Command Palette
Search for a command to run...
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video
Diffusion
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang Xun Li Zhengqi He Guande Zhou Mingyuan Shechtman Eli
Abstract
We introduce Self Forcing, a novel training paradigm for autoregressive video diffusion models. It addresses the longstanding issue of exposure bias, where models trained on ground-truth context must generate sequences conditioned on their own imperfect outputs during inference. Unlike prior methods that denoise future frames based on ground-truth context frames, Self Forcing conditions each frame's generation on previously self-generated outputs by performing autoregressive rollout with key-value (KV) caching during training. This strategy enables supervision through a holistic loss at the video level that directly evaluates the quality of the entire generated sequence, rather than relying solely on traditional frame-wise objectives. To ensure training efficiency, we employ a few-step diffusion model along with a stochastic gradient truncation strategy, effectively balancing computational cost and performance. We further introduce a rolling KV cache mechanism that enables efficient autoregressive video extrapolation. Extensive experiments demonstrate that our approach achieves real-time streaming video generation with sub-second latency on a single GPU, while matching or even surpassing the generation quality of significantly slower and non-causal diffusion models. Project website: http://self-forcing.github.io/
One-sentence Summary
The authors from Adobe Research and The University of Texas at Austin propose Self Forcing, a training paradigm for autoregressive video diffusion models that uses autoregressive rollout with KV caching to condition frame generation on self-generated outputs, overcoming exposure bias by enabling holistic video-level supervision; this approach achieves real-time streaming video generation with sub-second latency on a single GPU while matching or exceeding the quality of slower, non-causal models.
Key Contributions
- Self Forcing introduces a novel training paradigm for autoregressive video diffusion models that directly addresses exposure bias by performing autoregressive self-rollout during training, where each frame is conditioned on previously generated frames rather than ground-truth context, thereby aligning training and inference distributions.
- The method leverages holistic distribution-matching losses (e.g., SiD, DMD, GAN) applied to full generated video sequences, enabling the model to learn from and correct its own prediction errors, which mitigates error accumulation and improves long-term temporal coherence.
- Through a few-step diffusion backbone and stochastic gradient truncation, Self Forcing achieves real-time video generation at 17 FPS with sub-second latency on a single GPU, matching or exceeding the quality of slower, non-causal diffusion models while enabling efficient autoregressive extrapolation via a rolling KV cache.
Introduction
Autoregressive (AR) video diffusion models enable real-time, interactive video generation by producing frames sequentially, which is essential for applications like live streaming, gaming, and robotics. However, these models typically suffer from exposure bias—training on ground-truth context frames while relying on their own noisy predictions at inference—leading to error accumulation and degraded quality. Prior approaches like Teacher Forcing and Diffusion Forcing attempt to align training with inference but still fail to bridge the train-test distribution gap, as they either use perfect context or noisy context in ways that do not reflect actual autoregressive rollout. The authors propose Self Forcing, a novel training paradigm that performs autoregressive self-rollout during training, where each frame is denoised based on previously generated frames rather than ground truth. This forces the model to learn from its own errors and enables the use of holistic distribution-matching losses (e.g., SiD, DMD) on full generated videos, aligning training and inference distributions. Despite the sequential nature of self-rollout, the method is efficiently implemented in a post-training stage using gradient truncation and a rolling KV cache, achieving real-time generation at 17 FPS on a single H100 GPU with superior quality compared to prior models.
Method
The authors leverage a transformer-based autoregressive video diffusion model architecture, which combines the chain-rule decomposition of autoregressive models with denoising diffusion processes to generate video sequences. The joint distribution of a video sequence x1:N is factorized as p(x1:N)=∏i=1Np(xi∣x<i), where each conditional distribution p(xi∣x<i) is modeled using a diffusion process. This process generates a frame by progressively denoising an initial Gaussian noise conditioned on the previously generated frames. The model operates in a compressed latent space, encoded by a causal 3D variational autoencoder (VAE), and implements the autoregressive decomposition via causal attention mechanisms. The core innovation of the proposed method, Self Forcing, lies in its training paradigm, which directly addresses the exposure bias inherent in standard training approaches.
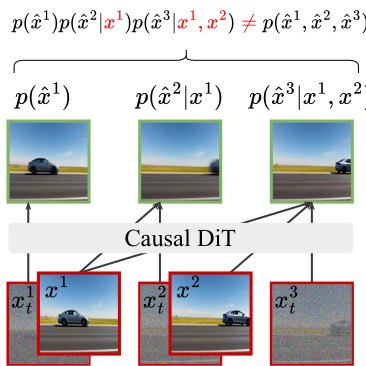
The standard training paradigms, Teacher Forcing (TF) and Diffusion Forcing (DF), train the model on the entire video in parallel, enforcing causal dependencies with custom attention masks. In TF, the model is trained to denoise each frame conditioned on clean, ground-truth context frames x<i. In DF, the context consists of noisy frames xtjj<i, and the model is trained to predict the noise added to each frame. Both methods use a frame-wise mean squared error (MSE) loss to minimize the difference between the predicted and true noise. In contrast, the Self Forcing training method innovatively employs key-value (KV) caching during training to mirror the autoregressive inference process. As shown in the figure below, this approach conditions the generation of each frame on previously self-generated outputs, enabling a holistic loss at the video level.

To make this computationally feasible, the authors use a few-step diffusion model to approximate each conditional distribution ptheta(xi∣x<i). This involves a truncated denoising process where the model performs a limited number of denoising steps, starting from a noisy input. The model's distribution is implicitly defined as a composition of these few denoising steps. To further reduce computational cost and memory consumption, a stochastic gradient truncation strategy is employed. This strategy limits backpropagation to only the final denoising step of each frame and randomly samples a denoising step s from [1,T] for each training sample, ensuring all intermediate steps receive supervision. Additionally, gradient flow into the KV cache embeddings is restricted to prevent gradients from the current frame from affecting the previous frames.
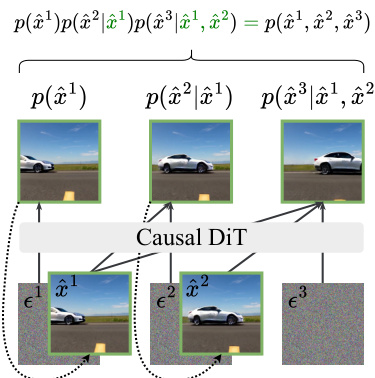
The training process is further enhanced by using holistic, video-level distribution matching losses, which align the distribution of the generated video sequence ptheta(x1:N) with the data distribution ptextdata(x1:N). This is achieved by injecting noise into both distributions and matching their noisy versions. The authors consider three approaches: Distribution Matching Distillation (DMD), Score Identity Distillation (SiD), and Generative Adversarial Networks (GANs). These methods minimize different divergence measures between the distributions, such as the reverse Kullback-Leibler divergence, Fisher divergence, or Jensen-Shannon divergence. This holistic approach fundamentally transforms the training dynamics by sampling context frames from the model's own distribution ptheta, effectively addressing exposure bias and forcing the model to learn from its own imperfections.

A key advantage of the autoregressive model is its ability to generate arbitrarily long videos. To enable efficient long video generation, the authors propose a rolling KV cache mechanism. This mechanism maintains a fixed-size KV cache that stores the KV embeddings of the most recent L frames. When generating a new frame, the oldest KV cache entry is evicted before adding the new one, enabling endless frame generation with a time complexity of O(TL). This approach avoids the need for recomputing the KV cache, which is required in prior methods, and allows for more efficient extrapolation. To mitigate flickering artifacts caused by distribution mismatch, the authors restrict the attention window during training so the model cannot attend to the first chunk when denoising the final chunk, simulating the conditions of long video generation. The overall training and inference processes are detailed in Algorithm 1 and Algorithm 2, respectively.
Experiment
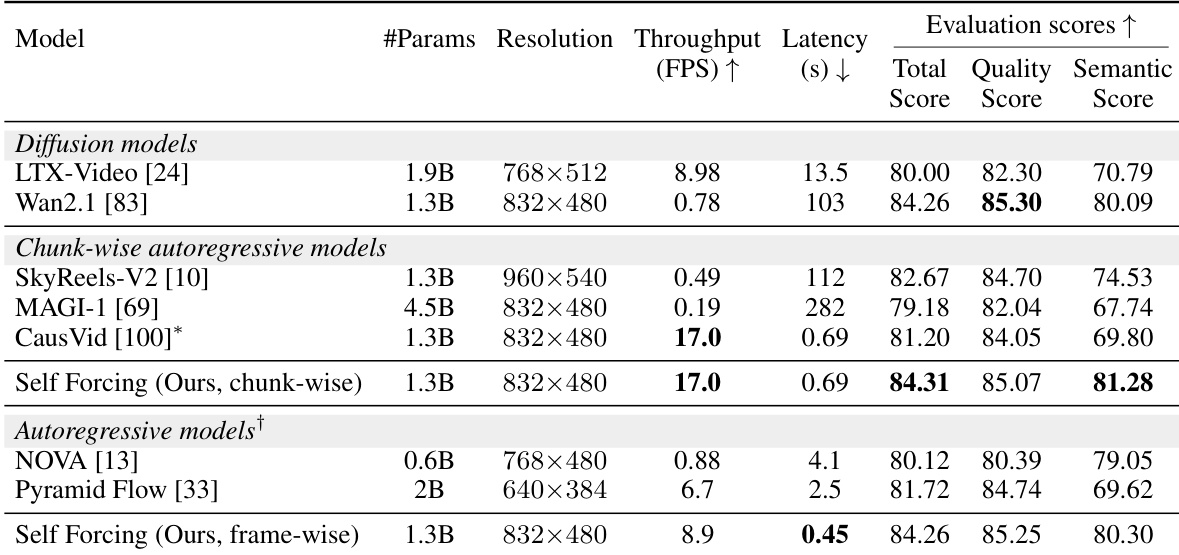
- Chunk-wise and frame-wise autoregressive variants of Self Forcing are evaluated on video generation quality, real-time performance, and efficiency. The chunk-wise variant achieves 17.0 FPS throughput with sub-second latency, surpassing diffusion baselines in both speed and quality.
- On the VBench benchmark, Self Forcing achieves the highest scores across all dimensions, excelling in semantic alignment (scene, object class, human action) and frame-wise quality (aesthetic and imaging quality), with the frame-wise variant showing more dynamic motion but lower temporal consistency.
- User preference studies show Self Forcing is consistently preferred over all baselines, including the initialization model Wan2.1-1.3B, demonstrating superior visual quality and prompt alignment.
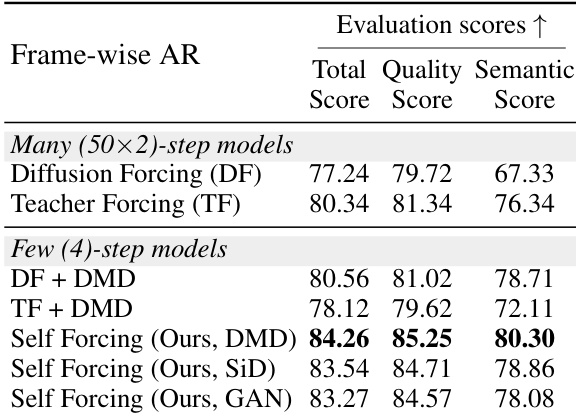
- Ablation studies confirm Self Forcing outperforms Teacher Forcing, Diffusion Forcing, and CausVid-like methods across different distribution matching objectives (DMD, SiD, GAN), maintaining consistent performance in both chunk-wise and frame-wise settings despite error accumulation challenges.
- The rolling KV cache with local attention training effectively mitigates visual artifacts during video extrapolation, while preserving high throughput (16.1 FPS).
- Self Forcing training is computationally efficient, converging in ~1.5 hours on 64 H100 GPUs, outperforming alternatives in both per-iteration speed and quality under the same wall-clock budget due to optimized attention kernels and high GPU utilization.
- The method is data-free for DMD/SiD implementations, enabling autoregressive video generation without additional video data, and supports real-time applications such as live streaming.
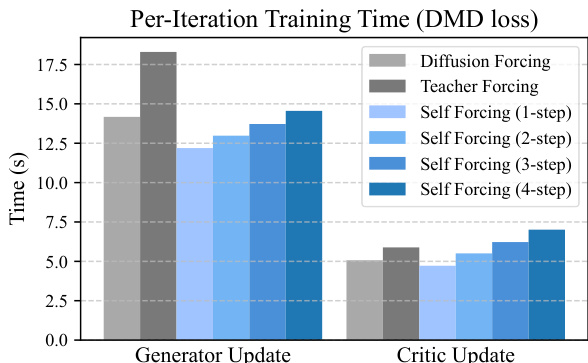
Results show that Self Forcing achieves comparable per-iteration training time to Teacher Forcing and Diffusion Forcing for generator updates, while maintaining lower training time for critic updates across all variants. The training efficiency of Self Forcing is attributed to its use of full attention and optimized kernels, which enable high GPU utilization despite its sequential nature.
Results show that the Self Forcing model with the DMD objective achieves the highest total and semantic scores among all compared methods, outperforming both diffusion-based and autoregressive baselines. The frame-wise variant of Self Forcing further improves quality metrics, particularly in semantic alignment, while maintaining strong performance across all evaluation dimensions.
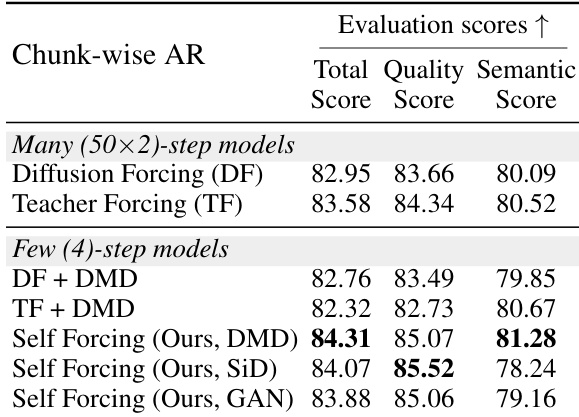
Results show that Self Forcing with the DMD objective achieves the highest total, quality, and semantic scores among all compared models, outperforming both diffusion-based and autoregressive baselines. The frame-wise AR variant of Self Forcing maintains strong performance across all metrics while offering the lowest latency, making it suitable for real-time applications.
The authors use Self Forcing to train autoregressive video models, achieving the highest VBench scores and real-time throughput among all compared models. Results show that the chunk-wise variant achieves 17.0 FPS with a total score of 84.31, while the frame-wise variant reduces latency to 0.45 seconds, maintaining strong quality and enabling low-latency applications.
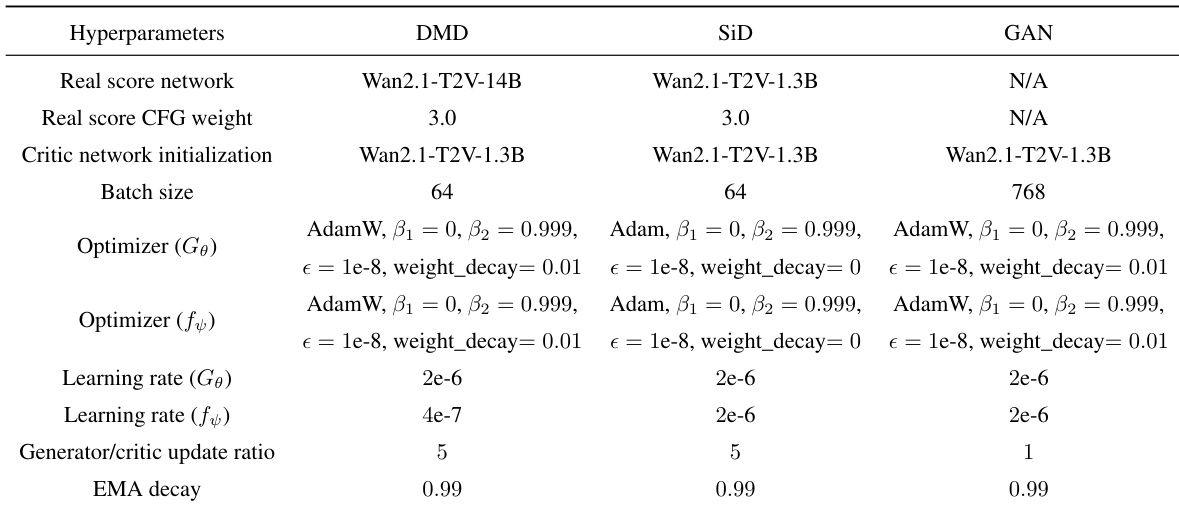
The authors use a consistent optimization setup across DMD, SiD, and GAN objectives, with AdamW as the optimizer and similar learning rates for both generator and critic networks. The only notable differences are the batch size, which increases to 768 for GAN, and the generator/critic update ratio, which is reduced to 1 for GAN, while all other hyperparameters remain identical.