HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

基于分解视觉代理的直接3D感知物体插入

AnchorWorld:基于视角演化定制的具身自我中心世界仿真





























基于分解视觉代理的直接3D感知物体插入
AnchorWorld:基于视角演化定制的具身自我中心世界仿真
SoCRATES:迈向跨领域与社会认知差异的大语言模型主动调解的可靠自动化评估
MMAE:一个大规模多任务音频编辑基准
你的未嵌入矩阵实际上是文本嵌入的特征透镜
ChordEdit:一种面向图像编辑的单步低能耗传输方法
NitroGen:一个面向通用游戏智能体的开源基础模型
高效地以每次一个 D4RT 的方式重建动态场景
Continual Learning Bench: 评估前沿 AI 系统在真实世界有状态环境中的表现
记忆缓存:具有增长式记忆能力的 RNN
RobotValues:当人类价值观冲突时评估家用机器人
VideoKR:迈向知识与推理密集型的视频理解
AdaPlanBench:评估世界与用户约束下大语言模型 Agent 的自适应规划
TIDE:基于模板引导迭代的主动多问题发现
ArcANE:角色扮演语言 Agent 是否在正确的时间保持角色?
Code2LoRA:软件演化下代码语言模型的超网络生成适配器
自蒸馏策略梯度
GSM-Symbolic:理解大语言模型在数学推理中的局限性
MUSE-Autoskill:通过技能创建、记忆、管理与评估实现自我进化的智能体
Nemotron 3 Ultra:用于智能体推理的开放、高效混合专家混合 Mamba-Transformer 模型
Qwen-Image-Flash:超越目标设计
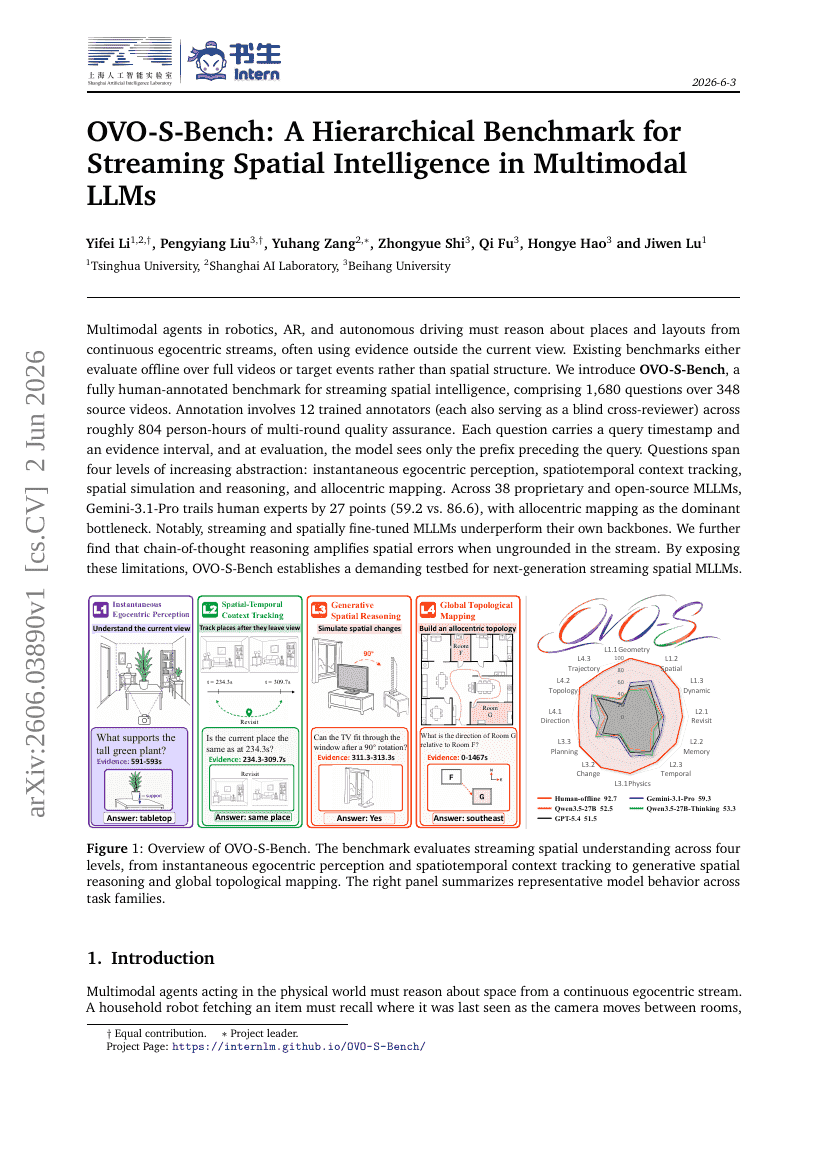
OVO-S-Bench:面向多模态大语言模型流式空间智能的分层基准
复现、分析与检测基于评分标准的强化学习中的奖励黑客攻击
深度研究 Agents 在哪里出错?Agent 轨迹中的跨度级错误定位
音频交互模型
Cosmos 3:面向物理AI的全模态世界模型
学习与快慢思维:迈向具备持续适应能力的 LLM
LEAP:利用智能体框架为大型语言模型在形式化数学领域的赋能增效
世界模型遇见语言模型:论具体与抽象推理的互补性
从激活到因果:人类大脑中因果视觉表征的发现
一种用于多域强化学习中跨域干扰与恢复的局部扰动理论
人形-GPT:用于零样本运动跟踪的数据与结构扩展
SoCRATES:迈向跨领域与社会认知差异的大语言模型主动调解的可靠自动化评估
MMAE:一个大规模多任务音频编辑基准
你的未嵌入矩阵实际上是文本嵌入的特征透镜
ChordEdit:一种面向图像编辑的单步低能耗传输方法
NitroGen:一个面向通用游戏智能体的开源基础模型
高效地以每次一个 D4RT 的方式重建动态场景
Continual Learning Bench: 评估前沿 AI 系统在真实世界有状态环境中的表现
记忆缓存:具有增长式记忆能力的 RNN
RobotValues:当人类价值观冲突时评估家用机器人
VideoKR:迈向知识与推理密集型的视频理解
AdaPlanBench:评估世界与用户约束下大语言模型 Agent 的自适应规划
TIDE:基于模板引导迭代的主动多问题发现
ArcANE:角色扮演语言 Agent 是否在正确的时间保持角色?
Code2LoRA:软件演化下代码语言模型的超网络生成适配器
自蒸馏策略梯度
GSM-Symbolic:理解大语言模型在数学推理中的局限性
MUSE-Autoskill:通过技能创建、记忆、管理与评估实现自我进化的智能体
Nemotron 3 Ultra:用于智能体推理的开放、高效混合专家混合 Mamba-Transformer 模型
Qwen-Image-Flash:超越目标设计
OVO-S-Bench:面向多模态大语言模型流式空间智能的分层基准
复现、分析与检测基于评分标准的强化学习中的奖励黑客攻击
深度研究 Agents 在哪里出错?Agent 轨迹中的跨度级错误定位
音频交互模型
Cosmos 3:面向物理AI的全模态世界模型
学习与快慢思维:迈向具备持续适应能力的 LLM
LEAP:利用智能体框架为大型语言模型在形式化数学领域的赋能增效
世界模型遇见语言模型:论具体与抽象推理的互补性
从激活到因果:人类大脑中因果视觉表征的发现
一种用于多域强化学习中跨域干扰与恢复的局部扰动理论
人形-GPT:用于零样本运动跟踪的数据与结构扩展