HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

在野外学习潜在动作世界模型

Dr. Zero:无需训练数据的自演化搜索Agent






















在野外学习潜在动作世界模型
Dr. Zero:无需训练数据的自演化搜索Agent
MHLA:通过Token级多头机制恢复线性注意力的表达能力
GlimpRouter:通过窥视一个思维token实现高效协同推理
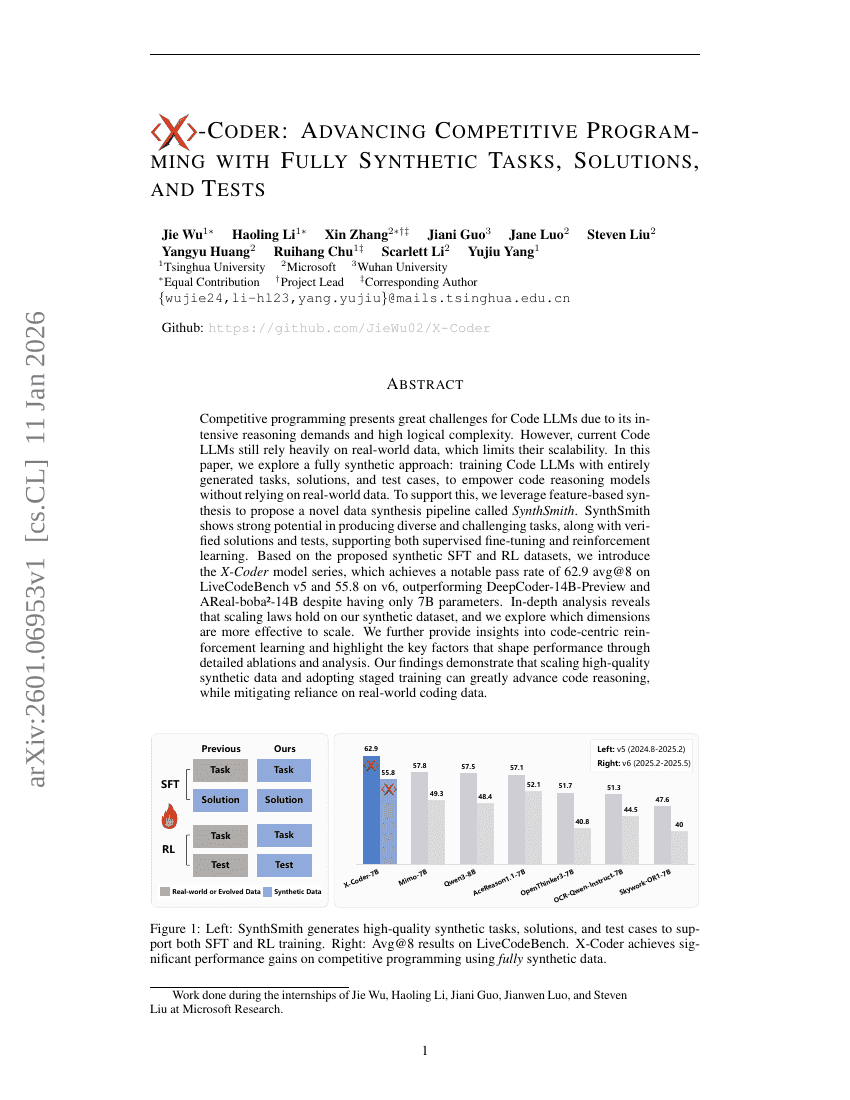
X-Coder:基于全合成任务、解法与测试的竞赛编程新范式
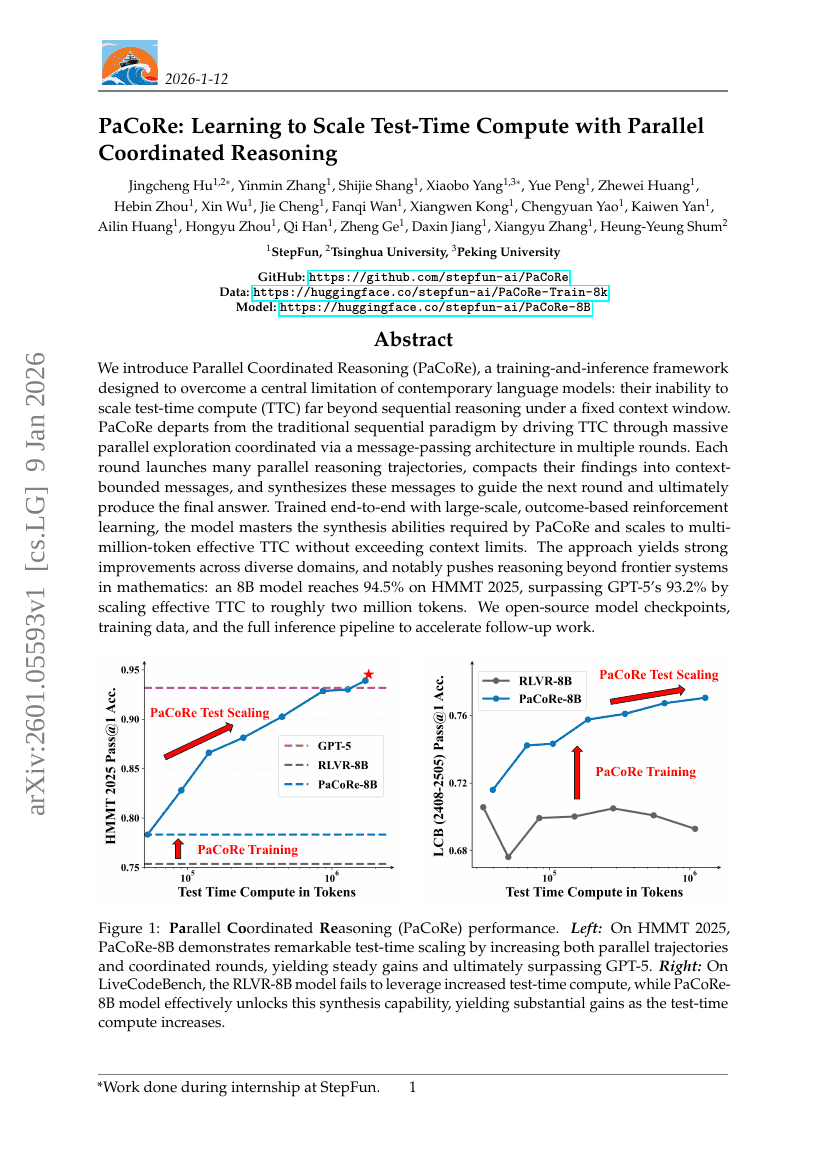
PaCoRe:通过并行协同推理学习在测试时扩展计算资源
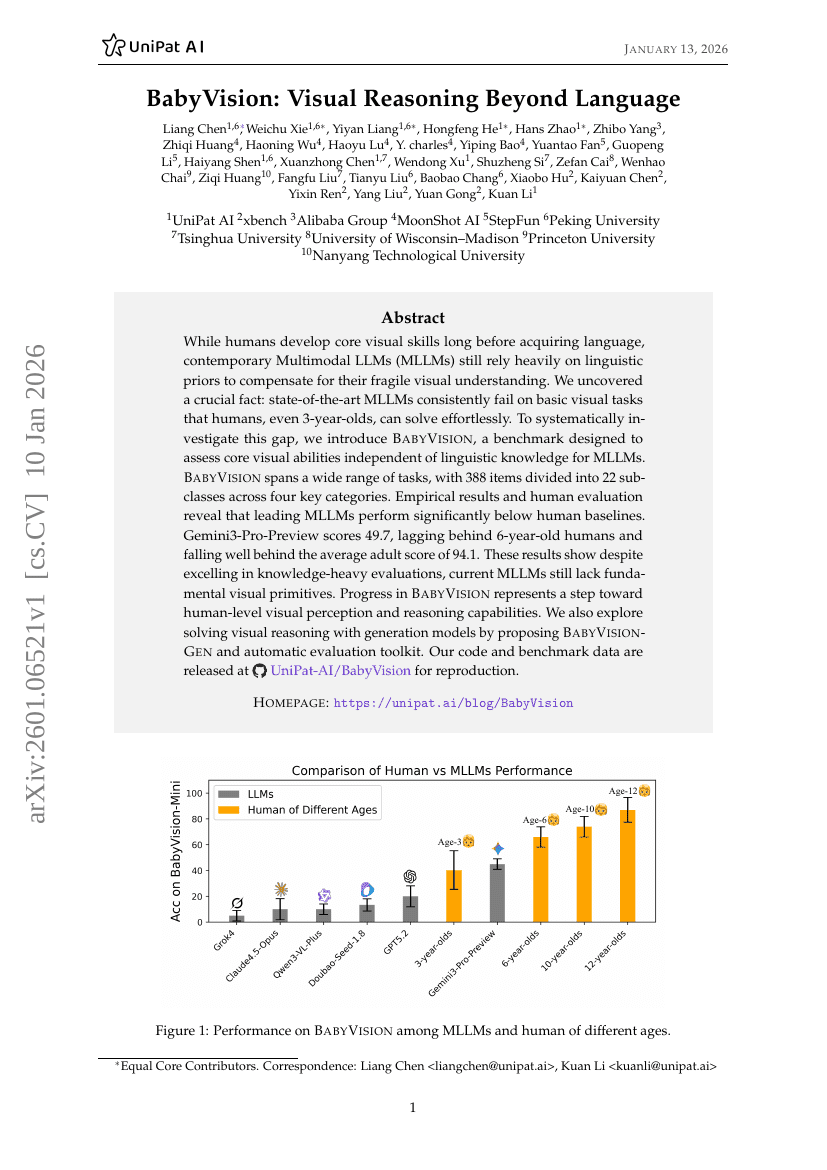
BabyVision:超越语言的视觉推理
观看、推理与搜索:面向智能体视频推理的开放网络视频深度研究基准
通过可扩展查找实现的条件记忆:大型语言模型稀疏性的一个新维度
EnvScaler:通过程序化合成实现LLM Agent的工具交互环境扩展
证据链构建:基于引用感知评分奖励的深度搜索Agent鲁棒强化学习
卡通化GS:基于高斯曲率的3D高斯溅射人脸夸张方法
思维的分子结构:长链思维推理拓扑结构的映射
MMFormalizer:开放环境中的多模态自动形式化
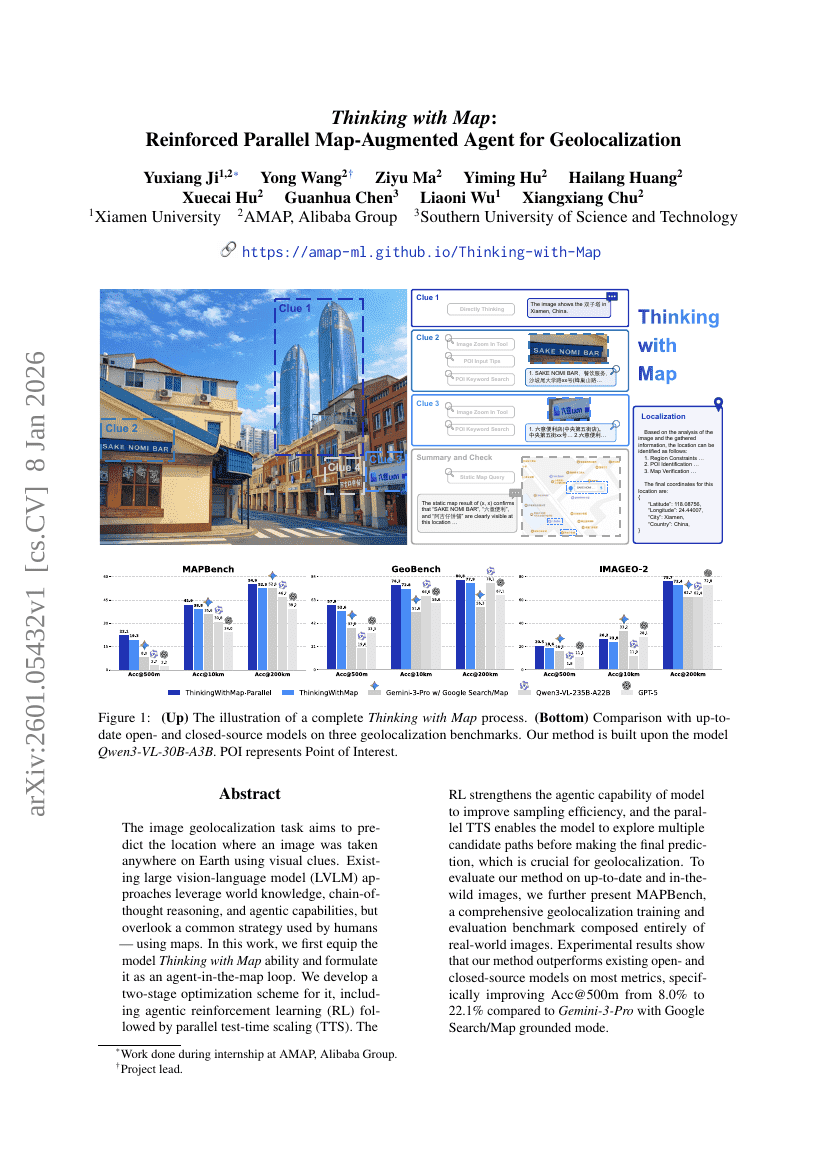
基于地图的思维:用于地理定位的强化并行地图增强型Agent
打破有向单源最短路径的排序障碍
GR-Dexter 技术报告
VideoAuto-R1:通过一次思考,两次作答实现视频自动推理
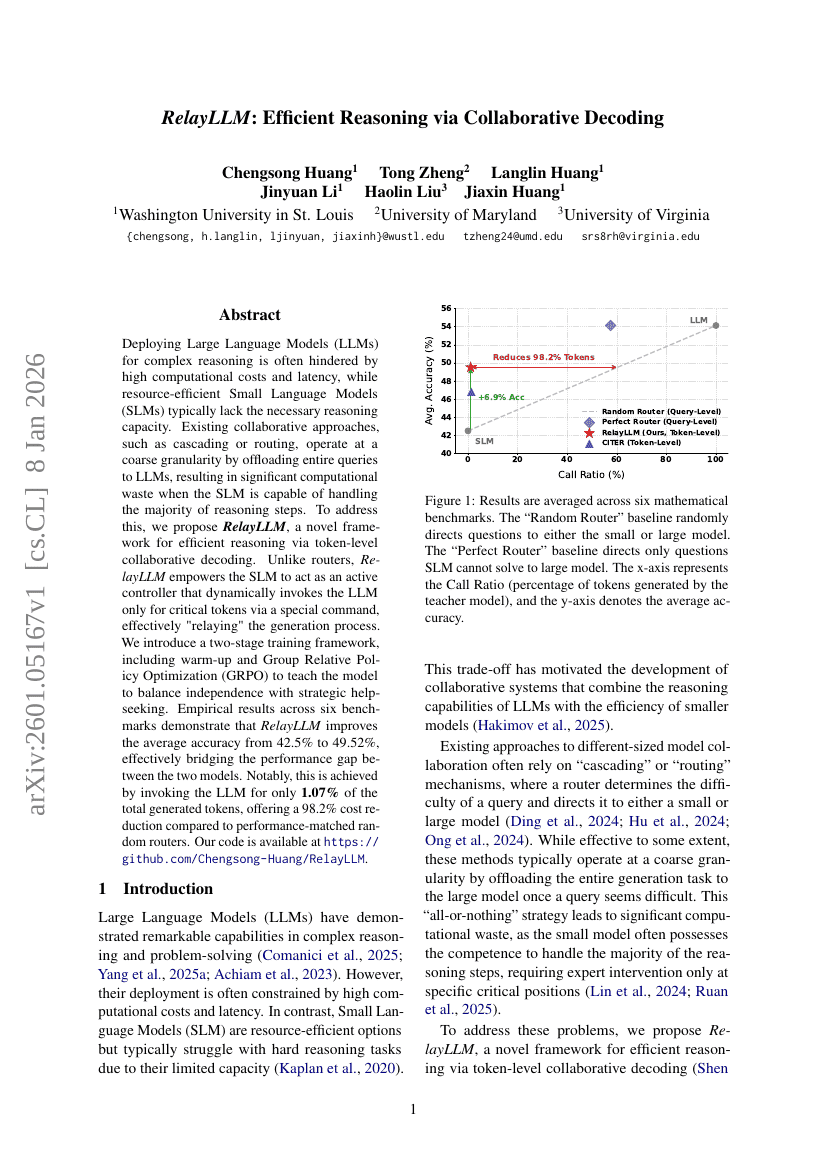
RelayLLM:通过协作解码实现高效推理
基于FusionRoute的Token级LLM协作
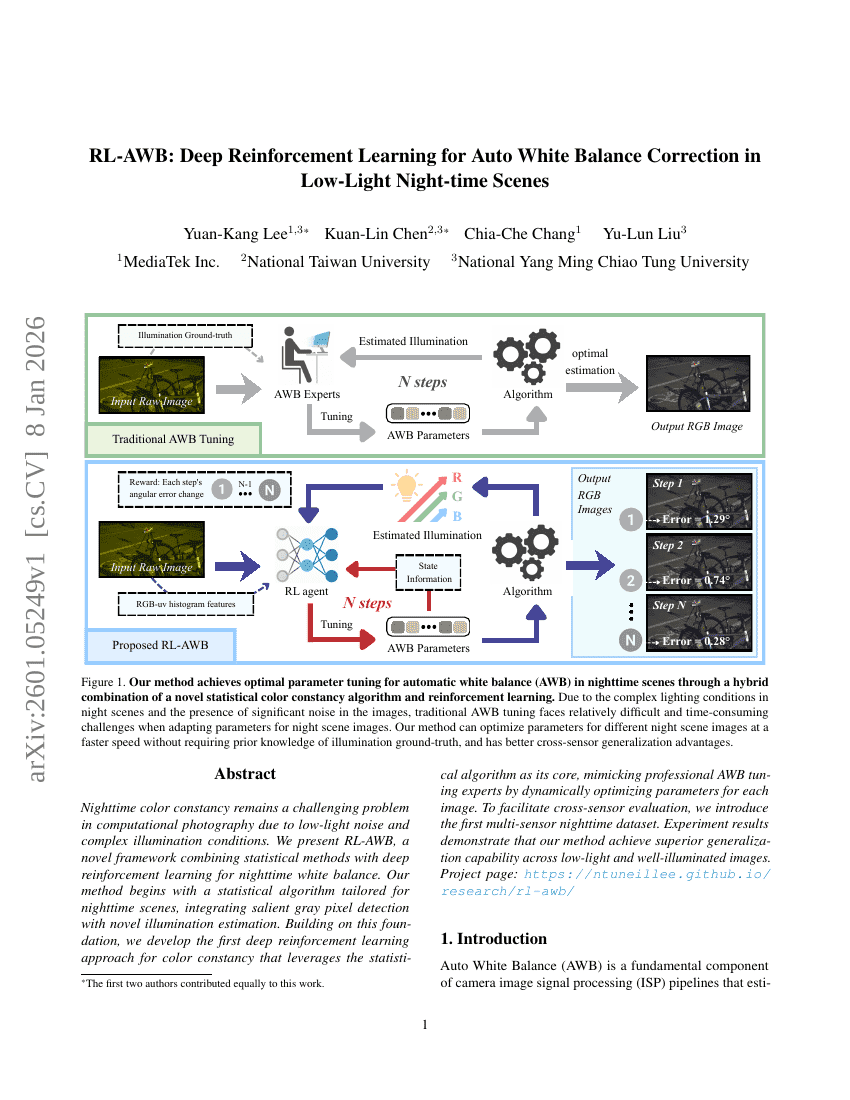
RL-AWB:基于深度强化学习的低光照夜间场景自动白平衡校正
可学习的缩放因子:释放语言模型矩阵层的规模限制
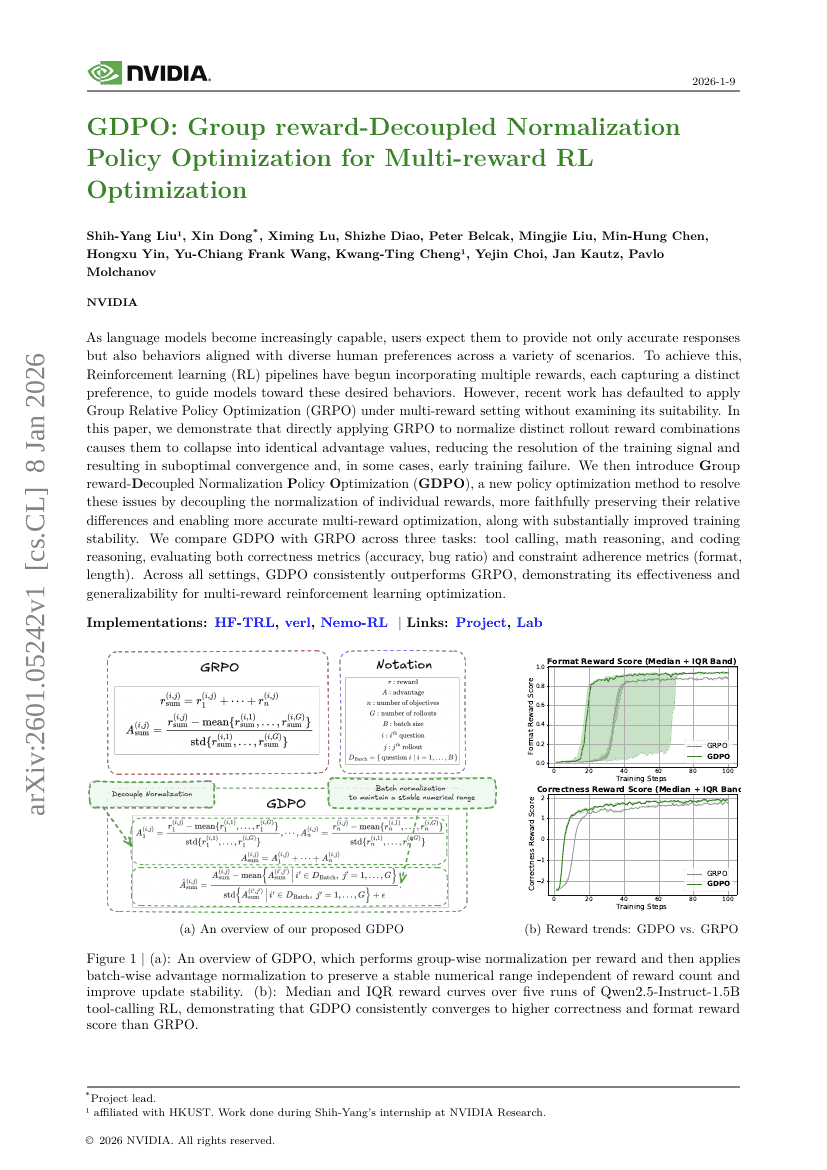
GDPO:面向多奖励强化学习优化的分组奖励解耦归一化策略优化
MemRL:通过情景记忆上的运行时强化学习实现自我演化的Agent
从失败到精通:为Tool-use Agents生成困难样本
编排一个动态物体的世界
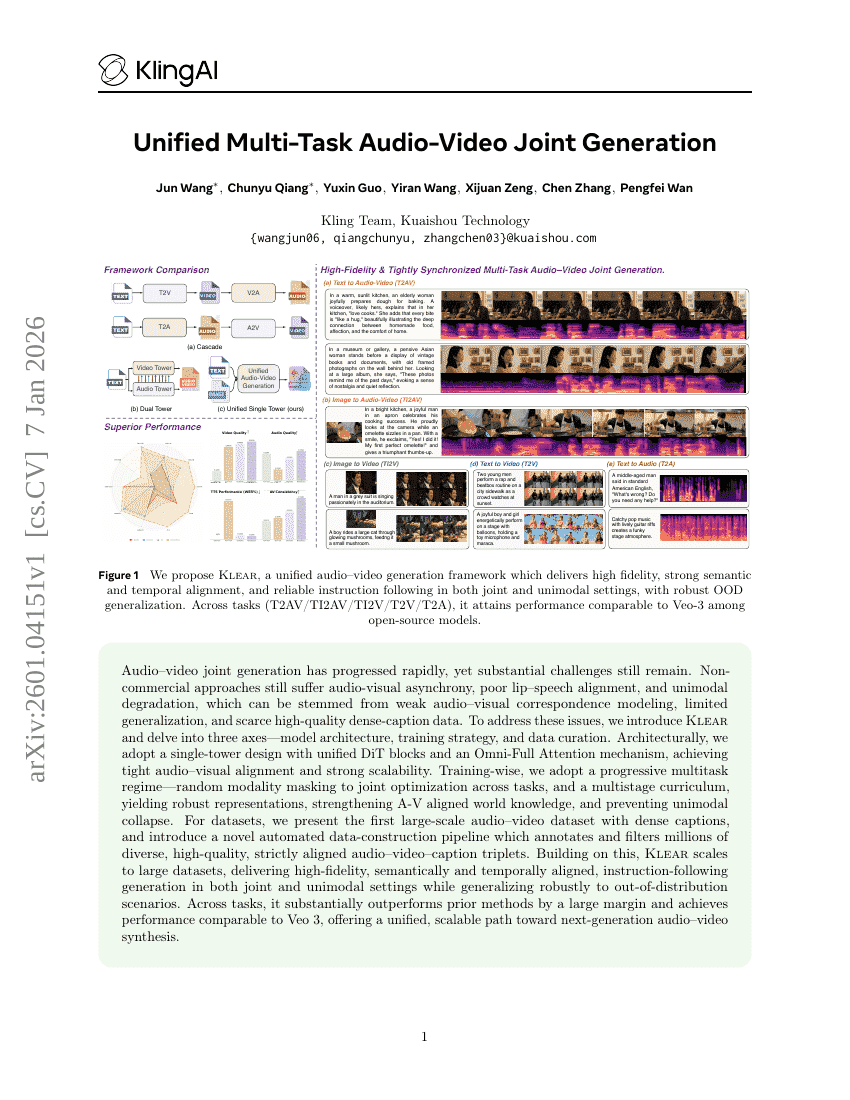
Klear:统一的多任务音视频联合生成
Atlas:面向多领域复杂推理的异构模型与工具编排
Benchmark^2:LLM基准测试的系统性评估
MindWatcher:迈向更智能的多模态工具融合推理
熵自适应微调:通过解决自信冲突以缓解遗忘
多样性还是精确性?深入探究下一个token预测
MHLA:通过Token级多头机制恢复线性注意力的表达能力
GlimpRouter:通过窥视一个思维token实现高效协同推理
X-Coder:基于全合成任务、解法与测试的竞赛编程新范式
PaCoRe:通过并行协同推理学习在测试时扩展计算资源
BabyVision:超越语言的视觉推理
观看、推理与搜索:面向智能体视频推理的开放网络视频深度研究基准
通过可扩展查找实现的条件记忆:大型语言模型稀疏性的一个新维度
EnvScaler:通过程序化合成实现LLM Agent的工具交互环境扩展
证据链构建:基于引用感知评分奖励的深度搜索Agent鲁棒强化学习
卡通化GS:基于高斯曲率的3D高斯溅射人脸夸张方法
思维的分子结构:长链思维推理拓扑结构的映射
MMFormalizer:开放环境中的多模态自动形式化
基于地图的思维:用于地理定位的强化并行地图增强型Agent
打破有向单源最短路径的排序障碍
GR-Dexter 技术报告
VideoAuto-R1:通过一次思考,两次作答实现视频自动推理
RelayLLM:通过协作解码实现高效推理
基于FusionRoute的Token级LLM协作
RL-AWB:基于深度强化学习的低光照夜间场景自动白平衡校正
可学习的缩放因子:释放语言模型矩阵层的规模限制
GDPO:面向多奖励强化学习优化的分组奖励解耦归一化策略优化
MemRL:通过情景记忆上的运行时强化学习实现自我演化的Agent
从失败到精通:为Tool-use Agents生成困难样本
编排一个动态物体的世界
Klear:统一的多任务音视频联合生成
Atlas:面向多领域复杂推理的异构模型与工具编排
Benchmark^2:LLM基准测试的系统性评估
MindWatcher:迈向更智能的多模态工具融合推理
熵自适应微调:通过解决自信冲突以缓解遗忘
多样性还是精确性?深入探究下一个token预测