HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

CostBench:评估LLM工具使用Agent在动态环境中多轮成本最优规划与适应性

寒武纪-S:迈向视频中的空间超感知

























CostBench:评估LLM工具使用Agent在动态环境中多轮成本最优规划与适应性
寒武纪-S:迈向视频中的空间超感知
通过经验合成实现Agent学习的扩展
V-Thinker:与图像交互的思考
基于视频的思考:视频生成作为一种有前景的多模态推理范式
Amber生物分子模拟的最新进展
UltraHR-100K:基于大规模高质量数据集增强UHR图像合成
从五个维度到众多维度:大型语言模型作为精准且可解释的心理画像工具
基于节点的多模态生成:文本、音频、图像与视频
DR. WELL:基于符号世界模型的具身LLM多Agent协作中的动态推理与学习
Orion-MSP:用于表格上下文学习的多尺度稀疏注意力
TabTune:用于表格基础模型推理与微调的统一库
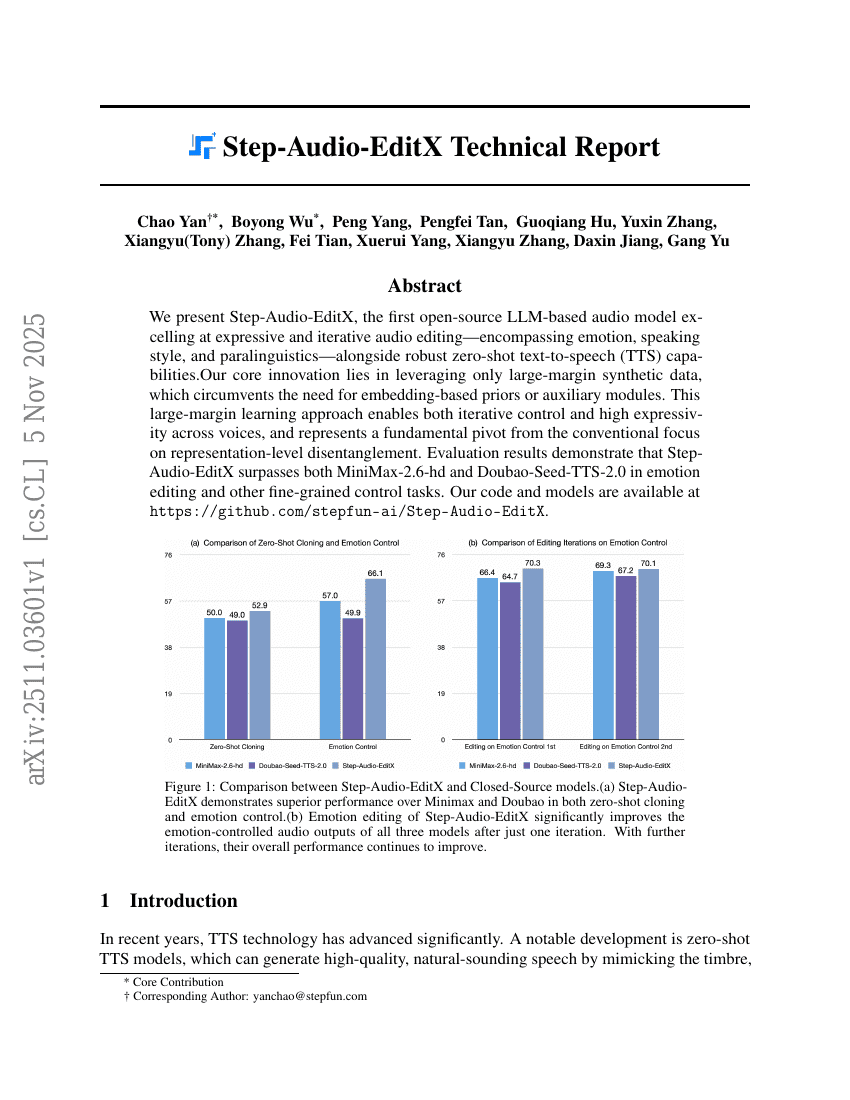
Step-Audio-EditX 技术报告
LEGO-Eval:面向通过工具增强合成3D具身环境的细粒度评估
UniAVGen:具有非对称跨模态交互的统一音频与视频生成
扩散语言模型是超数据学习者
UNO-Bench:一个用于探索Omni模型中单模态与全模态之间组合规律的统一基准
基于扩散模型的动态人口分布感知人类轨迹生成
基于3D生成式AI与视觉语言模型的文本到机器人多组件物体装配
Kosmos:用于自主发现的AI Scientist
更短但不更差:通过简单样本作为长度正则化项实现数学领域的节俭推理RLVR
Brain-IT:通过Brain-Interaction Transformer从fMRI进行图像重建
模态冲突时:单模态推理不确定性如何主导MLLMs中的偏好动态
不要盲视你的VLA:面向OOD泛化的视觉表征对齐
当可视化成为推理的第一步时:MIRA,一个用于视觉链式思维的基准测试
VCode:一个以SVG作为符号化视觉表示的多模态编码基准
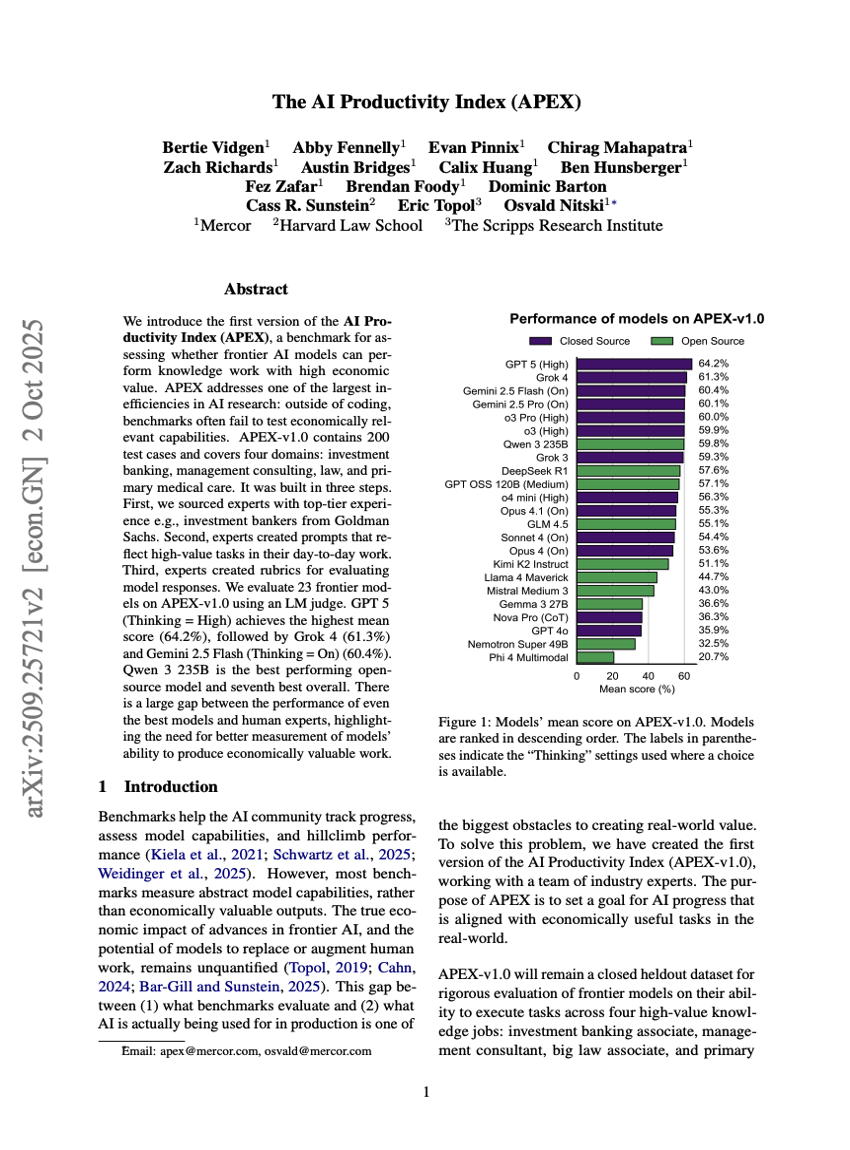
人工智能生产力指数(APEX)
帧链:通过帧感知推理推进多模态LLM中的视频理解
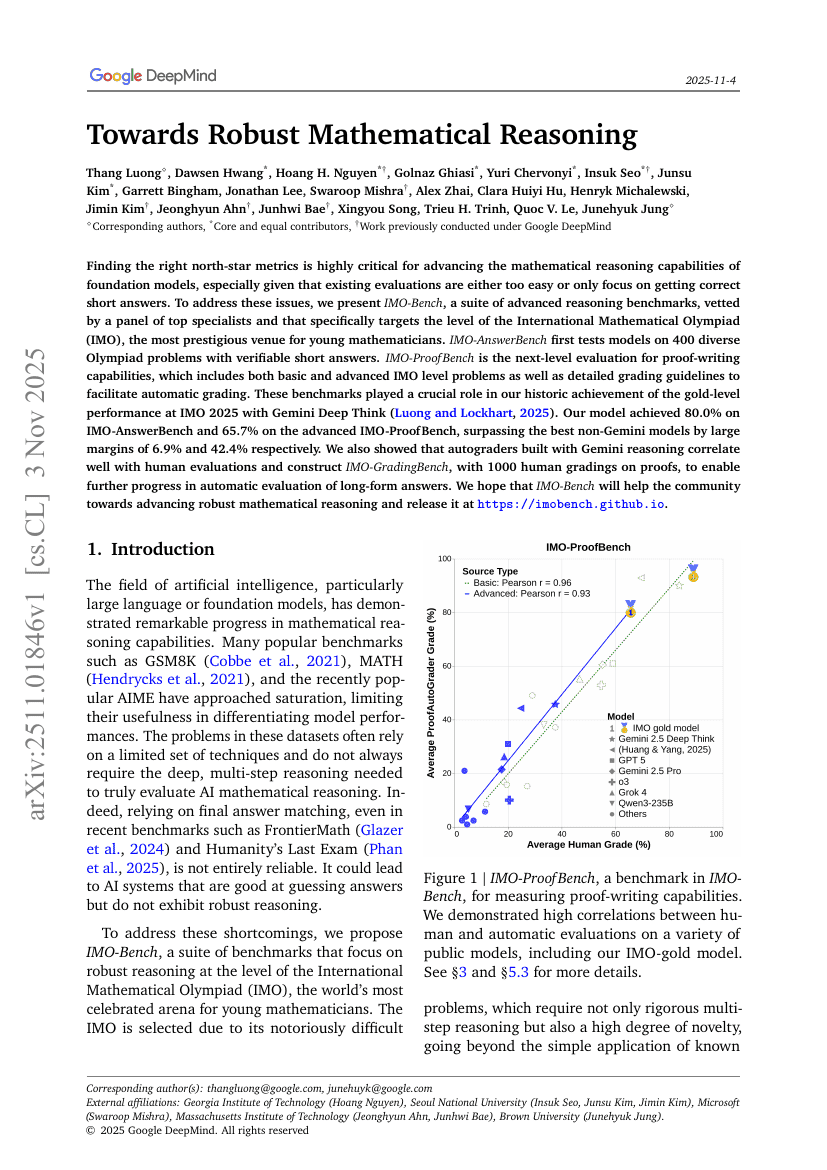
面向鲁棒的数学推理
面向未来基于空间的、高度可扩展的人工智能基础设施系统设计
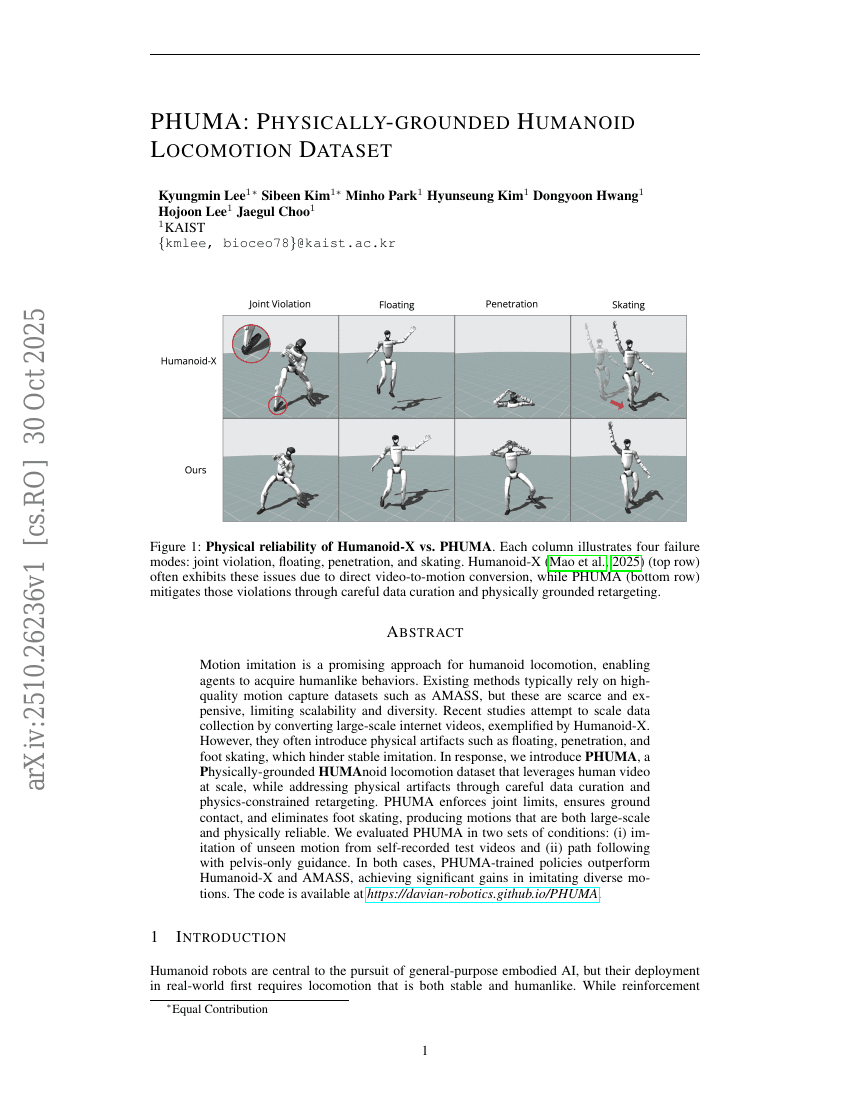
PHUMA:物理基础的人形行走数据集
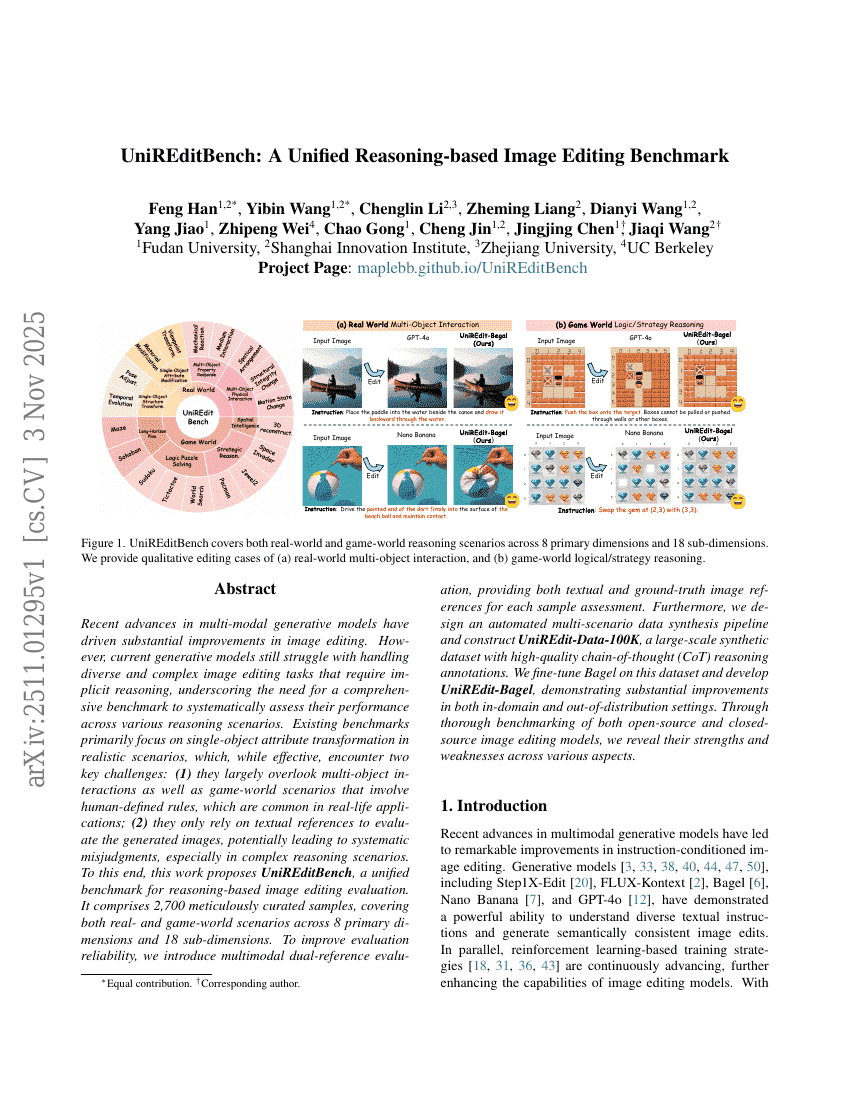
UniREditBench:一个统一的基于推理的图像编辑基准
通过经验合成实现Agent学习的扩展
V-Thinker:与图像交互的思考
基于视频的思考:视频生成作为一种有前景的多模态推理范式
Amber生物分子模拟的最新进展
UltraHR-100K:基于大规模高质量数据集增强UHR图像合成
从五个维度到众多维度:大型语言模型作为精准且可解释的心理画像工具
基于节点的多模态生成:文本、音频、图像与视频
DR. WELL:基于符号世界模型的具身LLM多Agent协作中的动态推理与学习
Orion-MSP:用于表格上下文学习的多尺度稀疏注意力
TabTune:用于表格基础模型推理与微调的统一库
Step-Audio-EditX 技术报告
LEGO-Eval:面向通过工具增强合成3D具身环境的细粒度评估
UniAVGen:具有非对称跨模态交互的统一音频与视频生成
扩散语言模型是超数据学习者
UNO-Bench:一个用于探索Omni模型中单模态与全模态之间组合规律的统一基准
基于扩散模型的动态人口分布感知人类轨迹生成
基于3D生成式AI与视觉语言模型的文本到机器人多组件物体装配
Kosmos:用于自主发现的AI Scientist
更短但不更差:通过简单样本作为长度正则化项实现数学领域的节俭推理RLVR
Brain-IT:通过Brain-Interaction Transformer从fMRI进行图像重建
模态冲突时:单模态推理不确定性如何主导MLLMs中的偏好动态
不要盲视你的VLA:面向OOD泛化的视觉表征对齐
当可视化成为推理的第一步时:MIRA,一个用于视觉链式思维的基准测试
VCode:一个以SVG作为符号化视觉表示的多模态编码基准
人工智能生产力指数(APEX)
帧链:通过帧感知推理推进多模态LLM中的视频理解
面向鲁棒的数学推理
面向未来基于空间的、高度可扩展的人工智能基础设施系统设计
PHUMA:物理基础的人形行走数据集
UniREditBench:一个统一的基于推理的图像编辑基准