Command Palette
Search for a command to run...
MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for
Zero-Shot Speech Synthesis
MegaTTS 3: Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Abstract
While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces extit{MegaTTS 3}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to MegaTTS 3 to reduce the difficulty of alignment without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that MegaTTS 3 achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
One-sentence Summary
Ziyue Jiang et al. from Zhejiang University, ByteDance, and Inner Mongolia University propose MegaTTS 3, a zero-shot TTS system with a sparse alignment algorithm that guides a latent diffusion transformer, enabling robust speech-text alignment without sacrificing naturalness, while multi-condition classifier-free guidance and piecewise rectified flow enable fine-grained accent control and ultra-fast generation—achieving high-quality one-minute speech in just 8 steps.
Key Contributions
-
MegaTTS 3 addresses the limitations of existing zero-shot text-to-speech models by introducing a sparse alignment algorithm that provides coarse alignment boundaries to guide the latent diffusion transformer, improving robustness to hard sentences and reducing alignment learning difficulty without restricting the model’s search space.
-
The system employs a multi-condition classifier-free guidance strategy that enables fine-grained, independent control over speaker timbre and text content, with the text guidance scale additionally allowing adjustable accent intensity for enhanced expressiveness.
-
By integrating piecewise rectified flow, MegaTTS 3 accelerates inference to just 8 sampling steps while maintaining state-of-the-art speech quality and naturalness, achieving high-fidelity one-minute speech synthesis with minimal computational cost.
Introduction
The authors leverage recent advances in latent diffusion models and neural codec language models to address key challenges in zero-shot text-to-speech (TTS) synthesis, where systems must generate natural, expressive speech from short audio prompts without prior exposure to the target speaker. Prior work faces a fundamental trade-off: models relying on implicit alignment via attention mechanisms lack robustness and suffer from slow autoregressive generation, while those using predefined forced alignments sacrifice naturalness and flexibility by constraining the model’s search space. To overcome these limitations, the authors introduce MegaTTS 3, a sparse alignment enhanced latent diffusion transformer that injects coarse alignment boundaries derived from forced alignment into the latent sequence, enabling the model to learn fine-grained alignments efficiently without restricting its expressive capacity. This design improves robustness to duration errors and supports high-quality synthesis with only 8 sampling steps, thanks to the piecewise rectified flow technique. Additionally, the authors propose a multi-condition classifier-free guidance strategy that enables independent control over speaker timbre and text content, with the text guidance scale further allowing flexible adjustment of accent intensity—without requiring paired accent annotations. This approach achieves state-of-the-art performance in speech quality, intelligibility, and expressiveness while enabling efficient, controllable zero-shot TTS.
Dataset
- The dataset for MegaTTS 3 consists of two main components: a large-scale unlabeled training corpus and multiple benchmark test sets.
- The primary training data is Libri-Light (Kahn et al., 2020), a 60k-hour collection of unlabeled speech from LibriVox audiobooks, sampled at 16kHz.
- Speech-text alignment is generated using an internal ASR system and an external alignment tool (McAuliffe et al., 2017).
- For scalability experiments, a 600k-hour multilingual corpus is constructed, combining English and Chinese speech from YouTube, podcasts (e.g., novelfm), and public datasets like LibriLight, WenetSpeech, and GigaSpeech.
- To handle alignment at scale, a 10k-hour subset of the 600k-hour corpus is used to train a robust MFA model, which is then applied to the full dataset.
- Benchmark test sets include:
- LibriSpeech test-clean (Panayotov et al., 2015), used for zero-shot TTS evaluation following NaturalSpeech 3 (Ju et al., 2024).
- LibriSpeech-PC test-clean, used for zero-shot TTS evaluation following F5-TTS (Chen et al., 2024b).
- L2-Artic dataset (Zhao et al., 2018), used for accented TTS evaluation following Melechovsky et al. (2022) and Liu et al. (2024a).
- For scalability testing, additional test sets are collected from diverse sources: CommonVoice (Ardila et al., 2019) for noisy, real-world speech; RAVDESS (Livingstone and Russo, 2018) for emotional speech (strong-intensity samples only); LibriTTS (Zen et al., 2019) for high-quality speech; and media clips from videos, movies, and animations to test timbre simulation.
- Each test set contains 40 audio samples per source, used for both objective and subjective evaluation.
- The model is trained on 8 NVIDIA A100 GPUs, with WaveVAE trained for 2M steps and MegaTTS 3 for 1M steps, including 800k steps of pre-training and 200k steps of PeRFlow distillation.
- Training uses a mixture of data from Libri-Light and the 600k-hour multilingual corpus, with processing including ASR-based transcription and alignment extraction.
- For evaluation, objective metrics include WER (using a fine-tuned HuBERT-Large model) and SIM-O (using WavLM-TDCNN speaker embeddings) for zero-shot TTS, and MCD and pitch distribution moments (σ, γ, κ) for accented TTS.
- Subjective evaluation uses MOS via Amazon Mechanical Turk, with 40 samples per dataset, scored across three dimensions: CMOS (quality, clarity, naturalness), SMOS (speaker similarity), and ASMOS (accent similarity), with testers focused on one aspect at a time.
- The model is scaled from 0.5B to 7.0B parameters while keeping the VAE fixed, demonstrating consistent improvements in SIM-O and WER with both data and model scaling.
Method
The authors leverage a two-stage architecture for MegaTTS 3, beginning with a WaveVAE-based speech compression model followed by a latent diffusion transformer for speech generation. The overall framework is illustrated in the figure below, which shows the two primary components: the WaveVAE and the Sparse-Aligned Diffusion Transformer.
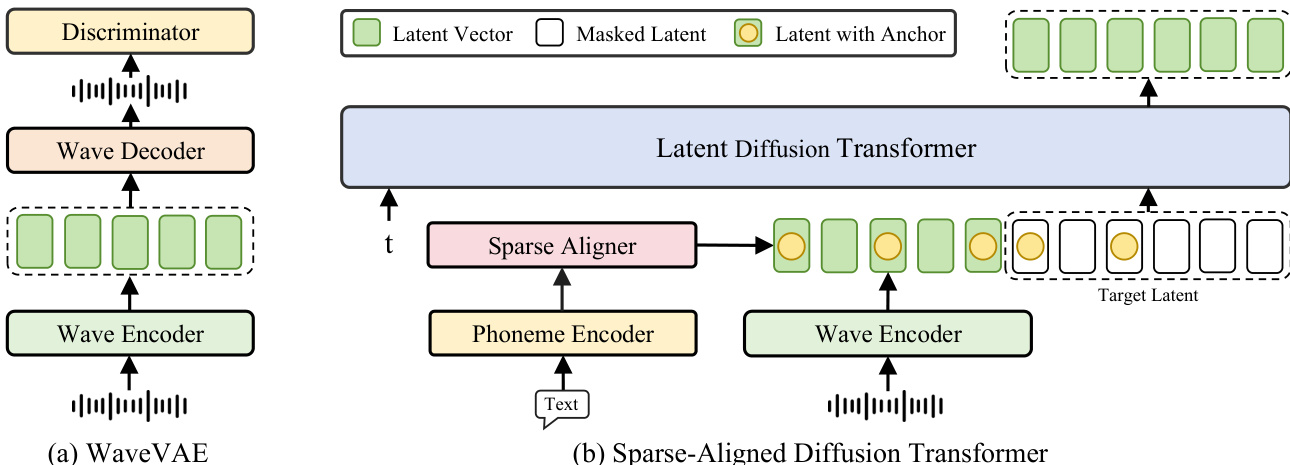
In the first stage, the WaveVAE compresses the input speech waveform s into a lower-dimensional latent representation z using a VAE encoder E. This encoder downsamples the waveform by a factor of d in length to reduce computational complexity. The latent vector z is then reconstructed into a waveform x=D(z) by a wave decoder D. To ensure high-quality reconstructions, the model employs multiple discriminators—multi-period (MPD), multi-scale (MSD), and multi-resolution (MRD)—to capture high-frequency details. The training loss for this compression model combines a spectrogram reconstruction loss Lrec, a slight KL-penalty loss LKL, and an adversarial loss LAdv.
In the second stage, the latent diffusion transformer generates speech conditioned on text and speaker information. Given a latent vector Z0 sampled from a standard Gaussian distribution and a target latent Z1 from the compressed speech distribution, the model learns a rectified flow T that maps Z0 to Z1. This flow is parameterized by a transformer network vθ, which estimates the drift force v(Zt,t) in the ordinary differential equation (ODE) dZt=v(Zt,t)dt. The transformer is trained to minimize the least squares loss over the line directions (Z1−Z0), ensuring the flow follows the optimal transport path.
The latent diffusion transformer is built using standard transformer blocks from LLAMA, with Rotary Position Embedding (RoPE) for positional encoding. During training, the latent vector sequence is randomly divided into a prompt region zprompt and a masked target region ztarget, with the prompt proportion γ drawn from a uniform distribution U(0.1,0.9). The model predicts the masked target vector z^target conditioned on zprompt and phoneme embeddings p, with the loss computed only over the masked region. This setup enables the model to learn average pronunciation from p and speaker-specific characteristics from zprompt.
To enhance alignment learning, the model incorporates a sparse alignment strategy. This strategy provides a rough alignment path by retaining only one anchor token per phoneme in the phoneme sequence, which is then downsampled and concatenated with the latent sequence. This rough alignment simplifies the learning process while allowing the model to construct fine-grained implicit alignment paths through attention mechanisms. The sparse alignment information is fed into the latent diffusion transformer via a Sparse Aligner module, which processes the phoneme encoder output and the wave encoder output to generate the aligned latent sequence.
The model further employs piecewise rectified flow acceleration to improve inference efficiency. This technique segments the flow trajectory into multiple time windows, allowing the student model to be trained on shorter ODE segments. By solving the ODE within these shortened intervals, the method reduces the number of function evaluations required for inference, significantly accelerating the generation process. The training objective for the student model is to predict the drift force within each time window, using the endpoint of the segment as the target.
Finally, the model uses a multi-condition classifier-free guidance (CFG) strategy to control the generation process. This approach steers the model output towards conditional generation by combining unconditional and conditional outputs with separate guidance scales for text and speaker conditions. The guidance scales αtxt and αspk are selected based on experimental results, allowing for flexible control over accent intensity and speaker similarity. During training, the model is exposed to all three types of conditional inputs by randomly dropping the speaker prompt and text conditions with specified probabilities.
Experiment
- MegaTTS 3 achieves state-of-the-art performance in zero-shot speech synthesis on LibriSpeech test-clean, surpassing 11 baselines including VALL-E 2, VoiceBox, and F5-TTS in SIM-O, SMOS, WER, and CMOS metrics, with a CMOS of 4.42 and WER of 4.42, demonstrating superior speaker similarity, intelligibility, and robustness.
- The proposed sparse alignment strategy significantly improves prosodic naturalness, achieving the best scores across MCD (4.42), GPE (0.31), VDE (0.29), and FFE (0.34) on LibriSpeech, outperforming both forced alignment and NaturalSpeech 3.
- In accented TTS on L2-ARCTIC, MegaTTS 3 significantly exceeds CTA-TTS in accent similarity MOS, MCD, pitch distribution statistics, CMOS, and SMOS, and shows superior accent controllability as confirmed by confusion matrix analysis.
- WaveVAE, the proposed speech codec, achieves superior reconstruction quality (PESQ, ViSQOL, MCD) at high compression rates (25 tokens/s), and enables better zero-shot TTS performance than Encodec and DAC due to its compact latent space.
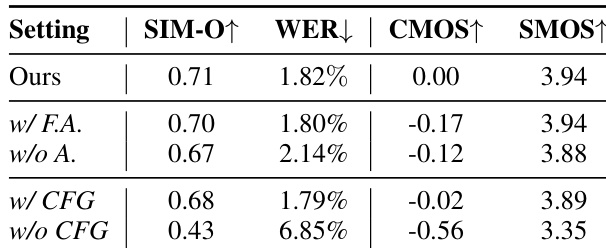
- Ablation studies confirm that sparse alignment improves CMOS by +0.17 over forced alignment, multi-condition CFG enhances control flexibility, and the CFG mechanism is essential for performance.
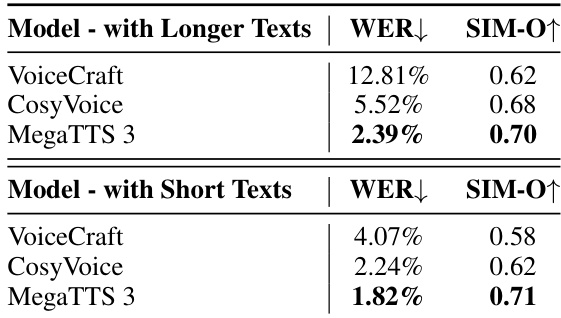
- MegaTTS 3 maintains high speech quality and intelligibility on long and challenging sentences, with no significant degradation compared to AR baselines like VoiceCraft and CosyVoice, and shows strong robustness on hard transcriptions from ELLA-V.
The authors use a controlled ablation study to evaluate the impact of different components in MegaTTS 3. Results show that the proposed sparse alignment strategy significantly improves performance, achieving the highest CMOS and SMOS scores compared to forced alignment and no alignment settings. Additionally, the multi-condition CFG mechanism further enhances the model's performance, with the full model outperforming all ablated versions across all metrics.
The authors compare the performance of MegaTTS 3 with VoiceCraft and CosyVoice on longer and shorter text samples, using WER and SIM-O as evaluation metrics. Results show that MegaTTS 3 achieves the lowest WER and highest SIM-O scores in both conditions, demonstrating its superior speech intelligibility and speaker similarity, especially for longer texts.
The authors compare several speech compression models in terms of reconstruction quality, with WaveVAE achieving the best performance across multiple metrics despite using a lower token rate. WaveVAE outperforms other codecs in PESQ, ViSQOL, and MCD, demonstrating its effectiveness in high-compression, high-fidelity speech representation.

Results show that the proposed sparse alignment in MegaTTS 3 achieves the best performance across all prosodic naturalness metrics, outperforming forced alignment and standard CFG baselines. The method with sparse alignment achieves an MCD of 4.42, GPE of 0.31, VDE of 0.29, and FFE of 0.34, indicating significant improvements in prosodic naturalness compared to the base model and other configurations.

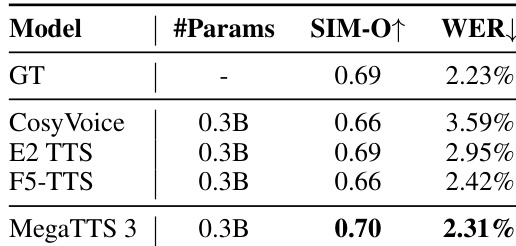
The authors use a zero-shot speech synthesis model, MegaTTS 3, and compare it against several baselines including CosyVoice, E2 TTS, and F5-TTS. Results show that MegaTTS 3 achieves the highest SIM-O score and the lowest WER among the compared models, indicating superior speaker similarity and speech intelligibility.