Command Palette
Search for a command to run...
Multimodal-Textbook-6.5M Multimodal Textbook Dataset
This dataset is a multimodal textbook dataset released by Alibaba DAMO Academy in 2025. The relevant paper results are:2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining", which aims to enhance multimodal pre-training and expand the model's ability to handle interleaved visual and textual inputs.
The dataset contains 6.5 million images and 800 million text data from teaching videos. All images and texts are extracted from online teaching videos (22,000 class hours), covering six basic subjects such as mathematics, physics, and chemistry, providing a more coherent background and richer knowledge for image-text alignment.
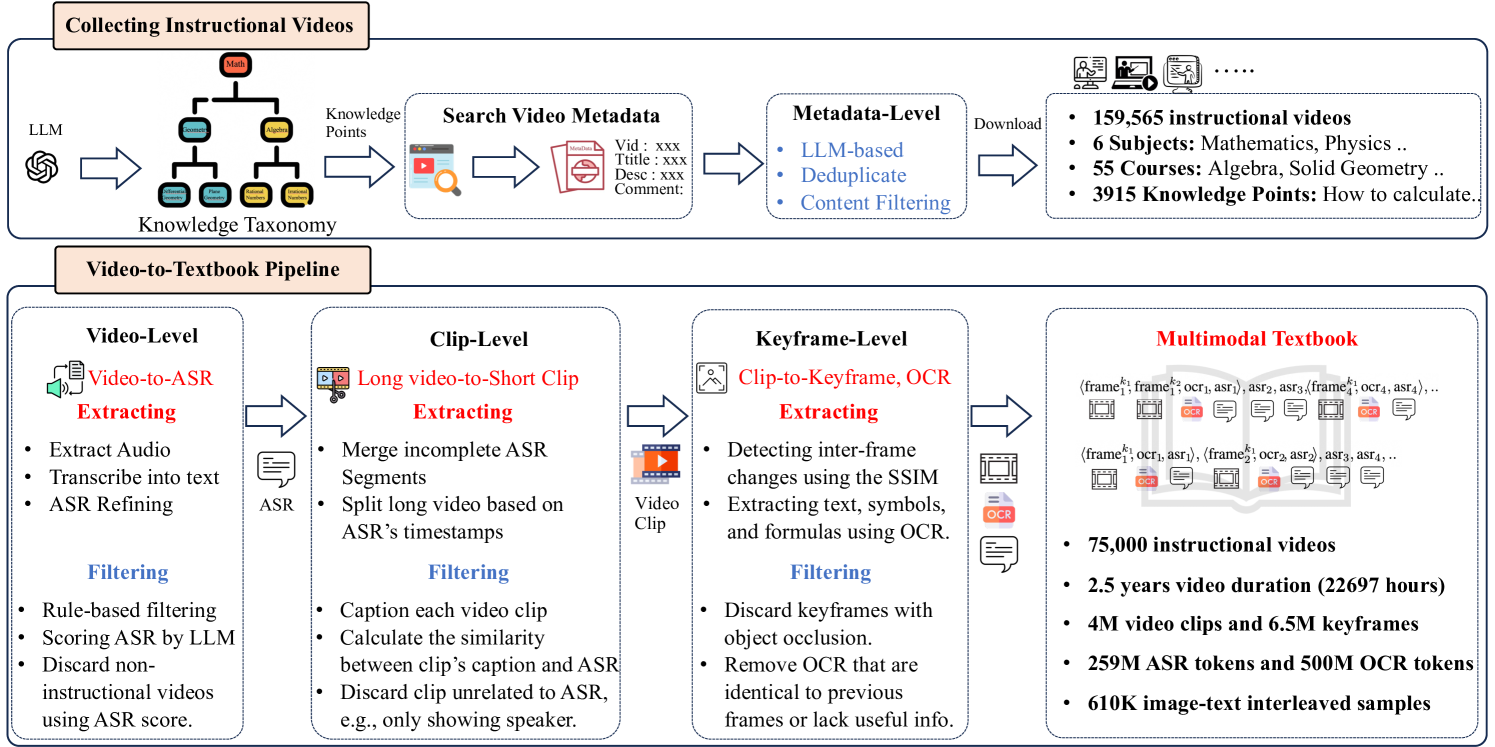 Example of building a dataset from a tutorial video
Example of building a dataset from a tutorial video
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.