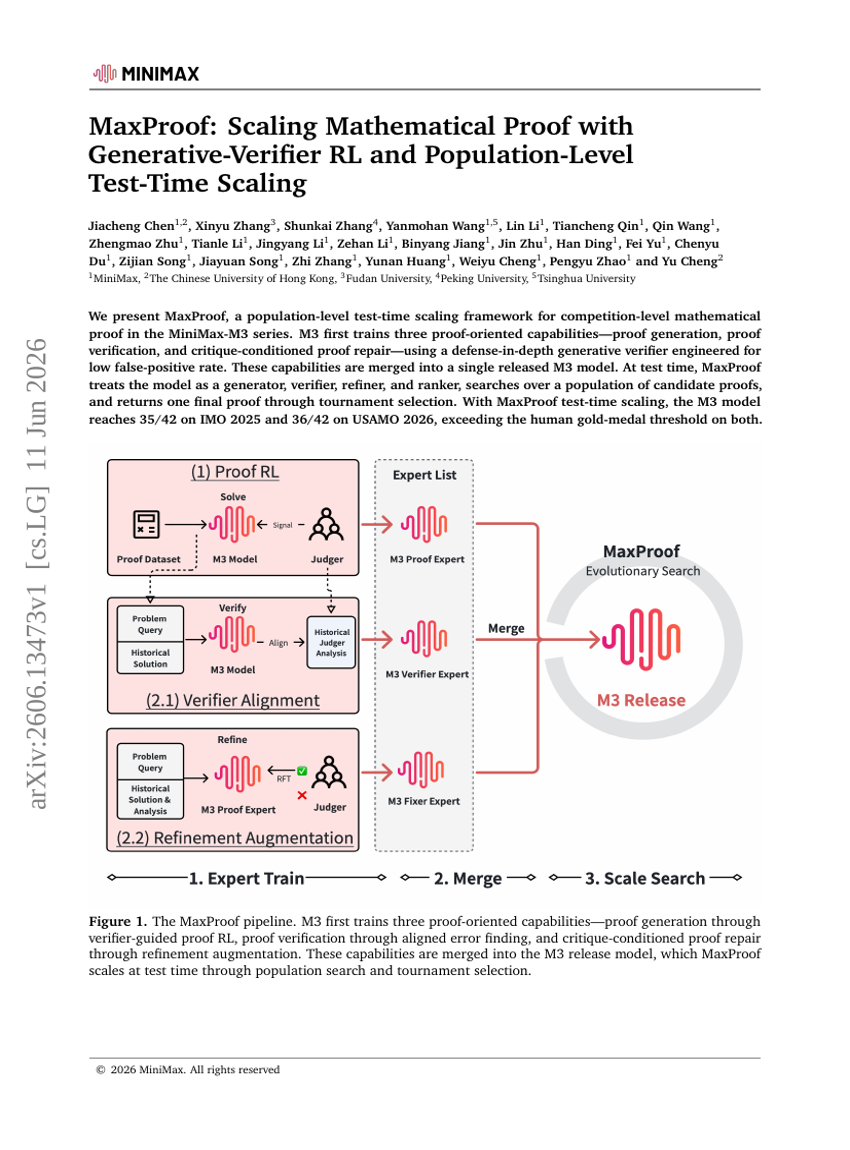
MaxProof:基于生成式-验证式强化学习与群体级测试时扩展的数学证明扩展方法
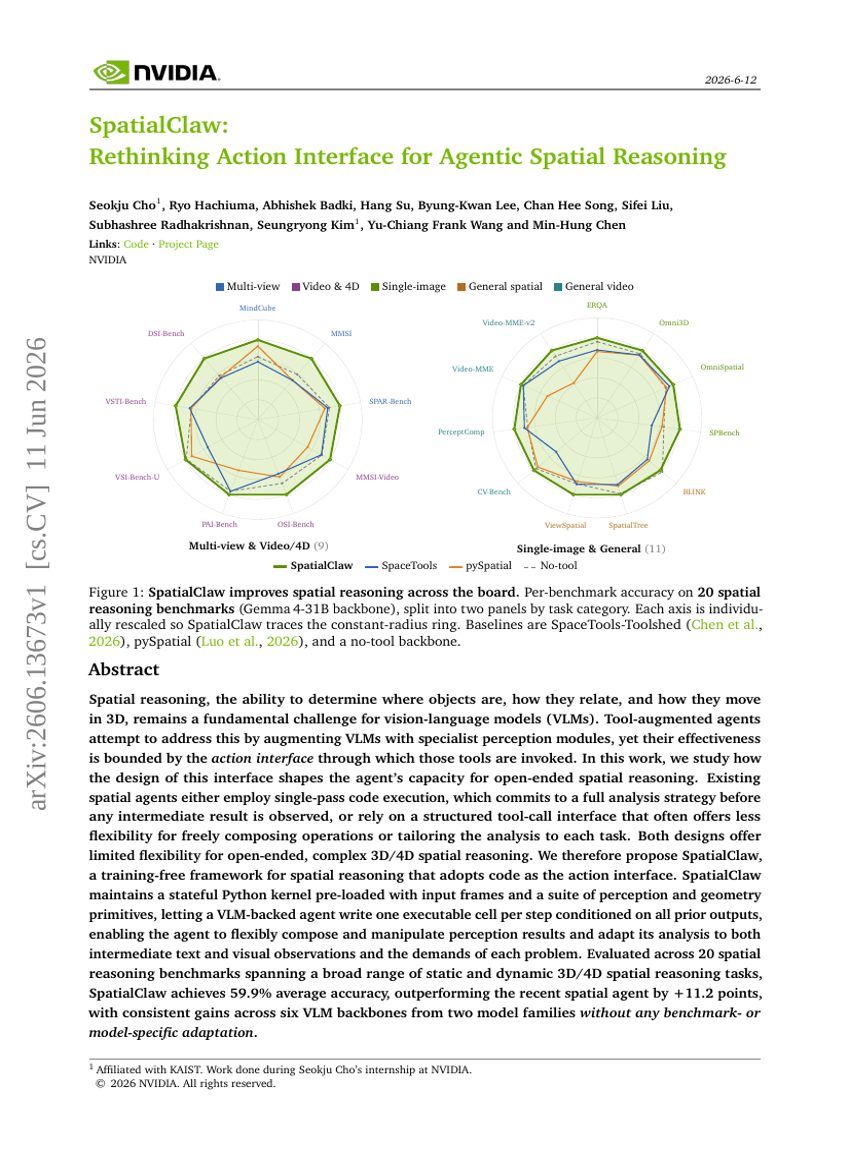
SpatialClaw:重新思考智能体空间推理的动作接口
WEAVEBENCH:面向混合界面计算机操作 Agent 的长程真实世界基准测试
MiniMax 稀疏注意力
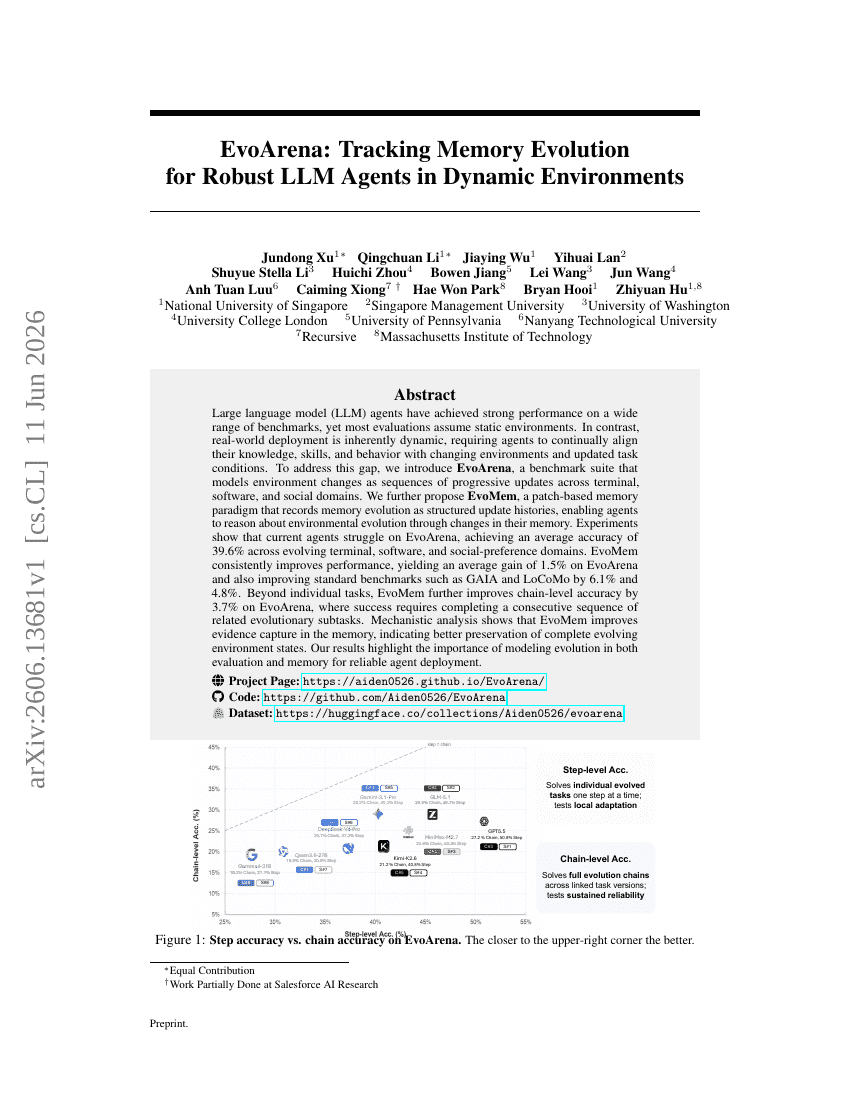
EvoArena:追踪动态环境中鲁棒 LLM Agents 的记忆演化
Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型
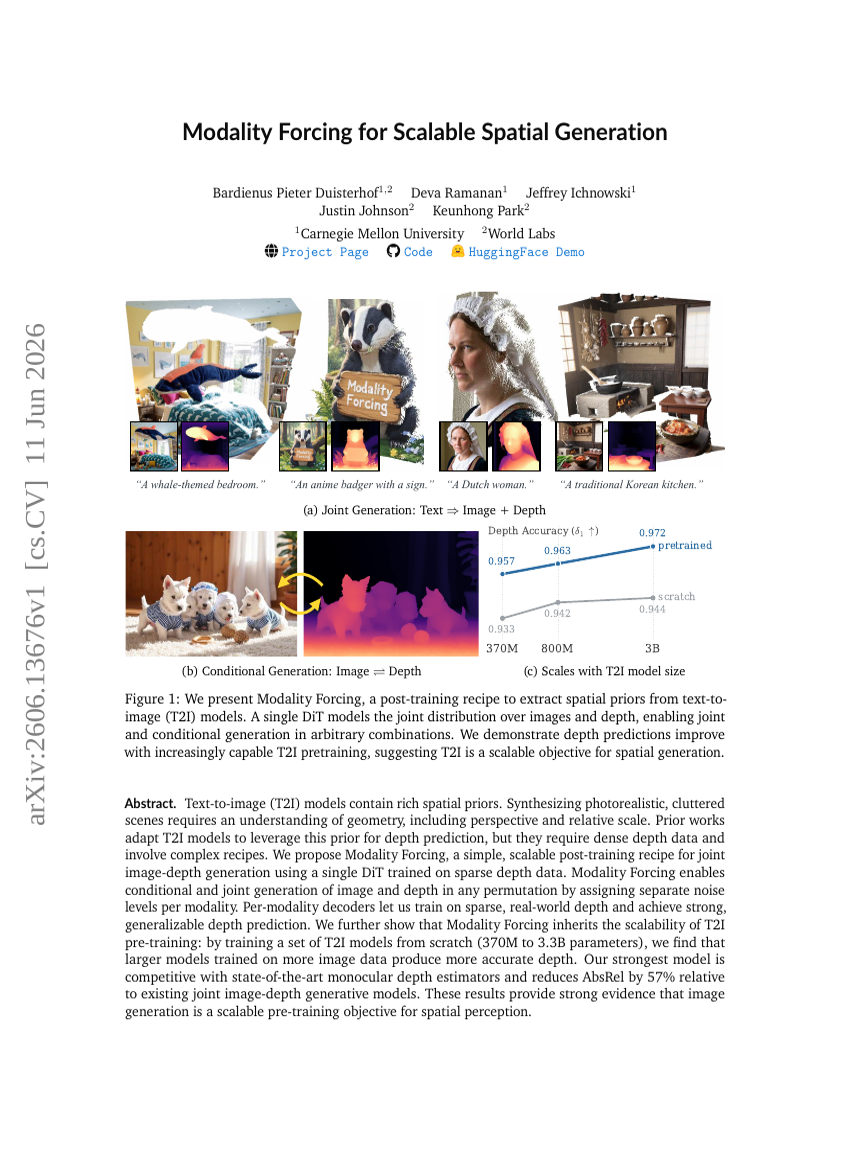
模态强制用于可扩展的空间生成
从AGI到ASI
ACE-Ego-0:统一第一人称视角的人类与机器人数据用于VLA预训练
LoopCoder-v2:仅循环一次以实现高效的测试时计算扩展
通过模拟部署预测大语言模型发布前的安全性
FastContext:训练面向 Coding Agents 的高效仓库探索器
VibeThinker-3B:探索小型语言模型中可验证推理的前沿
DreamX-World 1.0:一种通用的交互式世界模型
用于机器人策略学习的几何动作模型
数据记者 Agent:将数据转化为可验证的多模态故事
JoyAI-VL-Interaction:实时视觉-语言交互智能
dots.tts 技术报告
基于生成先验的确定性视频深度估计
基于展开式 Plug-and-Play ADMM 的弱引力透镜星系图像解卷积
AI必须通过超人类自适应智能拥抱专业化
奉承型聊天机器人会导致妄想性螺旋,即使在理想贝叶斯主义者中也是如此
混沌代理
HarnessX:一个可组合、自适应且可演化的智能体制造工厂
Orchestra-o1:全模态 Agent 编排
从聊天机器人到数字同事:迈向持久自主人工智能的范式转变
记忆是重构的,而非检索的:面向 LLM Agents 的图记忆
APPO:智能体过程策略优化
OmniDirector:无需跨配对数据的一般性多样本摄像机克隆
InterleaveThinker:强化代理式交错生成
MaxProof:基于生成式-验证式强化学习与群体级测试时扩展的数学证明扩展方法
SpatialClaw:重新思考智能体空间推理的动作接口
WEAVEBENCH:面向混合界面计算机操作 Agent 的长程真实世界基准测试
MiniMax 稀疏注意力
EvoArena:追踪动态环境中鲁棒 LLM Agents 的记忆演化
Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型
模态强制用于可扩展的空间生成
从AGI到ASI