Command Palette
Search for a command to run...
LoongBench multi-domain Reasoning Benchmark Dataset
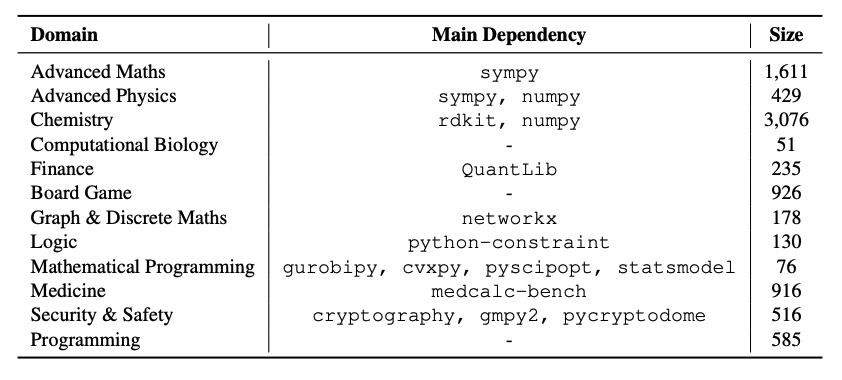
LoongBench is a multi-domain reasoning evaluation dataset released by the CAMEL-AI team in 2025. The related paper results are "Loong: Synthesize Long Chain-of-Thoughts at Scale through Verifiers", which aims to provide LLM with multi-domain, verifiable training and assessment resources. The dataset contains 8,729 questions expressed in natural language, covering 12 reasoning-intensive fields such as advanced mathematics, advanced physics, chemistry, computational biology, and programming. Each sample not only comes with executable code and verified answers, but also includes the problem statement, detailed reasoning process, final solution, as well as metadata (question ID and domain information) and domain labels. It is suitable for training and benchmarking cross-domain reasoning capabilities.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.