HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

用于概率天气预报的滚动扩散模型阐释

图像搜索:超越语义依赖约束的视频生成自适应测试时搜索



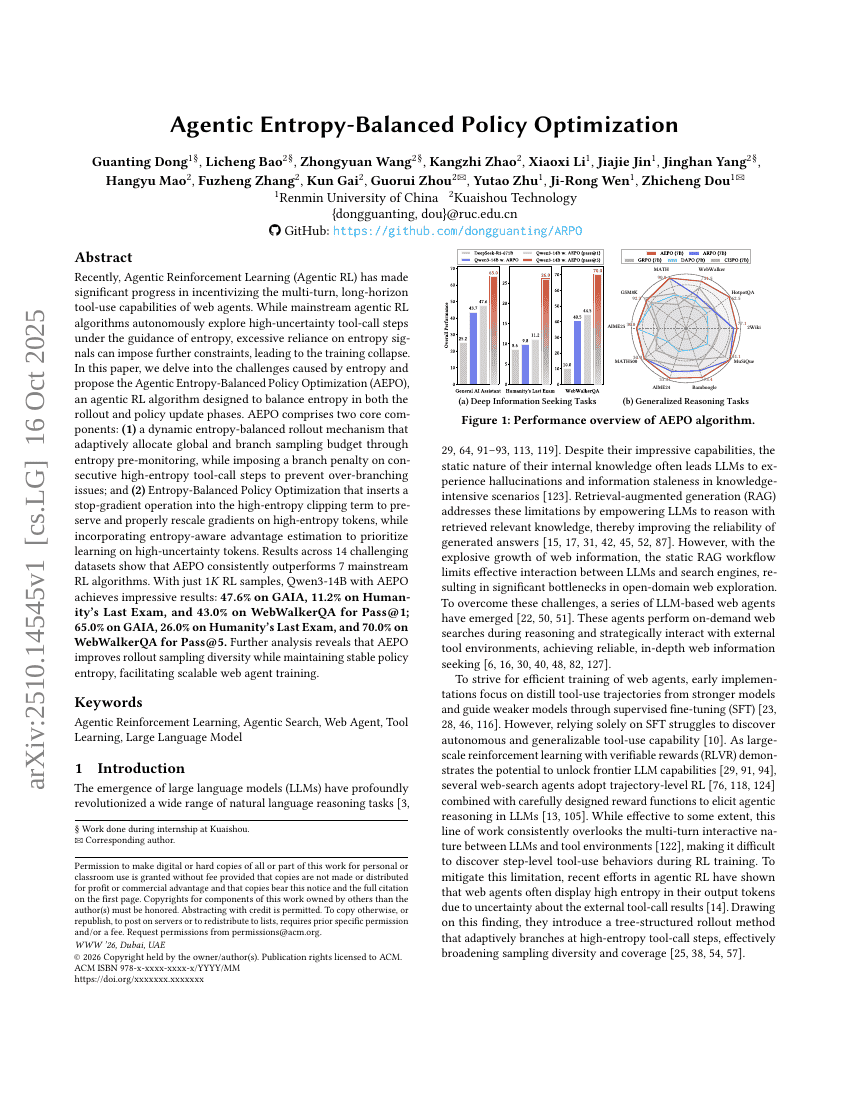













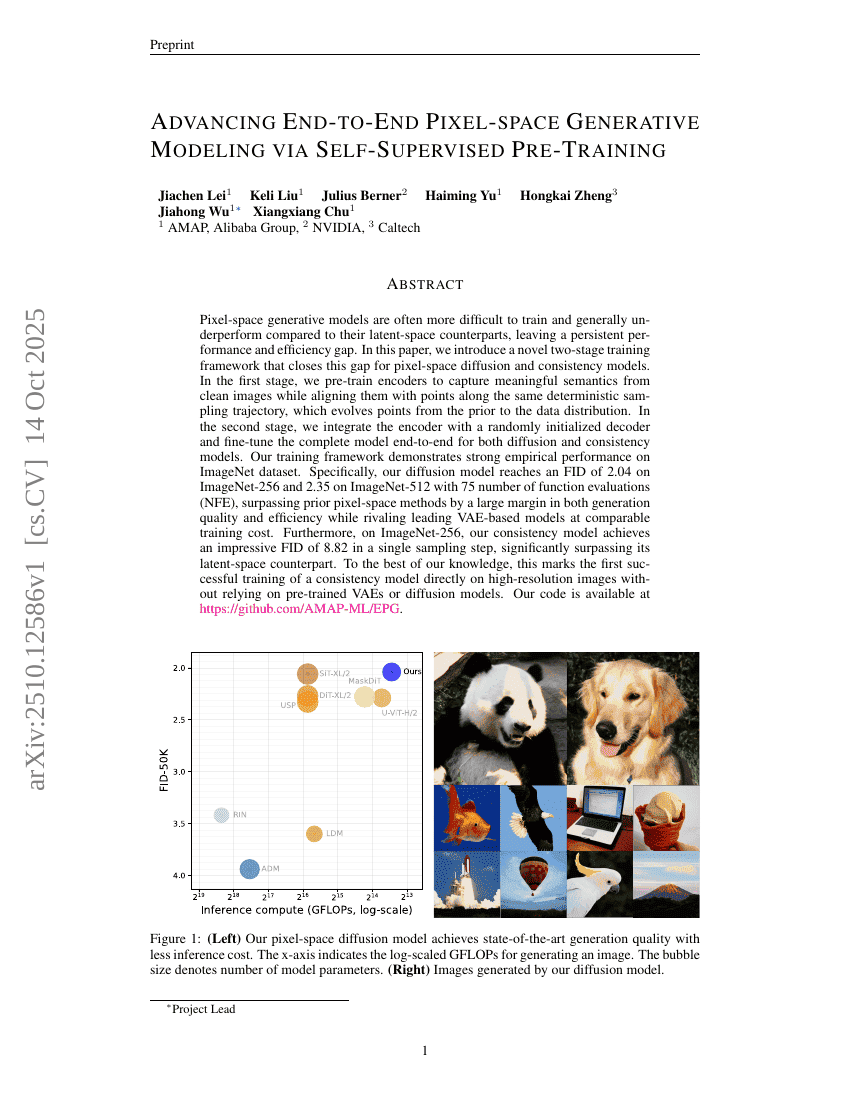



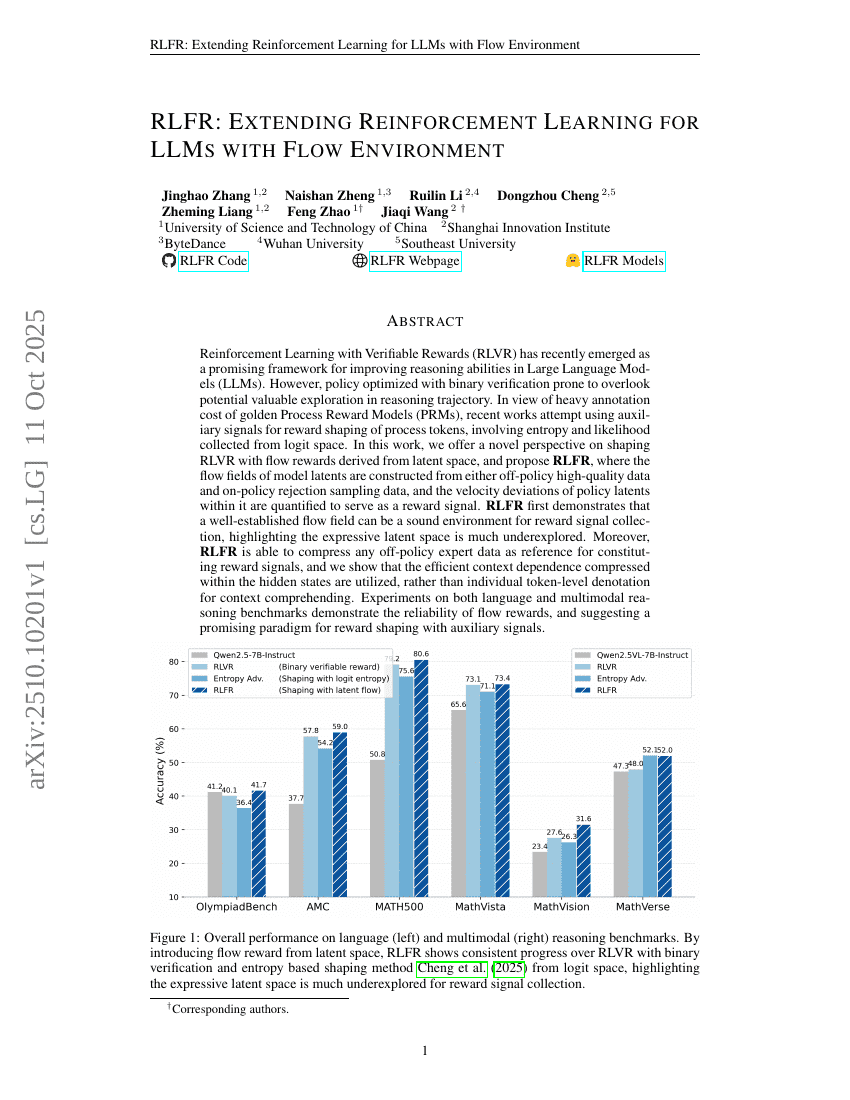




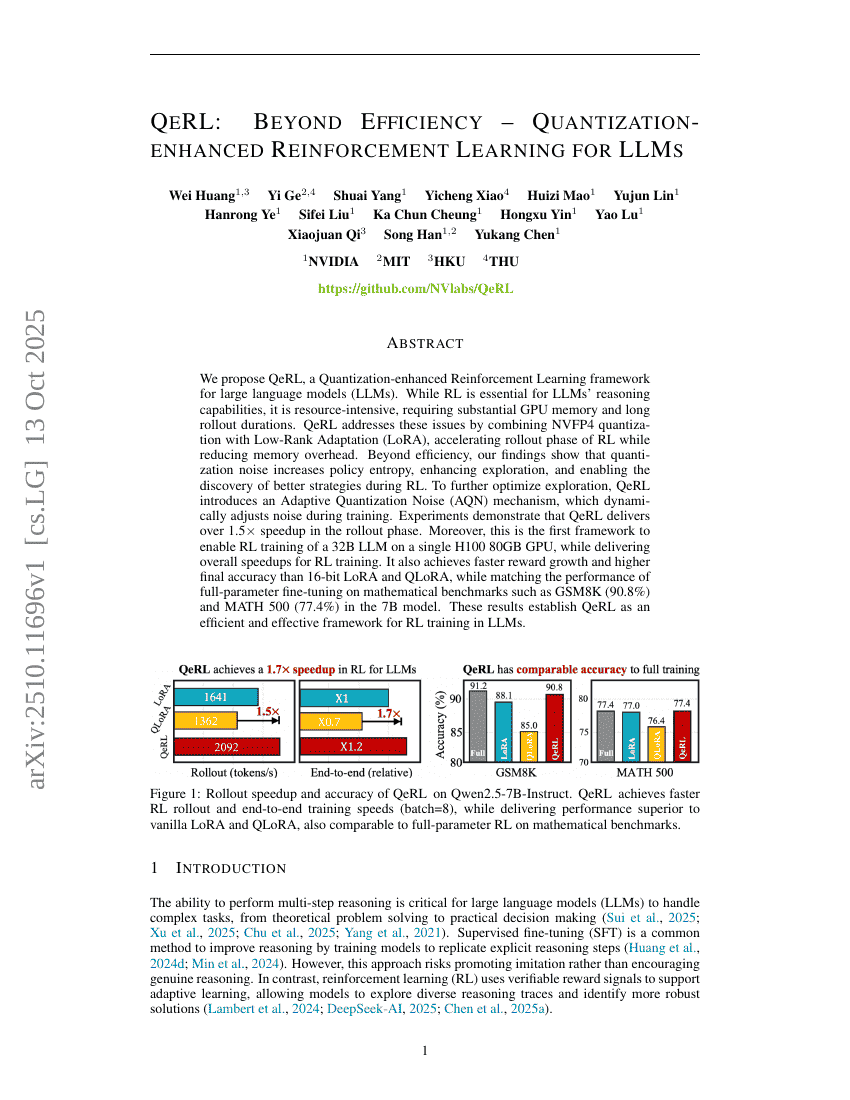

用于概率天气预报的滚动扩散模型阐释
图像搜索:超越语义依赖约束的视频生成自适应测试时搜索
从像素到文字——迈向大规模原生视觉-语言原子单元
面向服务的AI:通过AI眼镜实现主动辅助
WithAnyone:迈向可控且ID一致的图像生成
代理熵平衡策略优化
当模型说谎时,我们得以学习:基于PsiloQA的多语言跨度级幻觉检测
基于深度学习预测多模板PCR中的序列特异性扩增效率
基因组分析工具:一种用于分析下一代DNA测序数据的MapReduce框架
LAMMPS - 一种用于原子、介观和连续尺度下基于粒子材料建模的灵活模拟工具
LabOS:能够感知并协同人类的AI-XR共科研人员
海豚:基于异构锚点提示的文档图像解析
LiveCC:基于大规模流式语音转录学习视频LLM
DeepMMSearch-R1:赋能多模态LLM在多模态网络搜索中的应用
用于下一代单细胞分析的大型语言模型扩展
基于大语言模型的氛围编码综述
通过下一位置预测检测任何内容
面向语言中心的多模态表征学习的扩展
DITING:用于基准测试网络小说翻译的多Agent评估框架
通过自监督预训练推进端到端像素空间生成建模
空间强制:面向视觉-语言-动作模型的隐式空间表征对齐
基于大型语言模型的偏好获取中的澄清性问题提问
CTRL-Rec:通过自然语言控制推荐系统
RLFR:通过流环境扩展用于LLM的强化学习
潜在精炼解码:通过精炼信念状态增强基于扩散的LLM
OmniVideoBench:面向全景多模态大模型的音视频理解评估
BEAR:面向原子化具身能力的多模态语言模型基准测试与增强
具有表示自编码器的扩散Transformer
QeRL:超越效率——面向LLMs的量化增强型强化学习
无需反向传播的威尔逊环:一种用于检测不变性与顺序敏感性的实用诊断方法
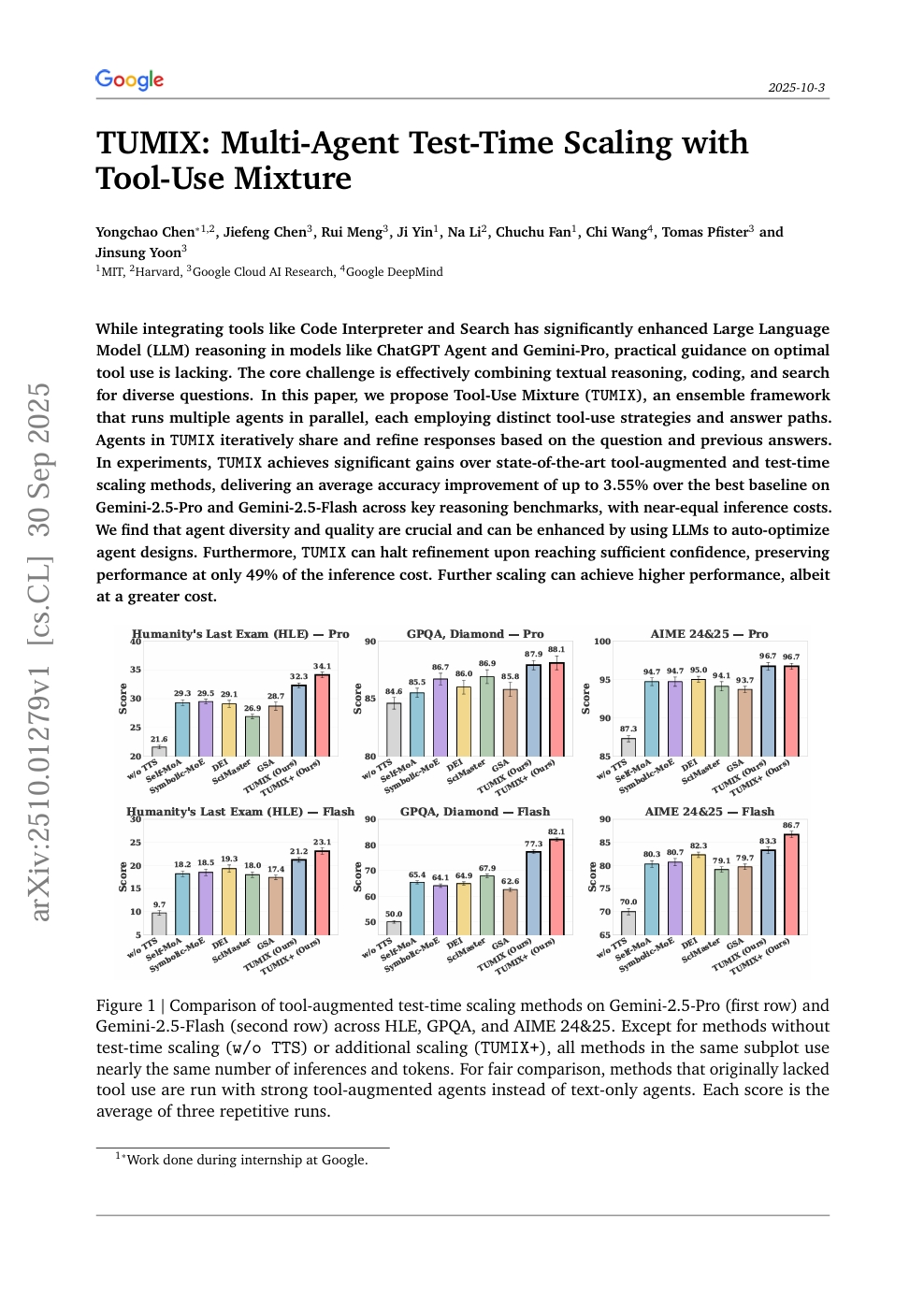
TUMIX:带有工具使用混合的多Agent测试时扩展
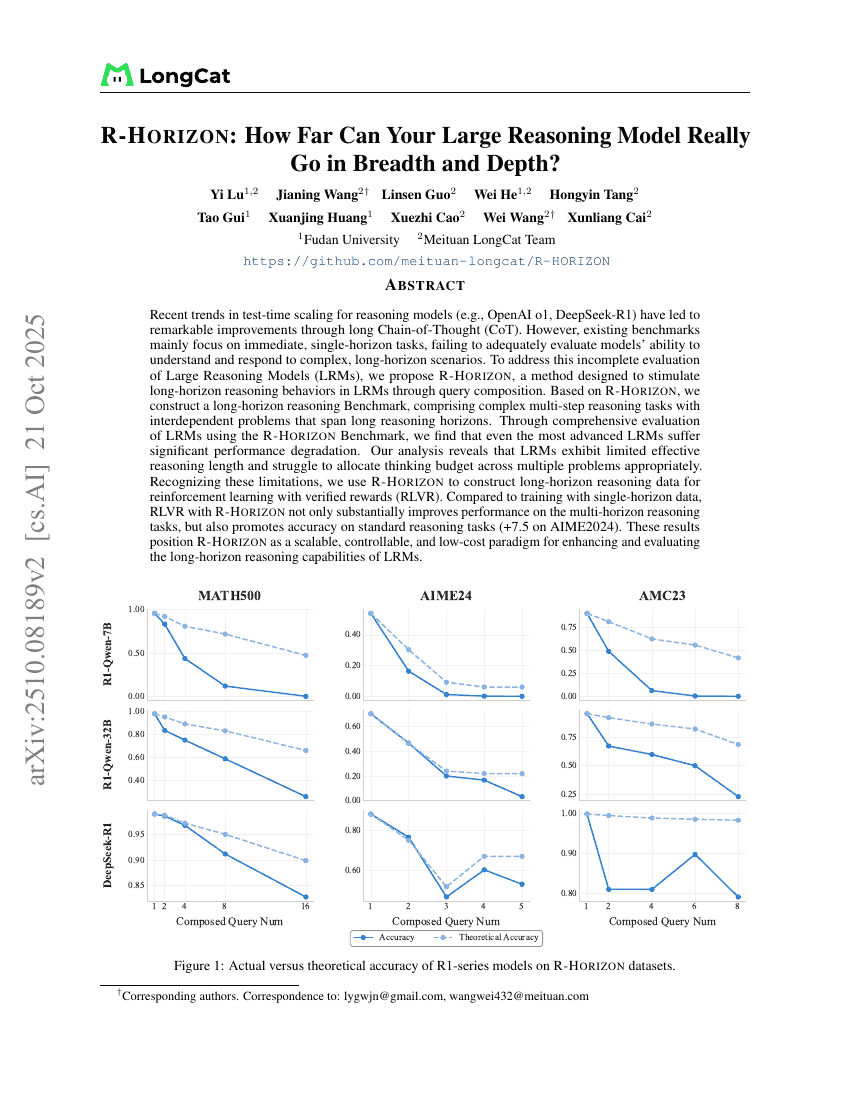
R-Horizon:你的大型推理模型在广度与深度上究竟能走多远?
从像素到文字——迈向大规模原生视觉-语言原子单元
面向服务的AI:通过AI眼镜实现主动辅助
WithAnyone:迈向可控且ID一致的图像生成
代理熵平衡策略优化
当模型说谎时,我们得以学习:基于PsiloQA的多语言跨度级幻觉检测
基于深度学习预测多模板PCR中的序列特异性扩增效率
基因组分析工具:一种用于分析下一代DNA测序数据的MapReduce框架
LAMMPS - 一种用于原子、介观和连续尺度下基于粒子材料建模的灵活模拟工具
LabOS:能够感知并协同人类的AI-XR共科研人员
海豚:基于异构锚点提示的文档图像解析
LiveCC:基于大规模流式语音转录学习视频LLM
DeepMMSearch-R1:赋能多模态LLM在多模态网络搜索中的应用
用于下一代单细胞分析的大型语言模型扩展
基于大语言模型的氛围编码综述
通过下一位置预测检测任何内容
面向语言中心的多模态表征学习的扩展
DITING:用于基准测试网络小说翻译的多Agent评估框架
通过自监督预训练推进端到端像素空间生成建模
空间强制:面向视觉-语言-动作模型的隐式空间表征对齐
基于大型语言模型的偏好获取中的澄清性问题提问
CTRL-Rec:通过自然语言控制推荐系统
RLFR:通过流环境扩展用于LLM的强化学习
潜在精炼解码:通过精炼信念状态增强基于扩散的LLM
OmniVideoBench:面向全景多模态大模型的音视频理解评估
BEAR:面向原子化具身能力的多模态语言模型基准测试与增强
具有表示自编码器的扩散Transformer
QeRL:超越效率——面向LLMs的量化增强型强化学习
无需反向传播的威尔逊环:一种用于检测不变性与顺序敏感性的实用诊断方法
TUMIX:带有工具使用混合的多Agent测试时扩展
R-Horizon:你的大型推理模型在广度与深度上究竟能走多远?