Command Palette
Search for a command to run...
MiniCPM4: Ultra-Efficient LLMs on End Devices
MiniCPM4: Ultra-Efficient LLMs on End Devices
Abstract
This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Furthermore, we construct a hybrid reasoning model, MiniCPM4.1, which can be used in both deep reasoning mode and non-reasoning mode. Evaluation results demonstrate that MiniCPM4 and MiniCPM4.1 outperform similar-sized open-source models across benchmarks, with the 8B variants showing significant speed improvements on long sequence understanding and generation.
One-sentence Summary
The authors propose MiniCPM4, a highly efficient LLM family optimized for end-side devices, featuring InfLLM v2 for sparse attention, UltraClean and UltraChat v2 for data efficiency, ModelTunnel v2 for training optimization, and CPM.cu for inference acceleration, enabling state-of-the-art performance on 8B and 0.5B variants with significant speed gains in long-context tasks, while MiniCPM4.1 supports hybrid reasoning modes for versatile on-device applications.
Key Contributions
- MiniCPM4 introduces InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding for long-context processing by enabling token-level sparse computation at the query level, significantly reducing computational overhead on end-side devices.
- The model leverages UltraClean, an efficient data filtering strategy using a nearly-trained LLM for quality assessment, and UltraChat v2, a comprehensive supervised fine-tuning dataset, enabling strong performance with only 8 trillion training tokens—22% of the data used by Qwen3-8B.
- Through the CPM.cu inference framework, which integrates sparse attention, model quantization, and speculative sampling, MiniCPM4 achieves up to 7× faster inference on 128K-length sequences compared to Qwen3-8B, while the hybrid MiniCPM4.1 variant supports both deep reasoning and non-reasoning modes with superior benchmark performance.
Introduction
The authors address the growing need for efficient, deployable large language models (LLMs) on end-side devices, where computational and memory constraints limit the use of large cloud-based models. Prior work faces challenges in balancing model performance with efficiency, particularly in long-context processing, high-quality data curation, and resource-constrained inference. Existing training strategies often rely on massive, noisy datasets and expensive hyperparameter searches, while inference systems lack cross-platform compatibility and optimization for edge hardware.
To overcome these limitations, the authors introduce MiniCPM4, an 8B-parameter LLM optimized for edge deployment through four key innovations. First, they propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding by enabling dynamic, kernel-optimized token-level sparsity. Second, they develop UltraClean, an efficient data filtering pipeline that uses a nearly-trained LLM to evaluate and select high-quality knowledge-intensive data, reducing pre-training data needs by 78% compared to Qwen3-8B. Third, they introduce UltraChat v2, a reasoning-intensive data generation framework that produces structured, multi-turn dialogues with deep logical chains, enhancing model reasoning capabilities. Fourth, they design a comprehensive inference stack: CPM.cu for efficient CUDA-based inference with speculative sampling and quantization, and ArkInfer, a cross-platform deployment system that enables seamless model execution across diverse hardware via a unified, extensible frontend.
These advancements enable MiniCPM4 to match larger models in performance while achieving 7× faster processing of 128K-length documents on edge devices, demonstrating a significant leap in efficiency and practical deployability for real-world applications.
Dataset
- The dataset for MiniCPM4 is composed of multiple high-quality, task-specific subsets derived from diverse sources, including academic papers, textbooks, exam syllabi, public code repositories, and curated function-calling datasets.
- Knowledge-intensive data is built from domain-specific corpora and educational materials, with LLMs generating question-answer pairs for individual knowledge points; these are then enhanced via instruction evolution and answer diversity evolution to improve stylistic and semantic variety.
- Long-context data is constructed by sampling documents from pretraining corpora (e.g., web pages, code, encyclopedic texts), generating task-oriented queries, and forming extended contexts by concatenating the original document with retrieved, potentially irrelevant documents; the context length is uniformly distributed between 8K and 64K tokens to simulate challenging, distractor-rich environments.
- Tool use data combines public datasets like xlam-function-calling-60k and glaive-function-calling-v2 with in-house data generated via in-context learning; strict filtering ensures tool schema consistency, and a chain-of-thought step is prepended to improve reasoning.
- Code interpreter data includes curated open-source datasets (e.g., CodeAct, Code-Feedback) and in-house generated problems from real-world files (CSVs, PDFs, images, videos); code snippets are preprocessed to remove external dependencies, and iterative execution in a sandboxed environment generates feedback-driven training examples, with failed attempts discarded after 10 tries.
- Survey generation data is built from 2.71 million paper abstracts sourced from Kaggle, processed through LLM-assisted rewriting and filtering to remove multimodal content and non-indexed references; a retrieval index using MiniCPM-Embedding-Light and Faiss enables efficient search, and synthetic data is generated for Query2Plan (3,750 samples) and Plan2Survey (61,684 samples) stages.
- Reverse data generation uses Claude-3.7-Sonnet to create single-tool and cross-tool queries based on tool descriptions, ensuring the model learns to invoke tools appropriately; existing tool-use datasets are converted into the MCP tool calling format, yielding ~140,000 instances.
- All data undergo dual-phase quality control: human evaluation for test data and LLM-based verification for training data, with only high-quality trajectories retained.
- The model uses this data in a mixture of training splits, with carefully balanced ratios across knowledge, reasoning, long-context, tool use, and code interpreter subsets; the overall training corpus maintains a reduced token count compared to full-scale corpora, yet achieves superior performance due to enhanced data quality and structured design.
Method
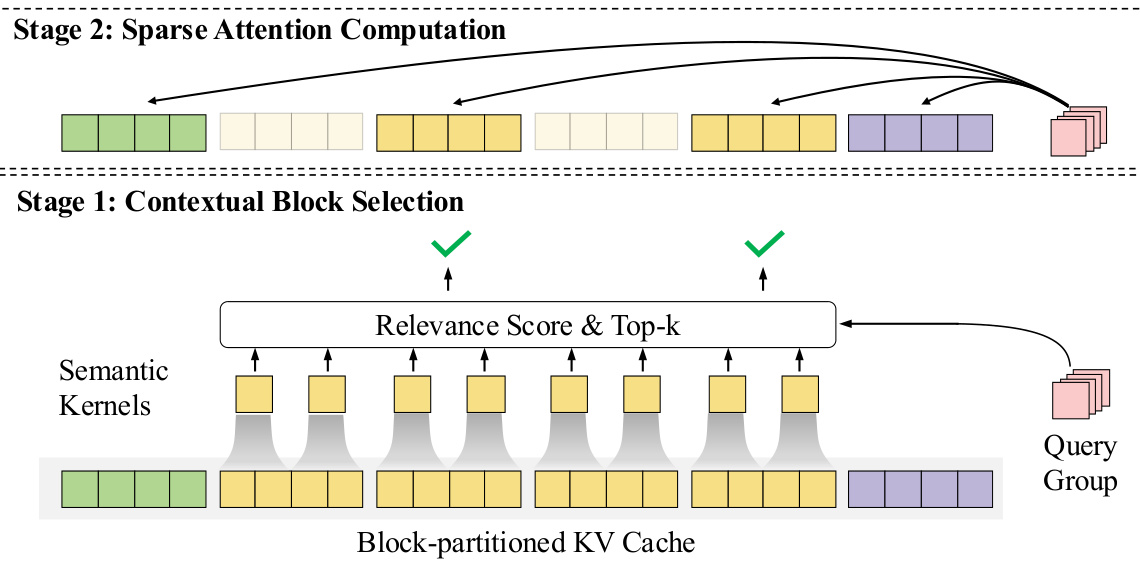
The authors leverage a comprehensive framework for developing MiniCPM4, focusing on efficient model architecture, training, and inference. The core of the model's efficiency lies in its trainable sparse attention mechanism, InfLLM v2, which enables high-performance long-context processing. The framework for InfLLM v2 operates in two distinct stages. In the first stage, contextual block selection, the model dynamically identifies relevant key-value (KV) blocks for attention computation. This process begins by partitioning the KV cache into fixed-size blocks. To compute relevance scores efficiently, InfLLM v2 introduces fine-grained semantic kernels, which are overlapping segments of the key sequence. The relevance score between a query token and a block is determined by the maximum relevance score of all semantic kernels that intersect with that block. This method avoids the computational overhead of token-level operations. The authors further enhance efficiency by requiring query heads within the same group to share the same top-k selected blocks, minimizing memory access. The second stage, sparse attention computation, involves computing attention between the query token and all tokens within the selected blocks. A critical design choice ensures that the initial tokens and those within a local sliding window are always attended to, which is achieved by setting their relevance scores to infinity. This mechanism guarantees that each query token can access both the initial context and the local window, ensuring the model's ability to capture essential short-range dependencies. The overall process is illustrated in the framework diagram, which shows the query group interacting with the block-partitioned KV cache through the relevance score and top-k selection module to identify the relevant blocks for attention computation.
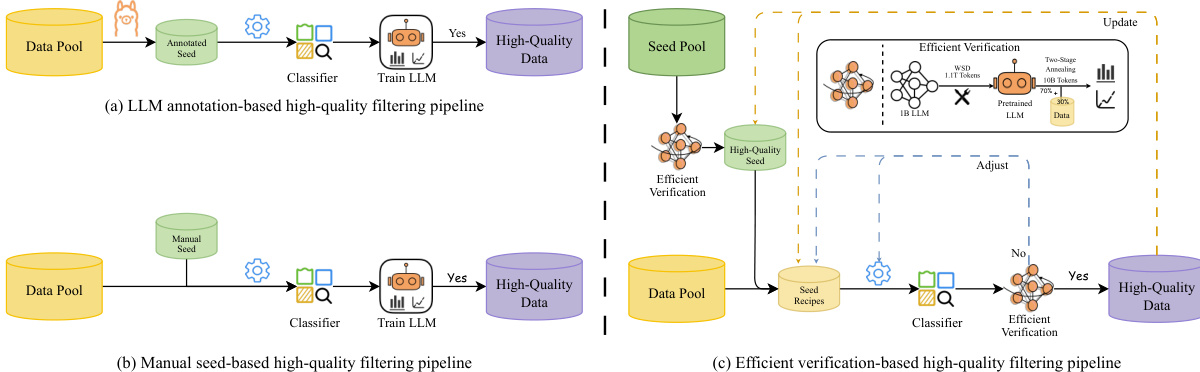
The training process for MiniCPM4 is designed for efficiency and effectiveness, utilizing a combination of advanced data filtering, pre-training strategies, and post-training techniques. A key component is the UltraClean data filtering and generation strategy, which ensures the quality of the training data. The authors propose an efficient verification-based filtering pipeline, as shown in the figure, which uses a pre-trained LLM to verify the quality of data generated from a seed pool. This approach is more efficient and accurate than traditional model-based filtering methods that rely on human expertise. The pre-training phase is optimized through the ModelTunnel v2 system, which allows for efficient strategy search on small models and transfer to large models, reducing the experimental cost. The pre-training objective is enhanced by adopting multi-token prediction (MTP), which provides denser supervision signals compared to traditional next-token prediction. This is implemented by adding additional prediction heads to the model, which predict multiple tokens ahead. The training infrastructure is optimized with an FP8 mixed-precision framework, which leverages the powerful FP8 computing capabilities of modern GPUs. This involves online block-wise FP8 quantization for both parameters and activations, with FP8 used for linear projections in the forward and backward passes, while gradients are computed in BF16 to maintain stability.
Post-training is conducted to enhance the model's foundational capabilities and deep reasoning. The authors construct a comprehensive supervised fine-tuning (SFT) dataset, UltraChat v2, which covers a wide range of skills including knowledge application, reasoning, tool use, and long-context processing. This dataset is generated through a synthetic data framework that systematically develops tracks for different skill areas. To further improve deep reasoning, the model undergoes reinforcement learning (RL) with a novel chunk-wise rollout strategy. This strategy addresses the unbalanced load challenge in RL by breaking down long responses into smaller chunks. The policy model generates trajectories of a fixed chunk length for all input samples. Trajectories that are completed or reach the maximum generation length are used for training, while incomplete ones are stored for later use. This approach maximizes GPU utilization and reduces computational waste. To ensure training stability, the authors introduce several techniques, including chunk-level importance sampling to account for distributional differences, dual-clip to constrain policy updates, and KL regularization with dynamic reference updates. The policy optimization objective is reformulated to support this strategy, incorporating a clip function to limit the policy update range and a KL penalty to maintain stability.

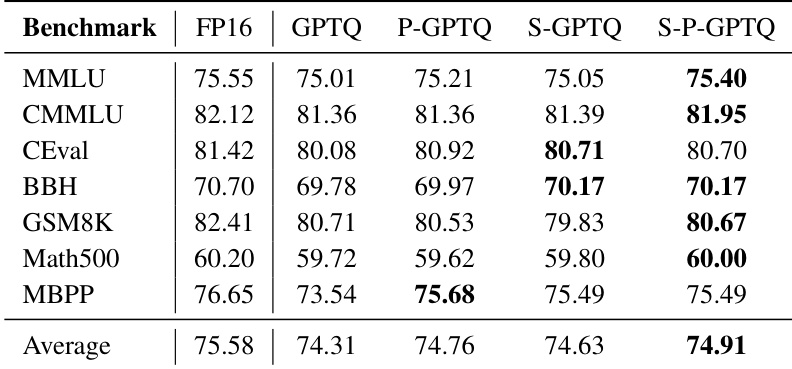
The inference system for MiniCPM4 is built on a lightweight and efficient CUDA framework, CPM.cu, which integrates several key optimizations. A central component is speculative sampling, a technique that accelerates inference by using a lightweight draft model to generate candidate token sequences, which are then verified in parallel by the target model. The authors optimize this process by introducing FR-Spec, a frequency-ranked speculative sampling framework. FR-Spec reduces the computational overhead of the draft model's language modeling head by restricting its vocabulary to a subset of high-frequency tokens, which can reduce the overhead by up to 75%. This is achieved by constructing a reduced vocabulary subset based on token frequency analysis and modifying the drafting computation to operate only on this subset. The framework also supports efficient quantization, including a novel prefix-aware post-training quantization method, P-GPTQ, which eliminates initial token bias during Hessian computation to improve quantization fidelity. Furthermore, the framework integrates the InfLLM v2 sparse attention kernel to support long-context processing, and applies sliding window attention to the draft model to minimize first-token latency. The overall architecture is designed to be cross-platform compatible, allowing for efficient deployment across diverse end-side hardware.
Experiment
- Evaluated chunk-wise rollout strategy on DAPO dataset: reduced sampling time per step with smaller chunk sizes, but minimal improvement in total training time due to increased log probability computations; demonstrated improved GPU utilization and mitigation of sampling bottlenecks.
- Trained MiniCPM4 models with optimized settings: used 256 batch size, 1e-5 learning rate, KL penalty (0.001), and 32K max response length; achieved strong performance with 16 rollouts per query and temperature/top-p set to 1.0.
- Trained ternary models BitCPM4-0.5B and BitCPM4-1B using 350B tokens via QAT: BitCPM4-0.5B outperformed qwen3-0.6B on knowledge tasks (MMLU, CMMLU, C-EVAL), and BitCPM4-1B matched 2B-parameter models; achieved competitive results with only 10% of BitNet-2B’s training tokens.
- MiniCPM4-0.5B and MiniCPM4-8B achieved state-of-the-art performance on standard benchmarks (MMLU, BBH, GSM8K, HumanEval, etc.): outperformed larger models like Llama3.2-1B, Gemma3-12B, and Phi4-14B; achieved comparable results to Qwen3 with only 22% of its training data (8T vs 36T tokens).
- MiniCPM4.1-8B achieved 79.93 average score on deep reasoning tasks (Table 9), with sparse attention showing only 0.79-point drop vs full attention (79.14), confirming minimal performance loss with significant computational gains.
- MiniCPM4 demonstrated strong long-context capabilities: achieved 100% accuracy on 128K needle-in-a-haystack task with 5% attention sparsity; maintained high performance on RULER benchmark (85.84% weighted average with sparse attention vs 88.93% with full attention).
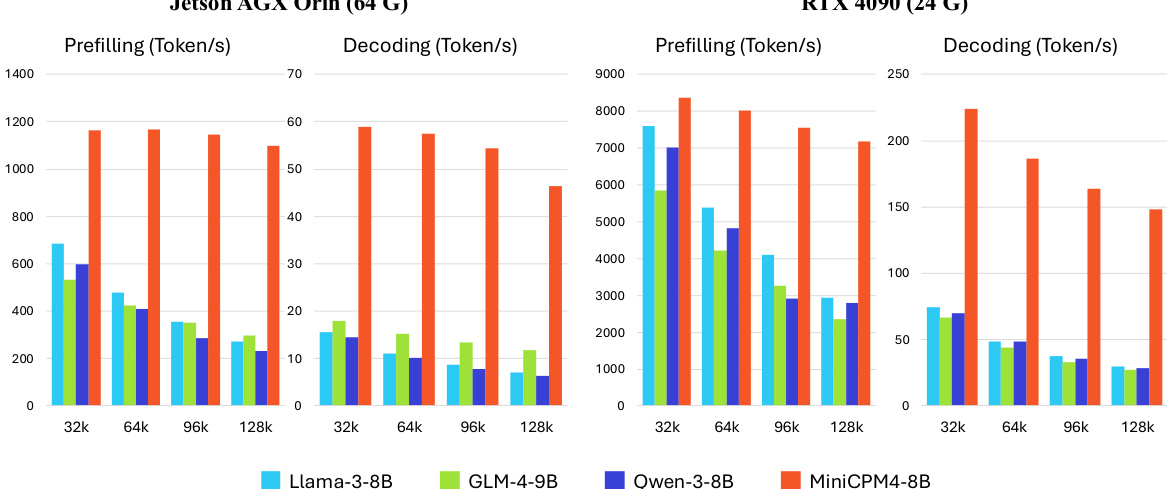
- Achieved up to 7x decoding speedup on Jetson AGX Orin compared to Qwen3-8B, with efficiency gains increasing with sequence length due to sparse attention reducing memory access overhead.
- MiniCPM4-Survey outperformed open-source (WebThinker) and closed-source (AutoSurvey, OpenAI Deep Research) baselines in relevance, coverage, depth, novelty, and factuality; showed significant improvement from SFT to RL, indicating effective reinforcement learning for planning and exploration.
- MiniCPM4 demonstrated superior MCP tool calling accuracy over Qwen3-8B, especially on specialized tools (e.g., arXiv, airbnb), due to learning from task-specific demonstrations.
The authors use a chunk-wise rollout strategy to evaluate training efficiency, comparing it against a naive full-response generation approach. Results show that reducing the chunk size decreases sampling time per step, improving GPU utilization, but smaller chunks increase log probability computations, limiting overall training efficiency gains.
The authors evaluate the inference efficiency of MiniCPM4-8B against several open-source models on two edge chips, Jetson AGX Orin and RTX 4090, across sequence lengths from 32K to 128K. Results show that MiniCPM4-8B achieves significant speedup in both prefilling and decoding, particularly on the Jetson AGX Orin, where it achieves approximately 7x faster decoding than Qwen3-8B, with the efficiency advantage increasing as sequence length grows.
The authors evaluate MiniCPM4.1 with full and sparse attention mechanisms on the RULER benchmark, showing that both variants achieve high performance, with the full attention model scoring 88.93 on the weighted average and the sparse attention model scoring 85.84. While the sparse variant shows a modest decrease in overall performance, it maintains competitive results across most tasks and offers significant computational efficiency gains, making it suitable for resource-constrained applications.

The authors use a chunk-wise rollout strategy to evaluate training efficiency, comparing it against a naive full-response generation approach. Results show that reducing the chunk size decreases sampling time per step, but further reduction from 8k to 4k tokens does not improve total training time due to increased log probability computations, indicating a trade-off between sampling speed and computational overhead.

The authors use a chunk-wise rollout strategy to evaluate training efficiency, with results showing that reducing chunk size decreases sampling time per step but has minimal impact on total training time due to increased log probability computations. The S-P-GPTQ method achieves the highest average score of 74.91, outperforming other quantization methods across most benchmarks while maintaining competitive performance.