HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

PhyCritic:面向物理AI的多模态批评者模型

GENIUS:生成式流体智能评估套件























PhyCritic:面向物理AI的多模态批评者模型
GENIUS:生成式流体智能评估套件
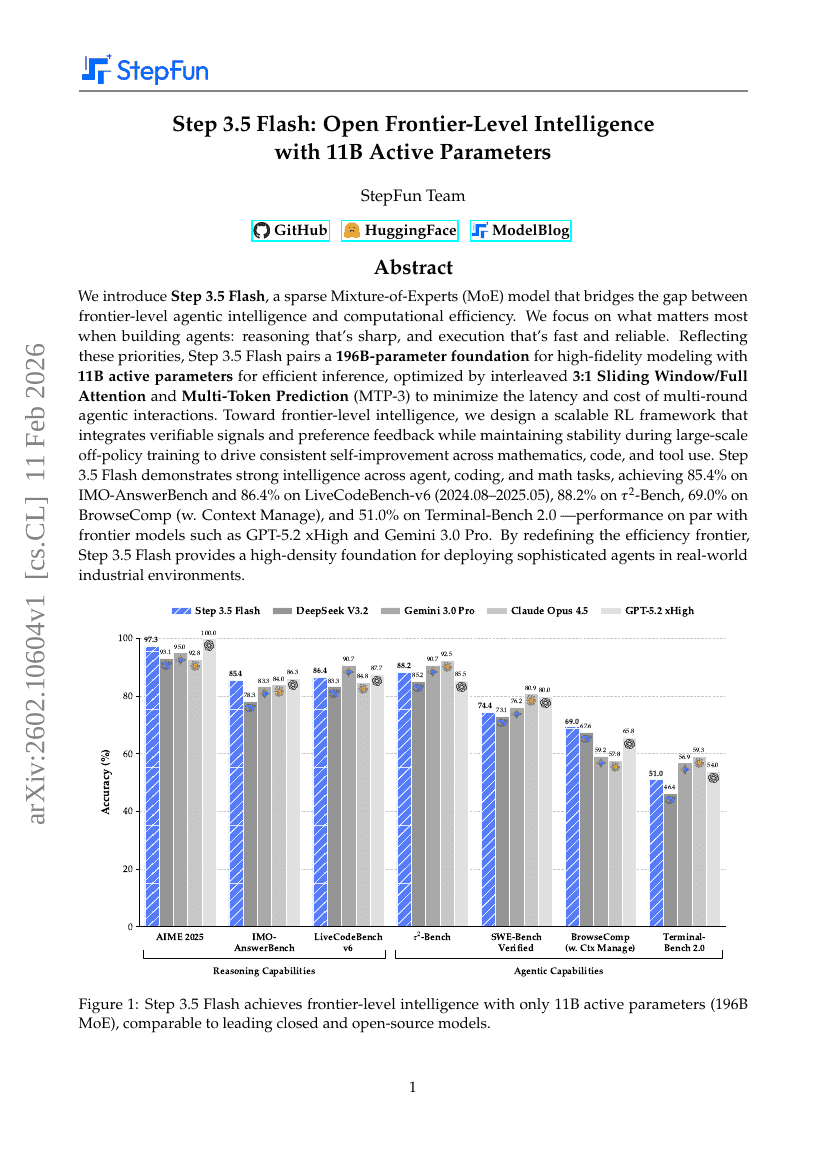
Step 3.5 Flash:以 11B 激活参数开启前沿级智能
世界-VLA-环:视频世界模型与VLA策略的闭环学习
迈向自主数学研究
Agent世界模型:用于智能体强化学习的无限合成环境
P1-VL:连接视觉感知与物理奥赛中的科学推理
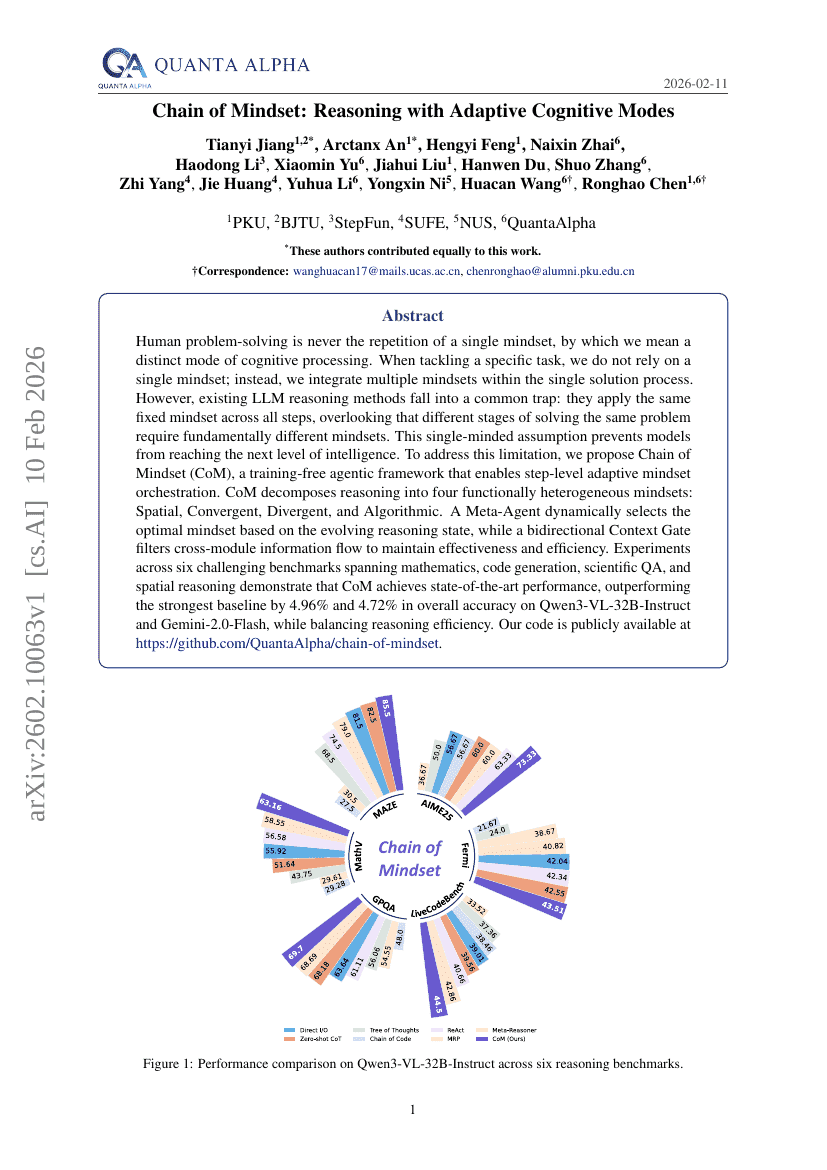
思维链:基于自适应认知模式的推理
UI-Venus-1.5 技术报告
Code2World:一种通过可渲染代码生成的GUI世界模型
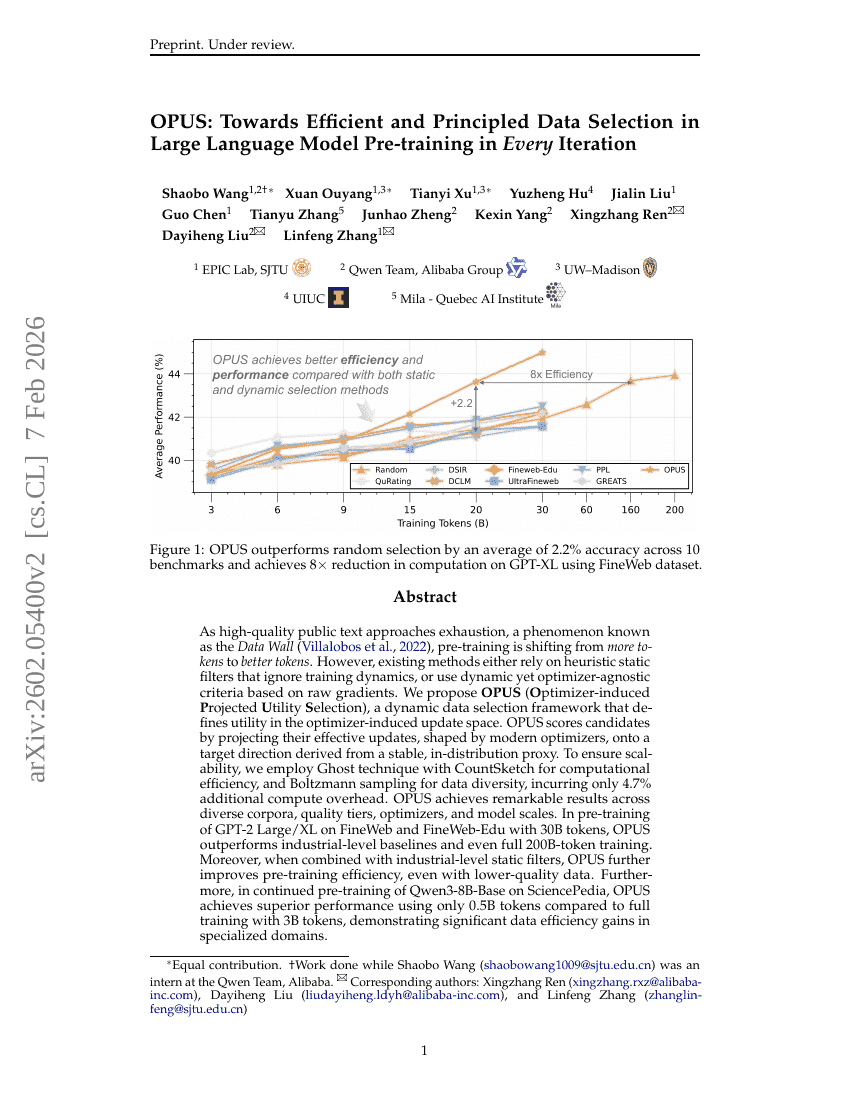
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
THINGS-data:用于研究人类大脑与行为中物体表征的大规模多模态数据集集合
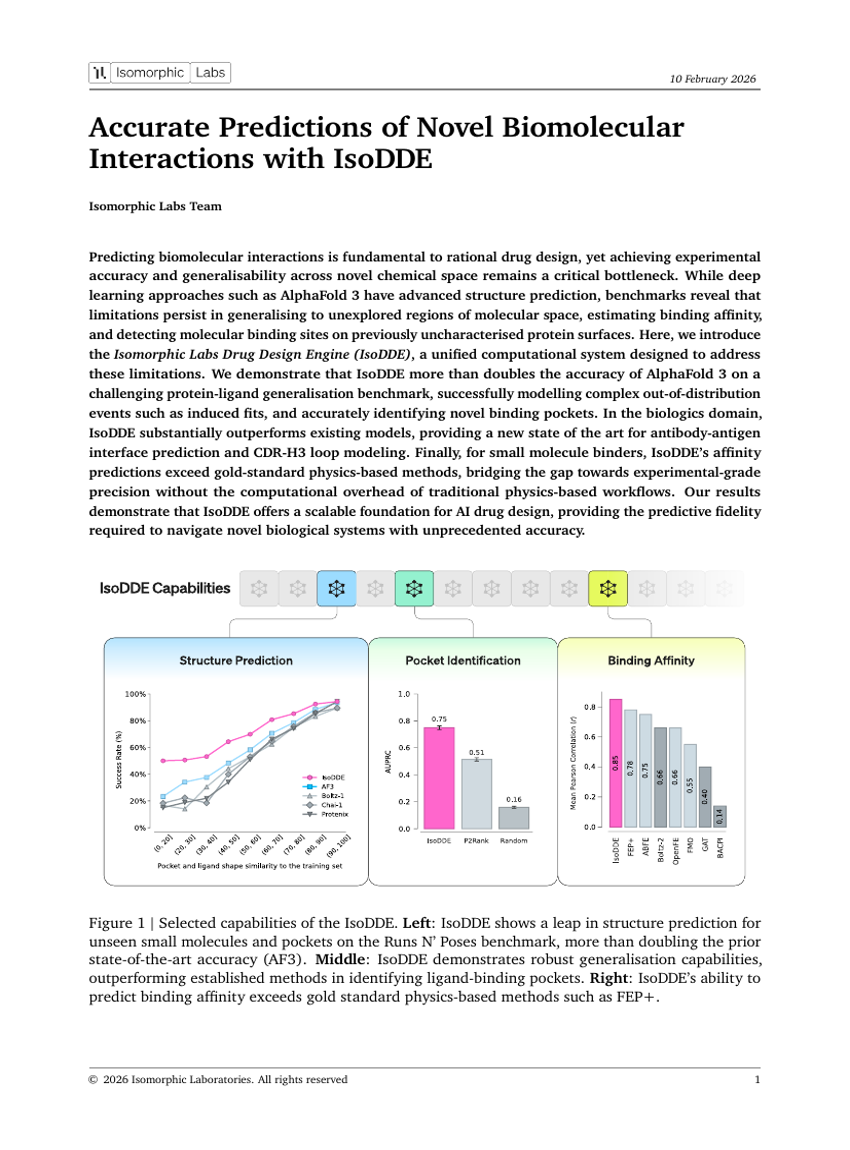
利用 IsoDDE 对新型生物分子相互作用进行准确预测
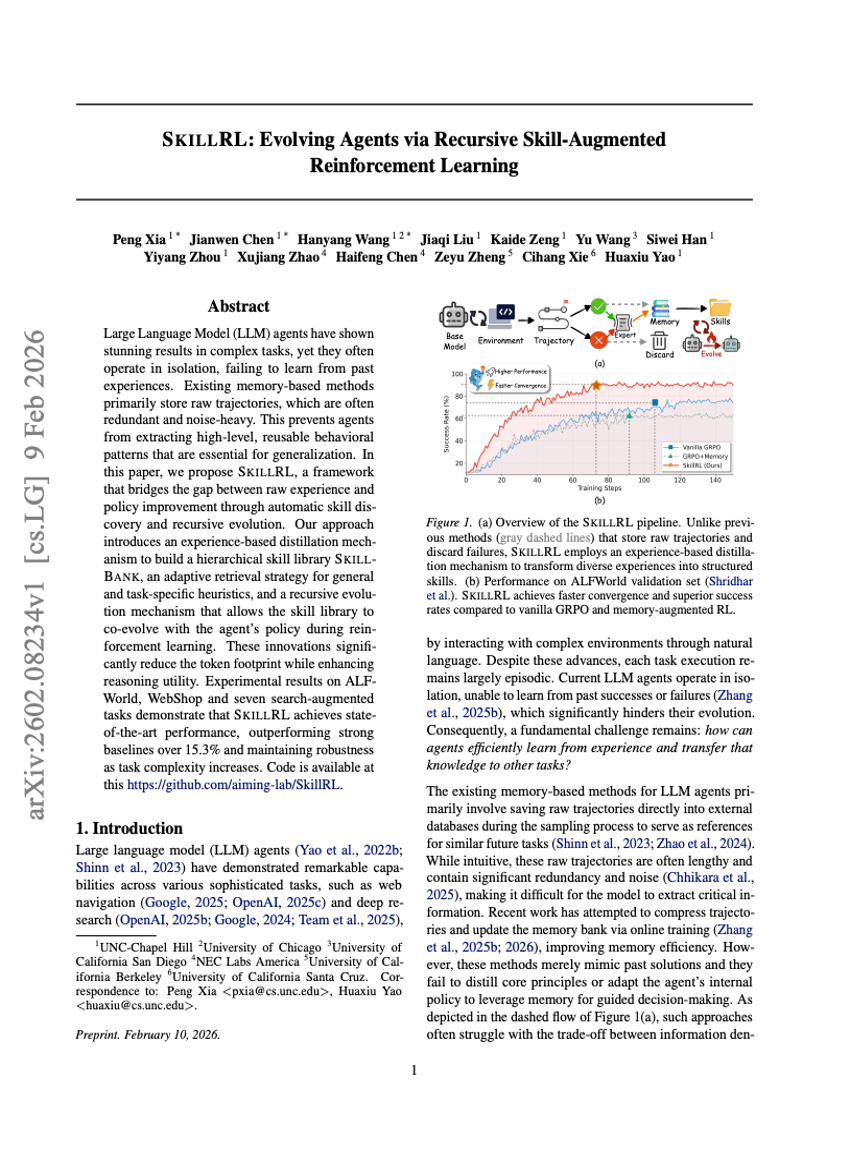
SKILLRL:通过递归式技能增强强化学习实现 Agents 的演进
LLaDA2.1:通过Token编辑加速文本扩散
通过建模基于流的GRPO中的步骤级与长期采样效应缓解稀疏奖励问题
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
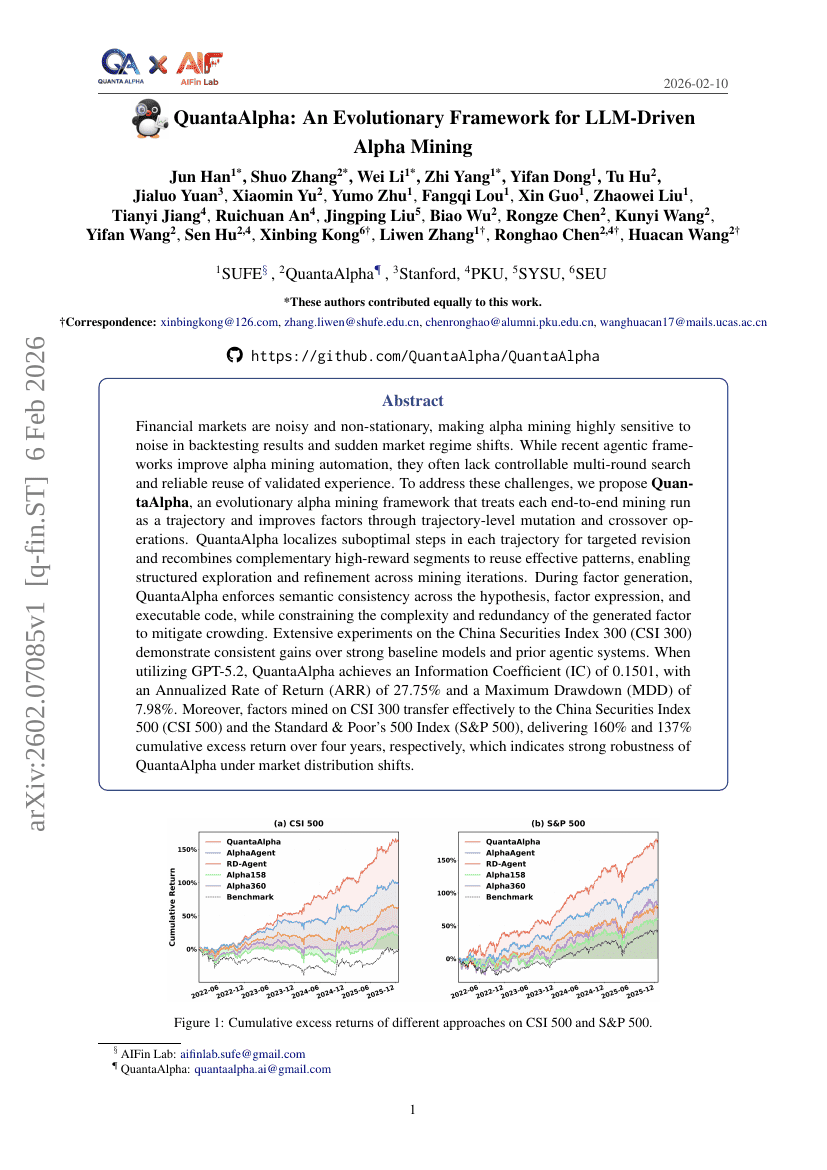
QuantaAlpha:一种面向LLM驱动的Alpha挖掘的进化框架
模态间隙驱动的子空间对齐训练范式用于多模态大语言模型
MOVA:迈向可扩展且同步的视频-音频生成
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
DreamDojo:基于大规模人类视频的通用机器人世界模型
F-GRPO:别让你的策略学习到显而易见的内容却遗忘稀有情况
MSign:通过稳定秩恢复防止大语言模型训练不稳定的优化器
AudioSAE:基于稀疏自编码器的音频处理模型理解
大型语言模型强化微调中的熵动态研究
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
百川-M3:面向可靠医疗决策的临床问诊建模
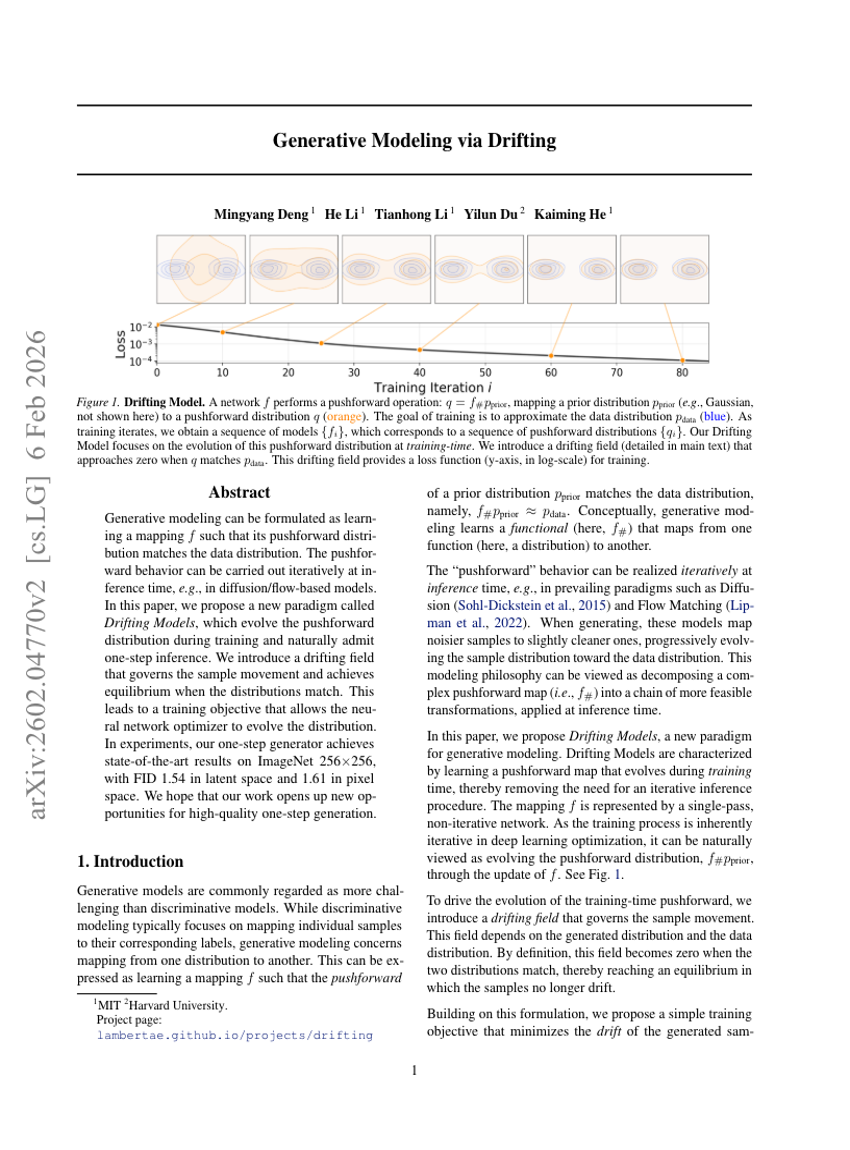
通过漂移进行生成建模
AlphaEdit:针对语言模型的零空间约束知识编辑
在13个参数中进行推理学习
Step 3.5 Flash:以 11B 激活参数开启前沿级智能
世界-VLA-环:视频世界模型与VLA策略的闭环学习
迈向自主数学研究
Agent世界模型:用于智能体强化学习的无限合成环境
P1-VL:连接视觉感知与物理奥赛中的科学推理
思维链:基于自适应认知模式的推理
UI-Venus-1.5 技术报告
Code2World:一种通过可渲染代码生成的GUI世界模型
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
THINGS-data:用于研究人类大脑与行为中物体表征的大规模多模态数据集集合
利用 IsoDDE 对新型生物分子相互作用进行准确预测
SKILLRL:通过递归式技能增强强化学习实现 Agents 的演进
LLaDA2.1:通过Token编辑加速文本扩散
通过建模基于流的GRPO中的步骤级与长期采样效应缓解稀疏奖励问题
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
QuantaAlpha:一种面向LLM驱动的Alpha挖掘的进化框架
模态间隙驱动的子空间对齐训练范式用于多模态大语言模型
MOVA:迈向可扩展且同步的视频-音频生成
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
DreamDojo:基于大规模人类视频的通用机器人世界模型
F-GRPO:别让你的策略学习到显而易见的内容却遗忘稀有情况
MSign:通过稳定秩恢复防止大语言模型训练不稳定的优化器
AudioSAE:基于稀疏自编码器的音频处理模型理解
大型语言模型强化微调中的熵动态研究
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
百川-M3:面向可靠医疗决策的临床问诊建模
通过漂移进行生成建模
AlphaEdit:针对语言模型的零空间约束知识编辑
在13个参数中进行推理学习