HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

多流大语言模型:通过并行思维、输入和输出流解锁大语言模型

你的语言模型是其自身的评论家:基于 Actor 内部状态的价值估计的强化学习








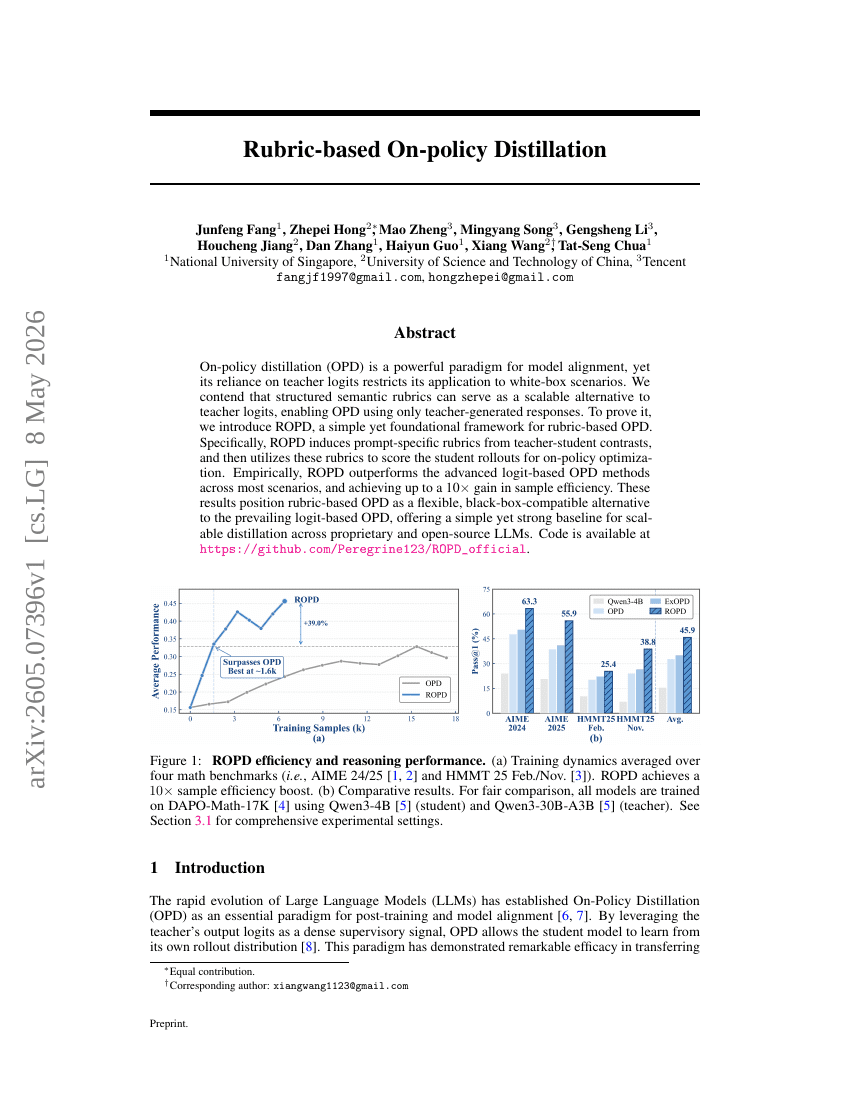
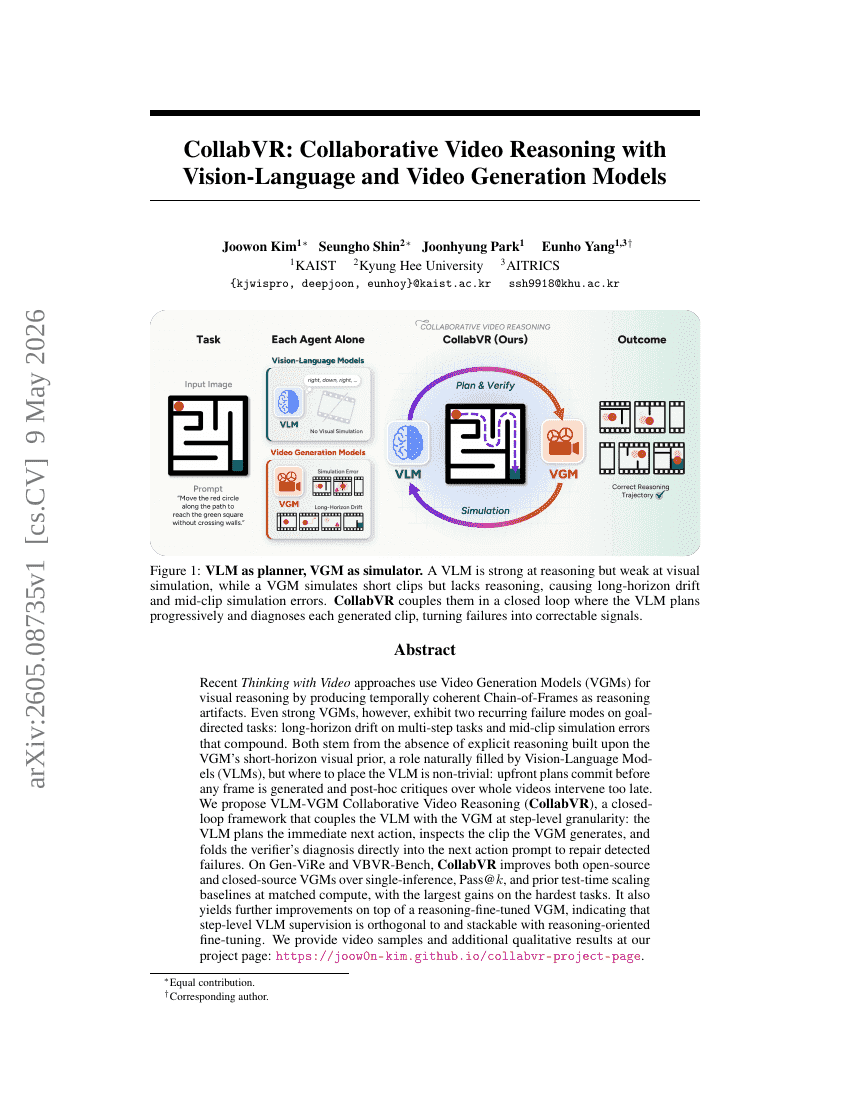


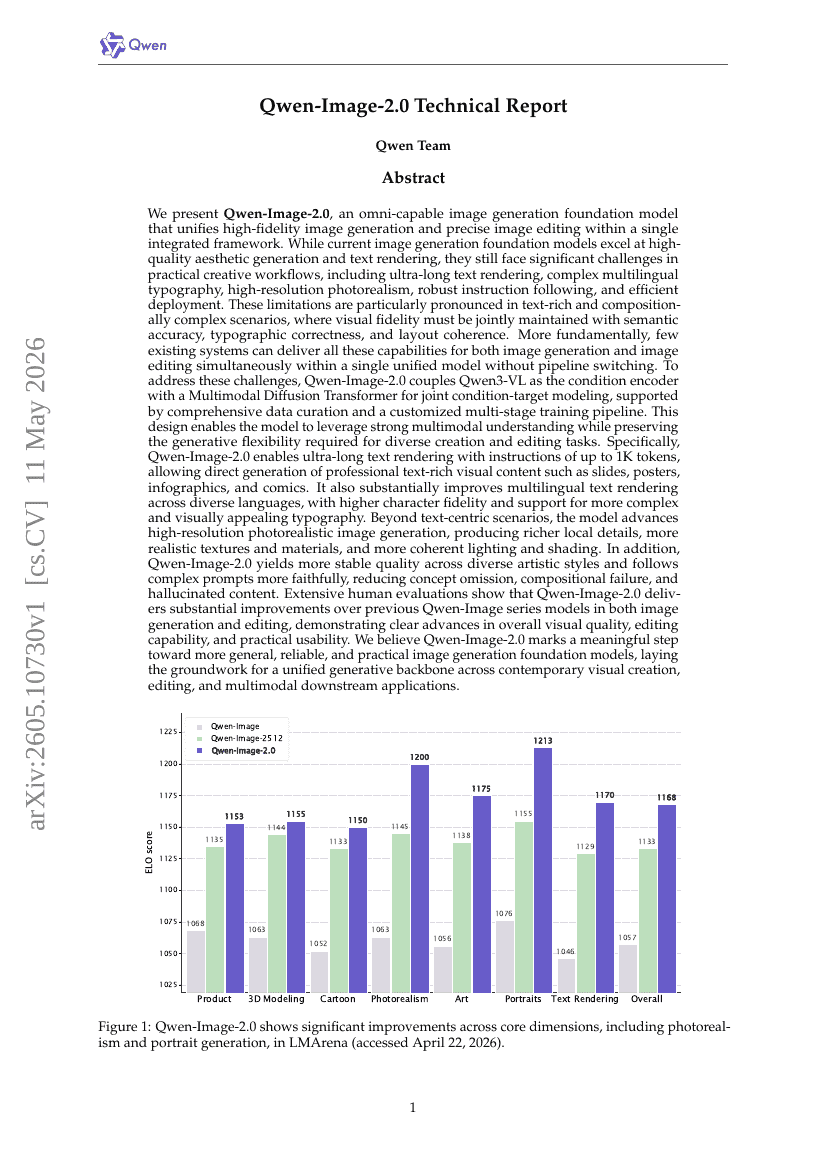
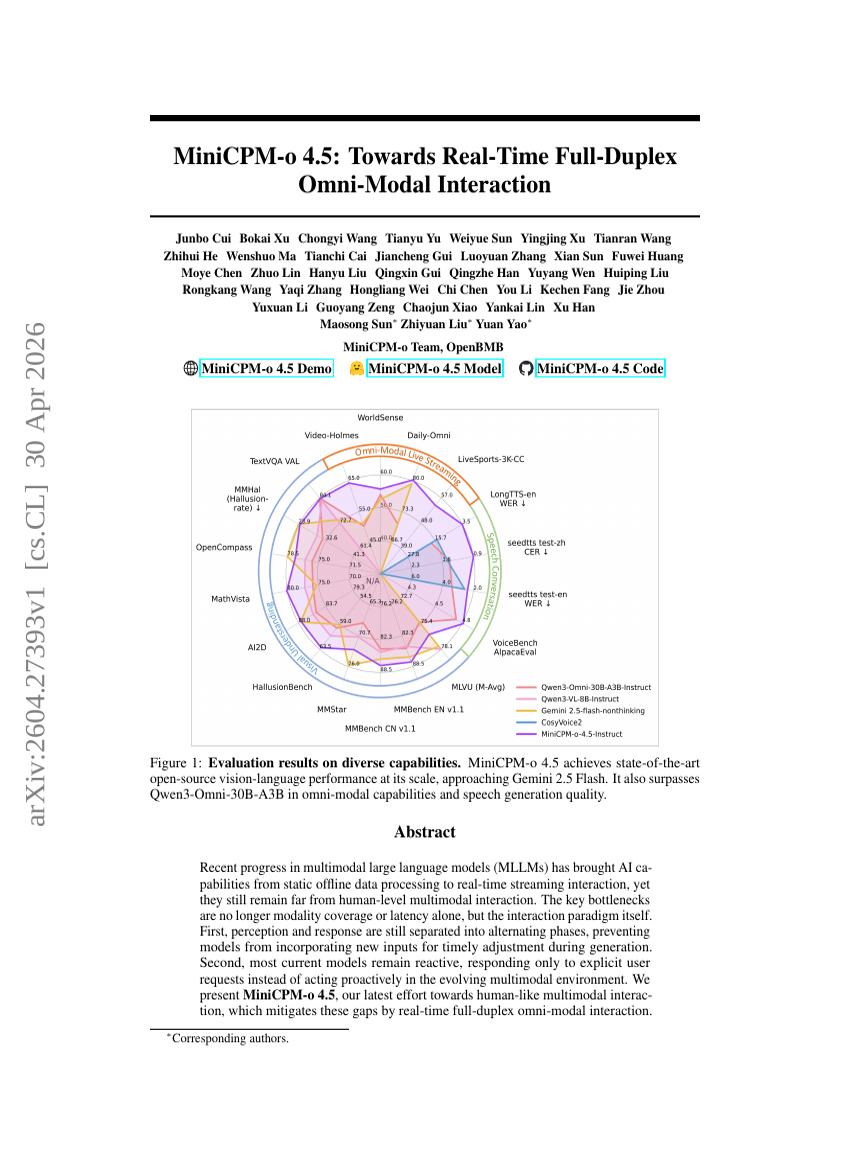















多流大语言模型:通过并行思维、输入和输出流解锁大语言模型
你的语言模型是其自身的评论家:基于 Actor 内部状态的价值估计的强化学习
Relit-LiVE:通过联合学习环境视频实现视频重光照
积极对齐:人工智能助力人类繁荣
LLaVA-UHD v4:是什么构成了多模态大语言模型中高效的视觉编码?
揭露策略内蒸馏的真相:其有益之处、有害之处及原因分析
单个神经元足以绕过大型语言模型的安全对齐
SlimQwen:探索大型混合专家(MoE)模型预训练中的剪枝与知识蒸馏
ELF:嵌入式语言流
PaperFit:面向科学文档的视域内排版优化
基于量规的在线策略蒸馏
CollabVR:基于视觉-语言与视频生成模型的协同视频推理
TMAS:通过多智能体协同扩展测试时计算
Soohak:由数学家精心策划的基准测试,用于评估大语言模型在研究级数学能力方面的表现
Qwen-Image-2.0 技术报告
MiniCPM-o 4.5:迈向实时全双模全模态交互
部署中学习:面向通用机器人策略的车队规模强化学习
快速字节隐式Transformer
AI共同数学家:利用智能体AI加速数学研究
HyperEyes:面向并行多模态搜索代理的双粒度效率感知强化学习
均值模式尖叫:1000层扩散Transformer中的均值-方差分裂残差
LLMs改进LLMs:用于测试时缩放的Agent发现
列表策略优化:基于组的RLVR作为对LLM响应单纯形的目标投影
Flow-OPD:流匹配模型上的策略蒸馏
MACE-Dance:用于音乐驱动舞蹈视频生成的运动-外观级联专家模型
重思推理密集型检索:评估与推进智能体搜索系统中的检索器
何时信任想象力:世界动作模型的自适应动作执行
采用 Judge 协调的大模型集成框架「Meno and Friends」进行高真实性多轮响应生成
MiA-Signature:近似全局激活以实现长上下文理解
连续潜扩散语言模型
技能1:基于强化学习的技能增强代理统一进化
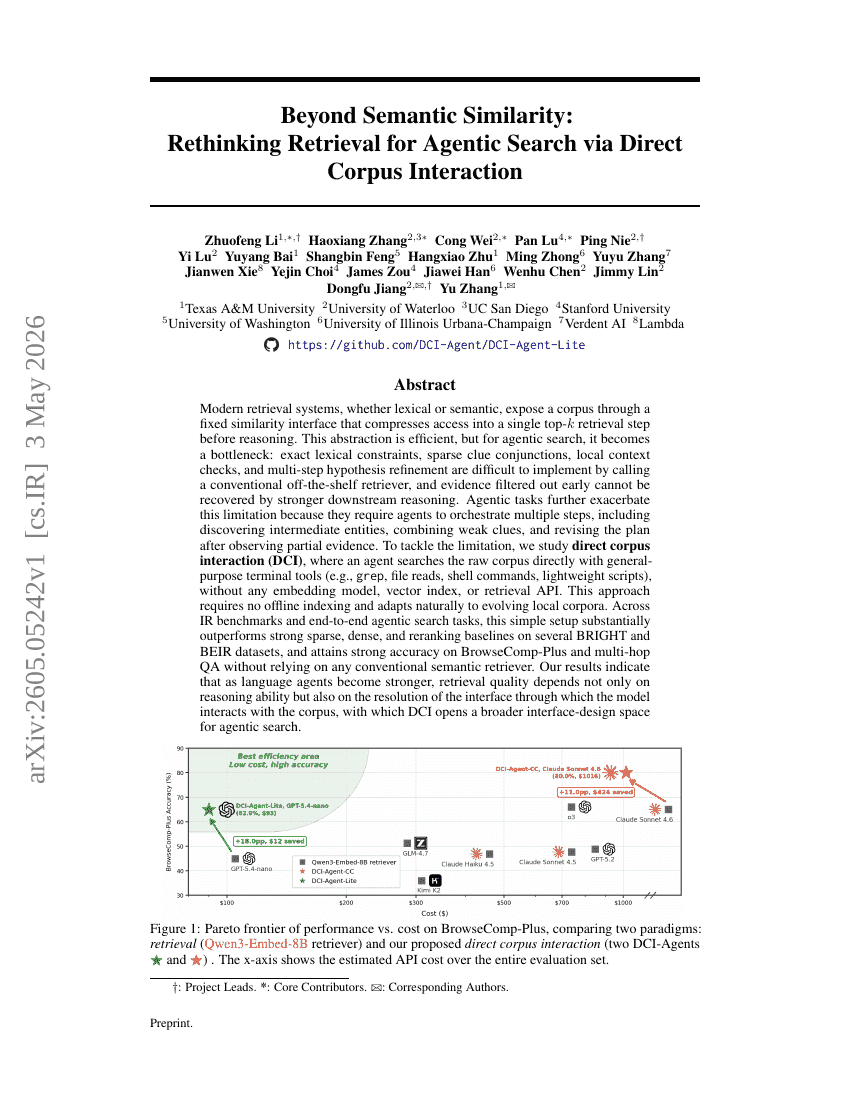
超越语义相似性:通过直接与语料库交互重新思考代理搜索中的检索
Relit-LiVE:通过联合学习环境视频实现视频重光照
积极对齐:人工智能助力人类繁荣
LLaVA-UHD v4:是什么构成了多模态大语言模型中高效的视觉编码?
揭露策略内蒸馏的真相:其有益之处、有害之处及原因分析
单个神经元足以绕过大型语言模型的安全对齐
SlimQwen:探索大型混合专家(MoE)模型预训练中的剪枝与知识蒸馏
ELF:嵌入式语言流
PaperFit:面向科学文档的视域内排版优化
基于量规的在线策略蒸馏
CollabVR:基于视觉-语言与视频生成模型的协同视频推理
TMAS:通过多智能体协同扩展测试时计算
Soohak:由数学家精心策划的基准测试,用于评估大语言模型在研究级数学能力方面的表现
Qwen-Image-2.0 技术报告
MiniCPM-o 4.5:迈向实时全双模全模态交互
部署中学习:面向通用机器人策略的车队规模强化学习
快速字节隐式Transformer
AI共同数学家:利用智能体AI加速数学研究
HyperEyes:面向并行多模态搜索代理的双粒度效率感知强化学习
均值模式尖叫:1000层扩散Transformer中的均值-方差分裂残差
LLMs改进LLMs:用于测试时缩放的Agent发现
列表策略优化:基于组的RLVR作为对LLM响应单纯形的目标投影
Flow-OPD:流匹配模型上的策略蒸馏
MACE-Dance:用于音乐驱动舞蹈视频生成的运动-外观级联专家模型
重思推理密集型检索:评估与推进智能体搜索系统中的检索器
何时信任想象力:世界动作模型的自适应动作执行
采用 Judge 协调的大模型集成框架「Meno and Friends」进行高真实性多轮响应生成
MiA-Signature:近似全局激活以实现长上下文理解
连续潜扩散语言模型
技能1:基于强化学习的技能增强代理统一进化
超越语义相似性:通过直接与语料库交互重新思考代理搜索中的检索