Command Palette
Search for a command to run...
EnergAIzer, a GPU Power Estimation Framework Developed by MIT and Others, Completes Predictions in an Average of 1.8 Seconds With an Error of Approximately 81 TP3T.

According to estimates from Lawrence Berkeley National Laboratory, due to the explosive growth of artificial intelligence,By 2028, data centers will consume 121 TP3T of the total electricity used in the United States.As the primary accelerator for AI workloads, graphics processing units (GPUs) have become a major source of power consumption, with thermal design power (TDP) reaching 700W and 1200W respectively in the latest NVIDIA H100 and GB200. Against the backdrop of increasingly severe energy challenges,Rapidly estimating GPU power and energy consumption for AI workloads has become crucial.
Power consumption models typically require hardware utilization information as input to characterize the usage intensity of various GPU modules (such as DRAM and Tensor Cores), as dynamic power consumption is directly proportional to module activity. Existing methods primarily obtain this information through two approaches: one is using instruction-level simulators to derive module utilization by simulating GPU execution cycle by cycle.However, even for medium-sized workloads, such detailed simulations can take several hours.The second is runtime performance analysis (profiling).However, this not only leads to higher analysis overhead, but also depends on available hardware resources.
Against this backdropResearchers from MIT and the MIT-IBM Watson AI Lab have built EnergAIzer, a fast GPU power estimation framework for AI workloads.Hardware utilization information can be directly provided to power consumption models without the need for expensive simulations or performance analysis.This new framework can complete end-to-end power consumption estimation in an average of only 1.8 seconds.On NVIDIA Ampere GPUs, EnergAIzer achieved a power consumption error of approximately 81 TP3T, which is competitive with traditional models that rely on complex cyclic simulations or hardware performance analysis.
The researchers also demonstrated EnergAIzer's capabilities in frequency scaling and architecture configuration exploration.Including the prediction of the NVIDIA H100's power consumption, the error is only 7%.Overall, EnergAIzer provides fast and accurate power consumption prediction capabilities for AI workloads. Data center operators can use these estimates to effectively allocate limited resources among multiple AI models and processors, thereby improving energy efficiency.
The related research findings, titled "EnergAIzer: Fast and Accurate GPU Power Estimation Framework for AI Workloads," have been published as a preprint on arXiv.
Research highlights:
* The new framework generates reliable power consumption estimates in just seconds, whereas traditional modeling techniques may take hours or even days to produce results.
* The new forecasting tool can be applied to a wide range of hardware configurations, including even emerging designs that have not yet been deployed.
This tool helps algorithm developers and model providers assess the potential energy consumption of new models before deployment.

Paper address:
https://arxiv.org/abs/2604.20105
Follow our official WeChat account and reply "power consumption prediction" in the background to get the full PDF.
Dataset: Covering various mainstream operator types and tensor shapes
In all experiments,Researchers built offline kernel databases based on NVIDIA A100-40GB-PCIE and A10 GPU.Covering various mainstream operator types and tensor shapes for training EnergAIzer, see the table below for details:
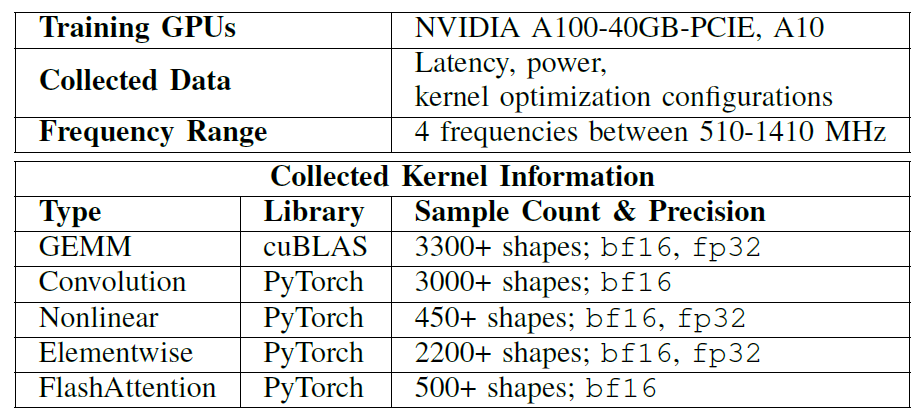
include:
* GEMM-type matrix calculations
* Convolution
* Nonlinear
* Elementwise
* FlashAttention
The researchers provided experimental resources for EnergAIzer.This includes the source code for the estimation framework, a pre-collected database for empirical fitting, and real measurement data for validating the predictions.Its resources include scripts for reproducing experiments, generating single-kernel-level power and latency estimates, and end-to-end estimates for AI workloads.
Three steps to build the EnergAIzer kernel-level prediction model
At the heart of ENERGAIZER is a kernel-level prediction model, which researchers build through three steps.first,Establishing workload representations, such as software optimization strategies like tiling, thread block scheduling, and pipelining, will form structured execution patterns that form the basis of performance models.Secondly,Build performance models and fit empirical data using these patterns as scaffolds;at last,The power consumption model uses the predicted utilization rate to estimate dynamic power consumption.
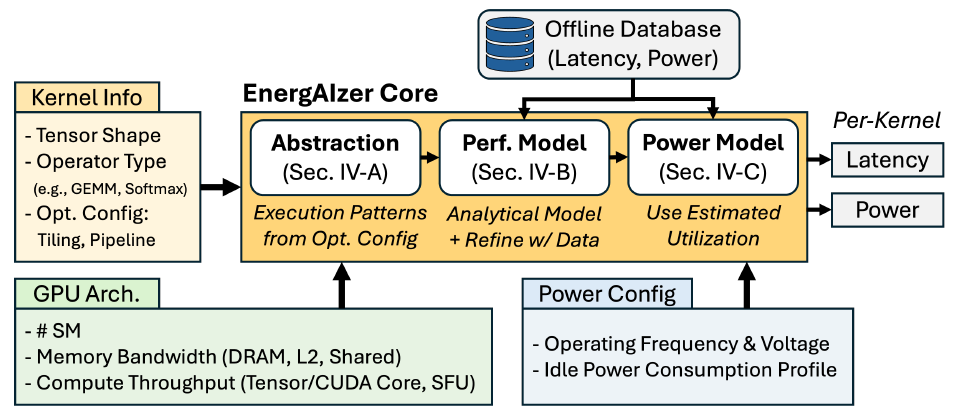
Workload Structure Modeling Layer
Optimization strategy
Tensors are hierarchically divided into data tiles at various levels of GPU execution. Thread block swizzling schedules thread blocks accessing the same input tile to adjacent tensors, thereby improving L2 cache reuse. Software pipelining overlaps data transfer and computation in time iterations. The pipelining structure determines the exposed latency, which is a key factor in performance modeling.
Beyond GEMM
Building on this, the researchers systematically extended the analysis to all major kernel types in AI (including nonlinear, element-wise, and fusion kernels) with the goal of deriving module-level utilization for service power modeling.
verify
Using analytical methods, researchers derived the total load traffic for shared memory, L2 cache, and DRAM, and compared it with hardware counter data obtained through NCU performance analysis on an NVIDIA A100-40GB-PCIE GPU. Near-perfect correlations were observed across more than 790 GEMM cores, 70 Softmax cores, and over 380 FlashAttention cores, thus validating that block parameters and ideal thread block rearrangement determine memory traffic.
Performance Model Layer
Timeline construction
The performance model constructs an execution timeline composed of coarse-grained operations. Tilting determines the granularity of the operations (e.g., data loading/storage, number of computation instructions), while pipelining determines how these operations overlap based on dependencies. This timeline forms the analytical scaffold and is used to reveal module-level utilization, as shown in the figure below:
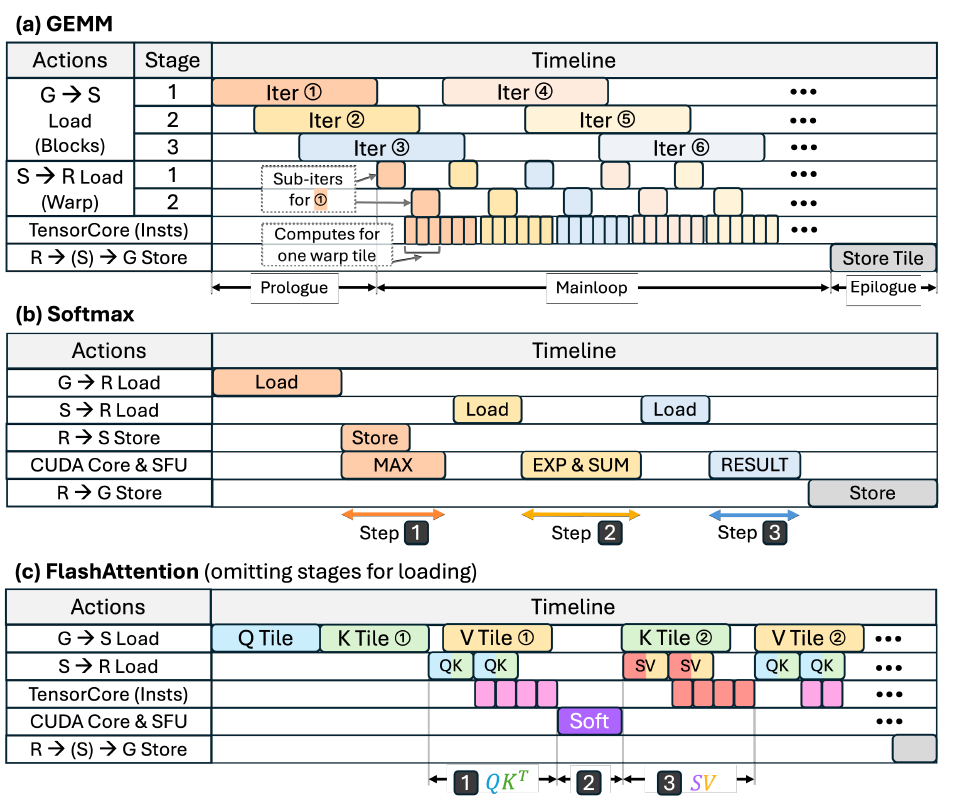
Delayed prediction
After establishing the timeline structure, the method for calculating the latency of each operation is described; subsequently, the latency of these individual operations is combined into the overall execution time, reflecting the impact of the pipeline.
Utilization Derivation
Based on the build timeline, the utilization rates of six key modules were extracted: DRAM, L2 cache, shared memory, Tensor Cores, CUDA Cores (for regular floating-point operations), and Special Function Units (for exponential and other nonlinear functions). For each module, its utilization rate was defined as the proportion of its active time to the total kernel execution time.
Power consumption model layer
Based on the module-level utilization obtained from the performance model, researchers estimated it using a standard dynamic power consumption formula. This method is formally consistent with traditional power consumption modeling, but the key difference lies in how the utilization α is obtained. Since the offline database covers power consumption measurements at multiple operating frequencies, the C coefficient is fitted to minimize the error across the entire frequency range, thus supporting power consumption estimation at any frequency without additional measurements during the inference phase.
On average, it only takes 1.8 seconds per workload to complete the joint estimation of latency and power consumption.
Researchers experimentally evaluated the predictive power of EnergAIzer and its application in exploring various design options:
Accuracy of latency and power consumption estimation for AI workloads
The figure below shows the end-to-end latency and power consumption estimation results for various language models (BERT-Large, GPT-2, OPT-1.3B, Qwen2-1.5B) and visual models (ResNet101, ViT, MobileViT):
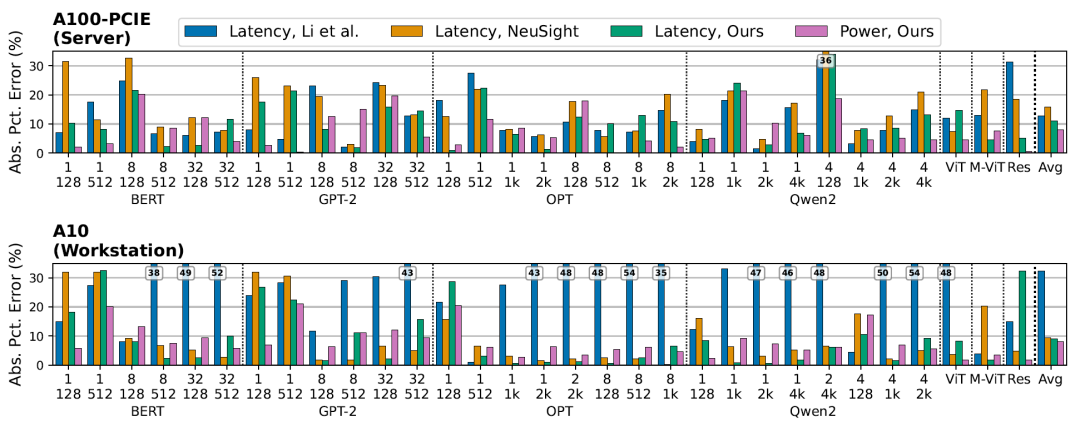
EnergAIzer achieved an average latency error of 11.01 TP3T and a power consumption error of 8.01 TP3T on a server-grade GPU (A100-40GB-PCIE).On a workstation-class GPU (A10), they are 8.8% and 8.2% respectively.These results are averaged across all workloads. In terms of latency prediction, EnergAIzer is competitive with state-of-the-art lightweight performance models (Li et al., NeuSight), while also providing power estimation capabilities that these models cannot offer.
EnergAIzer takes an average of only 1.8 seconds per workload to complete a joint estimation of latency and power consumption.For language models, a single prediction takes between 1.1 and 2.8 seconds. In contrast, hardware counter acquisition using the NCU takes 452 to 8192 seconds, thus achieving a speedup of 317× to 3856×.
Explore voltage-frequency regulation
Voltage-frequency regulation is a commonly used power management technique that can benefit from accurate power consumption prediction across different operating points. Researchers evaluated EnergAIzer's ability to estimate power consumption at different frequencies (510–1410 MHz) on an A100-40GB-PCIE. In the experiments, only the power configuration input parameters of EnergAIzer were adjusted, including the target frequency, voltage, and idle power consumption at that frequency. The following figure shows the comparison between actual measured values and predicted power consumption:
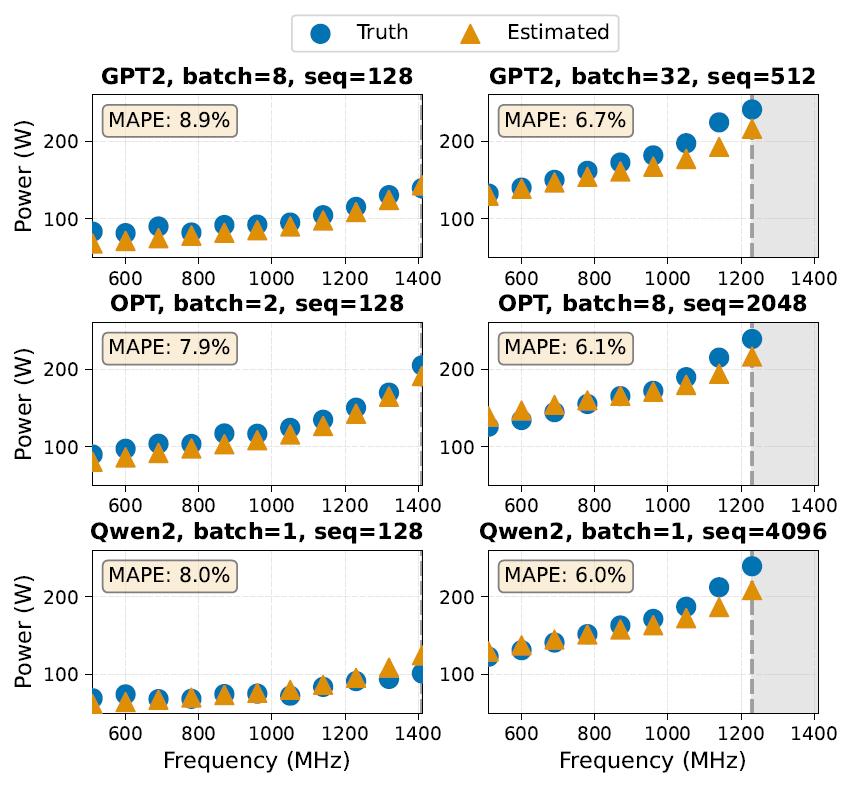
The EnergAIzer framework can capture typical scaling behaviors for different workload types: low-utilization workloads (small batch/sequence, left figure) and power-constrained workloads (large batch/sequence, right figure).The mean absolute percentage error (MAPE) at different frequencies is 6%–9%.
Exploring GPU architecture configuration
This framework also supports exploring different GPU architecture configurations by adjusting GPU architecture parameters (such as the number of SMs, memory bandwidth, and compute throughput) as input.This allows for the prediction of power consumption for the new architecture without the need for target hardware data acquisition. Researchers evaluated two scenarios: exploration within the same GPU architecture generation, and exploration across architecture generations. The target GPU configurations are summarized in the table below:
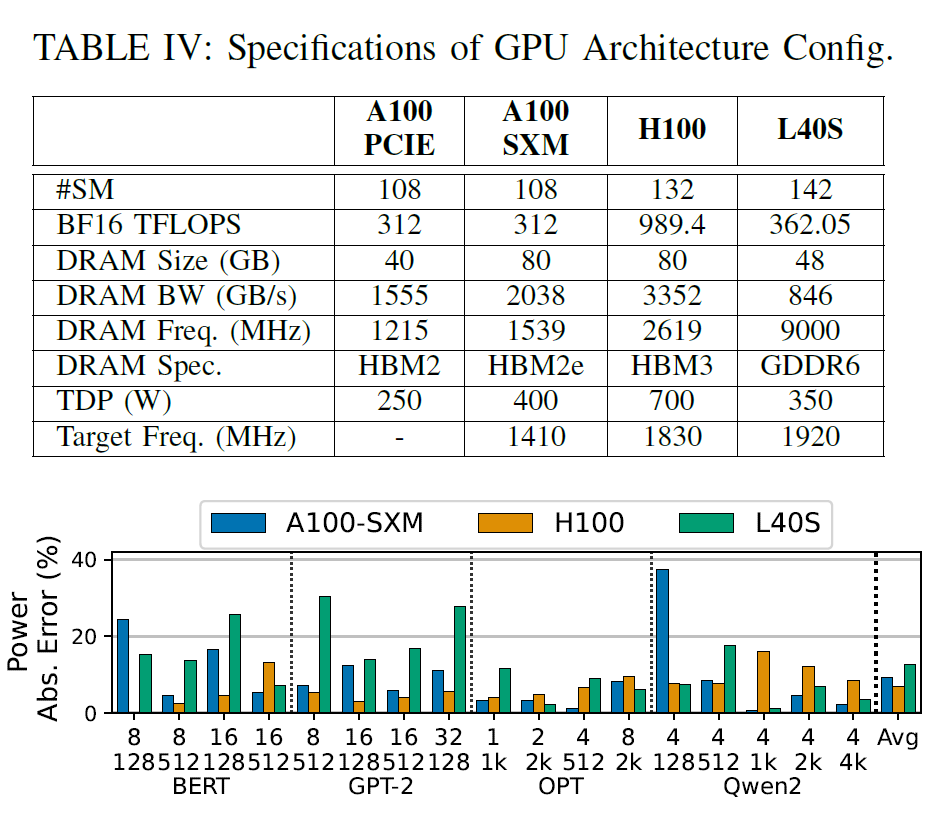
First, within the Ampere architecture, researchers used only a database collected from the A100-40GB-PCIE to predict the power consumption of the A100-80GB-SXM, with an average error of 9.11 TP3T. Second, in cross-generational scenarios, using the Ampere architecture database to predict the power consumption of the Hopper (H100) and Lovelace (L40S) yielded errors of 6.71 TP3T and 12.71 TP3T, respectively.
Overall, EnergAIzer provides fast and accurate power consumption prediction for AI workloads.
Conclusion
For data center operators, EnergAIzer can quickly assess the energy consumption performance of different GPU configurations, frequency strategies, and resource scheduling schemes, thereby supporting more refined resource orchestration and energy efficiency optimization. For AI model developers, this framework provides a new "hardware-aware" tool. During the model design phase, the performance and power consumption trade-offs resulting from different precisions and operator implementations can be evaluated, thus avoiding the exposure of energy consumption issues only during deployment.
Of course, the current framework still has certain limitations, such as the need to improve its modeling capabilities for multi-GPU collaborative computing, communication overhead, and irregular sparse computing. However, from a methodological perspective, EnergAIzer has demonstrated a clear trend: GPU power consumption modeling is evolving from an offline analysis tool that is "heavily dependent on measurement" to a "lightweight, embeddable" online decision-making capability. Against the backdrop of continuous expansion of AI computing power and increasingly tight energy constraints, the value of this type of technology is rapidly amplifying. In the future, as model complexity and hardware heterogeneity further increase, frameworks like EnergAIzer are likely to become more than just research tools; they may become an indispensable part of the AI infrastructure.
References
https://news.mit.edu/2026/faster-way-to-estimate-ai-power-consumption-0427
https://arxiv.org/pdf/2604.20105








