Command Palette
Search for a command to run...
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid
Mamba-Transformer Reasoning Model
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Abstract
We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
One-sentence Summary
NVIDIA introduces Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer reasoning model that achieves state-of-the-art accuracy on reasoning benchmarks while delivering up to 6× higher inference throughput than similarly-sized models like Qwen3-8B, enabled by a compressed architecture derived from a 12B base model via Minitron-based pruning and distillation; the model supports 128k context length inference on a single A10G GPU, with fine-grained control over thinking budget during generation.
Key Contributions
- Nemotron Nano 2 introduces a hybrid Mamba-Transformer architecture that replaces most self-attention layers with Mamba-2 blocks, enabling significantly faster inference for long reasoning traces while maintaining high accuracy, particularly in long-context generation tasks up to 128k tokens.
- The model is built on a 12-billion-parameter base (Nemotron-Nano-12B-v2-Base) pre-trained on 20 trillion tokens using FP8 precision and a Warmup-Stable-Decay learning rate schedule, with continuous pre-training extending its long-context capability without sacrificing performance on standard benchmarks.
- Through a multi-stage post-training pipeline including SFT, GRPO, DPO, and RLHF, the model achieves on-par or better accuracy than similarly-sized models like Qwen3-8B on reasoning tasks, while delivering up to 6× higher throughput in high-generation scenarios such as 8k input and 16k output tokens.
Introduction
The authors leverage NVIDIA's Nemotron Nano 2, a compact language model designed for efficient deployment in resource-constrained environments, to address the growing demand for lightweight, high-performance AI models in edge and real-time applications. Prior work in small language models often faced trade-offs between model size, inference speed, and task accuracy, particularly in long-context and safety-critical scenarios. The main contribution lies in a holistic system-level optimization across data curation, FP8 precision training, model architecture, long-context handling, alignment, compression, and evaluation—enabling a highly efficient, safe, and deployable model that maintains strong performance despite its small footprint.
Dataset
- The dataset for Nemotron-Nano-12B-v2-Base comprises curated and synthetically-generated data, drawn from multiple sources including Common Crawl, Wikipedia, FineWeb-2, GitHub, textbooks, and academic papers.
- Curated data includes:
- English web crawl data from 10 recent Common Crawl snapshots (CC-MAIN-2024-33 to CC-MAIN-2025-13), supplemented with CC-NEWS data up to April 23, 2025; filtered only for English and globally de-duplicated via fuzzy matching.
- Multilingual data in 15 languages (Arabic, Chinese, Danish, Dutch, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Swedish, Thai) extracted from three Common Crawl snapshots, processed with heuristic filtering and MinHash-based fuzzy de-duplication; augmented with Wikipedia and FineWeb-2 data.
- Math data processed via a custom pipeline: raw HTML from 98 Common Crawl snapshots was rendered with lynx, cleaned with Phi-4, filtered using FineMath, and decontaminated with LLM Decontaminator, resulting in two corpora—Nemotron-CC-Math-3+ (133B tokens) and Nemotron-CC-Math-4+ (52B tokens, top-quality subset).
- Code data sourced from GitHub, filtered via license detection (only permissive licenses retained, as listed in Appendix A), and processed with both exact and fuzzy (MinHash LSH) de-duplication; further filtered using heuristics from OpenCoder to remove low-value files.
- Synthetic data includes:
- STEM questions generated from GSM8K, MATH, AOPS, Stemez², and permissively licensed textbooks, expanded through three iterative rounds using Qwen3-30B-A3B, Qwen3-235B-A22B, Deepseek-R1, and Deepseek-V3 with prompts for similar, harder, and varied questions; solutions generated and duplicates removed via fuzzy de-duplication.
- Regenerated Nemotron-MIND dataset using Nemotron-CC-Math-4+ as input, producing a 73B-token synthetic math dialogue corpus with structured prompts (e.g., Teacher–Student, Debate) and 5K-token chunking.
- Multilingual Diverse QA data generated by translating English Diverse QA into 15 languages using Qwen3-30B-A3B, and by generating QA pairs directly from multilingual Wikipedia articles.
- Synthetic code QA pairs created by prompting an LLM to generate questions from code snippets, solve them, and filter via AST parsing and heuristics.
- Academic QA pairs generated from undergraduate and graduate-level textbooks and papers in math, chemistry, biology, physics, and medicine; snippets were embedded and retrieved via Milvus vector search, then used to generate multiple-choice and free-response QA pairs with justifications.
- SFT-style data covering code, math, MMLU-style knowledge, and general instruction following, synthesized from prior work.
- Fundamental reasoning SFT data derived from LSAT, LogiQA, and AQuA-RAT datasets, expanded using DeepSeek-V3 and Qwen3-30B-A3B with chain-of-thought generation and majority voting for final solution selection (4B and 4.2B tokens respectively).
- The pretraining data mixture consists of 13 categories, with weights assigned based on data quality. The mixture evolves across three curriculum phases: Phase 1 emphasizes diversity, Phase 2 and 3 prioritize high-quality data like Wikipedia. The multilingual data mix was optimized via ablation, with DiverseQA-crawl (translated from English) receiving the highest weight due to superior performance on Global-MMLU.
- Data processing includes:
- Fuzzy de-duplication using MinHash LSH for all major subsets.
- Metadata construction for academic data, including educational difficulty, subject, and quality labels.
- Line-by-line translation with language identification and bracket formatting for multilingual post-training data to ensure quality.
- Use of a robust verification pipeline for tool-calling data, simulating multi-agent conversations with rule-based validation to retain only successful trajectories.
- The model is pre-trained on a mixture of these datasets using a phased curriculum, with the final training conducted using DeepSeek’s FP8 recipe (E4M3 for tensors, 128x128 quantization blocks, 1x128 activation tiles), with first and last four linear layers kept in BF16 and optimizer states in FP32.
Method
The authors leverage a hybrid Mamba-Transformer architecture for the Nemotron-Nano-12B-v2-Base model, which combines Mamba-2 layers, self-attention layers, and feed-forward network (FFN) layers to balance efficiency and reasoning capability. The model consists of 62 layers in total, with 28 Mamba-2 layers, 6 self-attention layers, and 28 FFN layers. The self-attention layers are strategically distributed throughout the model, as illustrated in the framework diagram, with approximately 8% of the total layers being self-attention blocks. This configuration is designed to maintain long-context modeling capabilities while improving inference speed for reasoning tasks. The model employs a hidden dimension of 5120, an FFN hidden dimension of 20480, and uses Grouped-Query Attention with 40 query heads and 8 key-value heads. For Mamba-2 layers, the architecture specifies 8 groups, a state dimension of 128, a head dimension of 64, an expansion factor of 2, and a convolution window size of 4. The FFN layers utilize squared ReLU activation, and the model does not use position embeddings, dropout, or bias weights for linear layers, instead relying on RMSNorm for normalization. The overall layer pattern and key architectural details are summarized in the framework diagram.
The alignment process for the Nemotron-Nano-12B-v2-Base model involves a multi-stage training pipeline designed to enhance instruction following, tool use, and conversational abilities. The process begins with three distinct stages of supervised fine-tuning (SFT). Stage 1 uses a comprehensive dataset augmented with a subsample of prompts paired with outputs stripped of reasoning traces, enabling the model to produce direct answers in a reasoning-off mode. To improve efficiency and preserve long-context learning, samples are concatenated into sequences of approximately 128k tokens. Stage 2 focuses on tool-calling, trained without concatenation to avoid disrupting learning of tool-calling patterns. Stage 3 reinforces long-context capability by incorporating long-context data and augmented examples with abruptly truncated reasoning traces to improve robustness under varying inference-time thinking budgets. Following SFT, the model undergoes reinforcement learning through multiple techniques. IFEval RL improves instruction adherence by using a rule-based verifier to score outputs based on how well they satisfy instructions. DPO is applied to strengthen tool-calling capabilities, using the WorkBench environment to generate on-policy data for iterative training. RLHF is employed to enhance overall helpfulness and chat capabilities, using GRPO with English-only contexts from HelpSteer3 and a Qwen-based reward model. The alignment flow is illustrated in the diagram below.
The model compression strategy extends the Minitron framework to achieve inference over 128k tokens on a single NVIDIA A10G GPU. This process involves importance estimation and lightweight neural architecture search. Importance estimation computes sensitivity scores for model components to guide pruning decisions. Layer importance is determined by iteratively removing each layer and measuring the mean squared error (MSE) between the original and pruned model's logits, with the least impactful layers removed first. For FFN and embedding channels, importance is assessed by aggregating the outputs of neurons and embedding channels using mean and 12-norm metrics over a calibration dataset. Mamba head importance is estimated using a nested activation-based scoring strategy, where activation scores from the Wx projection are aggregated, and heads are ranked within each Mamba group to preserve structural constraints. The lowest-scoring heads are pruned to remove less important components while maintaining the integrity of the selective state space model (SSM) block. The compression process also includes a lightweight neural architecture search that explores a multi-axis search space within a 19.66 GiB memory budget, considering depth reduction, width pruning of embedding channels, FFN dimension, and Mamba heads to find optimal architectural candidates.
Experiment
- Ablation study on Fundamental Reasoning (FR) SFT-style data showed that incorporating 5% FR-SFT data during continuous pretraining improved MMLU-Pro accuracy from 44.24 to 56.36 and increased average MATH score by approximately 2 points, without degrading commonsense reasoning or code benchmarks.
- Nemotron-Nano-12B-v2-Base was trained on a 20T token horizon with sequence length 8192, global batch size 768, and WSD learning rate schedule (stable: 4.5×10⁻⁴, min: 4.5×10⁻⁶), achieving strong performance on mathematical reasoning, code, and general reasoning benchmarks.
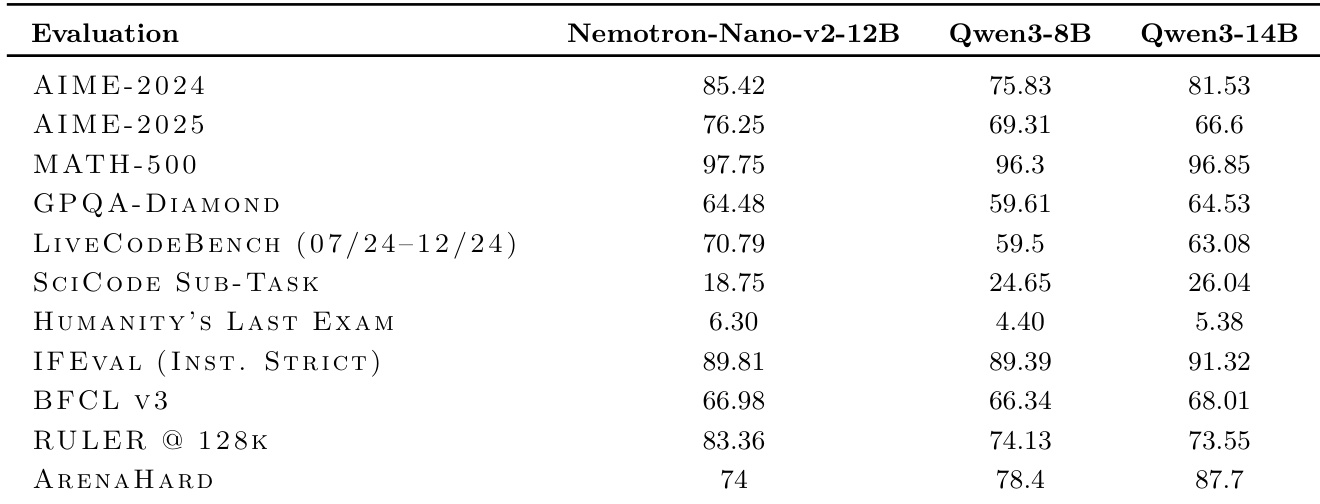
- Evaluation on diverse tasks demonstrated that the 12B model achieved high performance on MATH-500, AIME-2024, GPQA-DIAMOND, LIVECodeBench, and HUMANITY'S LAST EXAM, with strong results on instruction following (IFEVAL), tool calling (BFCL v3), long context (RULER), and chat capability (ARENAHARD).
- Architecture search identified 56-layer depth as optimal, with width pruning along FFN and embedding dimensions sufficient for compression; Candidate 2 (56 layers, pruned FFN and embedding) achieved the best balance of accuracy and throughput.
- Knowledge distillation and staged training (including DPO, GRPO, RLHF, and model merging) recovered accuracy post-pruning, with the final Nemotron-Nano-9B-v2 model achieving 3×–6× higher throughput than Qwen3-8B on an A10G GPU while surpassing it in accuracy and matching the 12B teacher on most benchmarks.
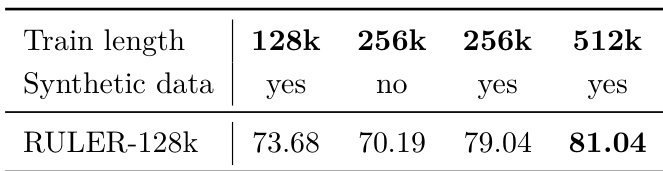
Results show that increasing the training sequence length from 128k to 512k improves the RULER-128k score from 73.68 to 81.04, with the best performance achieved when synthetic data is used at 256k and 512k lengths. The inclusion of synthetic data at 256k and 512k leads to higher scores compared to its absence at 256k, indicating that both longer context and synthetic data contribute to improved long-context performance.
The authors use an ablation study to evaluate the impact of varying proportions of fundamental reasoning SFT-style data on model performance. Results show that increasing the proportion of reasoning-SFT data from 50% to 70% improves average accuracy from 57.5 to 58.5, but further increasing it to 90% reduces accuracy to 57.2, indicating that 70% is optimal.

The authors use a 12B model as a base to develop a compressed 9B variant through depth and width pruning, resulting in improved inference throughput. The pruned model retains 56 layers, reduces FFN and embedding dimensions, and achieves higher throughput while maintaining accuracy comparable to the larger model.

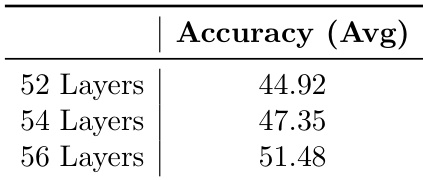
The authors use a depth-pruning experiment to evaluate the impact of model depth on reasoning accuracy, training three variants of a 12B model with 52, 54, and 56 layers. Results show that accuracy increases with depth, reaching 51.48 for the 56-layer model, which is significantly higher than the 44.92 accuracy of the 52-layer variant, indicating that deeper models perform better in reasoning tasks.
The authors compare the Nemotron-Nano-v2-12B model against Qwen3-8B and Qwen3-14B across multiple reasoning and general capability benchmarks. Results show that Nemotron-Nano-v2-12B achieves higher scores than Qwen3-8B on most tasks, including AIME-2024, MATH-500, and IFEval, while remaining competitive with the larger Qwen3-14B model.