Command Palette
Search for a command to run...
Memory Usage Reduced by up to 751 Tp3T: Scientists at the U.S. Department of Energy Have Proposed a cross-channel Hierarchical Aggregation Method, D-CHAG, to Enable the Running of Extremely large-scale Model multi-channel datasets.

Vision-based scientific foundation models hold immense potential for driving scientific discovery and innovation, primarily due to their ability to aggregate image data from diverse sources (e.g., different physical observation scenarios) and learn spatiotemporal correlations using the Transformer architecture. However, the tokenization and aggregation of images are computationally expensive, and existing distributed methods such as tensor parallelism (TP), sequence parallelism (SP), or data parallelism (DP) have not yet adequately addressed this challenge.
In this context,Researchers from Oak Ridge National Laboratory of the U.S. Department of Energy have proposed a distributed cross-channel hierarchical aggregation (D-CHAG) method for basic models.This method distributes the tokenization process and employs a hierarchical strategy for channel aggregation, enabling extremely large-scale models to run on multi-channel datasets. Researchers evaluated D-CHAG on hyperspectral imaging and weather forecasting tasks, finding that combining this method with tensor parallelism and model sharding reduced memory footprint by up to 751 TP3T on the Frontier supercomputer and achieved sustained throughput improvements of over 2x on up to 1,024 AMD GPUs.
The relevant research findings, titled "Distributed Cross-Channel Hierarchical Aggregation for Foundation Models," have been published in SC25.
Research highlights:
* D-CHAG solves the memory bottleneck and computational efficiency problems in multi-channel base model training.
* Compared to using TP alone, D-CHAG can achieve a memory footprint reduction of up to 70%, thus supporting more efficient large-scale model training.
* The performance of D-CHAG was validated on two scientific workloads: weather forecasting and hyperspectral plant image masking prediction.
Paper address:
https://dl.acm.org/doi/10.1145/3712285.3759870
Follow our official WeChat account and reply "cross-channel" in the background to get the full PDF.
Using two typical multichannel datasets
This study used two typical multichannel datasets to validate the effectiveness of the D-CHAG method:Hyperspectral images of plants and the ERA5 meteorological dataset.
The plant hyperspectral image data used for self-supervised mask prediction was collected by the Advanced Plant Phenotyping Laboratory (APPL) of Oak Ridge National Laboratory (ORNL).The dataset contains 494 hyperspectral images of poplar trees, each containing 500 spectral channels covering wavelengths from 400 nm to 900 nm.
This dataset is primarily used for biomass research and is an important resource for plant phenotyping and bioenergy research. These images are used for masked self-supervised training, where image slices are used as tokens for masking. The model's task is to predict missing content, thereby learning the underlying data distribution of the images. Notably, this dataset does not use any pre-trained weights and is trained entirely on self-supervised learning, highlighting the applicability of D-CHAG in high-channel self-supervised tasks.
also,In the weather forecasting experiment, the research team used the ERA5 high-resolution reanalysis dataset.The study selected five atmospheric variables (geopotential height, temperature, wind speed u-component, wind speed v-component, and specific humidity) and three surface variables (2-meter temperature, 10-meter u-component wind speed, and 10-meter v-component wind speed), covering more than 10 pressure layers, generating a total of 80 input channels. To adapt to model training, the original 0.25° resolution data (770 × 1440) was regrinded to 5.625° (32 × 64) using the xESMF toolkit and bilinear interpolation algorithm.
The model task is to predict meteorological variables for future time steps, such as 500 hPa geopotential height (Z500), 850 hPa temperature (T850), and 10 m u component wind speed (U10), thereby verifying the performance of the D-CHAG method in time series forecasting tasks.
D-CHAG: Combining hierarchical aggregation with distributed tokenization
In short, the D-CHAG method is a fusion of two independent methods:
Distributed tokenization method
During the forward propagation process, each TP rank only tokenizes a subset of the input channels.Before performing the channel aggregation step, an AllGather operation needs to be executed to achieve cross-attention across all channels. Theoretically, this method can reduce the tokenization computation overhead per GPU.
Hierarchical cross-channel aggregation
The main advantage of this approach is the reduced memory footprint per cross-channel attention layer, because fewer channels are processed per layer.However, increasing the number of layers leads to a larger overall model size and increased memory usage. This trade-off is more favorable for datasets with a large number of channels because standard cross-channel attention incurs higher secondary memory overhead.
While both methods have their advantages, they also have some drawbacks. For example, the distributed tokenization method incurs high communication overhead between TP ranks and does not solve the problem of large memory consumption at the channel level; while the hierarchical cross-channel aggregation method increases the number of model parameters per GPU. The D-CHAG method combines the two methods in a distributed manner, and the overall architecture is shown in the figure below:
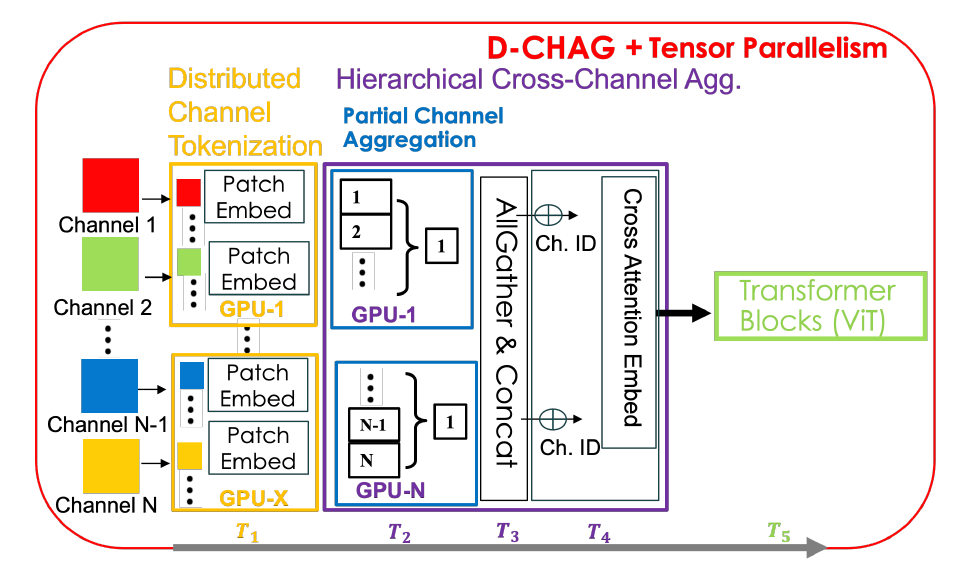
Specifically,Each TP rank tokenizes the two-dimensional images in the total channel subset.Since each GPU only holds a subset of all channels, channel aggregation is performed locally on these channels—this module is called the partial-channel aggregation module. After channel aggregation is completed within each TP rank, the outputs are collected and final aggregation is performed using cross-channel attention. Only one AllGather operation is performed during forward propagation; during backpropagation, only the relevant gradients for each GPU are collected, thus avoiding additional communication.
The D-CHAG method can fully leverage the advantages of distributed tokenization and hierarchical channel aggregation while mitigating their shortcomings.By distributing hierarchical channel aggregation across TP ranks, researchers reduced AllGather communication to processing only a single channel per TP rank, eliminating the need for any communication during backpropagation. Furthermore, by increasing model depth, they retained the advantage of reduced channel processing per layer, while distributing additional model parameters across TP ranks through partial channel aggregation modules.
The study compared two implementation strategies:
* D-CHAG-L (Linear Layer): The hierarchical aggregation module uses a linear layer, which has low memory usage and is suitable for situations with a large number of channels.
* D-CHAG-C (Cross-Attention Layer): Uses a cross-attention layer, which has a higher computational cost, but significantly improves performance for very large models or extremely high channel counts.
Results: D-CHAG supports training larger models on high-channel datasets.
After constructing D-CHAG, the researchers validated the model's performance and then further evaluated its performance on hyperspectral imaging and weather forecasting tasks:
Model performance analysis
The following figure shows the performance of D-CHAG under different partial channel aggregation module configurations:
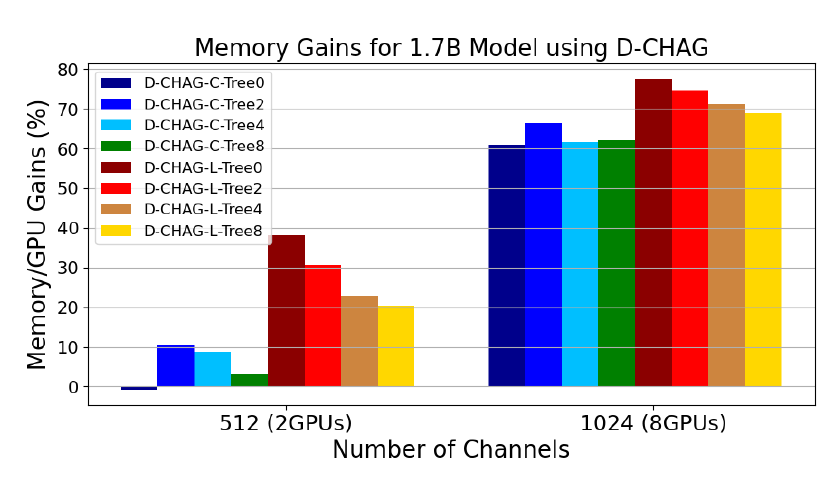
* Tree0 indicates that there is only one level of aggregation in some aggregation modules, Tree2 indicates two levels, and so on;
* The suffixes -C and -L indicate the type of layers used: -C indicates all layers are cross-attention, and -L indicates all layers are linear.
The results show:
For 512-channel data, the performance of using a single-layer cross-attention layer is slightly lower than the baseline, but it can improve performance by about 60% for 1024-channel data.
As the hierarchical structure deepens, even 512-channel data can achieve significant performance improvements, while the performance of 1024-channel data remains relatively stable.
Using linear layers, even with a shallow hierarchy, can yield performance improvements on 512- and 1024-channel images. In fact, the best performance is seen in D-CHAG-L-Tree0, which contains only one channel aggregation layer. Adding aggregation layers increases model parameters and introduces additional memory overhead. While increasing the number of layers seems beneficial for the 512-channel case, for both channel sizes, using only one linear layer outperforms deeper configurations.
The D-CHAG-C-Tree0 has a slight negative impact on performance with two GPUs, but can achieve a 60% performance improvement when scaled up to eight GPUs.
Self-supervised mask prediction of plant hyperspectral images
The figure below compares the training loss of the baseline method and the D-CHAG method in the application of hyperspectral plant image mask autoencoders. The results show:During training, the training loss performance of the single-GPU implementation is highly consistent with that of the D-CHAG method (running on two GPUs).
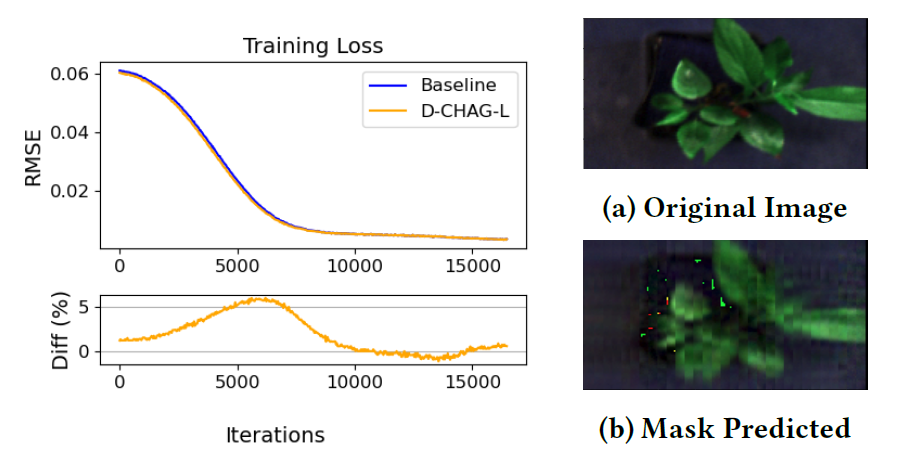
Larry York, a senior researcher in the Molecular and Cellular Imaging Group at Oak Ridge National Laboratory, said that D-CHAG can help plant scientists quickly complete tasks such as measuring plant photosynthetic activity directly from images, replacing time-consuming and laborious manual measurements.
Weather Forecast
Researchers conducted a 30-day weather forecasting experiment on the ERA5 dataset. The figure below compares the training loss and RMSE of the three test variables of the baseline method and the D-CHAG method in weather forecasting applications:
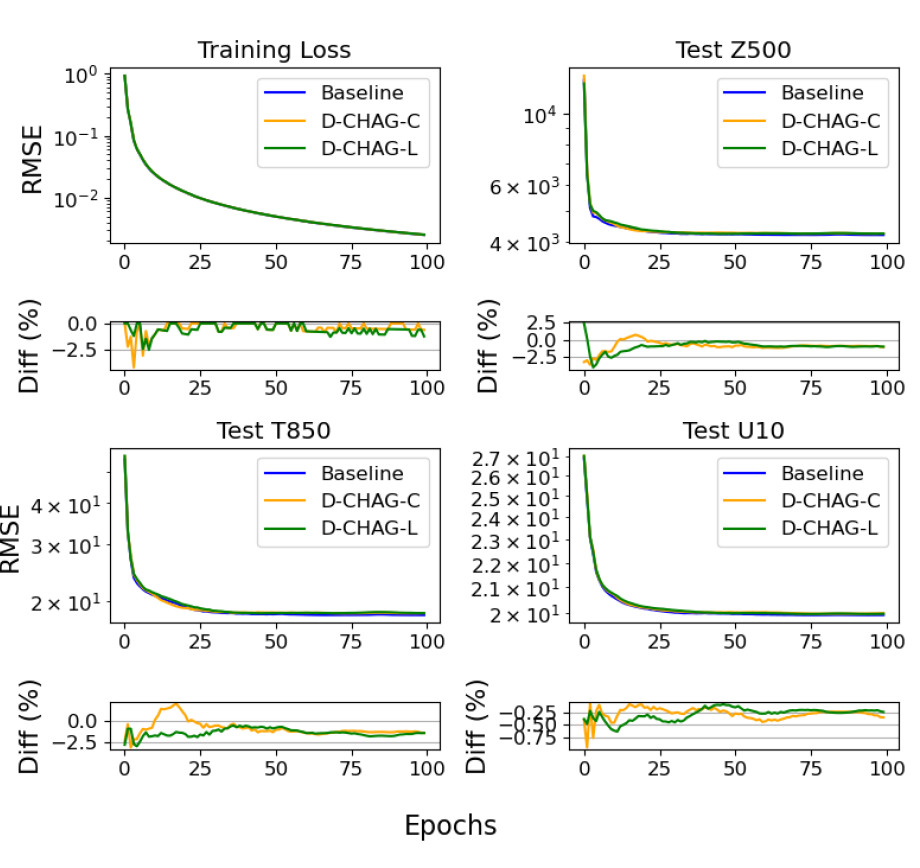
The table below shows the final comparison of the model on 7-, 14-, and 30-day prediction tasks, including RMSE, MSE, and Pearson correlation coefficient (wACC).
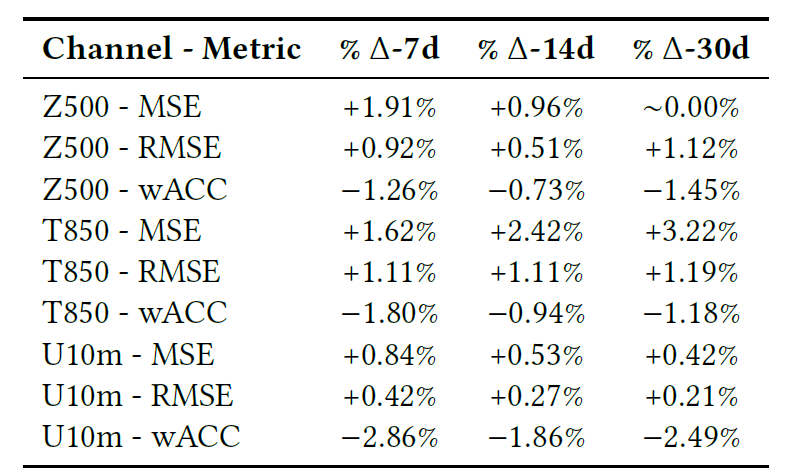
Overall, based on the graphs and tables, the training loss is highly consistent with the baseline model, and the deviations of various indicators are minimal.
Performance scaling with model size
The figure below shows the performance improvement of the D-CHAG method compared to using only TP for three model sizes with channel configurations requiring TP:
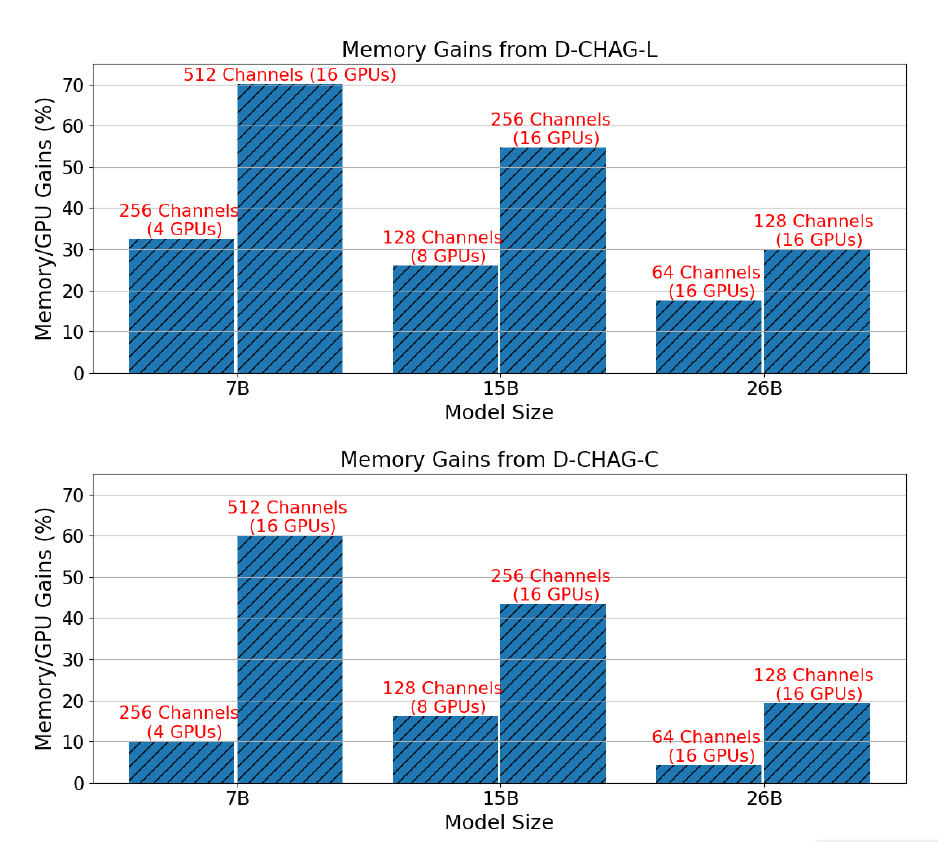
The results show thatFor the 7B parameter model,Using linear layers in the partial channel aggregation module can achieve a performance improvement of 30% to 70%, while using cross-attention layers can achieve an improvement of 10% to 60%.For the 15B parameter model,Performance improvements exceed 20% to 50%;The performance improvement of the 26B parameter model is between 10% and 30%.
Furthermore, with a fixed model size, the performance improvement becomes more significant as the number of channels increases. This is because, under a given architecture, increasing the number of channels does not increase the computational cost of the transformer block, but it does increase the workload of the tokenization and channel-aggregation modules.
On the other hand, TP alone cannot train images with 26 parameters and 256 channels, but the D-CHAG method can train a model with 26 parameters and 512 channels using less than 80% of available memory—this shows that the method can support the training of larger models on high-channel datasets.
ViT: Visual AI - From Perceptual Models to General Visual Foundation Models
Over the past decade, computer vision models have primarily revolved around "single-task optimization"—classification, detection, segmentation, and reconstruction have developed independently. However, as the Transformer architecture has spawned foundational models like GPT and BERT in the natural language processing domain, the vision field is undergoing a similar paradigm shift: from task-specific models to general-purpose vision foundational models. In this trend, the Vision Transformer (ViT) is considered a key technological cornerstone of vision foundational models.
Vision Transformer (ViT) was the first to fully introduce the Transformer architecture into computer vision tasks. Its core idea is to treat an image as a sequence of patch tokens and replace the local receptive field modeling of convolutional neural networks with a self-attention mechanism. Specifically, ViT divides the input image into fixed-size patches, maps each patch to an embedding token, and then models the global relationships between patches through a Transformer Encoder.
Compared to traditional CNNs, ViT has particular advantages for scientific data: it is suitable for high-dimensional multi-channel data (such as remote sensing, medical images, and spectral data), can handle non-Euclidean spatial structures (such as climate grids and physical fields), and is suitable for cross-channel modeling (coupling relationships between different physical variables), which is also the core issue addressed in the D-CHAG paper.
Beyond the scenarios mentioned in the research above, ViT is demonstrating its core value in even more scenarios. In March 2025, Dr. Han Gangwen, Chief Physician of the Department of Dermatology at Peking University International Hospital, and his team developed a deep learning algorithm called AcneDGNet. This algorithm integrates visual Transformer and convolutional neural networks to obtain a more efficient hierarchical feature table, resulting in more accurate grading. Prospective evaluations show that AcneDGNet's deep learning algorithm is not only more accurate than that of junior dermatologists but also comparable to that of senior dermatologists. It can accurately detect acne lesions and determine their severity in different healthcare scenarios, effectively helping dermatologists and patients diagnose and manage acne in both online consultations and offline medical visits.
Paper Title:
Evaluation of an acne lesion detection and severity grading model for Chinese population in online and offline healthcare scenarios
Paper address:
https://www.nature.com/articles/s41598-024-84670-z
From an industry perspective, Vision Transformer marks a crucial inflection point in visual AI's evolution from perceptual models to general-purpose visual foundational models. Its unified Transformer architecture provides a universal foundation for cross-modal fusion, scalable expansion, and system-level optimization, making visual models a core infrastructure for AI for Science. In the future, parallelization, memory optimization, and multi-channel modeling capabilities surrounding ViT will become key competitive factors determining the speed and scale of the industrial deployment of visual foundational models.
References:
1.https://phys.org/news/2026-01-empowering-ai-foundation.html
2.https://dl.acm.org/doi/10.1145/3712285.3759870
3.https://mp.weixin.qq.com/s/JvKQPbBQFhofqlVX4jLgSA