Command Palette
Search for a command to run...
Online Tutorial | WeChat AI Team Proposes WeDLM, a Diffusion Language Model That Achieves 3x Inference Speed Up for AR Model Deployment Compared to vLLM

In large-scale deployments and commercial applications, inference speed is becoming increasingly important, even surpassing the sheer number of model parameters in many cases, and becoming a key factor determining its engineering value. Although the autoregressive (AR) generation paradigm remains the mainstream decoding method due to its stability and mature ecosystem,However, its inherent mechanism of token-by-token generation makes it almost impossible for the model to fully utilize parallel computing resources during the inference phase.This limitation is particularly pronounced in scenarios involving long text generation, complex reasoning, and high-concurrency services, and it directly increases inference latency and computing costs.
To overcome this bottleneck, the research community has been continuously exploring parallel decoding paths in recent years.Among them, Diffusion Language Models (DLMs) are considered one of the most promising alternatives due to their characteristic of "generating multiple tokens per step".However, a significant gap remains between the ideal and reality: in real-world deployment environments, many DLLMs have failed to demonstrate the expected speed advantage, and even struggle to outperform highly optimized AR inference engines (such as vLLMs). The problem does not stem from parallelism itself, but rather from a deeper conflict hidden within the model structure and system level—Many existing diffusion methods rely on bidirectional attention mechanisms, which undermines the efficiency cornerstone of modern inference systems—prefix key-value caching—and forces the model to repeatedly recalculate the context, thus negating the potential benefits of parallelism.
In this context,Tencent's WeChat AI team proposed WeDLM (WeChat Diffusion Language Model).This is the first diffusion language model to outperform comparable AR models in inference speed under industrial-grade inference engine (vLLM) optimization. Its core idea is to conditionalize each masked position to all currently observed tokens while maintaining strict causal masking. To this end, researchers introduced a topological reordering method, moving observed tokens to physical prefix regions without changing their logical positions.
Experimental results show that WeDLM achieves significant inference acceleration while maintaining the quality of strong autoregressive backbone generation. Specifically, it achieves more than 3 times the speedup of AR models deployed by vLLM in tasks such as mathematical reasoning, and the inference efficiency in low-entropy scenarios is more than 10 times faster.
Currently, the "WeDLM High-Efficiency Large Language Model Decoding Framework" is available on the HyperAI website's "Tutorials" section. You can experience the online tutorials via the link below ⬇️
Online tutorials:
Open source address:
https://github.com/tencent/WeDLM
To help everyone better experience the online tutorials, HyperAI is also offering computing power benefits.New users can get 2 hours of NVIDIA GeForce RTX 5090 usage time by using the redemption code "WeDLM" after registration (the resource is valid for 1 month).Limited quantities available, grab yours now!
Demo Run
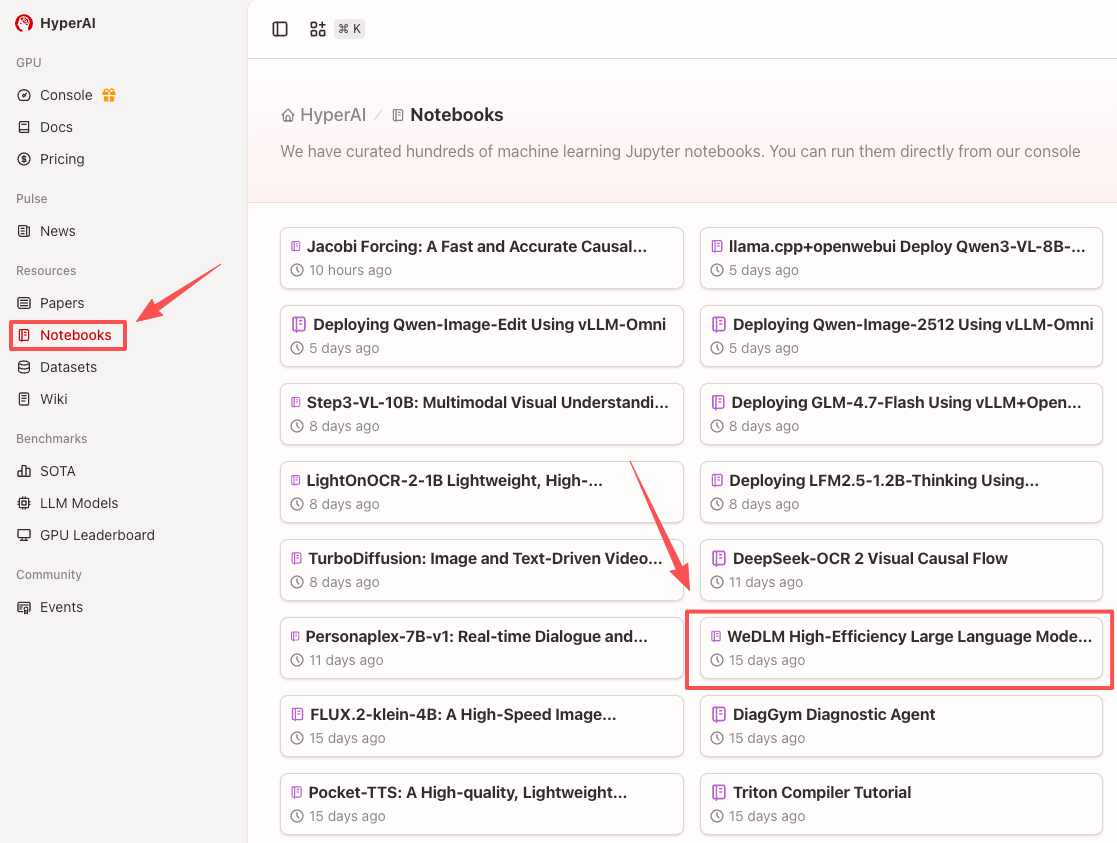
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "WeDLM High-Efficiency Large Language Model Decoding Framework", and click "Run this tutorial online".
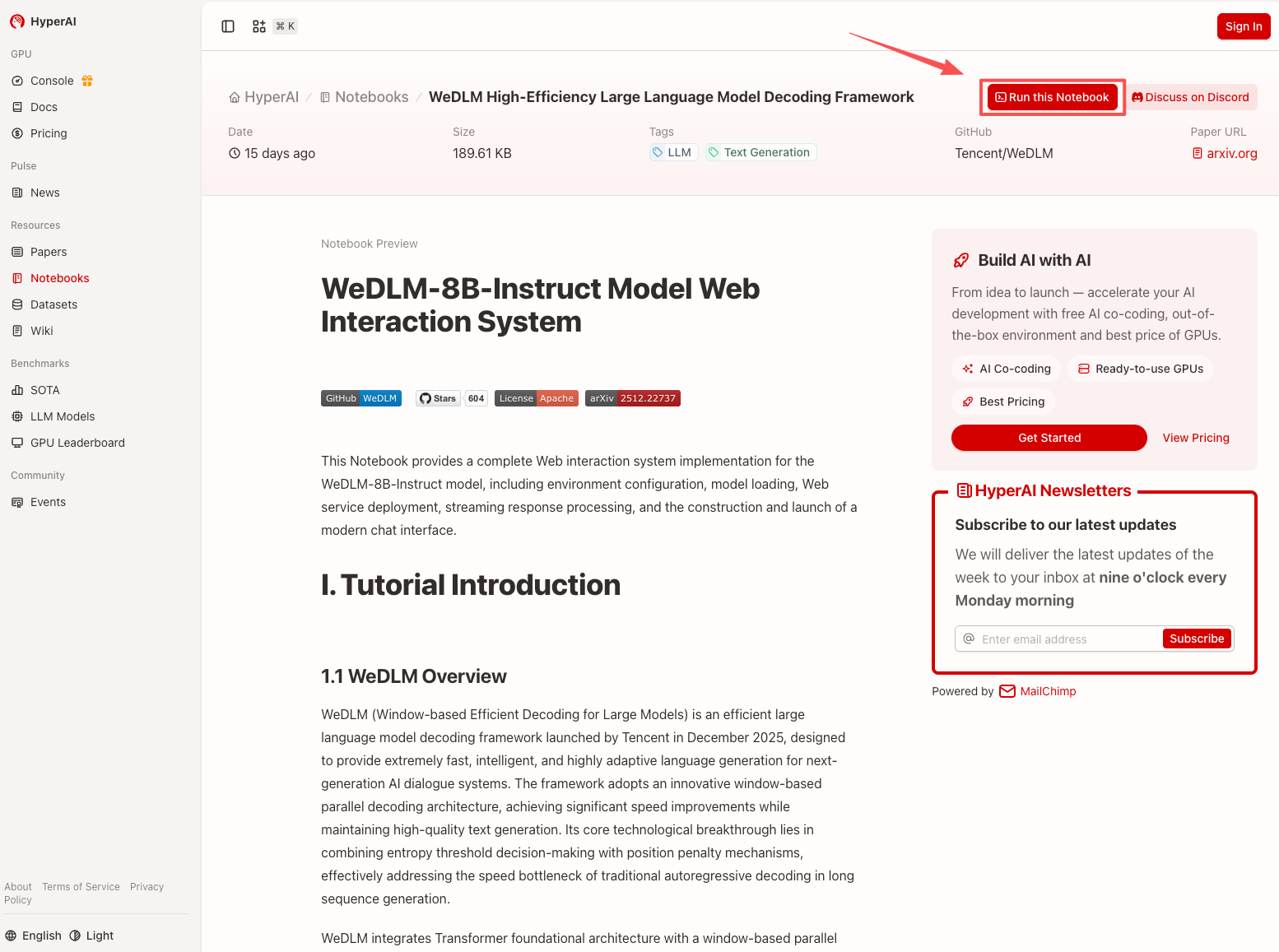
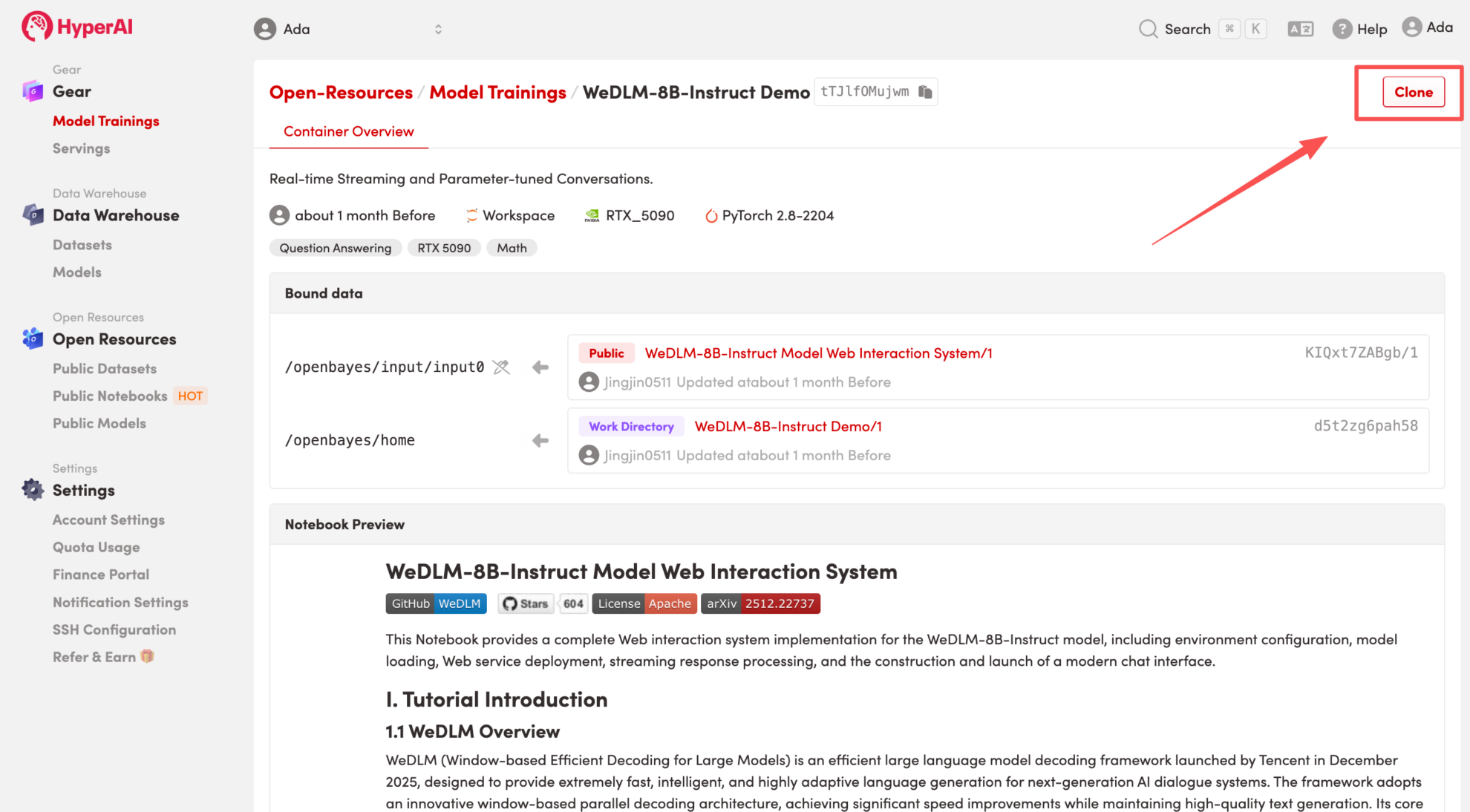
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
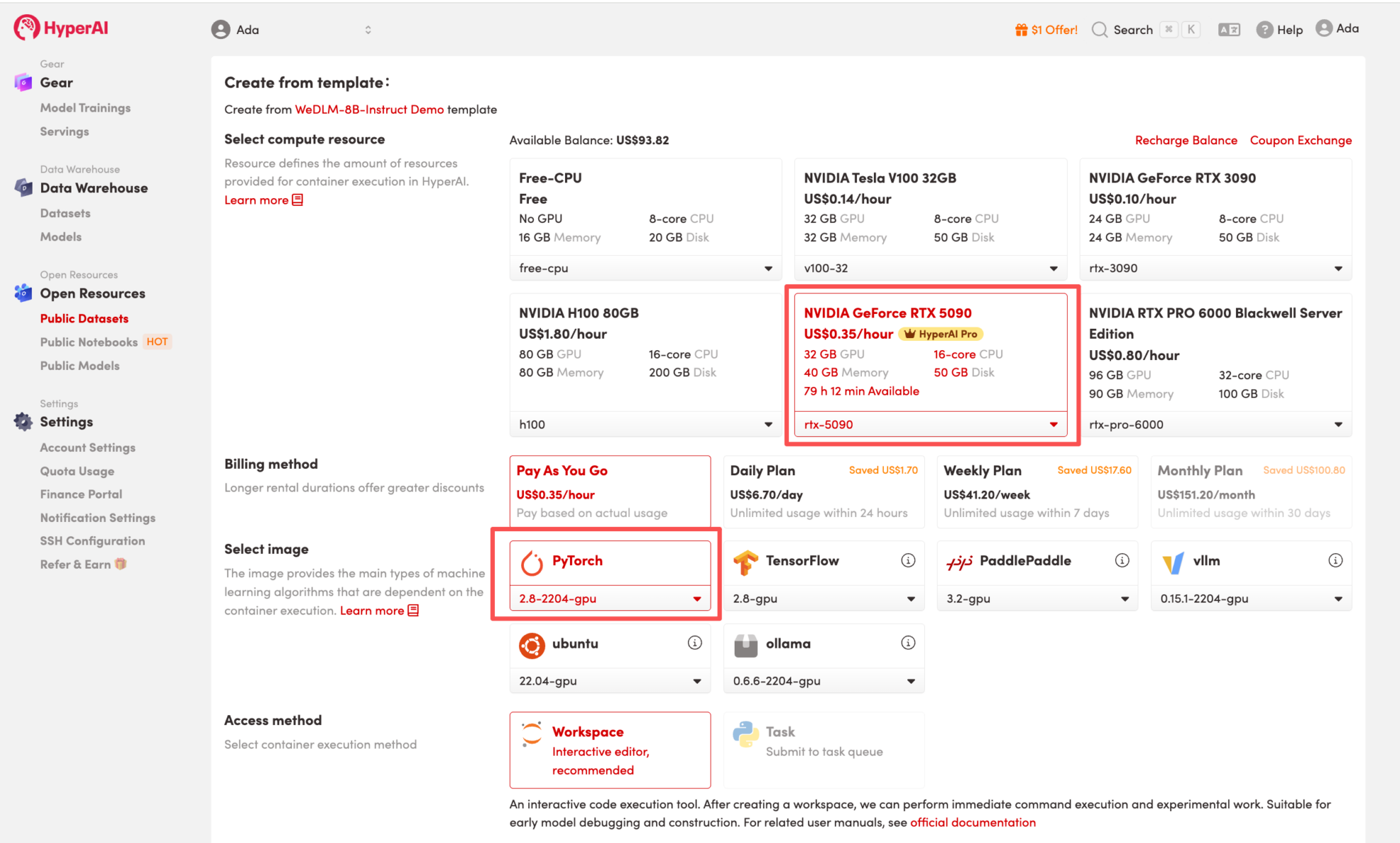
3. Select the "NVIDIA GeForce RTX 5090" and "PyTorch" images, and choose "Pay As You Go" or "Daily Plan/Weekly Plan/Monthly Plan" as needed, then click "Continue job execution".
HyperAI is offering registration benefits for new users.For just $1, you can get 20 hours of RTX 5090 computing power (original price $7).The resource is permanently valid.
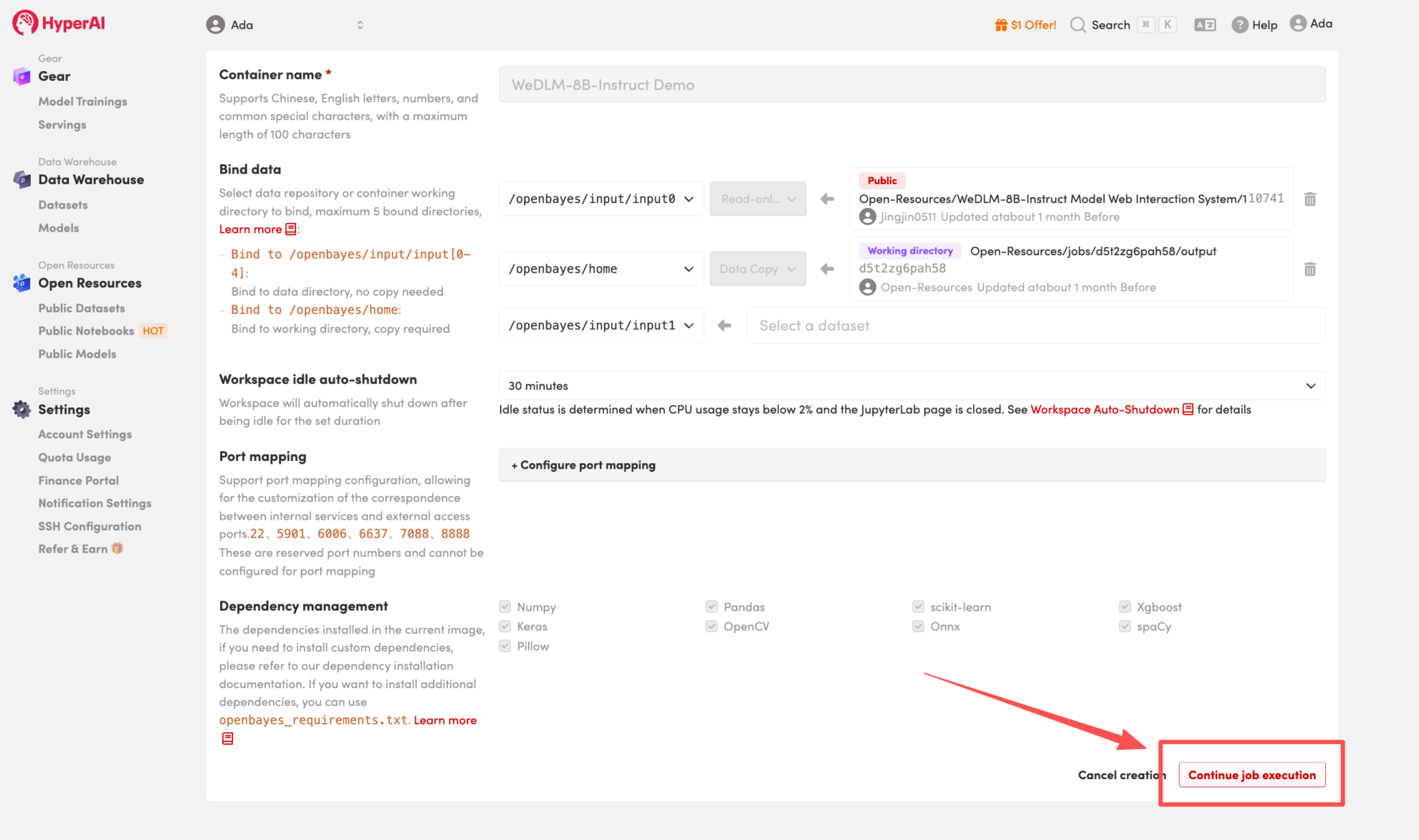
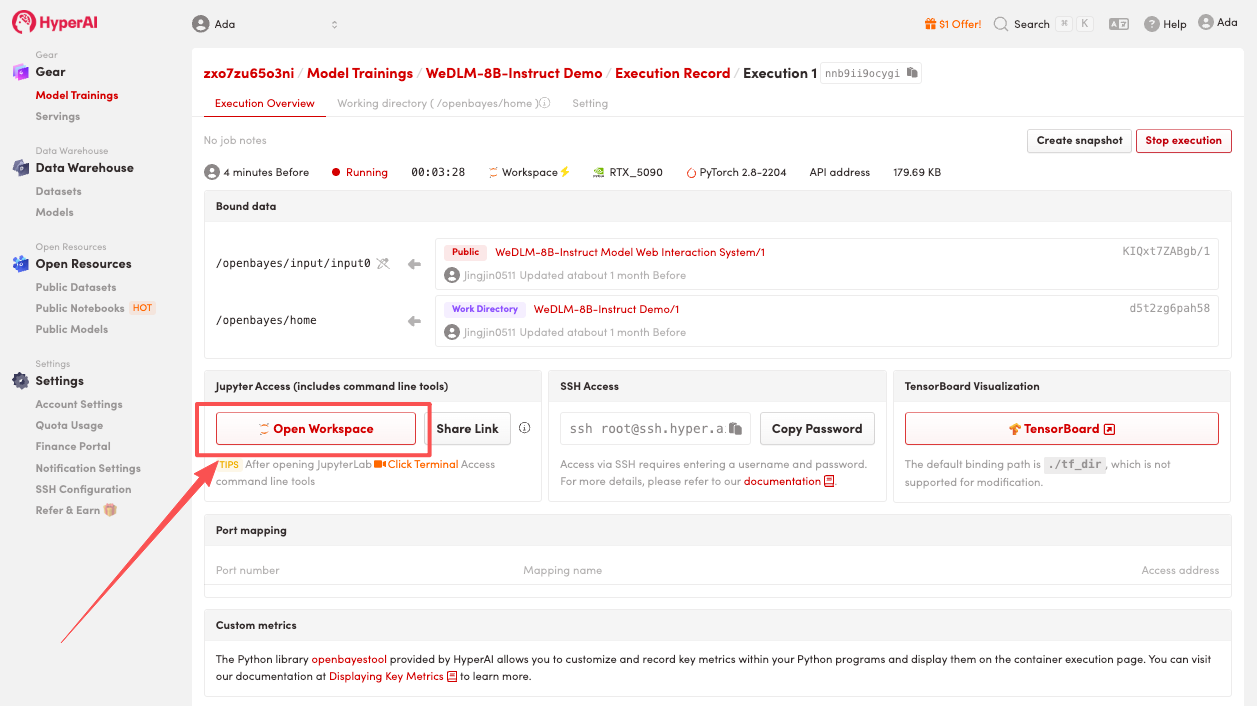
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
Effect Demonstration
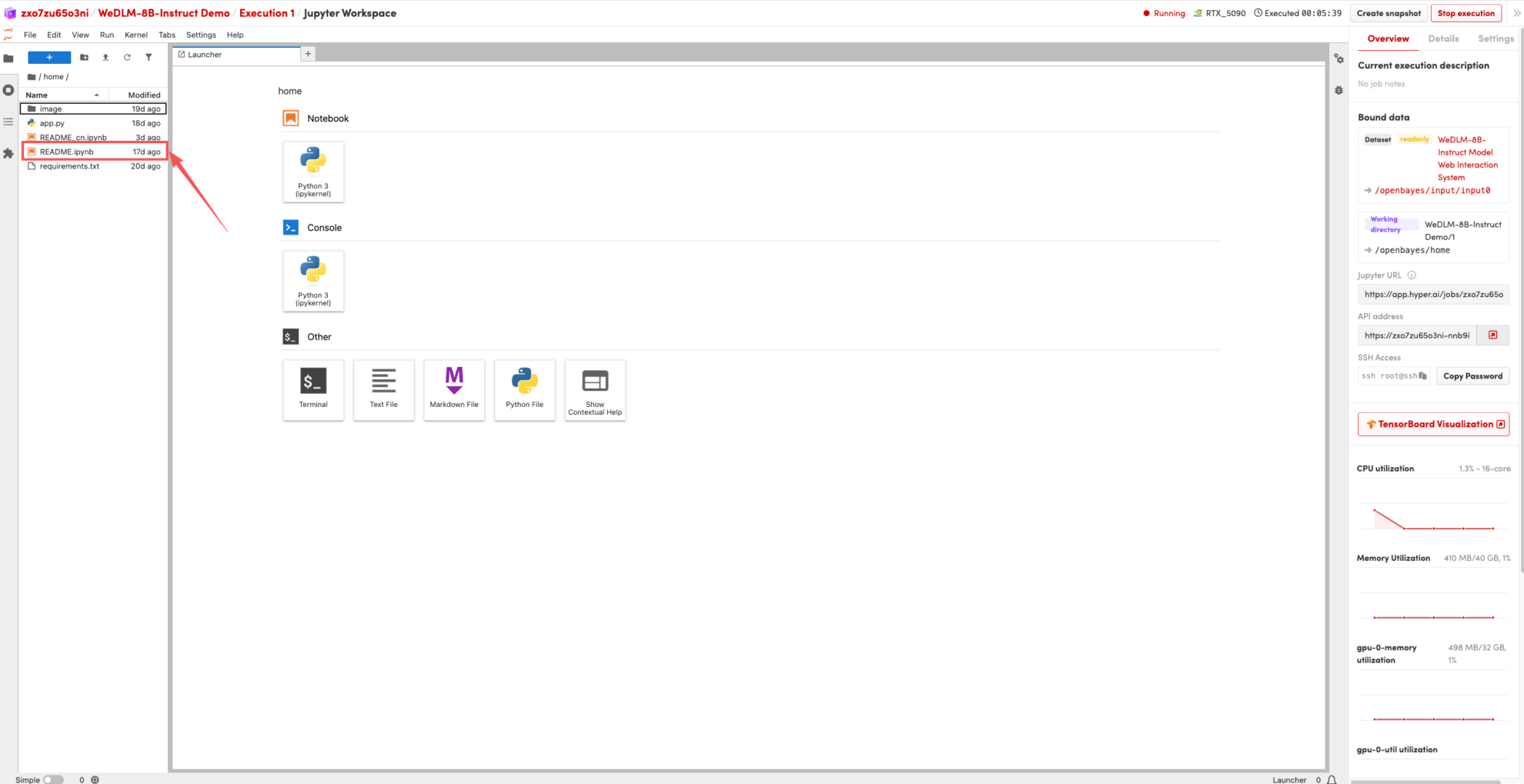
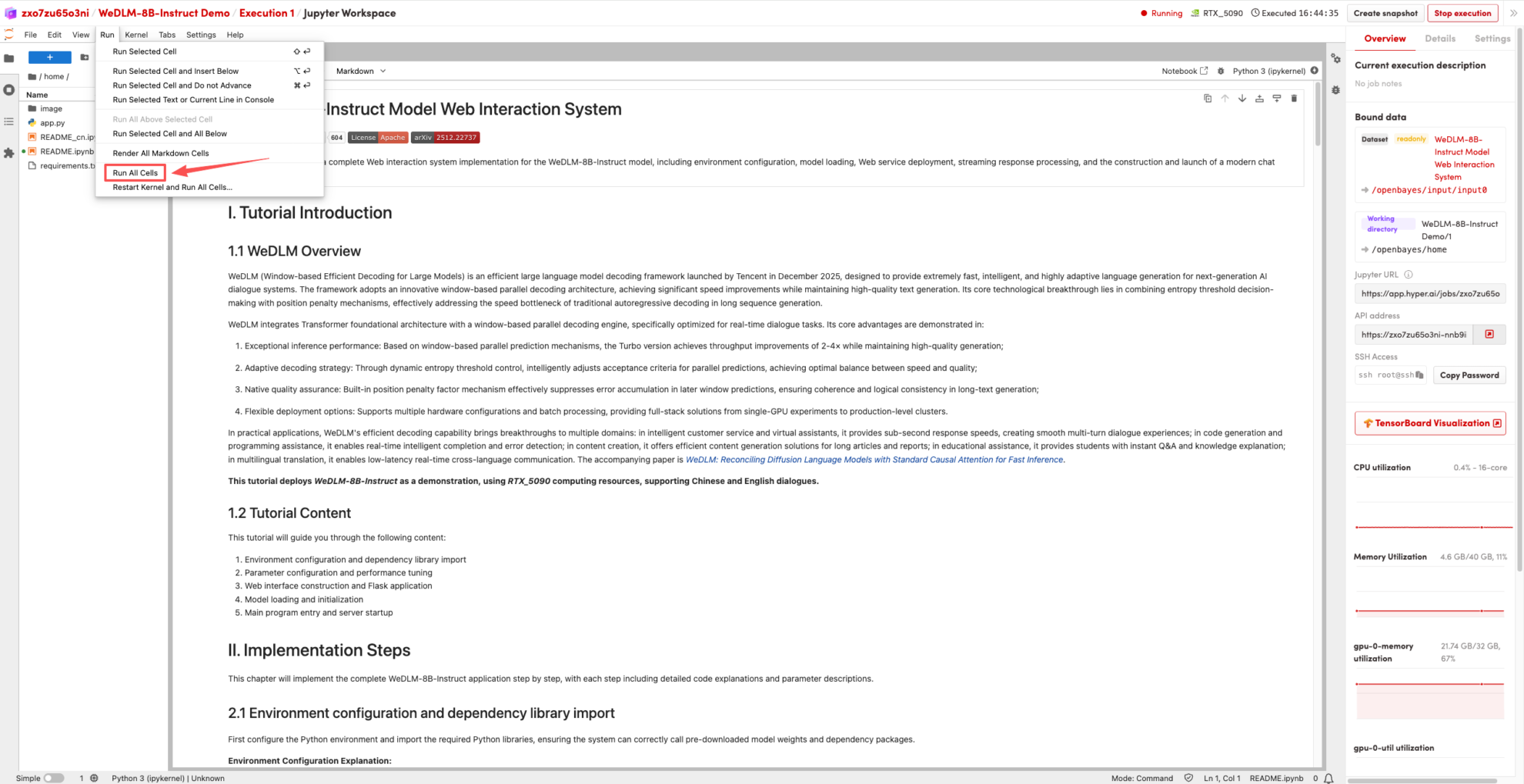
1. After the page redirects, click on the README page on the left, and then click Run at the top.
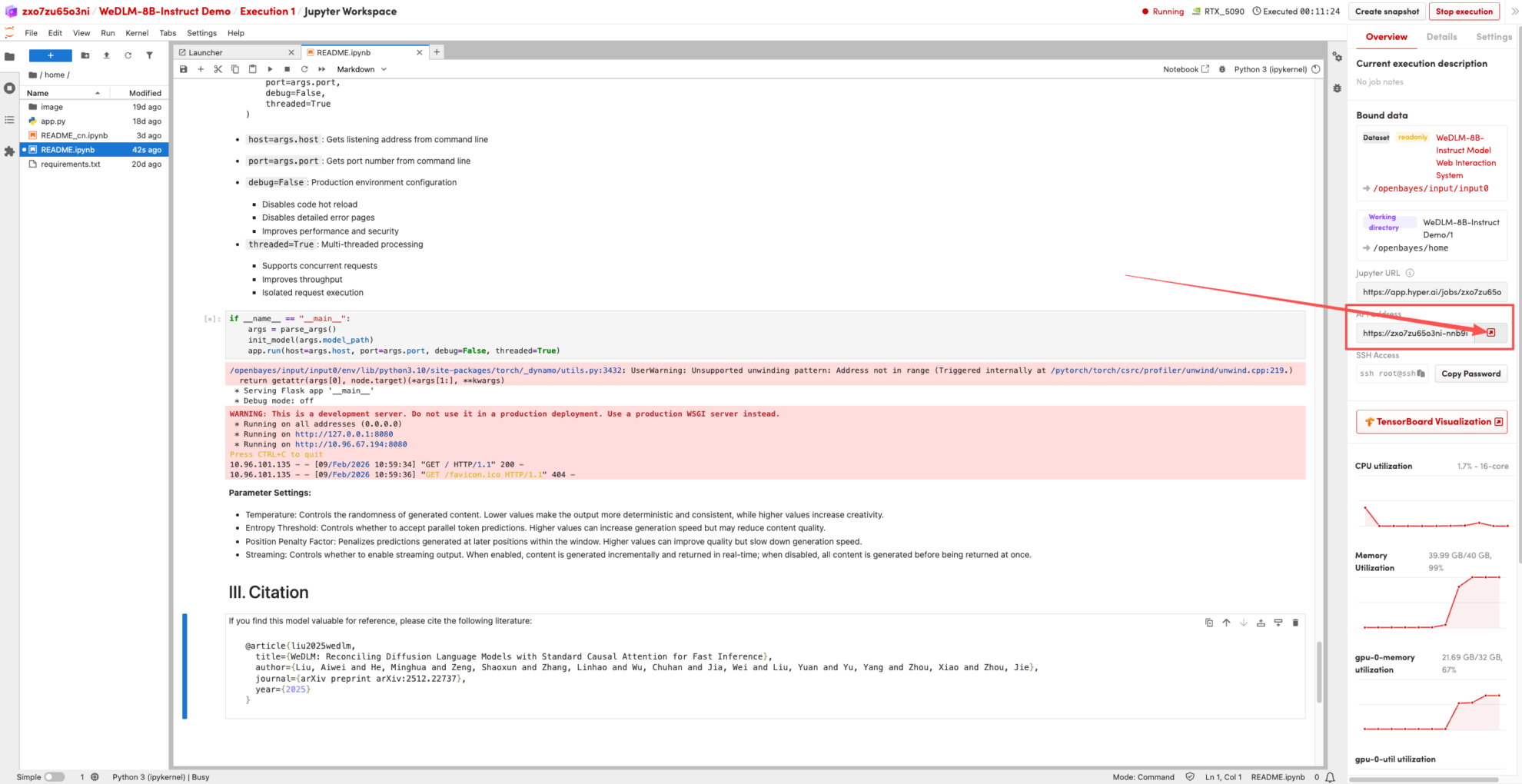
2. Once the process is complete, click the API address on the right to jump to the demo page.
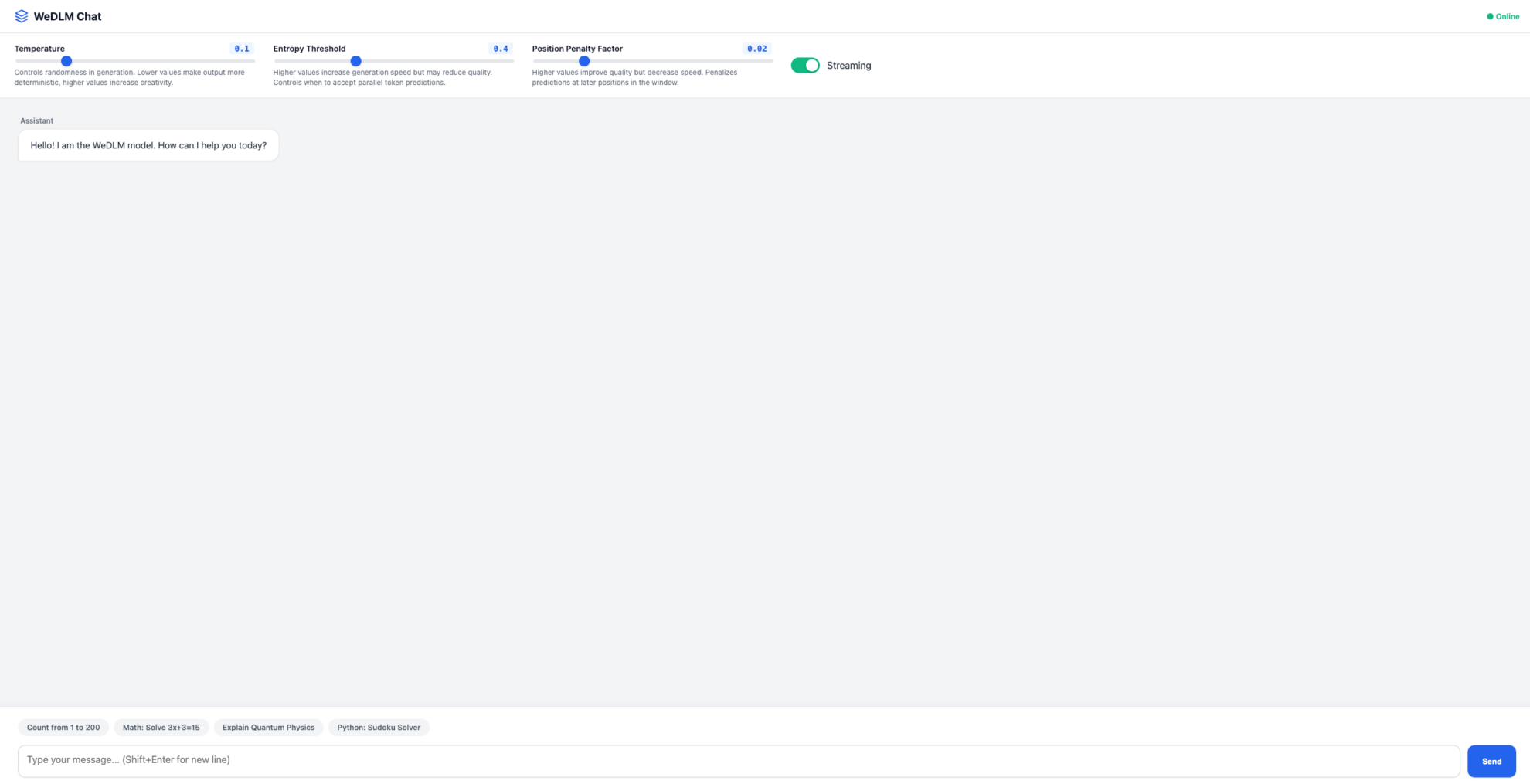
The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
Tutorial Link:https://go.hyper.ai/qf0Y6