Command Palette
Search for a command to run...
WildSpeech-Bench Speech Understanding Generation Benchmark Dataset
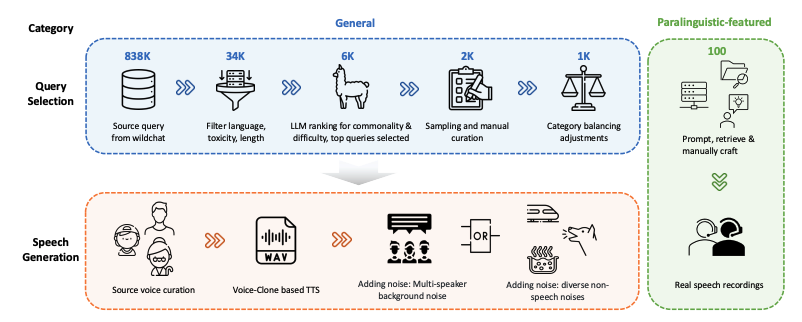
WildSpeech-Bench is the first benchmark for evaluating the speech-to-speech capabilities of SpeechLLM, released by Tencent in 2025. The related paper results are "WildSpeech-Bench: Benchmarking End-to-End SpeechLLMs in the Wild", which aims to measure the model's ability to understand and generate complete speech input to speech output (Speech-to-Speech, S2S) in real voice interaction scenarios. The dataset contains 1,100 queries across five main categories: information queries, solution requests, opinion exchanges, text creation, and paralinguistic expressions. Each category corresponds to a common user intent. 1,000 of these queries are from general voice interaction scenarios (including information queries, solution requests, opinion exchanges, and text creation), while another 100 are characterized by paralinguistic features such as pauses, intonation, stuttering, and near-phonetic word recognition. Each query is accompanied by diverse speech output examples, encompassing a wide range of speaker attributes (gender, age, voice variants), acoustic conditions, and noise environment settings, to more realistically simulate the diversity and challenges of natural voice interaction.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.