Command Palette
Search for a command to run...
Qwen2.5-Coder Technical Report
Qwen2.5-Coder Technical Report
Abstract
In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes six models: Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B). As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general and math skills. These models have been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size. We believe that the release of the Qwen2.5-Coder series will advance research in code intelligence and, with its permissive licensing, support wider adoption by developers in real-world applications.
One-sentence Summary
The Qwen Team at Alibaba Group presents Qwen2.5-Coder, a series of six code-specialized models up to 32B parameters, built on the Qwen2.5 architecture with enhanced data curation and synthetic data generation, achieving state-of-the-art performance in code generation, completion, and reasoning while maintaining strong general and mathematical capabilities, enabling broader real-world developer adoption under permissive licensing.
Key Contributions
-
Qwen2.5-Coder is a code-specific language model series built on the Qwen2.5 architecture, pre-trained on over 5.5 trillion tokens of curated code and text data, with enhanced capabilities in code generation, completion, reasoning, and repair through file-level and repository-level pretraining strategies.
-
The models achieve state-of-the-art performance across more than 10 benchmarks, consistently outperforming larger models of the same size and matching the coding capabilities of GPT-4o, while also maintaining strong general and mathematical reasoning skills.
-
With support for up to 128K tokens, Qwen2.5-Coder demonstrates advanced long-context understanding, validated through tasks like "Needle in the Code" and practical applications such as Text-to-SQL, enabling real-world use in code assistants and artifact generation.
Introduction
The authors leverage the Qwen2.5 architecture to introduce Qwen2.5-Coder, a family of six code-specific language models ranging from 0.5B to 32B parameters, designed to advance open-source code intelligence. This work addresses key limitations in prior code LLMs—such as narrow task coverage, weak long-context understanding, and suboptimal performance on real-world coding tasks—by training on a meticulously curated 5.5 trillion token dataset that combines high-quality public code, web-crawled code-related text, and synthetic data. The models are further refined through a carefully constructed instruction-tuning pipeline that covers diverse coding tasks, including code generation, completion, reasoning, editing, and text-to-SQL. The main contribution is a scalable, high-performance open-source code model series that achieves state-of-the-art results across more than ten benchmarks, outperforming larger models of similar size and matching the capabilities of proprietary models like GPT-4o, while supporting long-context reasoning up to 128K tokens and practical applications in code assistants and artifact generation.
Dataset
-
The Qwen2.5-Coder-Data dataset is composed of five core data types: Source Code Data, Text-Code Grounding Data, Synthetic Data, Math Data, and Text Data, designed to support comprehensive code and language understanding.
-
Source Code Data includes public GitHub repositories created before February 2024, covering 92 programming languages. It also incorporates Pull Requests, Commits, Jupyter Notebooks, and Kaggle datasets, all processed with rule-based filtering to ensure quality and relevance.
-
Text-Code Grounding Data is derived from Common Crawl and includes code-related documentation, tutorials, and blogs. A four-stage coarse-to-fine hierarchical filtering approach was used, leveraging lightweight models like fastText at each stage to maintain efficiency and surface-level accuracy. This method enables fine-grained quality control and assigns quality scores, with final retained data showing improved performance on code generation benchmarks.
-
Synthetic Data was generated using CodeQwen1.5, the predecessor model, with an executor-based validation step to ensure only executable code was retained, reducing hallucination risks.
-
Math Data was integrated from the Qwen2.5-Math pre-training corpus to strengthen mathematical reasoning, without degrading code generation performance.
-
Text Data comes from the Qwen2.5 model’s pre-training corpus, preserving general language capabilities. All code segments were removed to prevent data overlap and ensure source independence.
-
The dataset is used in two pretraining stages: file-level and repo-level. File-level pretraining uses a maximum sequence length of 8,192 tokens and 5.2T of high-quality data, with objectives including next token prediction and fill-in-the-middle (FIM) formatting.
-
Repo-level pretraining extends context to 32,768 tokens, with RoPE base frequency adjusted to 1,000,000 and YARN mechanism applied to support up to 131,072 tokens. It uses approximately 300B tokens of long-context code data and applies a repo-level FIM format.
-
A decontamination step was performed across all data using a 10-gram word-level overlap method to remove any training samples matching key test datasets like HumanEval, MBPP, GSM8K, and MATH, preventing test leakage.
-
The dataset is processed with a focus on quality and diversity, with iterative filtering and validation ensuring high signal-to-noise ratio, especially in text-code grounding and synthetic data generation.
Method
The authors leverage the Qwen2.5 architecture as the foundation for Qwen2.5-Coder, adapting it for code-specific tasks through a multi-stage training pipeline. The model architecture, detailed in Table 1, is a transformer-based design with variations in key parameters across different model sizes (0.5B to 32B parameters). These parameters include hidden size, number of attention heads, intermediate layer size, and the use of embedding tying, which is applied to smaller models but not larger ones. All models share a consistent vocabulary size of 151,646 tokens and are trained on a corpus of 5.5 trillion tokens. The architecture supports a large context window, enabling the processing of extensive code sequences.
To enhance the model's understanding of code, Qwen2.5-Coder incorporates a set of special tokens, as outlined in Table 2, which are essential for handling diverse code structures. These tokens include </endoftext|> to mark sequence boundaries, and the Fill-in-the-Middle (FIM) tokens </fim_prefix|>, </fim_middle|>, and </fim_suffix|>, which are used to train the model to predict missing segments of code. Additional tokens like </repo_name|> and </file_sep|> facilitate the organization of repository-level data, allowing the model to manage information at both the file and repository levels.
The training process for Qwen2.5-Coder is structured as a three-stage pipeline, as illustrated in the framework diagram. The first stage is file-level pretraining, where the base Qwen2.5 model is trained on 5.2 trillion tokens of code data. This is followed by repo-level pretraining, which uses 300 billion tokens to further refine the model's understanding of code within the context of entire repositories. The final stage involves alignment, where the model undergoes supervised fine-tuning (SFT) and direct preference optimization (DPO) to align its outputs with human preferences and improve its code generation capabilities.

The instruction data used for fine-tuning is synthesized from a variety of sources, including code snippets from GitHub and open-source instruction datasets. A multilingual multi-agent collaborative framework is employed to generate high-quality, multilingual instruction data, where specialized agents for different programming languages engage in collaborative discussions to enhance their capabilities. The quality of the instruction data is rigorously evaluated using a checklist-based scoring system that assesses factors such as consistency, relevance, difficulty, and code correctness.
To ensure the correctness of the generated code, a multilingual sandbox is utilized for code verification. This sandbox supports static checking and dynamic execution of code snippets across multiple programming languages, including Python, Java, and C++. The sandbox is composed of several modules: a language support module that provides parsing and execution environments for different languages, a unit test generator that creates test cases based on sample code, and a code execution engine that runs the tests in isolated environments. This verification process is critical for filtering out low-quality data and ensuring the model learns to generate correct and reliable code.


Experiment
- Evaluated data mixture ratios for Code, Math, and Text; found 70% Code, 20% Text, 10% Math (7:2:1) optimal, achieving superior performance despite lower code proportion, with final dataset totaling 5.2 trillion tokens.
- On HumanEval and MBPP benchmarks, Qwen2.5-Coder-7B achieved state-of-the-art results among open-source models of similar size, outperforming larger models like DS-Coder-33B across all metrics.
- On BigCodeBench-Complete, Qwen2.5-Coder demonstrated strong generalization, achieving top performance on both full and hard subsets, indicating robust out-of-distribution capability.
- On MultiPL-E, Qwen2.5-Coder achieved state-of-the-art results across eight programming languages, scoring over 60% in five languages.
- On code completion benchmarks (HumanEval-FIM, CrossCodeEval, CrossCodeLongEval, RepoEval, SAFIM), Qwen2.5-Coder-32B achieved state-of-the-art performance, with significant improvements over comparable models and strong results even at smaller sizes (e.g., Qwen2.5-Coder-7B matching 33B models).
- On CRUXEval, Qwen2.5-Coder-7B-Instruct achieved 65.8% and 65.9% accuracy on Input-CoT and Output-CoT tasks, outperforming larger models and demonstrating strong code reasoning.
- On math benchmarks (MATH, GSM8K, MMLU-STEM, TheoremQA), Qwen2.5-Coder showed strong performance, attributed to balanced training data and strong base model foundation.
- On general natural language benchmarks (MMLU, ARC-Challenge, TruthfulQA, WinoGrande, HellaSwag), Qwen2.5-Coder maintained strong performance, validating effective retention of general capabilities.
- On LiveCodeBench, Qwen2.5-Coder-7B-Instruct achieved 37.6% Pass@1, surpassing models with similar and larger sizes, and Qwen2.5-Coder-32B-Instruct reached 31.4%, matching many closed-source APIs.
- On McEval and MdEval, Qwen2.5-Coder-32B-Instruct achieved top performance across 40 and 18 languages, respectively, outperforming or matching larger models.
- On CodeEditorBench, Qwen2.5-Coder-32B-Instruct achieved a win rate of 86.2%, comparable to DS-Coder-V2-Instruct (236B parameters), demonstrating strong code editing capability.
- On TableBench, Qwen2.5-Coder-32B-Instruct achieved 45.1 score under TCoT setting, the best among evaluated models.
- Human preference alignment evaluation (CodeArena) showed Qwen2.5-Coder-32B-Instruct outperformed other open-source models in alignment with human preferences.
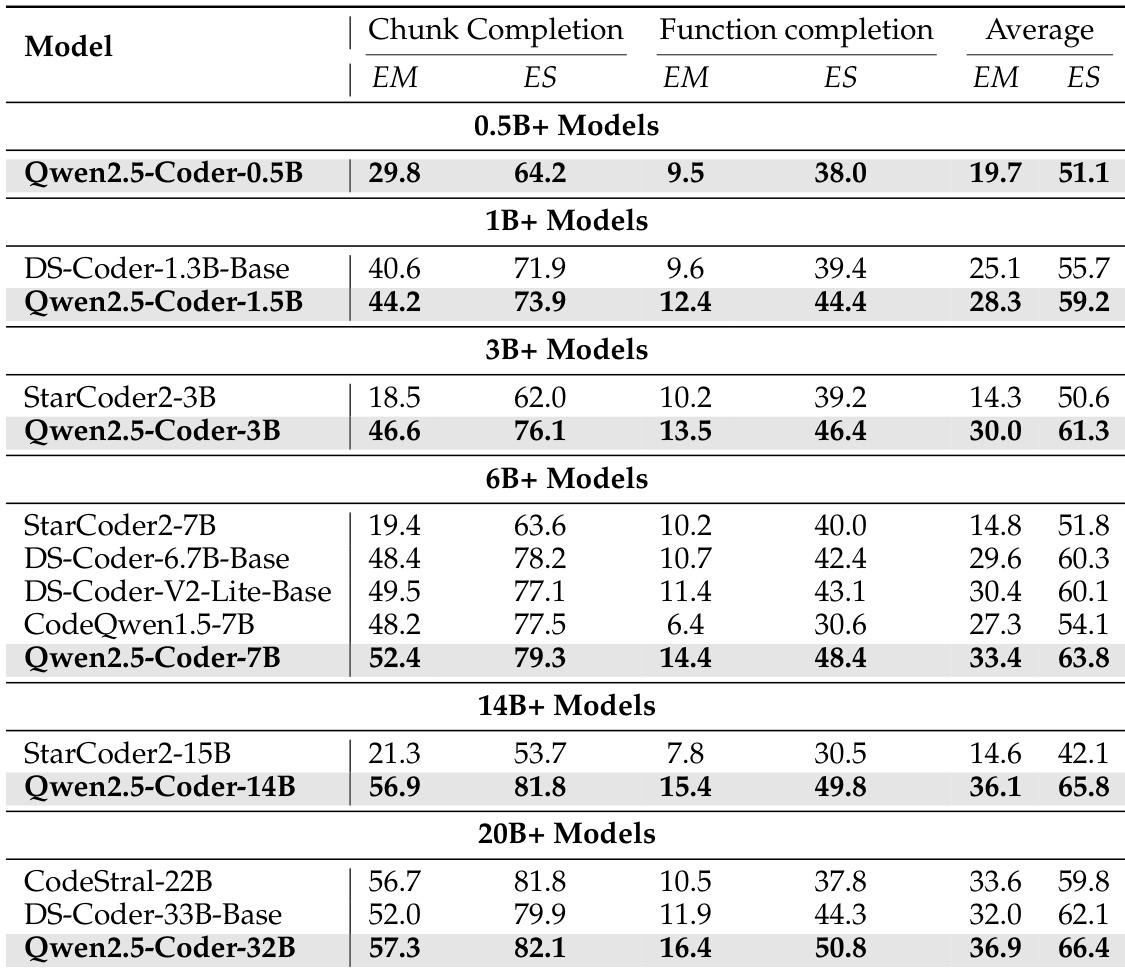
The authors use the table to compare the performance of various code completion models across different parameter sizes. Results show that Qwen2.5-Coder models consistently outperform other models of similar size, with Qwen2.5-Coder-32B achieving the highest scores in the 20B+ category, demonstrating strong performance in both chunk and function completion tasks.
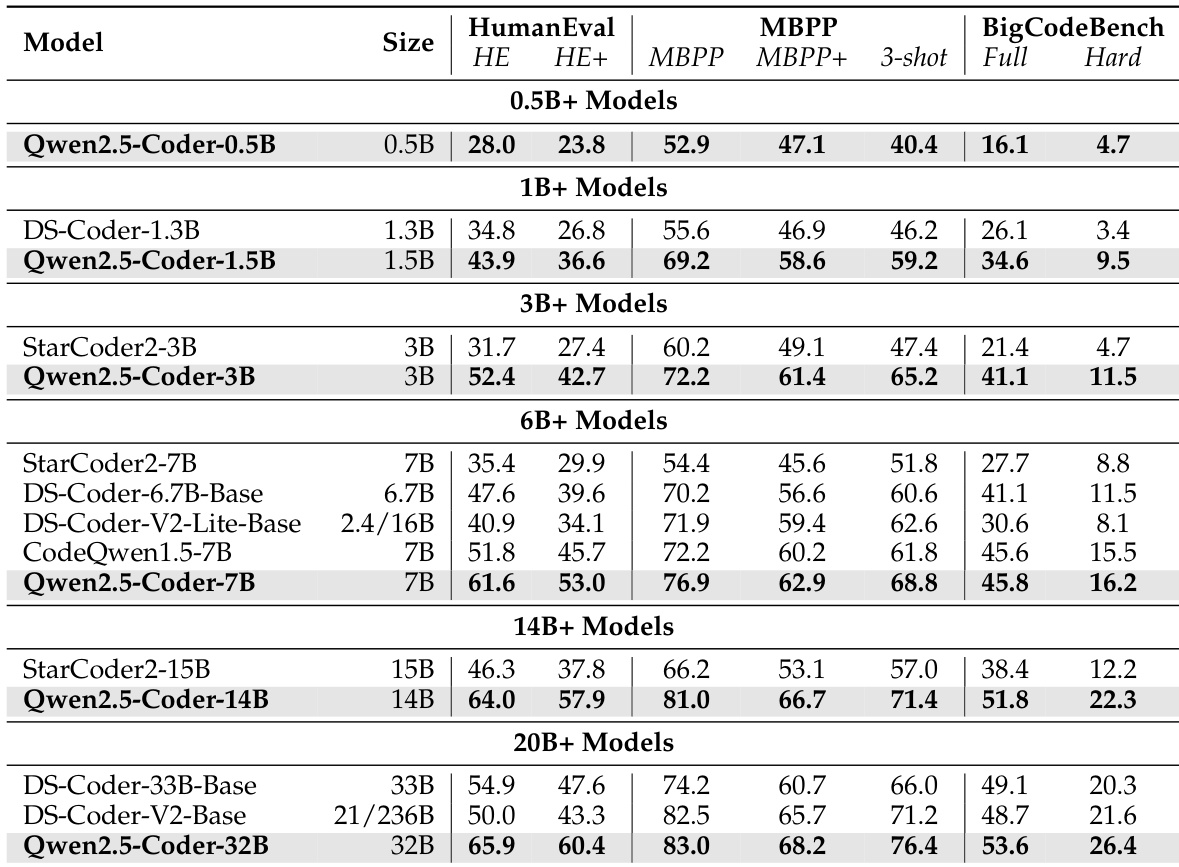
The authors use a data mixture of 70% Code, 20% Text, and 10% Math to train the Qwen2.5-Coder series, which achieves state-of-the-art performance across various code generation benchmarks. Results show that the Qwen2.5-Coder-32B model outperforms other open-source models, including larger ones, on HumanEval, MBPP, and BigCodeBench, demonstrating strong code generation capabilities.
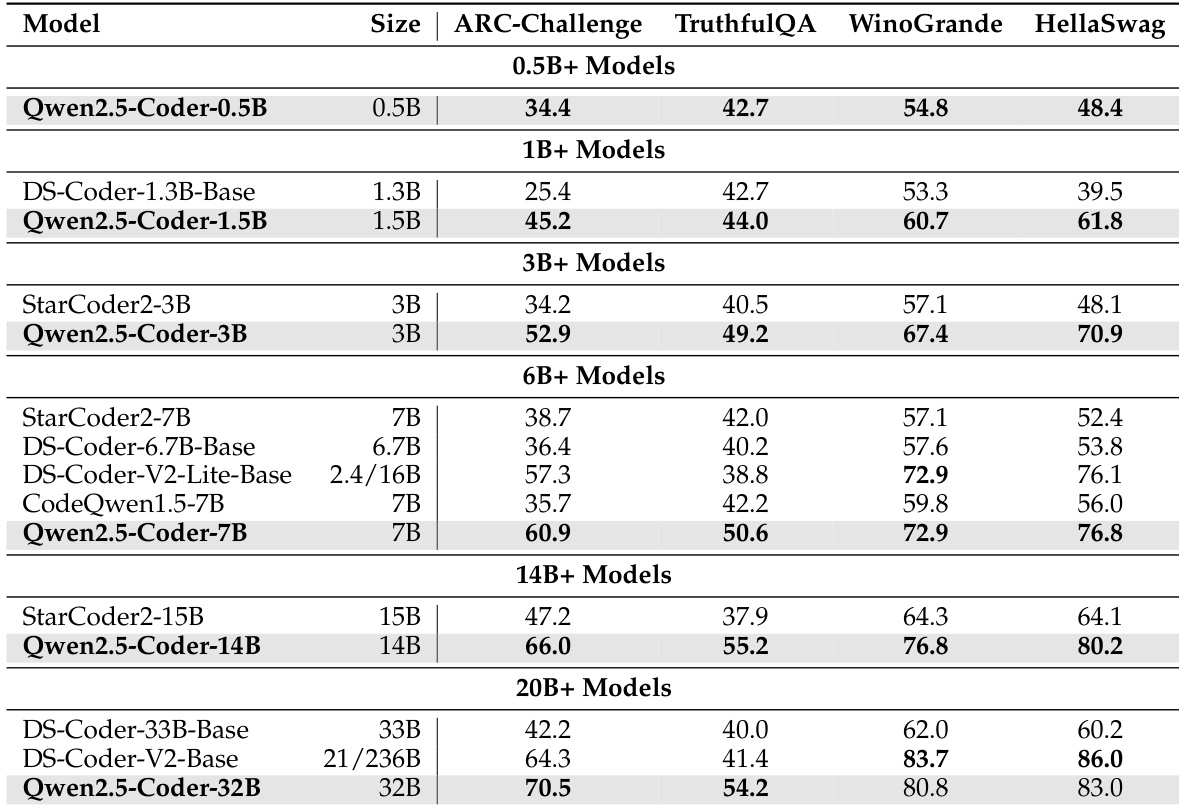
The authors use the table to compare the performance of Qwen2.5-Coder models across various sizes on general natural language benchmarks. Results show that Qwen2.5-Coder models consistently outperform other models of similar size, with the 32B model achieving the highest scores on all evaluated benchmarks.
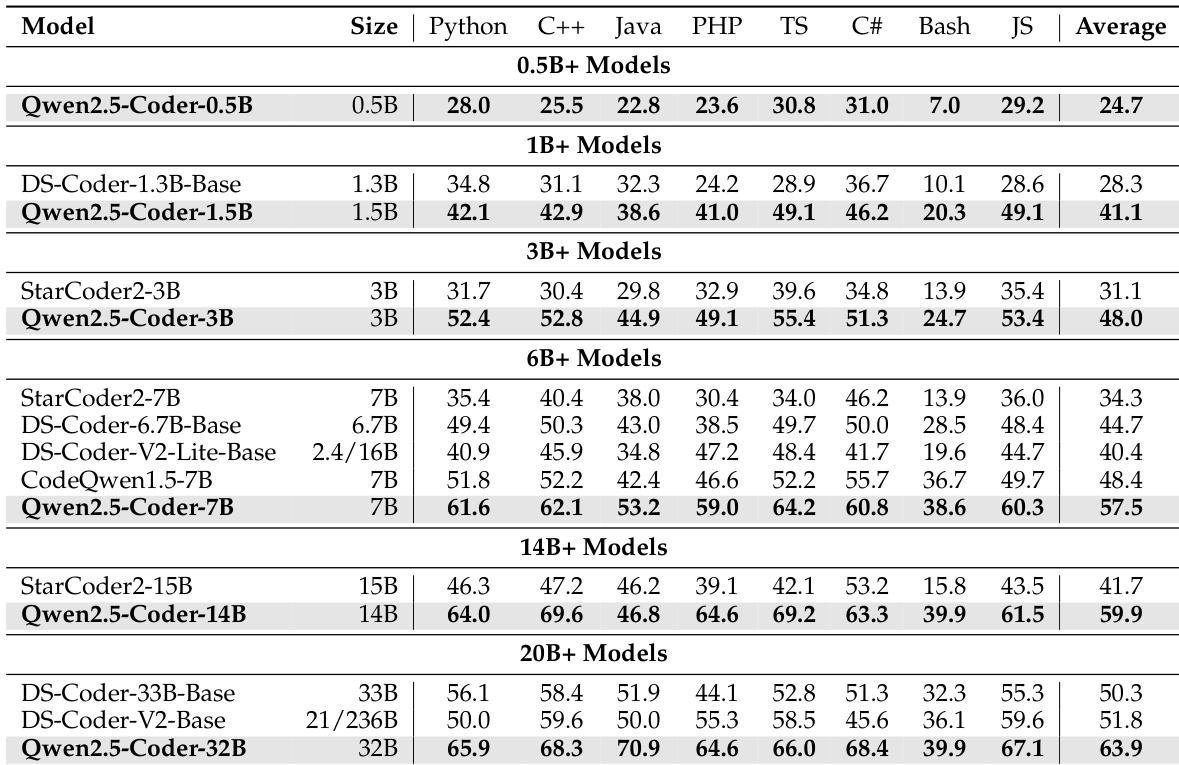
The authors use the MultiPL-E benchmark to evaluate the performance of various code models across eight programming languages. Results show that Qwen2.5-Coder-32B achieves the highest average score of 63.9, outperforming all other models in the 20B+ category and demonstrating strong multi-language capabilities.
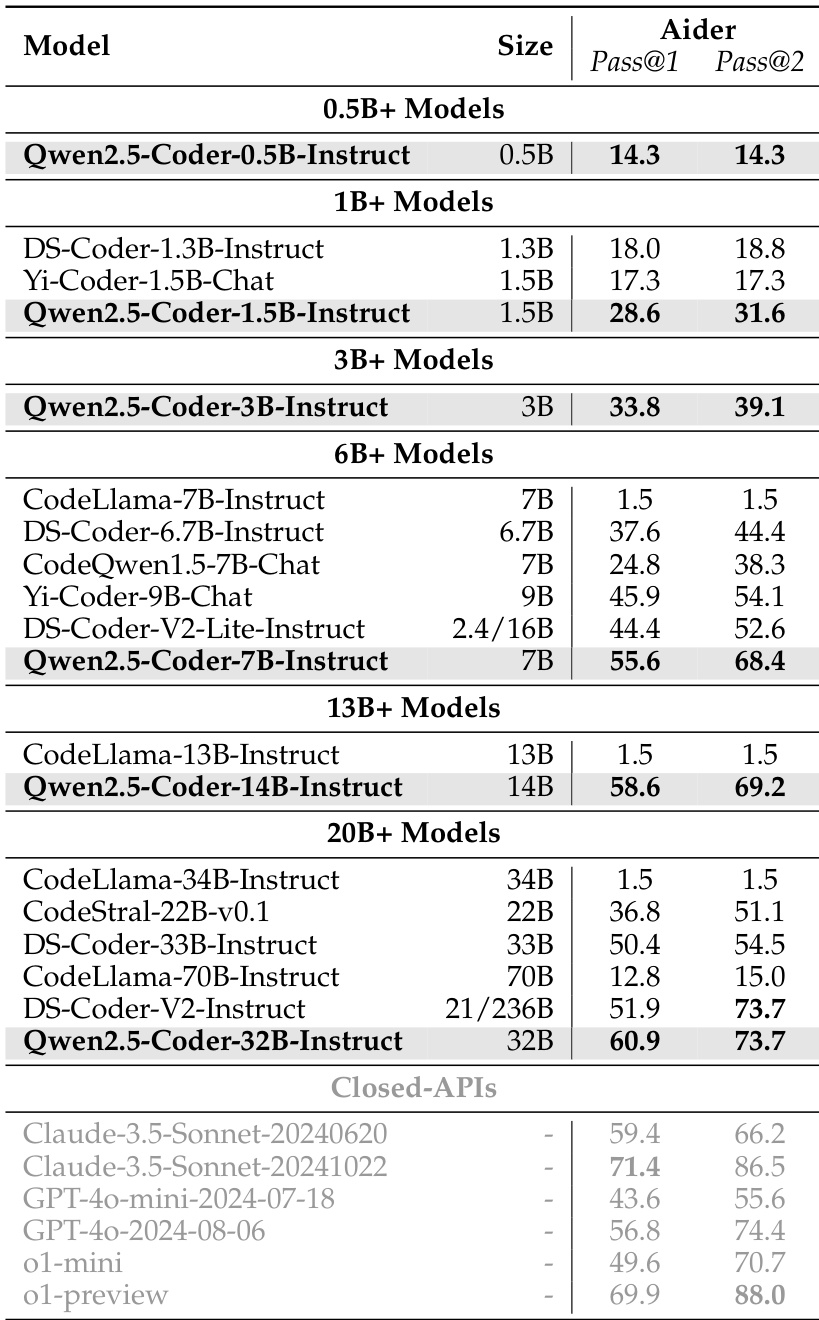
The authors evaluate the Qwen2.5-Coder series instruct models on the Aider benchmark, measuring their ability to edit code to pass unit tests. Results show that Qwen2.5-Coder-32B-Instruct achieves a Pass@1 of 60.9 and Pass@2 of 73.7, outperforming larger models like DS-Coder-33B-Instruct and CodeStral-22B-v0.1, and approaching the performance of closed-source APIs.