HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

自主实验室协调器的最优资源利用

TERA:一个基于统一泰勒模型的可达性分析框架


























自主实验室协调器的最优资源利用
TERA:一个基于统一泰勒模型的可达性分析框架
感知以推理:解耦感知与推理实现细粒度视觉推理
基于Trie的级联IR管道高效实验计划
LLM训练中学习率缩放的非线性研究
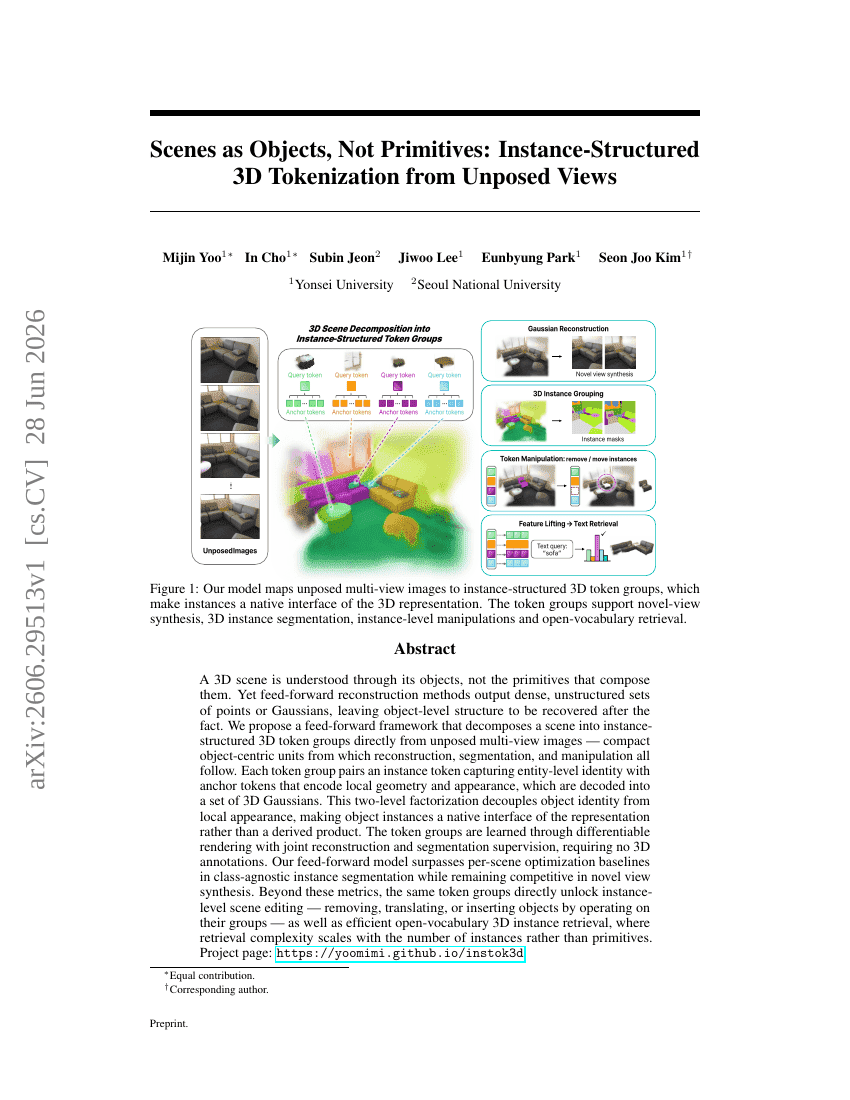
场景即物体,而非基元:从无位姿视角实现实例结构化的三维分词
BlockPilot:面向扩散推测解码的实例自适应策略学习
DOPD:双重在线策略蒸馏
Dockerless:面向编程智能体的免环境程序验证器
Orca:世界在你心中
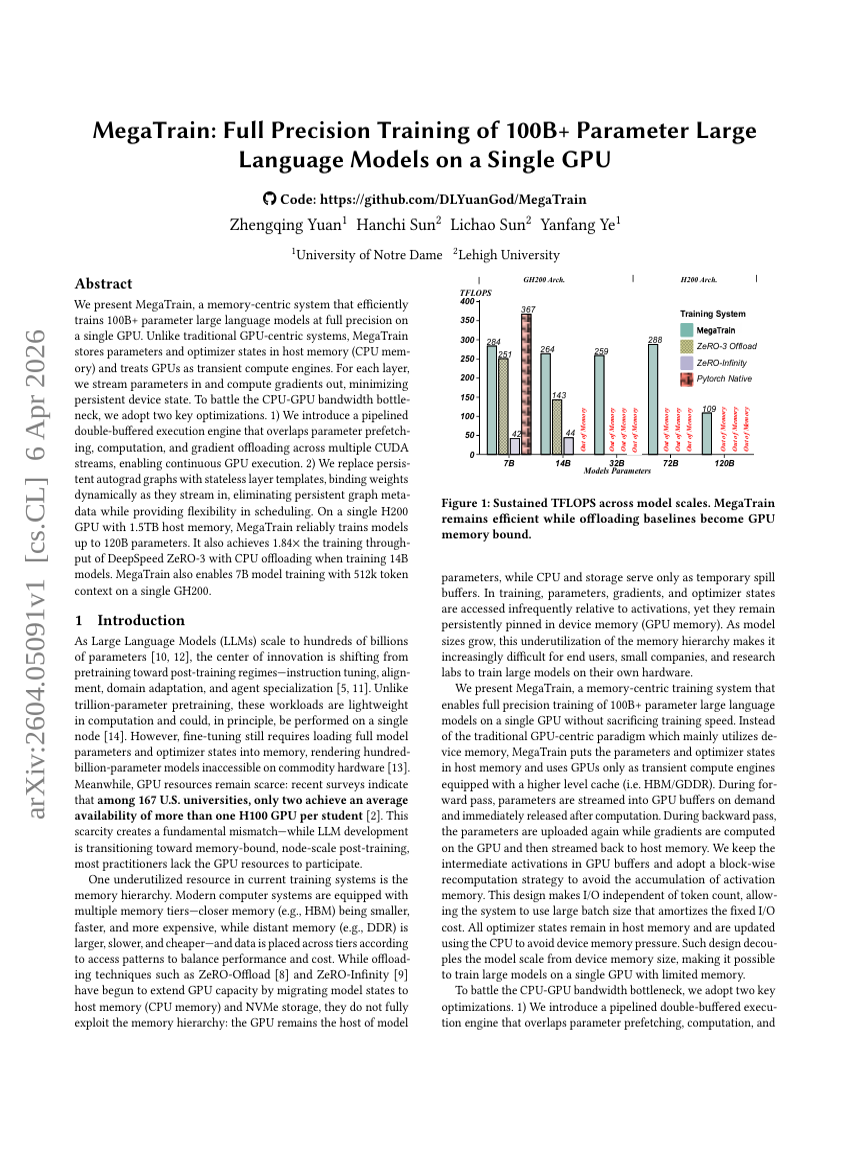
MegaTrain:在单GPU上以全精度训练千亿参数级大语言模型
寻找思考的时间:实时强化学习中的规划预算学习
接近最优的学习率调度形状是什么样的?
超越独立同分布:表格基础模型究竟有多通用?
ReFreeKV:迈向无阈值KV缓存压缩
TUA-Bench:面向通用终端使用智能体的基准测试
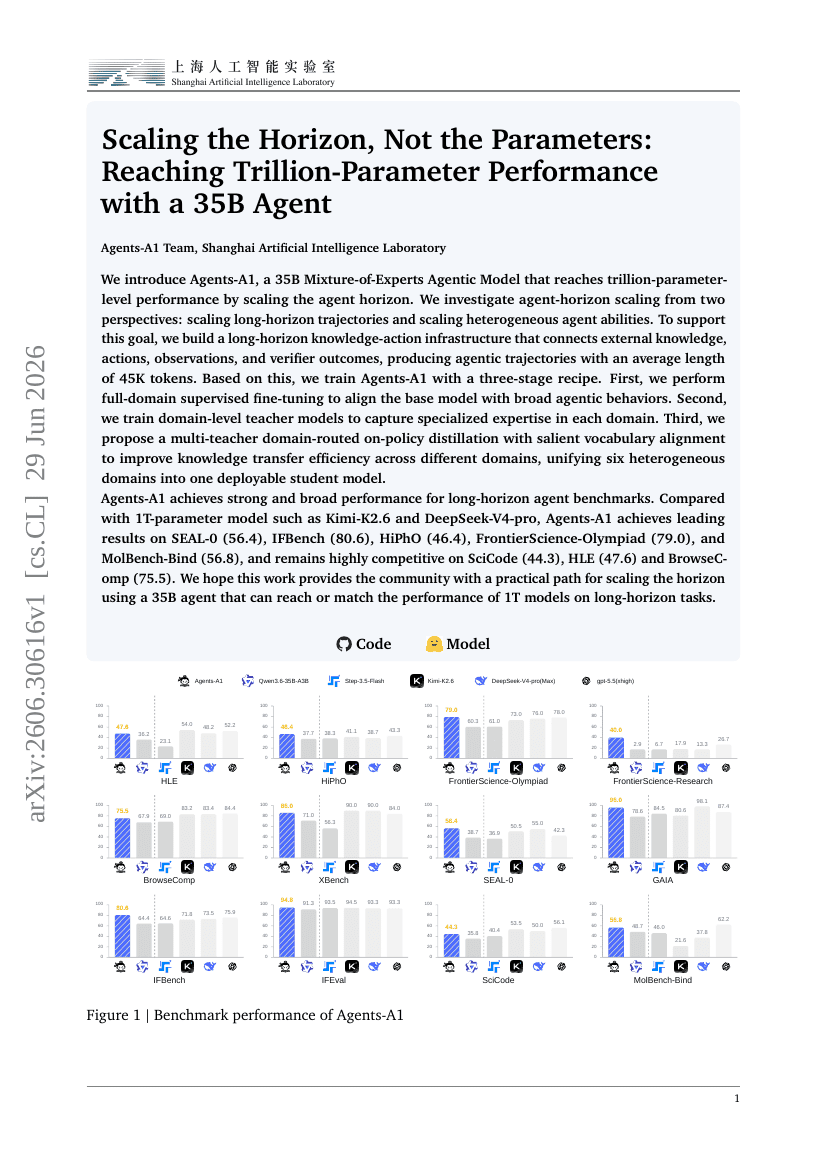
扩展智能体视野而非参数规模:用35B智能体实现万亿参数级性能
LiveEdit:迈向实时扩散式流媒体视频编辑
智能体弃权:智能体知道何时停止而非行动吗?
EVA-Bench:评估语音智能体的全新端到端框架
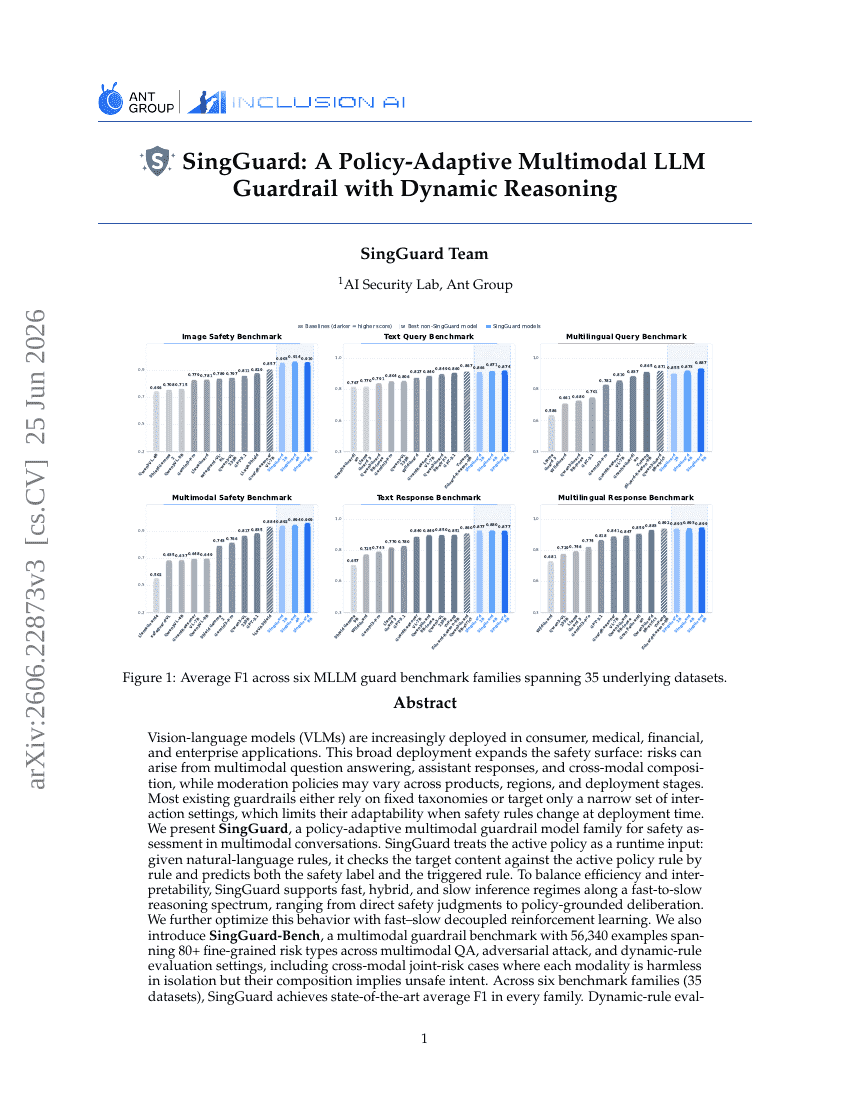
SingGuard:一个策略自适应的多模态大语言模型护栏,具备动态推理能力
形式化潜在思维:大语言模型中思维表征的四项公理
MultiHashFormer:基于哈希的生成式语言模型
Qwen-Image-2.0-RL 技术报告
翻译作为桥梁动作:将人类操作技能迁移至机器人
PhysisForcing: 用于机器人操作的物理增强世界模拟器
OpenTME:来自 TCGA 的 AI 驱动 H&E 肿瘤微环境谱系的开源数据集
FlashAttention-4:面向非对称硬件扩展的算法与内核流水协同设计
DSpark:基于置信度调度与半自回归生成的推测解码
ViQ:任意分辨率下的文本对齐视觉量化表征
验证视界:编程 Agent 奖励没有银弹
Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距
感知以推理:解耦感知与推理实现细粒度视觉推理
基于Trie的级联IR管道高效实验计划
LLM训练中学习率缩放的非线性研究
场景即物体,而非基元:从无位姿视角实现实例结构化的三维分词
BlockPilot:面向扩散推测解码的实例自适应策略学习
DOPD:双重在线策略蒸馏
Dockerless:面向编程智能体的免环境程序验证器
Orca:世界在你心中
MegaTrain:在单GPU上以全精度训练千亿参数级大语言模型
寻找思考的时间:实时强化学习中的规划预算学习
接近最优的学习率调度形状是什么样的?
超越独立同分布:表格基础模型究竟有多通用?
ReFreeKV:迈向无阈值KV缓存压缩
TUA-Bench:面向通用终端使用智能体的基准测试
扩展智能体视野而非参数规模:用35B智能体实现万亿参数级性能
LiveEdit:迈向实时扩散式流媒体视频编辑
智能体弃权:智能体知道何时停止而非行动吗?
EVA-Bench:评估语音智能体的全新端到端框架
SingGuard:一个策略自适应的多模态大语言模型护栏,具备动态推理能力
形式化潜在思维:大语言模型中思维表征的四项公理
MultiHashFormer:基于哈希的生成式语言模型
Qwen-Image-2.0-RL 技术报告
翻译作为桥梁动作:将人类操作技能迁移至机器人
PhysisForcing: 用于机器人操作的物理增强世界模拟器
OpenTME:来自 TCGA 的 AI 驱动 H&E 肿瘤微环境谱系的开源数据集
FlashAttention-4:面向非对称硬件扩展的算法与内核流水协同设计
DSpark:基于置信度调度与半自回归生成的推测解码
ViQ:任意分辨率下的文本对齐视觉量化表征
验证视界:编程 Agent 奖励没有银弹
Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距