HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

首帧是视频内容定制的首选之地

基于多模态基础模型的时空智能扩展

























首帧是视频内容定制的首选之地
基于多模态基础模型的时空智能扩展
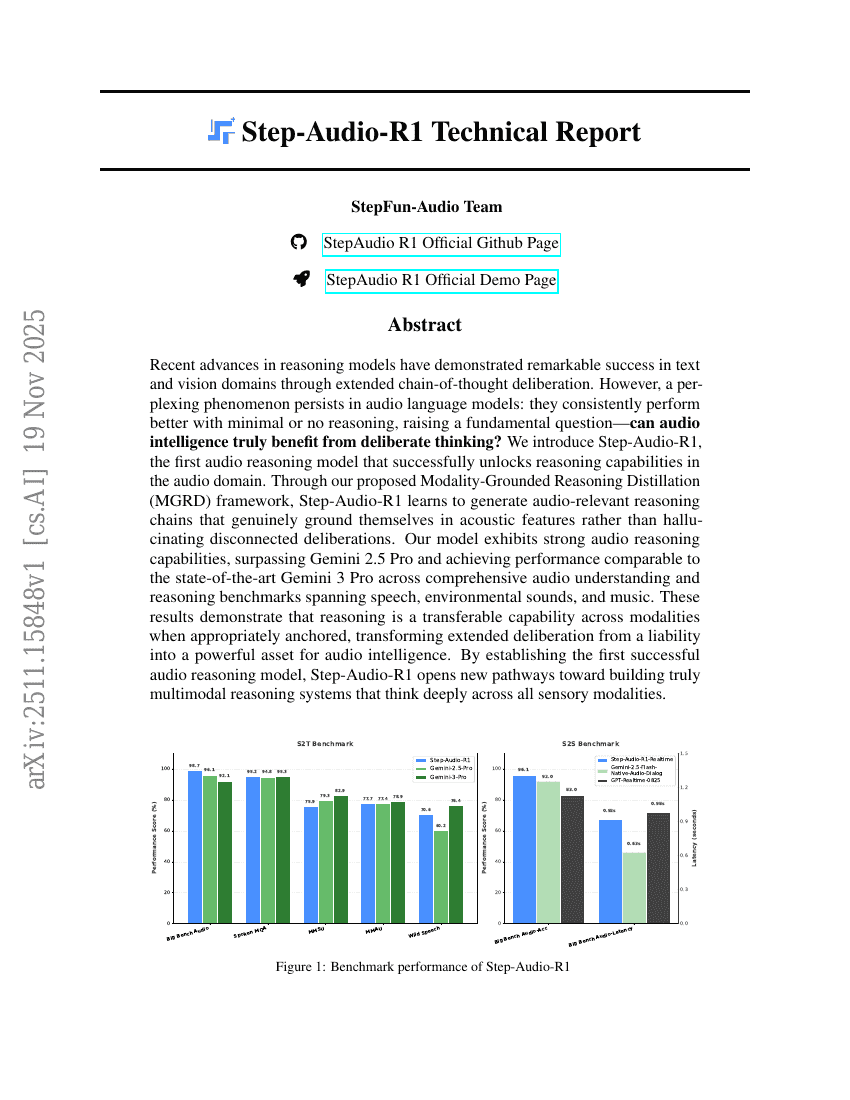
Step-Audio-R1 技术报告
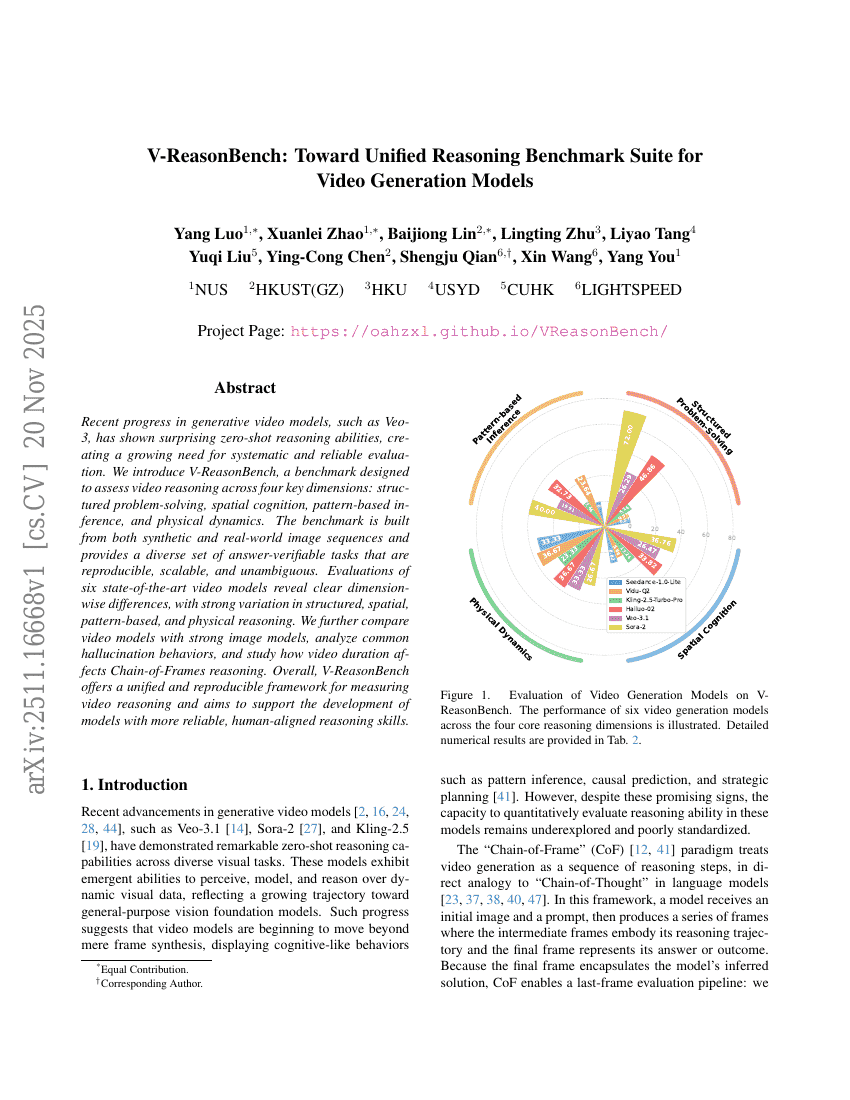
V-ReasonBench:面向视频生成模型的统一推理基准测试套件
Olmo 3
GPT-5的早期科学加速实验
迈向人工智能在医学影像中偏见的客观、系统评估
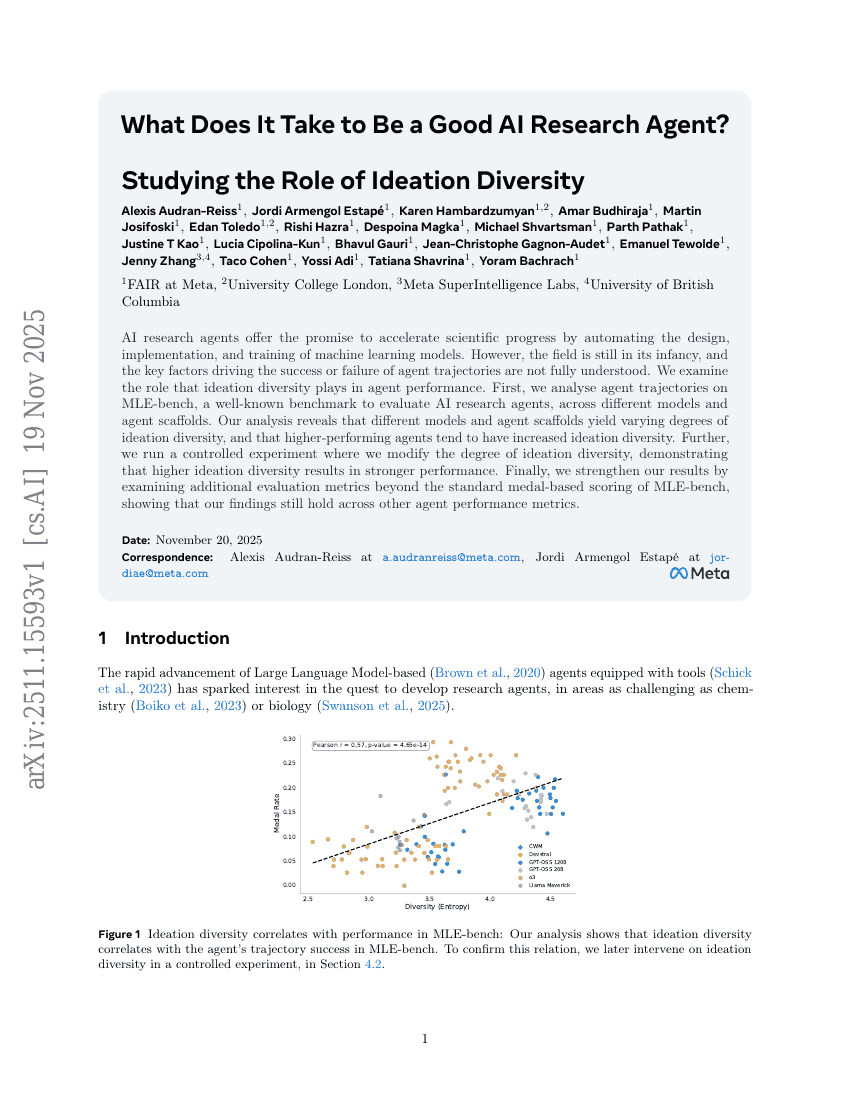
成为优秀的AI研究Agent需要什么?——探究创意多样性的作用
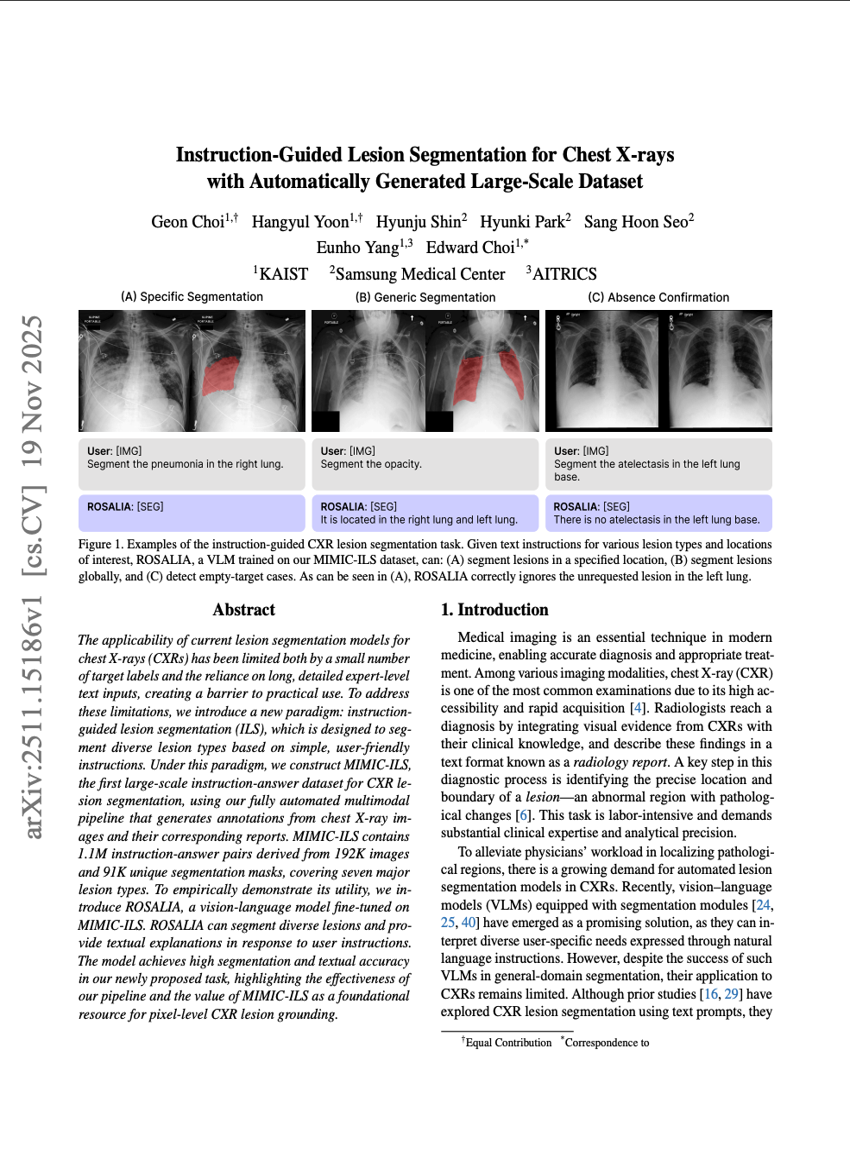
指令引导的胸部X光图像病灶分割方法及其自动构建的大规模数据集
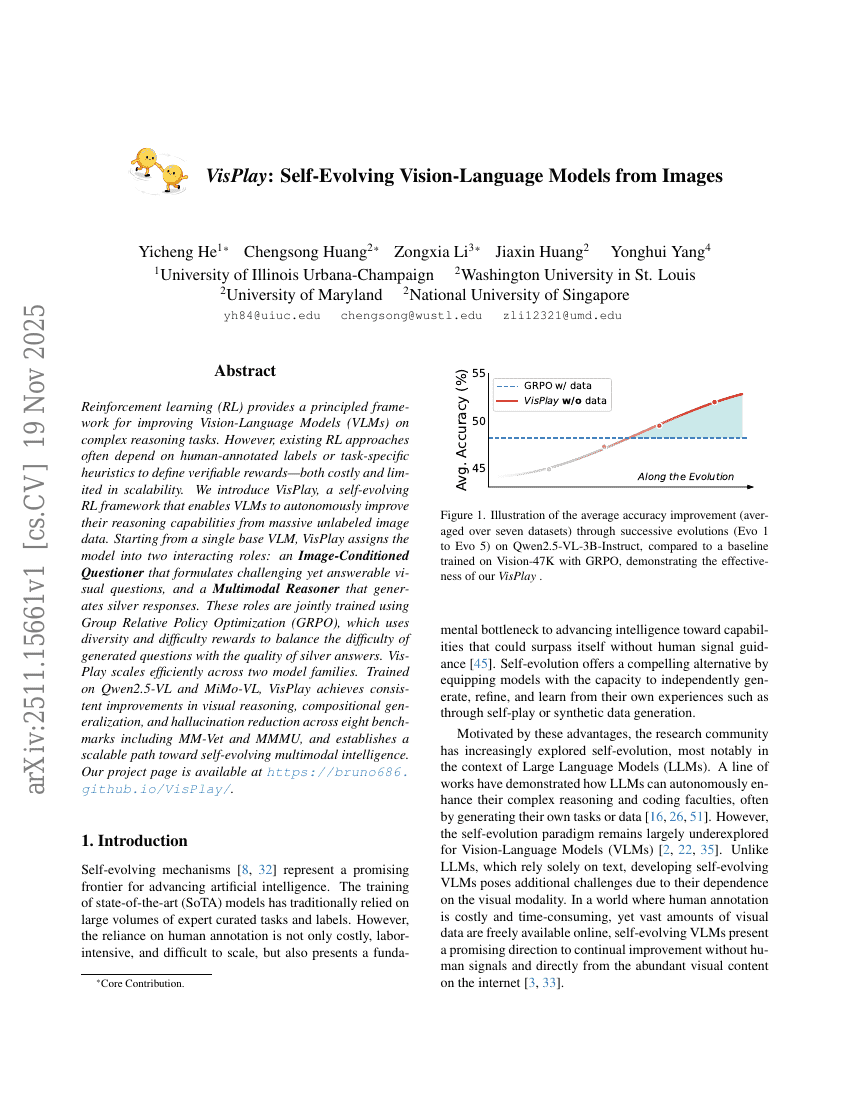
VisPlay:从图像中自演化视觉-语言模型
通过视频进行推理:首个基于迷宫求解任务对视频模型推理能力的评估
VIDEOP2R:从感知到推理的视频理解
Kandinsky 5.0:面向图像与视频生成的基础模型家族
JAM-2:具有高成功率的类药物抗体的全计算设计
PathMind:一种基于大型语言模型的知识图谱推理的检索-优先级排序-推理框架
审稿人:超越文本反思,迈向长视频理解中的多模态内省推理
MVI-Bench:面向低视觉语言模型中误导性视觉输入鲁棒性评估的综合性基准
世界模拟器能进行推理吗?Gen-ViRe:一个生成式视觉推理基准
一种风格胜过一行代码:通过离散风格空间实现代码到风格图像的生成
AraLingBench:用于评估大型语言模型阿拉伯语语言能力的人工标注基准
Think-at-Hard:通过选择性潜在迭代提升推理型语言模型
HumanSense:从多模态感知到通过推理实现共情的上下文感知响应的MLLMs
CamCloneMaster:实现基于参考的相机控制用于视频生成
EditScore:通过高保真奖励建模解锁图像编辑中的在线RL
InteractMove:基于文本控制的3D场景中可移动物体的人-物交互生成
WebCoach:具有跨会话记忆引导的自演化Web Agent
信任的学习:在序列决策中对不同建议者可靠性进行贝叶斯自适应
GroupRank:一种由强化学习驱动的分组重排序范式
MMaDA-Parallel:面向思维感知编辑与生成的多模态大扩散语言模型
TiViBench:面向视频生成模型的视频思维推理基准测试
Part-X-MLLM:面向部件感知的3D多模态大语言模型
Uni-MoE-2.0-Omni:基于先进MoE、训练与数据的面向语言中心的全模态大模型扩展
Step-Audio-R1 技术报告
V-ReasonBench:面向视频生成模型的统一推理基准测试套件
Olmo 3
GPT-5的早期科学加速实验
迈向人工智能在医学影像中偏见的客观、系统评估
成为优秀的AI研究Agent需要什么?——探究创意多样性的作用
指令引导的胸部X光图像病灶分割方法及其自动构建的大规模数据集
VisPlay:从图像中自演化视觉-语言模型
通过视频进行推理:首个基于迷宫求解任务对视频模型推理能力的评估
VIDEOP2R:从感知到推理的视频理解
Kandinsky 5.0:面向图像与视频生成的基础模型家族
JAM-2:具有高成功率的类药物抗体的全计算设计
PathMind:一种基于大型语言模型的知识图谱推理的检索-优先级排序-推理框架
审稿人:超越文本反思,迈向长视频理解中的多模态内省推理
MVI-Bench:面向低视觉语言模型中误导性视觉输入鲁棒性评估的综合性基准
世界模拟器能进行推理吗?Gen-ViRe:一个生成式视觉推理基准
一种风格胜过一行代码:通过离散风格空间实现代码到风格图像的生成
AraLingBench:用于评估大型语言模型阿拉伯语语言能力的人工标注基准
Think-at-Hard:通过选择性潜在迭代提升推理型语言模型
HumanSense:从多模态感知到通过推理实现共情的上下文感知响应的MLLMs
CamCloneMaster:实现基于参考的相机控制用于视频生成
EditScore:通过高保真奖励建模解锁图像编辑中的在线RL
InteractMove:基于文本控制的3D场景中可移动物体的人-物交互生成
WebCoach:具有跨会话记忆引导的自演化Web Agent
信任的学习:在序列决策中对不同建议者可靠性进行贝叶斯自适应
GroupRank:一种由强化学习驱动的分组重排序范式
MMaDA-Parallel:面向思维感知编辑与生成的多模态大扩散语言模型
TiViBench:面向视频生成模型的视频思维推理基准测试
Part-X-MLLM:面向部件感知的3D多模态大语言模型
Uni-MoE-2.0-Omni:基于先进MoE、训练与数据的面向语言中心的全模态大模型扩展