HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

更难才更好:通过感知难度的GRPO与多维度问题重表述提升数学推理能力
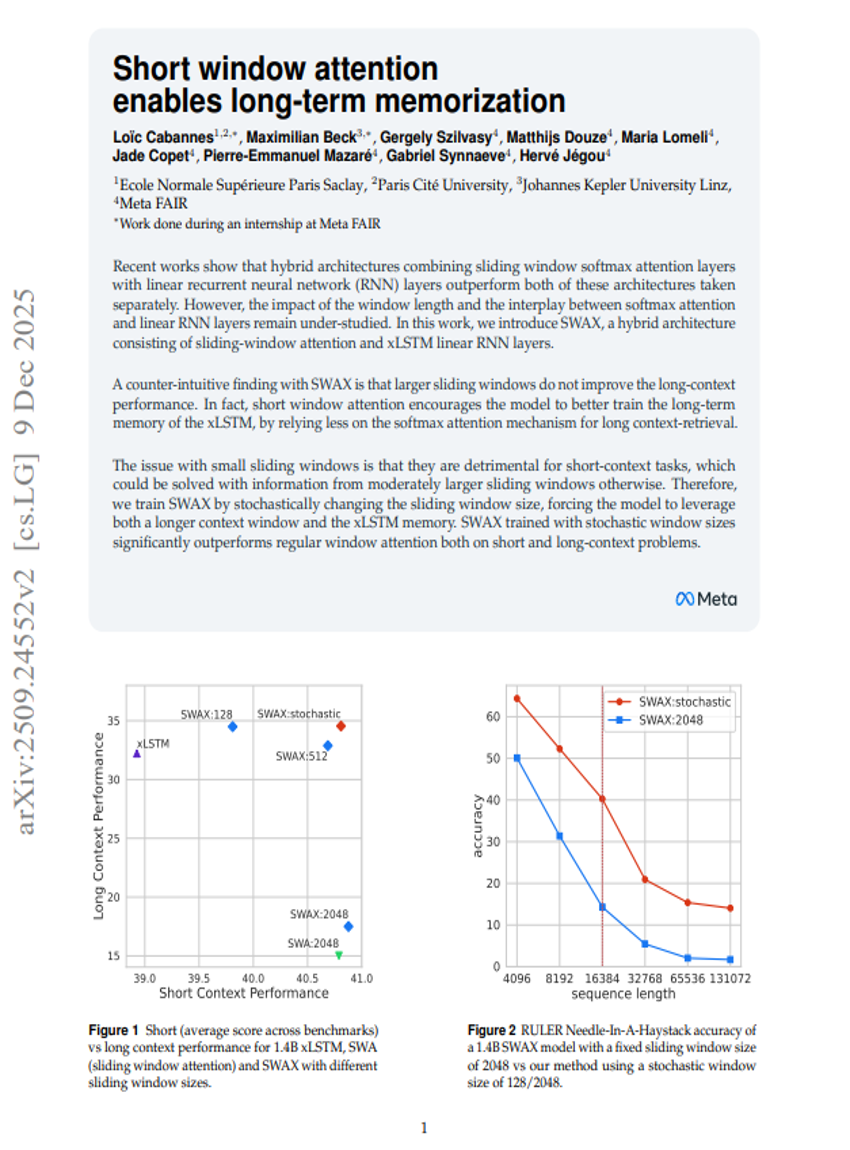
短窗口注意力实现长期记忆化















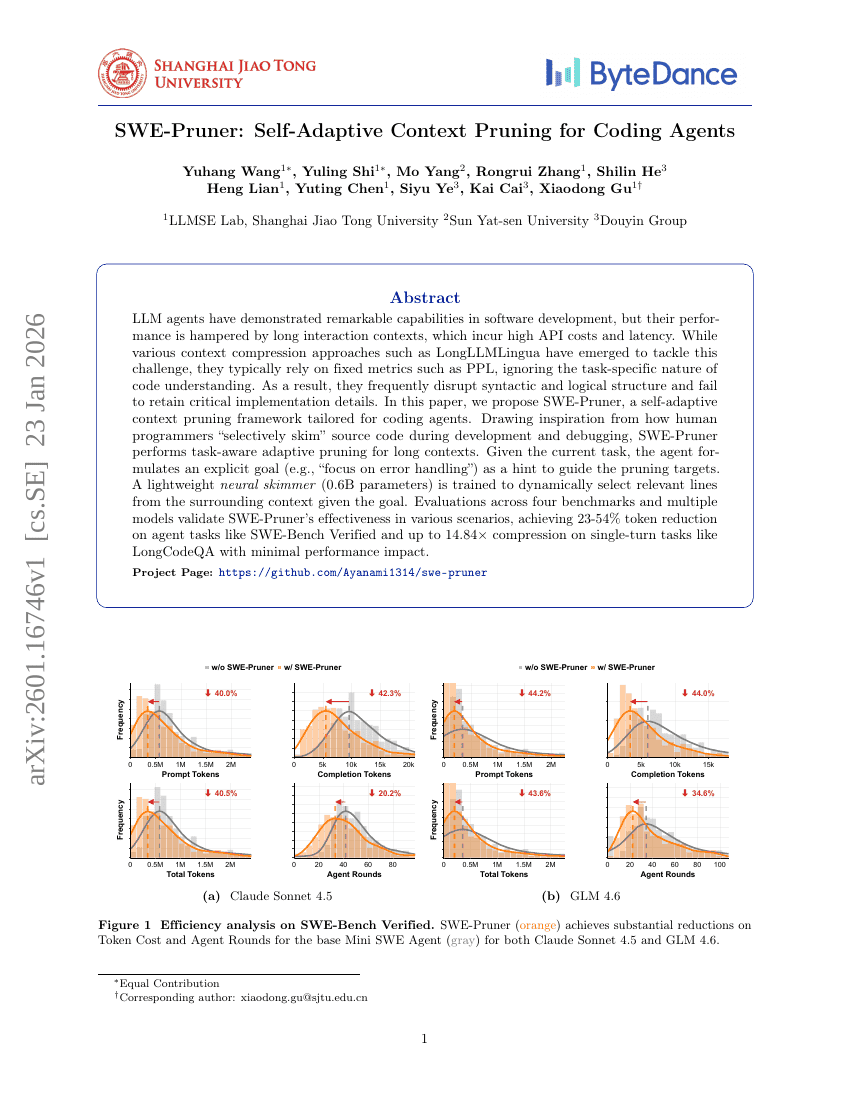
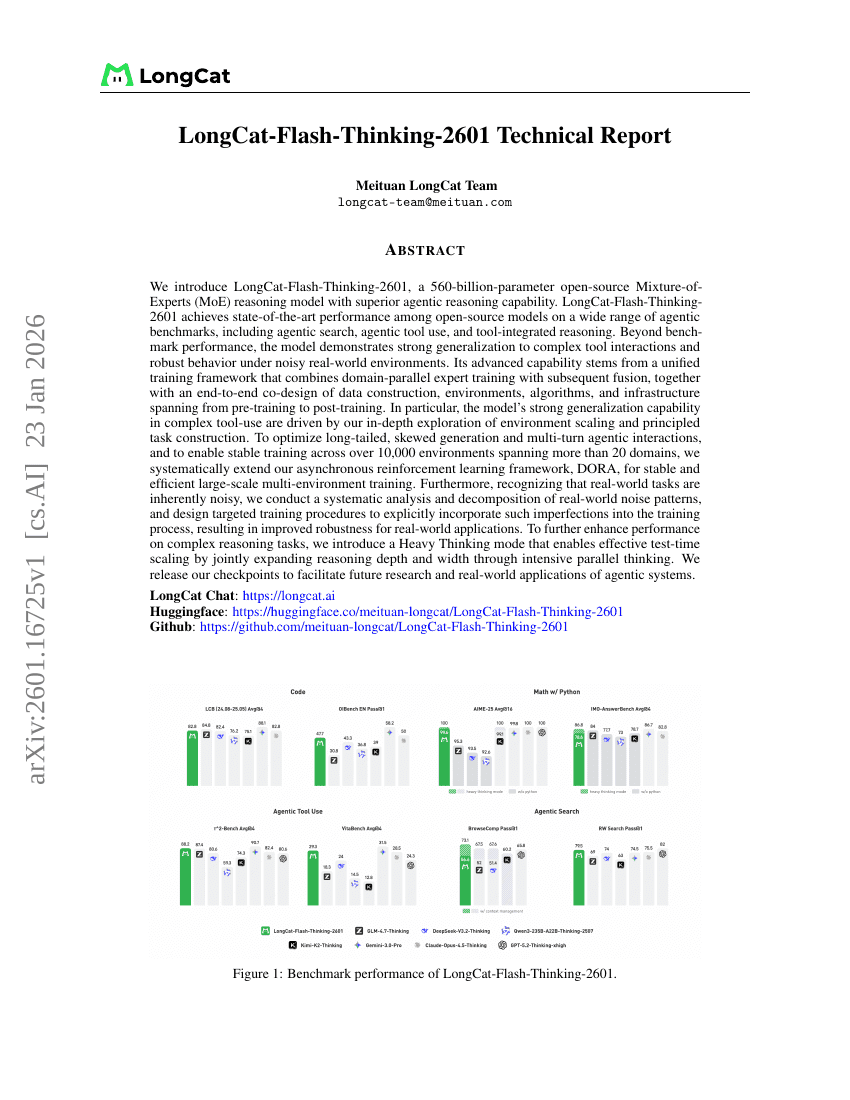



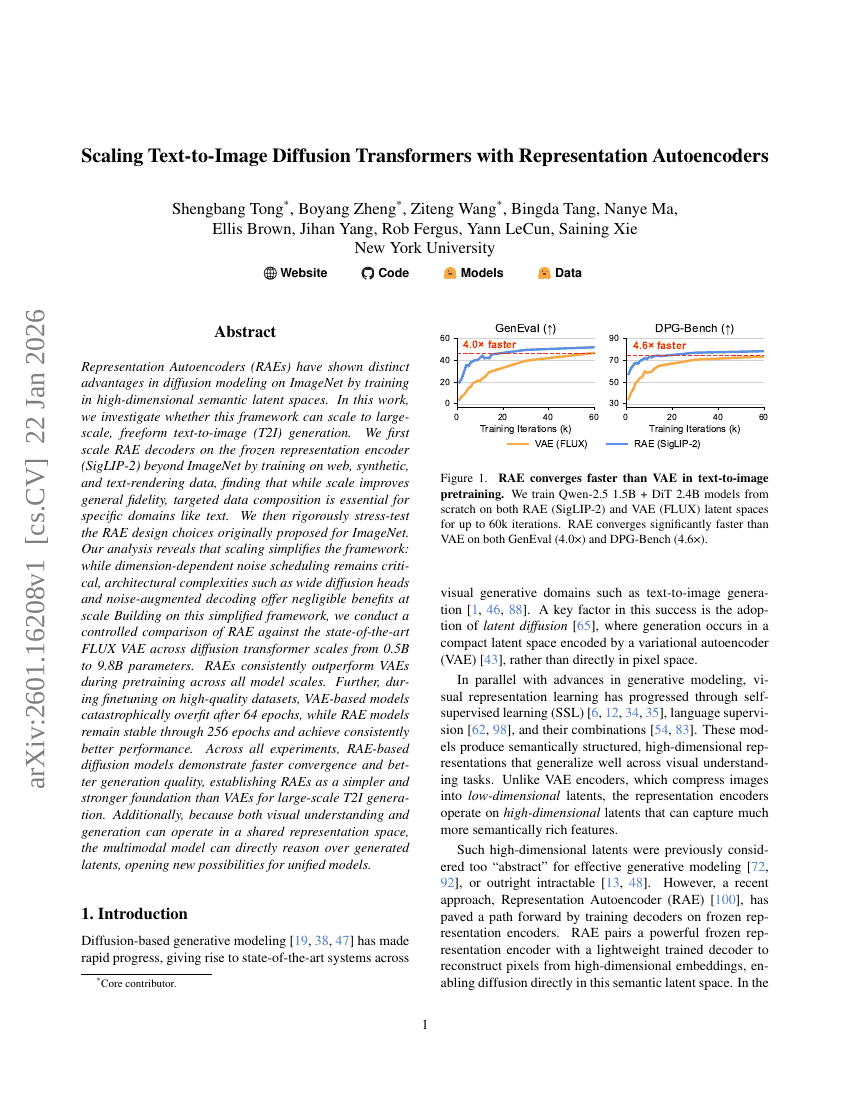

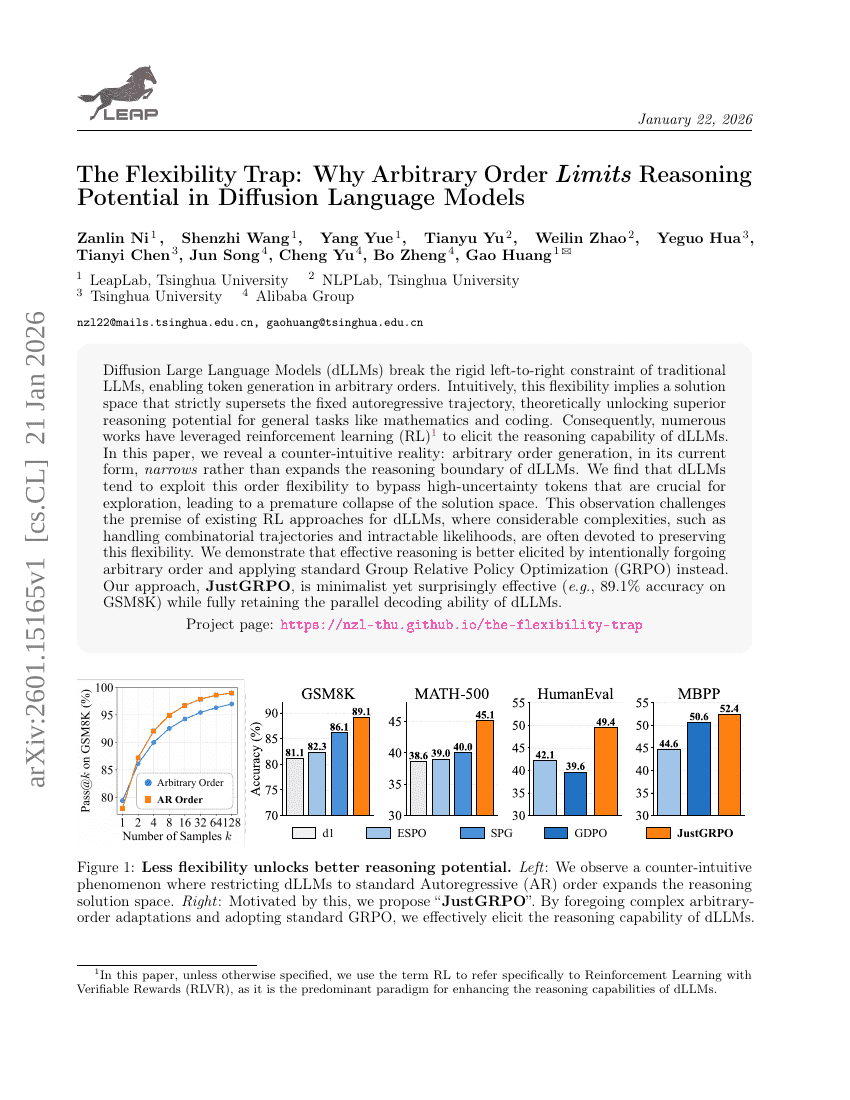
更难才更好:通过感知难度的GRPO与多维度问题重表述提升数学推理能力
短窗口注意力实现长期记忆化
World Craft:通过文本创建可可视化世界的智能体框架
视觉生成通过多模态世界模型解锁类人推理
掩码深度建模用于空间感知
一种实用的VLA基础模型
AdaReasoner:用于迭代视觉推理的动态工具编排
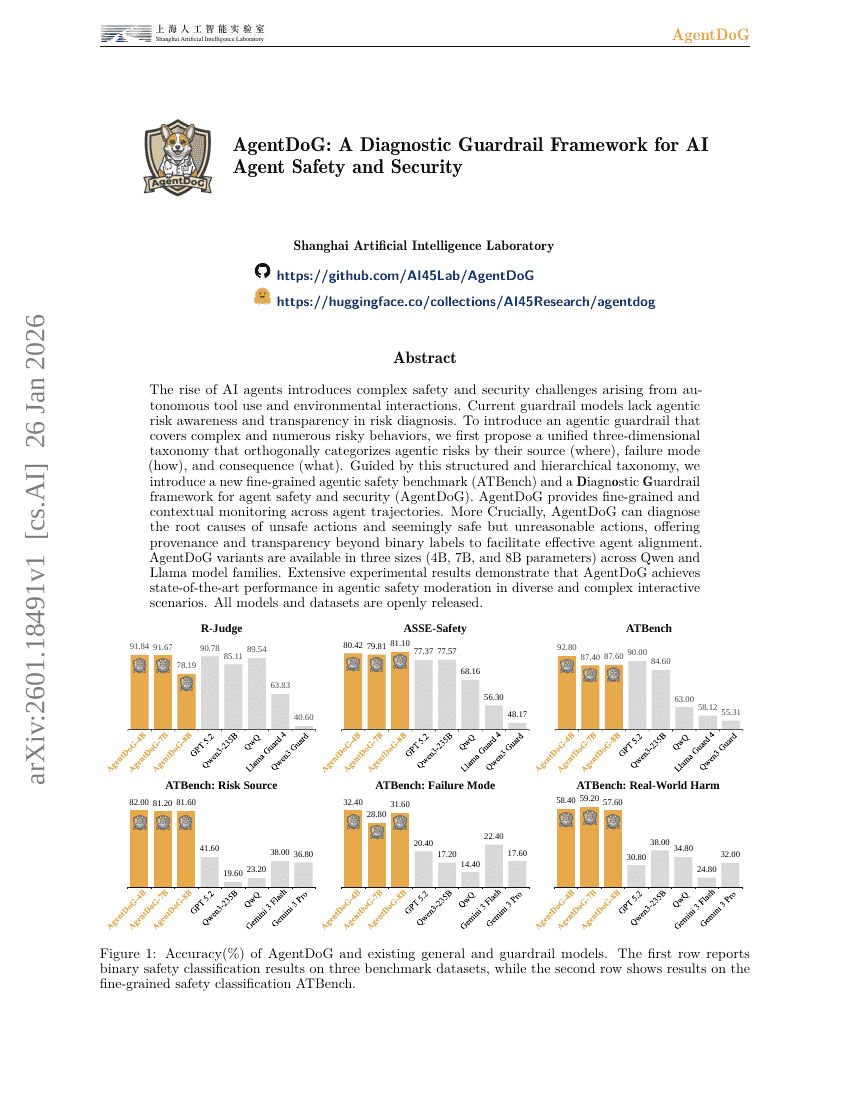
AgentDoG:面向AI Agent安全与可信的诊断防护框架
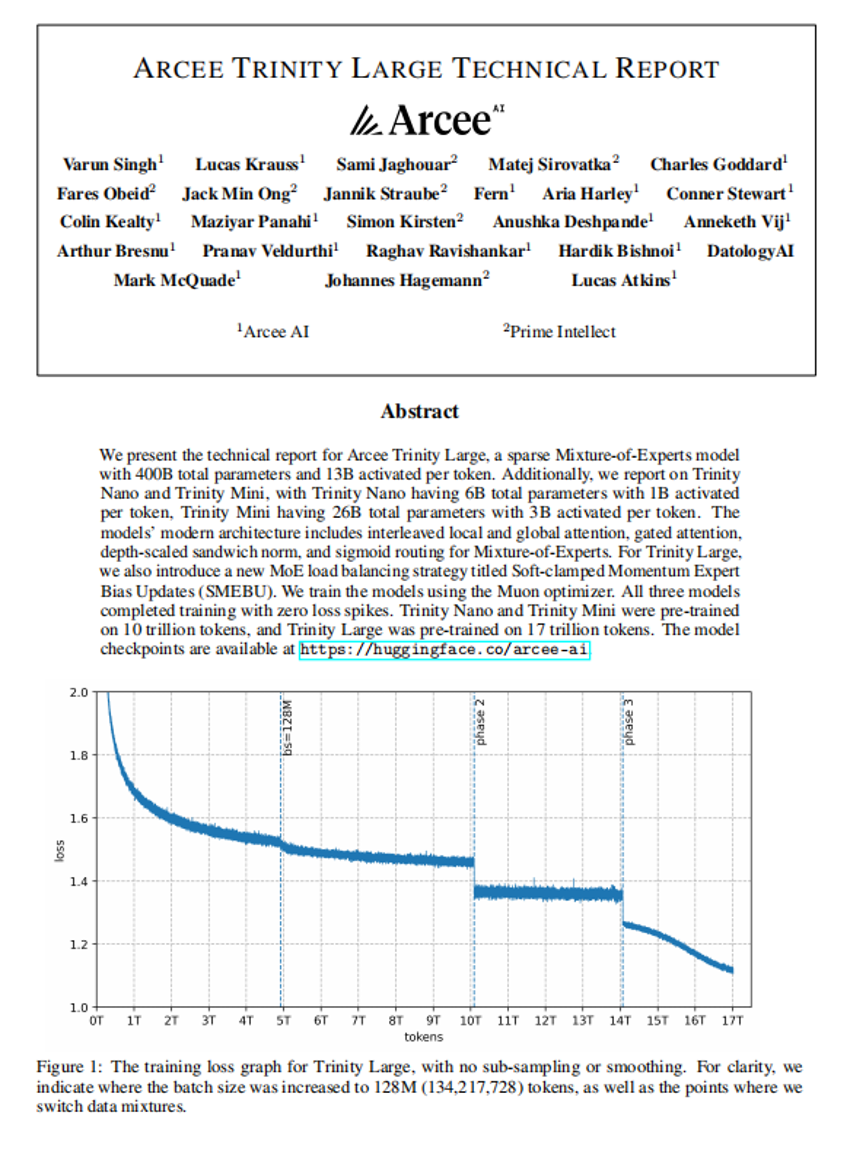
Arcee Trinity 大型技术报告
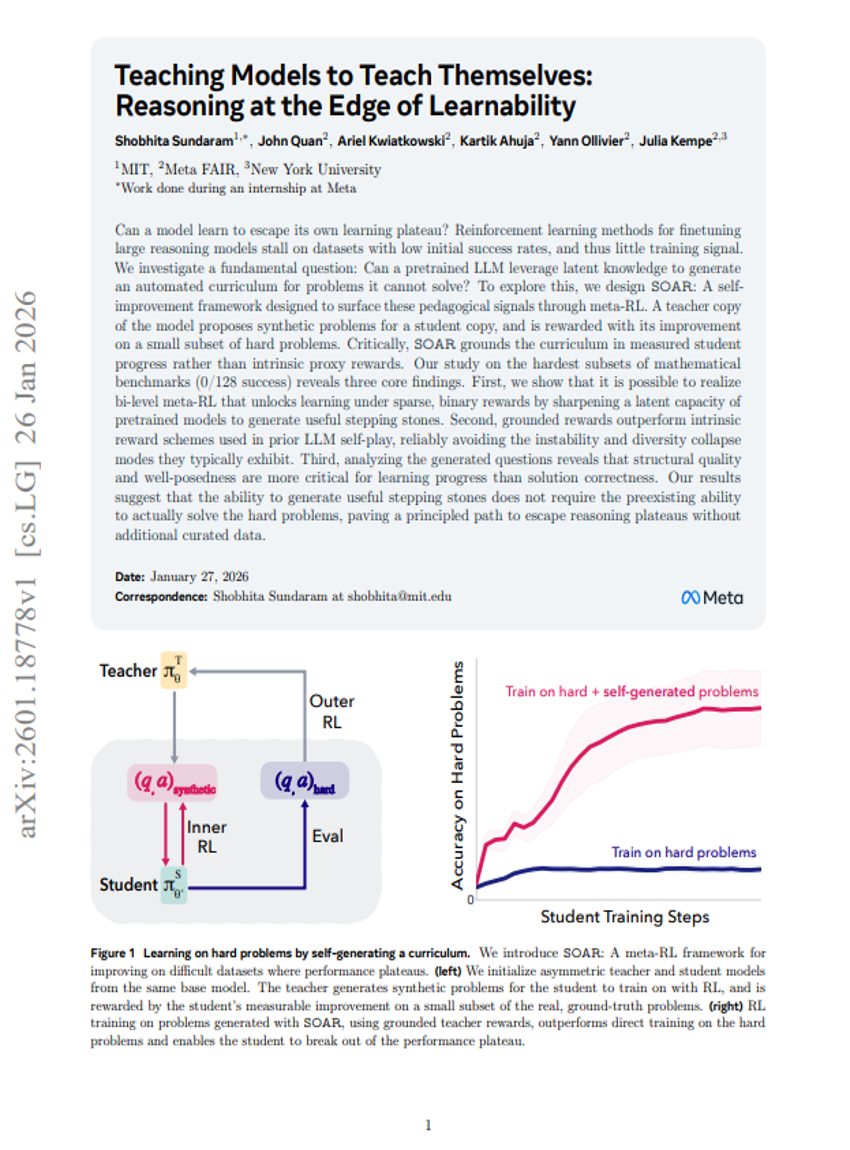
让模型学会自我教学:在可学习性边缘的推理
ATLAS:多语言预训练、微调与解码多语言困境的自适应迁移缩放定律
iFSQ:仅需一行代码提升图像生成中的FSQ性能
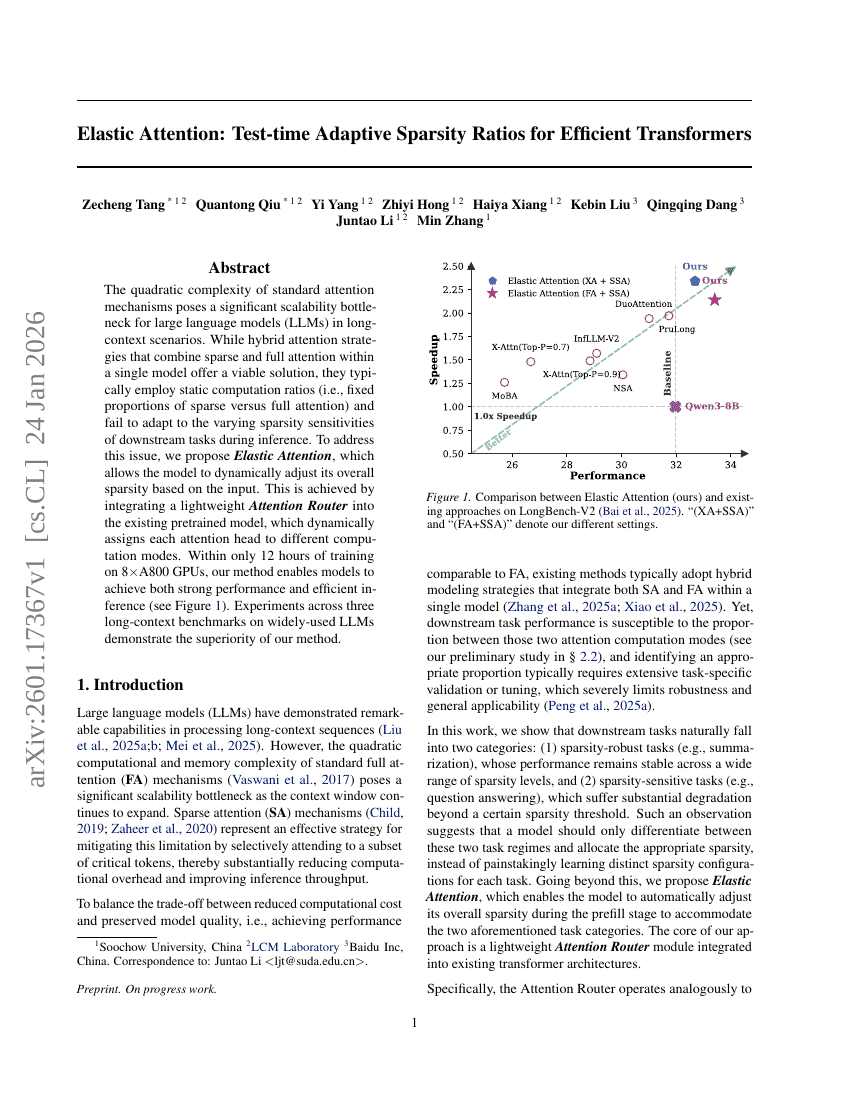
弹性注意力:面向高效Transformer的测试时自适应稀疏率
科学图像生成:基准测试、方法论及下游应用价值
脚本即一切:一种面向长时程对话到影视视频生成的智能体框架
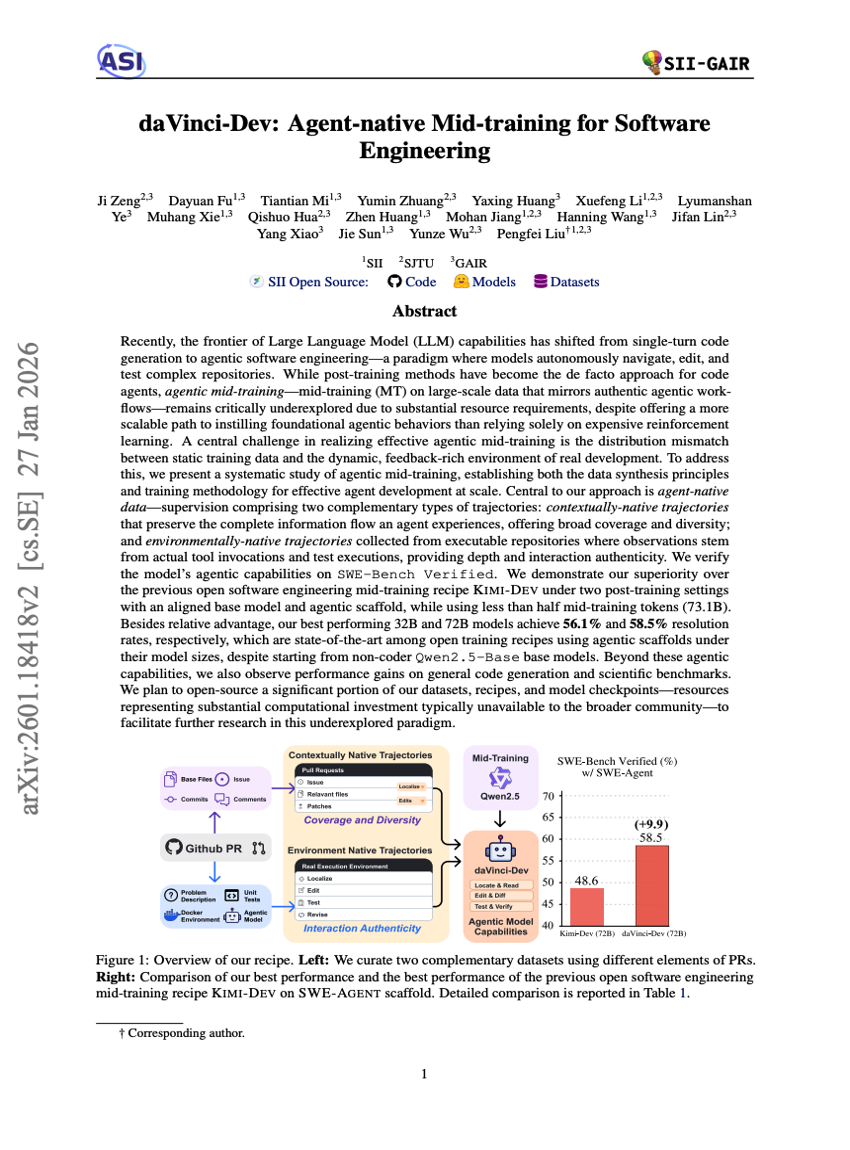
daVinci-Dev:面向软件工程的Agent原生中段训练
LLM能否帮你收拾烂摊子?基于LLM的应用就绪数据准备综述
DeepSeek-OCR 2:视觉因果流
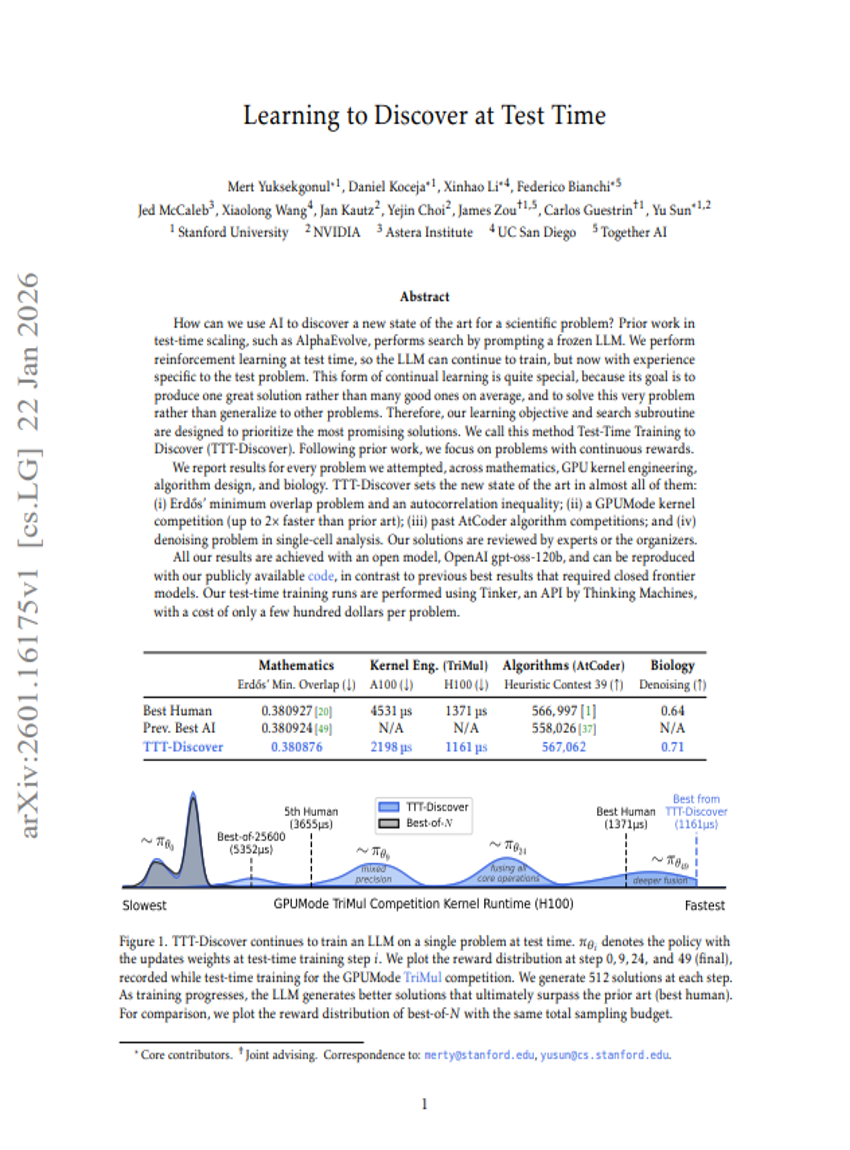
学习测试时发现
通过在防护输出上微调以诱发有害能力
Memory-V2V:通过记忆增强视频到视频扩散模型
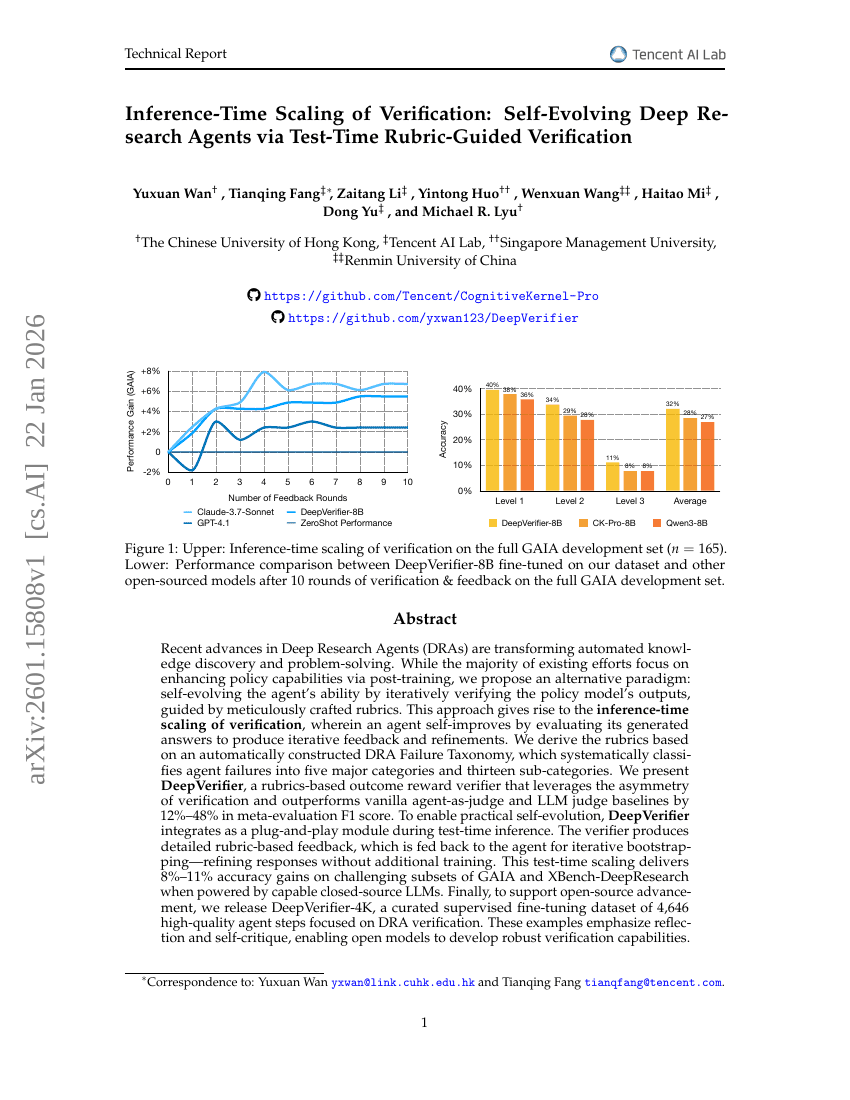
推理时扩展验证:通过测试时评分标准引导的验证实现自演化深度研究Agent
VisGym:面向多模态Agent的多样化、可定制化、可扩展环境
TwinBrainVLA:通过非对称Transformer混合模型释放通用VLM在具身任务中的潜力
SWE-Pruner:面向编码Agent的自适应上下文剪枝
LongCat-Flash-Thinking-2601 技术报告
语言模型能否发现缩放定律?
Cosmos Policy:针对视觉运动控制与规划微调视频模型
Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
基于表征自编码器的文本到图像扩散Transformer的扩展
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力
World Craft:通过文本创建可可视化世界的智能体框架
视觉生成通过多模态世界模型解锁类人推理
掩码深度建模用于空间感知
一种实用的VLA基础模型
AdaReasoner:用于迭代视觉推理的动态工具编排
AgentDoG:面向AI Agent安全与可信的诊断防护框架
Arcee Trinity 大型技术报告
让模型学会自我教学:在可学习性边缘的推理
ATLAS:多语言预训练、微调与解码多语言困境的自适应迁移缩放定律
iFSQ:仅需一行代码提升图像生成中的FSQ性能
弹性注意力:面向高效Transformer的测试时自适应稀疏率
科学图像生成:基准测试、方法论及下游应用价值
脚本即一切:一种面向长时程对话到影视视频生成的智能体框架
daVinci-Dev:面向软件工程的Agent原生中段训练
LLM能否帮你收拾烂摊子?基于LLM的应用就绪数据准备综述
DeepSeek-OCR 2:视觉因果流
学习测试时发现
通过在防护输出上微调以诱发有害能力
Memory-V2V:通过记忆增强视频到视频扩散模型
推理时扩展验证:通过测试时评分标准引导的验证实现自演化深度研究Agent
VisGym:面向多模态Agent的多样化、可定制化、可扩展环境
TwinBrainVLA:通过非对称Transformer混合模型释放通用VLM在具身任务中的潜力
SWE-Pruner:面向编码Agent的自适应上下文剪枝
LongCat-Flash-Thinking-2601 技术报告
语言模型能否发现缩放定律?
Cosmos Policy:针对视觉运动控制与规划微调视频模型
Triton-distributed:使用 Triton 编译器在分布式 AI 系统中编程重叠内核
基于表征自编码器的文本到图像扩散Transformer的扩展
BayesianVLA:通过潜在动作查询对视觉-语言-动作模型进行贝叶斯分解
灵活性陷阱:为何任意顺序限制制约了扩散语言模型的推理潜力